
《R语言数据挖掘:实用项目解析》——第2章,第2.5节解读分布
2023-09-11 14:16:11 时间
本节书摘来自华章出版社《R语言数据挖掘:实用项目解析》一书中的第2章,第2.5节解读分布,作者[印度]普拉迪帕塔·米什拉(Pradeepta Mishra),更多章节内容可以访问云栖社区“华章计算机”公众号查看
2.5 解读分布
计算概率分布、将数据点拟合于一些特定类型的分布以及后续的解读有助于建立假设。此假设可用于在给定一组参数下估算事件的概率。我们来看看对不同类型分布的解读。
解读连续型数据
一个数据集的任何变量都可通过拟合一个分布来得到其分布参数的最大似然估计。密度函数适用于诸如“贝塔”“柯西”“卡方”“指数”“f”“伽马”“几何”“对数正态”“logistic”“负二项”“正态”“泊松”“t”和“威布尔”等分布。这些分布都是常用的,这里不给出示例。对于连续型数据,我们采用正态分布和t分布:
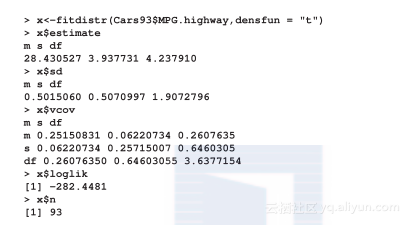
在上面的代码中,我们用的是Cars93数据集中的MPG.highway变量。通过让t分布拟合这个变量,我们得到参数估计、标准误差估计、协方差矩阵估计、对数似然值还有总数。类似的操作也适用于对连续型变量执行正态分布拟合:

现在我们来看如何图形化地表示变量的正态性:

可以看到,所表示的偏离的数据点距离直线很远。
下面解读离散数据,因为其中有所有分类:
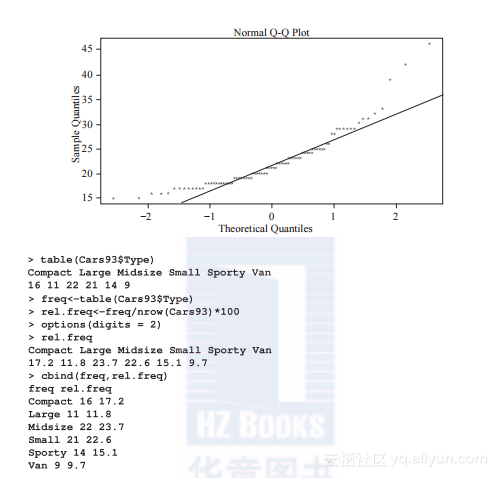
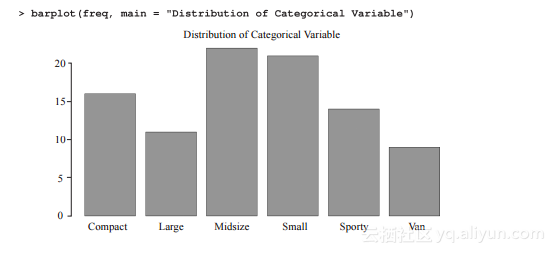
为了将结果可视化,我们需要用到下图所示的盒状图:
相关文章
- 《R语言数据挖掘:实用项目解析》——第1章,第1.1节什么是数据挖掘
- 《R语言数据挖掘:实用项目解析》——第1章,第1.8节循环原理——for循环
- 《R语言数据挖掘:实用项目解析》——第1章,第1.13节缺失值(NA)的处理
- 《R语言数据挖掘:实用项目解析》——第2章,第2.3节多元分析
- 《R语言数据挖掘:实用项目解析》——第2章,第2.4节解读分布和变换
- 《R语言数据挖掘:实用项目解析》——第2章,第2.6节变量分段
- 《圣殿祭司的ASP.NET4.0专家技术手册》---- 1-14 项目同时使用C# 与VB语言及多组件的技巧
- SwiftUI 语音合成与语言识别教程之 03 实现录音文件转文字(含完整项目源码)SFSpeechURLRecognitionRequest
- 《R语言数据挖掘:实用项目解析》——1.5 索引或切分数据框
- 《R语言数据挖掘:实用项目解析》——1.7 创建新函数
- 《R语言数据挖掘:实用项目解析》——1.11 apply原理
- 《R语言数据挖掘:实用项目解析》——小结
- 《R语言数据挖掘:实用项目解析》——第2章 汽车数据的探索性分析 2.1 一元分析
- 《R语言数据挖掘:实用项目解析》——2.4 解读分布和变换
- c语言开源项目--SQLite学习资料总结
- (三)xxx项目系统之日志全面监控,实现主流开发语言和平台日志监控分析和告警,简单高效的非侵入式接入项目