
《多核与GPU编程:工具、方法及实践》----第1章 概 述 1.1 多核计算机时代
本节书摘来自华章出版社《多核与GPU编程:工具、方法及实践》一书中的第1章,第1.1节, 作 者 Multicore and GPU Programming: An Integrated Approach[阿联酋]杰拉西莫斯·巴拉斯(Gerassimos Barlas) 著,张云泉 贾海鹏 李士刚 袁良 等译, 更多章节内容可以访问云栖社区“华章计算机”公众号查看。
本章目标:
了解计算机(计算机体系架构)设计的发展趋势以及该趋势如何影响软件开发。
学习基于Flynn分类的计算机分类方法。
学习评估多核/并行程序性能即加速比和效率的必备工具。
学习测量和报告程序性能的正确实验方法。
学习Amdahl和Gustafson-Barsis定律,并使用这两个定律预测并行程序性能。
1.1 多核计算机时代在过去的40年中,数字计算机已经成为技术和科学发展的基石。遵循20世纪70年代摩尔(Gordon E. Moore)发现的摩尔定律,计算机的信息处理速度(性能)呈指数提高,这使得我们可以处理更加复杂的问题。
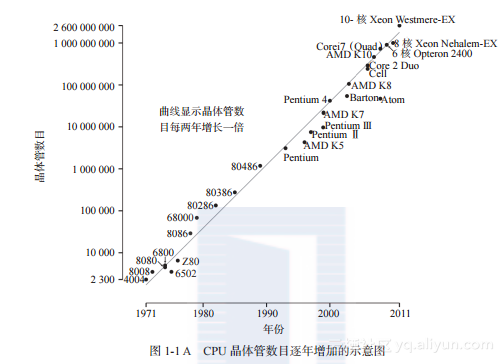
令人惊讶的是,即使在今天,摩尔定律也描述了行业的发展趋势。然而,在大众科学中有一个被忽视的问题需要澄清一下:摩尔定律描述的是晶体管数量呈指数级增长,而不是运行性能。图1-1描述了摩尔定律。
这是一个非常容易犯的错误,因为晶体管数目的增加伴随着运行频率(时钟频率)的提高。但是,时钟频率的增加会导致产热的增加。为此,芯片设计者不断降低电子电路的操作电压(目前的运行电压为1.29V)。然而,这并不足以解决这个问题。因此,时钟频率的发展不可避免地陷入停滞。在过去10年中,主流时钟频率维持在2~4GHz之间。
所以,获取更高计算能力的唯一途径就是在芯片内部集成更多的计算逻辑和计算核心。随着AMD于2015年推出第一款双核芯片(AMD 64 X2),更多的多核芯片也被不断推出。这其中不仅包括拥有大量计算核心的同构芯片(如 64核Tilera,TILE64),而且包括异构芯片,如Cell BE,它采用Power架构,并用于Sony Playstation 3。
这些芯片是多路(multisocket)平台(即,20世纪90年代中后期出现的搭载多个CPU的计算机)的自然演化。然而,GPGPU(通用计算图形处理单元)的出现是一个意外。GPGPU是指利用GPU (Graphical Processing Unit,图形处理器)进行通用计算。虽然单个GPU核与同时代的CPU核相比性能很差,但是GPU采用了大规模并行架构,拥有通过高带宽、高性能RAM相连的成百上千个计算核心。因此,同CPU相比,GPU的性能以数量级提升。
在能源日益紧张的今天,GPGPU还有一个额外优势:它提供了卓越的GFlop/W的性能。换句话说,可以使用同样的能源进行更多的计算。这在服务器和云基础设施领域是非常重要的。在这些领域中,CPU在其运行寿命中消耗的能源费用要比其购买价格高得多。
GPGPU技术被认为是颠覆性的,在很多层面上确实是这样:它为使用现代单核甚至多核CPU技术仍然无法解决的问题提供了解决方案。但是,GPGPU需要新的软件设计、开发工具和技术。据预测,在不久的将来,需要数百万个线程来开发下一代高性能计算硬件的性能。
然而,所有这些多核芯片带来的性能提升都不是免费的:需要对按部就班执行的传统算法进行重新设计。
《多核与GPU编程:工具、方法及实践》----2.2 PCAM方法学 PCAM代表分割(Partitioning)、通信(Communication)、聚集(Agglomeration)和映射(Mapping),是一个分四步的并行程序设计过程,由Ian Foster在其1995的书[34]中推广使用。
《多核与GPU编程:工具、方法及实践》----第2章 多核和并行程序设计 2.1 引言 本章目标 学习设计并行程序的PCAM方法。 使用任务图和数据依赖图来识别可以并行执行的计算部分。 学习将问题的解法分解为可并发执行部分的流行的分解模式。 学习编写并行软件的主要程序结构模式,如主/从和fork/join。 理解分解模式的性能特点,如流水线。
