
《多核与GPU编程:工具、方法及实践》----2.2 PCAM方法学
本节书摘来自华章出版社《多核与GPU编程:工具、方法及实践》一书中的第2章,第2.2节, 作 者 Multicore and GPU Programming: An Integrated Approach[阿联酋]杰拉西莫斯·巴拉斯(Gerassimos Barlas) 著,张云泉 贾海鹏 李士刚 袁良 等译, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
2.2 PCAM方法学PCAM代表分割(Partitioning)、通信(Communication)、聚集(Agglomeration)和映射(Mapping),是一个分四步的并行程序设计过程,由Ian Foster在其1995的书[34]中推广使用。Foster的书是理解和合理使用PCAM的权威资源。即使对于多核平台,PCAM的核心思想在当今仍然是有意义的。
PCAM步骤如下。
1.分割:第一步是将计算分解成尽可能多的独立片段,这一步将能使算法中的并行性(如果存在)显示出来,片段的粒度取决于不同应用程序。分解可以是基于功能的,即把要发生的不同步骤分开(叫做功能分解);也可以是基于数据的,即把要处理的数据分开(叫做域分解或数据分解)。通常的经验是分解出的片段数量比可用计算节点的数量多一到两个数量级,这可使接下来的步骤有更好的灵活性。
2.通信:理想情况下,从上一步分解出的片段是完全独立的。然而,通常情况是任务之间都有依赖性:一个任务的开始要等待另一任务的结束,以此类推。这种依赖性可能包括数据传输:通信。在本步骤,需要在任务之间传输的数据量是确定的。结合前两步骤可创建任务依赖图,用节点表示任务,用边表示通信量。
3.聚集:通信妨碍并行计算,避免通信的方法之一是将任务聚集起来。每个聚集的组将被分配到同一计算节点,避免组内通信。按通常的经验,此时组的数量应该比可用计算节点多一个数量级。
4.映射:对于要执行的应用,由步骤3产生的任务组将被分配/映射到可用节点。本步骤要达到的目标是:(a)节点负载均衡,即节点应该有按执行时间衡量的差不多相同的工作量;(b)通过将有大量数据通信的任务组分配到相同节点以进一步降低通信开销——通过共享内存的通信基本是无开销的。
每一步骤将如何执行取决于具体应用。另外,映射步骤是一个NP完全问题,即它的通式对非平凡图没有最优解,但是可以使用一些启发式方法。
另外,重复计算可以提高性能,从而避免传输计算结果[9]。
作为应用PCAM的例子,这里考虑并行化一个低层图像处理算法,例如图像卷积,根据所使用的核,图像卷积可以用于噪声滤波、边缘检测或者其他应用。核是一个方阵,元素是用于计算新像素数据的权重。图2-1展示了一个用于计算模糊效果的核。
一个奇数尺寸为n的核K和一个图像f的卷积由下面的公式来定义:
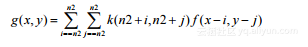
(2-1)
其中,如果 例如,使用的3×3核是:
例如,使用的3×3核是:
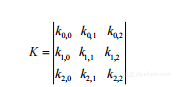
(2-2)
则对在第i行第j列的每个像素,根据下面的公式,其卷积运算得到的新像素值v’ij由该像素值及其8个邻居的像素值来决定:
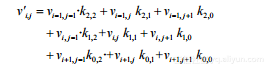
(2-3)
其中,v是原始像素值。

图2-1 将一个3×3的核应用到图像中的像素值以产生需要的效果,其中3×3的矩阵产生了模糊效果。右侧图像的新像素值是由核权重与包围像素所在区域的像素值乘积再求和所得到的应用基于卷积的滤波器的程序伪码如代码清单2-1所示。为避免特殊处理边界像素(即在图像四边的像素),保存数据值的数组增大了两行和两列。如何初始化这些多余的像素取决于如何设置卷积进行边界计算。例如,它们可以初始化为0,或者设置为离其最近的像素点值。

代码清单2-1 使用卷积进行图像滤波的伪码。图像尺寸假定是IMGX×IMGY,核尺寸是n×n
将代码清单2-1中的前两个循环展开,将循环体作为一个任务,便得到了一个尺寸为IMGX × IMGY的任务图。这是一个域分解的例子,因为每个任务将计算一个节点。然而,仅有像素的原始值是不足以进行计算的,还需要邻居像素的值,图2-2展示了产生的图。
图2-2中的计算所需要执行的通信操作等于:
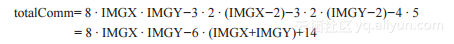
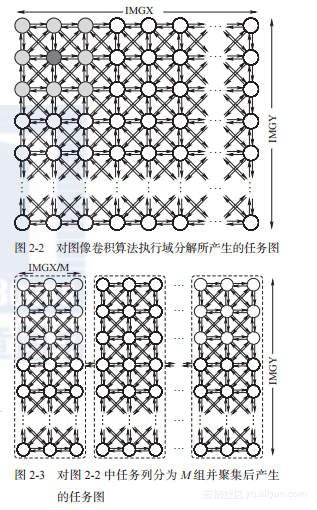
第一项计算每个像素点所需要的8次通信(图2-2中的深灰色任务得到8个浅灰色任务的数据)。后三项分别是对第一行和最后一行元素的修正次数(每个点少通信三次,总共少通信3·2·(IMGX-2)次)、第一列和最后一列元素的修正次数(3·2·(IMGY-2))和四个角像素的修正次数(4·5)。
图2-2是应用PCAM方法前两步的结果,很明显,通信操作的数量非常大。
按PCAM方法和第三步将任务组合起来,通过将任务所需的数据本地化来降低通信开销。将任务组合的方法有很多:
1-D:沿x或y轴组合任务。
2-D:组合相邻任务,形成固定大小的矩形组。
每组的边应该均匀划分,尽可能与相应的图片尺寸一致,否则产生的组会有不同的工作负载。在映射步骤完成后,这能导致一些节点空闲而另一些仍在计算的情况。
如果聚集是沿x轴进行的,假设组数M能整除图像列数,所得的任务图为图2-3。
这里通信操作减为2(M-1),但每个操作要IMGY个像素值。这个简单例子的组数可以和可用的计算节点数相匹配,使映射环节很简单。如果执行平台是非同构的,聚集也可能是非均一的,即各组的大小不相同。数据表示和执行平台的可能性是无穷无尽的,而且受问题驱动。
之前在第三章对比过CPU和GPU, 差距非常大. 这一次来看看GPU自身的优化, 主要是shared memory的用法.
