
颠覆大数据分析之Spark弹性分布式数据集
Spark中迭代式机器学习算法的数据流可以通过图2.3来进行理解。将它和图2.1中Hadoop MR的迭代式机器学习的数据流比较一下。你会发现在Hadoop  MR中每次迭代都会涉及HDFS的读写,而在Spark中则要简单得多。它仅需从HDFS到Spark中的分布式共享对象空间的一次读入——从HDFS文件中创建RDD。RDD可以重用,在机器学习的各个迭代中它都会驻留在内存里,这样能显著地提升性能。当检查结束条件发现迭代结束的时候,会将RDD持久化,把数据写回到HDFS中。后续章节会对Spark的内部结构进行详细介绍——包括它的设计,RDD,以及世系等等。
MR中每次迭代都会涉及HDFS的读写,而在Spark中则要简单得多。它仅需从HDFS到Spark中的分布式共享对象空间的一次读入——从HDFS文件中创建RDD。RDD可以重用,在机器学习的各个迭代中它都会驻留在内存里,这样能显著地提升性能。当检查结束条件发现迭代结束的时候,会将RDD持久化,把数据写回到HDFS中。后续章节会对Spark的内部结构进行详细介绍——包括它的设计,RDD,以及世系等等。
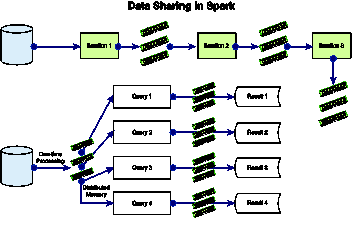
图2.3 Spark中进行迭代式计算的数据共享
Spark的弹性分布式数据集
RDD这个概念跟我们讨论到的Spark的动机有关——就是能让用户操作分布式系统上的Scala集合。Spark中的这个重要的集合就是RDD。RDD可以通过在其它RDD或者稳态存储中的数据(比如说,HDFS中的文件)上执行确定性操作来进行创建。创建RDD的另一种方式就是将Scala集合并行化。RDD的创建也就是Spark中的转换操作。RDD上除了转换操作,还有其它的一些操作,比如说动作(action)。像map, filter以及join这些都是常见的转换操作。RDD有意思的一点在于它可以将自己的世系或者说创建它所需的转换序列,以及它上面的动作给存储起来。这意味着Spark程序只能拥有一个RDD引用——它知道自己的世系,包括它是如何创建的,上面执行过哪些操作。世系为RDD提供了容错性——即使它丢失了,只要世系本身被持久化或者复制了,就仍能重建整个RDD。RDD的持久化以及分块可以由程序员来指定。比如说,你可以基于记录的主键来进行分块。
在RDD上可以执行许多操作。包括count,collect以及save,它们分别可以用来统计元素总数,返回记录,以及保存到磁盘或者HDFS中。世系图中存储了RDD的转换以及动作。表2.1中列举了一系列的转换及动作。
表2.1
groupByKey(noTasks) 只能在键值对数据上进行调用——返回的数据按值进行分组。并行任务的数量通过一个参数来指定(默认是8)
reduceByKey(function f4,noTasks) 对相同key元素上应用函数f4的结果进行聚合。第二个参数是并行的任务数
saveAsTextFile(path) 将RDD持久化成HDFS或者其它Hadoop支持的文件系统中路径为path的一个文件
saveAsSequenceFile(path) 将RDD持久化为Hadoop的一个序列文件。只能在实现了Hadoop写接口或类似接口的键值对类型的RDD上进行调用。
下面将通过一个例子来介绍下如何在Spark环境中进行RDD的编程。这里是一个呼叫数据记录(CDR)——基于影响力分析的应用程序——通过CDR来构建用户的关系图,并识别出影响力最大的K个用户。CDR结构包括id,调用方,接收方,计划类型,呼叫类型,持续时长,时间,日期。具体做法是从HDFS中获取CDR文件,接着创建出RDD对象并过滤记录,然后再在上面执行一些操作,比如说通过查询提取出特定的字段,或者执行诸如count的聚合操作。最终写出的Spark代码如下:
val spark = new SparkContext();
Call_record_lines = spark.textFile(“HDFS://….”);
Plan_a_users = call_record_lines.filter(_.
CONTAINS(“plana”)); // RDD上的过滤操作.
Plan_a_users.cache(); // 告诉Spark运行时,如果仍有空间,就将这个RDD缓存到内存里Plan_a_users.count();
%% 呼叫数据集处理中.