《多核与GPU编程:工具、方法及实践》----1.5 并行程序性能的预测与测量 构建并行程序要比串行程序更具挑战性。并行程序程序员需要解决诸如共享资源访问、负载均衡(即,将计算负载分配到所有计算资源上来最小化执行时间)以及程序终止(即,以协调方式暂停程序)等相关问题。
《多核与GPU编程:工具、方法及实践》----1.4 性能指标 发展多核硬件和开发多核软件的目标是获取更高性能,例如更短的执行时间、更大规模的问题和更大的数据集等。很明显,这需要一个客观的标准或者准则来评估这些努力的有效性。
《多核与GPU编程:工具、方法及实践》----1.3 现代计算机概览 现代计算机模糊了Flynn分类的界限。为了获取更高性能,根据其测试的层次,现代计算机既是MIMD也是SIMD。 通过小型化和改进半导体材料增加晶体管数目,现代计算机目前主要有两种趋势。
《多核与GPU编程:工具、方法及实践》----1.2 并行计算机的分类 使用多种资源获取更高性能并不是最新的技术,这个技术最早开始于20世纪60年代。因此,定义一种描述并行计算机架构特征的方法是非常重要的。1966年,Michael Flynn引入了一种计算机体系结构分类方法:根据能够并发处理的数据量和同时执行的不同指令数目进行分类。
《多核与GPU编程:工具、方法及实践》----导读 多核架构出现在21世纪的第一个10年里,给并行计算带来了勃勃生机。新平台需要新方法来进行软件开发,其中一个新方法就是把工具和工作站网络时代的惯例同新兴软件平台(如CUDA)相结合。 为满足这种需求,本书将介绍目前主流的工具和技术,不仅是各自独立的工具和技术,更重要的是将它们相互结合。
《多核与GPU编程:工具、方法及实践》---- 3.9 调试多线程应用 调试多线程应用不仅仅是具备一个能够管理多线程的调试器。许多现代调试器支持线程的执行和独立调试,并支持指定线程的断点、观察窗等。本节不讨论调试器的具体实现方法。例如,图3-13展示了DDD——GNU DeBugger(GDB)前端,它执行代码清单3-24中公平的读者–写者解决方案。
相关文章
- 爬虫 Http请求,urllib2获取数据,第三方库requests获取数据,BeautifulSoup处理数据,使用Chrome浏览器开发者工具显示检查网页源代码,json模块的dumps,loads,dump,load方法介绍
- WinThruster中文版破解方法(注册表无伤清理工具)
- 工作总结 for 另类写法 循环加时间 集合合并 也是用的 static class Enumerable (IEnumerable<T>的扩展方法) (IEnumerable<T> 的 工具类) (所有集合 数组都实现IEnumerable<T>)
- Oracle数据库:oracle启动,oracle客户端工具plsql安装教程和使用方法
- 微信小程序自动化测试pytest版工具使用方法
- 汽车嵌入式软件自动化测试的方法及推荐工具
- 自学Linux命令的四种方法
- 《多核与GPU编程:工具、方法及实践》----1.4 性能指标
- 《多核与GPU编程:工具、方法及实践》----第2章 多核和并行程序设计 2.1 引言
- 《多核与GPU编程:工具、方法及实践》----2.4 程序结构模式
- 《多核与GPU编程:工具、方法及实践》----第3章 共享内存编程:线程 3.1 引言
- 《多核与GPU编程:工具、方法及实践》----3.6 monitor
- 《多核与GPU编程:工具、方法及实践》---- 3.7 经典问题中的monitor
- MySQL--Centos7.x MySQL5.7.x忘记root密码的解决方法
- QT-子线程或自定义类操作访问主界面UI控件的几种方法
- opencv多线程显示的问题和解决方法
- vue源码中的一些工具方法
- 网络I/O模型--04非阻塞模式(解除accept()、 read()方法阻塞)的基础上加入多线程技术
- 从网页抓取数据的一般方法
- CSRF简单介绍及利用方法-跨站请求伪造
- 工具及方法 - Linux下串口工具Minicom
- 工具及方法 - 电子烟开发中使用温度测试工具
- 工具及方法 - 查看飞机信息
- Eclipse设置类和方法的注释模板
- (精简)Spring框架的IoC(替代工厂类实现方法)和AOP(定义规则,约定大于配置)