之前第三篇也看到了, 并行方面GPU真的是无往不利, 现在再看下第二个例子, 并行规约. 通过这次的例子会发现, 需要了解GPU架构, 然后写出与之对应的算法的, 两者结合才能得到令人惊叹的结果.
GPU编程(二): GPU架构了解一下! GPU架构 GPU处理单元 概念GPU GPU线程与存储 之前谈了谈CUDA的环境搭建. 这次说一下基本的结构, 如果不了解, 还是没法开始CUDA编程的.
GPU编程(一): Ubuntu下的CUDA8.0环境搭建 老黄和他的核弹们 开发环境一览 显卡驱动安装 禁用nouveau 安装CUDA8.0 在Linux下安装驱动真的不是一件简单的事情, 我在经历了无数折磨之后终于搭起了GPU编程环境.
《多核与GPU编程:工具、方法及实践》----第2章 多核和并行程序设计 2.1 引言 本章目标 学习设计并行程序的PCAM方法。 使用任务图和数据依赖图来识别可以并行执行的计算部分。 学习将问题的解法分解为可并发执行部分的流行的分解模式。 学习编写并行软件的主要程序结构模式,如主/从和fork/join。 理解分解模式的性能特点,如流水线。
相关文章
- CAS SSO:汇集配置过程中的错误解决方法
- R语言中样本平衡的几种方法
- StringUtils 工具类的常用方法(转载)
- 魔法变量和魔法方法:__变量__、__方法__
- python(字符串、列表、字典、元组、集合)的常用内置方法
- nslookup工具的使用方法
- 抓取Dump文件的方法和工具介绍
- SAP UI5 应用开发教程之四十二 - SAP UI5 自带的 Diagnostics 诊断工具使用方法介绍
- Chrome 开发者工具 Initiator 面板单击后看不到 JavaScript 源代码的解决方法
- 如何在Chrome开发者工具console里手动调用focus方法给元素设置focus
- Atitit.通过null 参数 反射 动态反推方法调用
- paip.自适应网页设计 跟 响应式 设计方法与工具补充(2)o54
- AI之AutoML:Ludwig(无需编写代码/易于使用的界面和可视化自动机器学习工具)的简介、安装、使用方法之详细攻略
- SWIG:SWIG的简介、安装、使用方法之详细攻略
- 【华为云技术分享】CentOS7.4系统下,手动安装MySQL5.7的方法
- SQL Sever 2008配置工具中过程调用失败解决方法
- Apple Mach-O Linker Warning 警告解决的方法
- 004-unity3d MonoBehaviour脚本方法简介
- PostgreSQL的学习心得和知识总结(七十八)|深入理解PostgreSQL数据库客户端工具psql 添加 SHOW_ALL_RESULTS选项 的作用原理和使用方法
- PostgreSQL的学习心得和知识总结(七十六)|深入理解PostgreSQL数据库客户端工具psql元命令 扩展表格式化模式 的作用原理和使用方法
- Windiws10系统不显示可用网络的处理方法!
- Java:Java的jar包之POI的简介、安装、使用方法(基于POI将Word、Excel、PPT转换为html)之详细攻略
- python工具方法 31 通过导入自定义dll实现显存释放
- python工具方法 23 应用于语义分割的F1,recall,precision,iou,kappa系数的计算工具(支持ignore_index)
- python工具方法 18 labelme语义分割标注数据批量转换为png
- python工具方法 16 保存模型分类后的数据及分类错误的数据
- python工具方法 1 tensorflow简单全连接神经网络,识别minist手写数字
- Android抓包方法(三) 之Win7笔记本Wifi热点+WireShark工具