
《精通Python网络爬虫:核心技术、框架与项目实战》——1.3 网络爬虫的组成
2023-09-11 14:16:11 时间
本节书摘来自华章出版社《精通Python网络爬虫:核心技术、框架与项目实战》一书中的第1章,第1.3节,作者 韦 玮,更多章节内容可以访问云栖社区“华章计算机”公众号查看。
1.3 网络爬虫的组成接下来,我们将介绍网络爬虫的组成。网络爬虫由控制节点、爬虫节点、资源库构成。
图1-1所示是网络爬虫的控制节点和爬虫节点的结构关系。
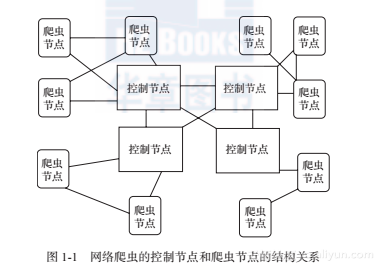
可以看到,网络爬虫中可以有多个控制节点,每个控制节点下可以有多个爬虫节点,控制节点之间可以互相通信,同时,控制节点和其下的各爬虫节点之间也可以进行互相通信,属于同一个控制节点下的各爬虫节点间,亦可以互相通信。
控制节点,也叫作爬虫的中央控制器,主要负责根据URL地址分配线程,并调用爬虫节点进行具体的爬行。
爬虫节点会按照相关的算法,对网页进行具体的爬行,主要包括下载网页以及对网页的文本进行处理,爬行后,会将对应的爬行结果存储到对应的资源库中。
快速上手python的简单web框架flask python可以做很多事情,虽然它的强项在于进行向量运算和机器学习、深度学习等方面。但是在某些时候,我们仍然需要使用python对外提供web服务。
新手教程 | Python Scrapy框架HTTP代理的配置与调试 做过python爬虫的都知道,HTTP代理的设置时要在发送请求前设置好,那HTTP代理的逻辑点在哪里呢?实际上,只需要在Scrapy 的项目结构中添加就好
相关文章
- Python之——python-nmap的安装与常用方法说明
- Python爬虫模拟登录的github项目
- 第三百五十七节,Python分布式爬虫打造搜索引擎Scrapy精讲—利用开源的scrapy-redis编写分布式爬虫代码
- Python 字符串_python 字符串截取_python 字符串替换_python 字符串连接
- 【python cookbook】【字符串与文本】13.对齐文本字符串
- python: 安装DeOldify库:黑白图片上色(Python 3.7.15)
- 理解Python中的装饰器
- 小白学 Python 爬虫(39): JavaScript 渲染服务 scrapy-splash 入门
- 小白学 Python 爬虫(6):前置准备(五)爬虫框架的安装
- Atitit nlp自然语言处理类库(java python nodejs c#net) 目录 1.1. Python snownlp1 1.2. NLP.js一个nodejs/javascri
- paip.数组以及集合的操作uapi java php python总结..
- 学习python 115小时后,告诉想学爬虫的你,别怕,爬虫,没那么难抓!
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(Canvas)
- Python编程语言学习:python中与数字相关的函数(取整等)、案例应用之详细攻略
- Python语言学习之字符串那些事:python和字符串的使用方法之详细攻略
- 真香,Python “手绘风格”数据可视化方法汇总
- C++调用C++项目中的Python脚本中的函数和类。,在,工程,python
- Python: TypeError: 'dict' object is not callable
- Python: yield, python 实现tail -f
- 雅虎财经数据python 网络爬虫stock股票 用 Python 通过雅虎财经获取股票数据
- C#、C++、Java、Python选择哪个好?
- Python+Selenium+Threading进行兼容性测试
- python实战===2017年30个惊艳的Python开源项目 (转)
- python 爬虫 循环分页
- 【python】Python实现网络爬虫demo实例
- Python实现logistics回归
- Python爬虫自学系列(七) -- 项目实战篇(一)
- 从零开始,学会Python爬虫不再难!!! -- (11)项目三:梳理博客中的无效链接丨蓄力计划