RDD可以表示成一张图,这样跟踪RDD在不同转换/动作间的世系变化会简单一些。RDD接口由五部分信息组成,详见表2.2。
表2.2 RDD接口
Spark的实现
Spark是由大概20000行Scala代码写就的,核心部分大概是14000行。Spark可以运行在Mesos, Nimbus或者YARN等集群管理器之上。它使用的是未经修改的Scala解释器。当触发RDD上的一个动作时,一个被称为有向无环图(DAG)调度器的Spark组件就会去检查RDD的世系图,同时会创建各阶段的DAG。每个阶段内都只会出现窄依赖,宽依赖所需的洗牌操作就是阶段的边界。调度器在DAG的不同阶段启动任务来计算出缺失的分区,以便重构整个RDD对象。它将各阶段的任务对象提交给任务调度器(Task Scheduler, TS)。任务对象是一个独立的实体,它由代码和转换以及所需的元数据组成。调度器还负责重新提交那些输出丢失了的阶段。任务调度器使用一个被称为延迟调度(Zaharia等 2010)的调度算法来将任务分配给各个节点。如果RDD中有指定了优先区域的话,任务会被传送给这些节点,否则会被分配到那些有分区在请求内存任务的节点上。对于宽依赖而言,中间记录会在那些包含父分区的节点上生成。这样会使得错误恢复变得简单,Hadoop MR中map输出的物化也是类似的。
Spark中的Worker组件会负责接收任务对象并在一个线程池中调用它们的run方法。它将异常或者错误报告给TaskSetManager(TSM)。TSM是任务调度器管理的一个实体——每个任务集都会对应一个TSM,用于跟踪任务的执行过程。TS是按先进先出的顺序来轮询TSM集的。通过插入不同的策略或者算法,这里仍有一定的优化空间。执行器会与其它的组件进行交互,比如说块管理器(BM),通信管理器(CM),Map输出跟踪器(MOT)。块管理器是节点用于缓存RDD并接收洗牌数据的组件。它也可以看作是每个worker中只写一次的K-V存储。块管理器和通信管理器进行通信以便获取到远端的块数据。通信管理器是一个异步网络库。MOT这个组件会负责跟踪每个map任务都在哪运行并把这些信息返回给归约器——Worker会缓存这个信息。当映射器的输出丢失了的话,会使用一个“分代ID”来将这个缓存置为无效。Spark中各组件的交互如图2.4中所示。
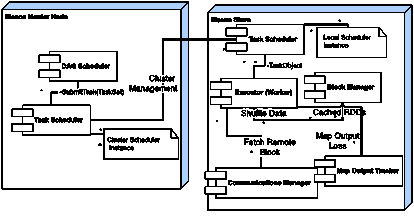
图2.4 Spark集群中的组件
RDD的存储可以通过下面这三种方式来完成:
作为Java虚拟机中反序列化的Java对象:由于对象就在JVM内存中,这样做的性能会更佳。 作为内存中序列化的Java对象:这么表示内存的使用率会更高,但却牺牲了访问速度。 存储在磁盘上:这样做性能最差,但是如果RDD太大以至于无法存放到内存中的话就只能这么做了。一旦内存满了,Spark的内存管理会通过最近最少使用(LRU)策略来回收RDD。然而,属于同一个RDD的分区是无法剔除的——因为通常来说,一个程序可能会在一个大的RDD上进行计算,如果将同一个RDD中的分区剔除的话则会出现系统颠簸。
世系图拥有足够的信息来重建RDD的丢失分区。然而,考虑到效率的因素(重建整个RDD可能会需要很大的计算量),检查点仍是必需的——用户可以自主控制哪个RDD作为检查点。使用了宽依赖的RDD可以使用检查点,因为在这种情况下,计算丢失的分区会需要显著的通信及计算量。而对于只拥有窄依赖的RDD而言,检查点则不太适合。
转载自 并发编程网 - ifeve.comAI大事件 | 人类理解行为数据集推出,Uber发布自家分布式深度学习框架 呜啦啦啦啦啦大家好呀,又到了本周的AI大事件时间了。过去的一周中AI圈都发生了什么?大佬们互撕了哪些问题?研究者们发布了哪些值得一读的论文?又有哪些开源的代码和数据库可以使用了?文摘菌带你盘点过去一周AI大事件!
Spark2.3.0 版本: Spark2.3.0 创建RDD Spark的核心概念是弹性分布式数据集(RDD),RDD是一个可容错、可并行操作的分布式元素集合。
相关文章
- 分布式服务框架 Zookeeper—管理分布式环境中的数据
- 适用于app.config与web.config的ConfigUtil读写工具类 基于MongoDb官方C#驱动封装MongoDbCsharpHelper类(CRUD类) 基于ASP.NET WEB API实现分布式数据访问中间层(提供对数据库的CRUD) C# 实现AOP 的几种常见方式
- js遍历PHP的json数据
- 108分布式电商项目 - MySQL优化(插入数据优化)
- 抽取网页数据的不同思路
- 大规模数据的分布式机器学习平台
- 《Arduino计算机视觉编程》一3.2 传感器数据采集
- [转]js将扁平结构数据转换为树形结构
- [转]手把手教你--Bootstrap Table表格插件及数据导出(可导出Excel2003及Exce2007)
- 手机数据抓包入门教程
- 一图读懂 大数据在线实习项目-可获实习证明
- 8.【kafka运维】kafka-dump-log.sh数据查看
- 《深入理解大数据:大数据处理与编程实践》一一2.3 集群分布式Hadoop系统安装基本步骤
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
- 调用hcm接口同步员工数据更新员工信息没有同步到bdm
- 大数据教程之Zookeeper 分布式服务在分布式环境中协调和管理服务
- 云端数据遭觊觎 安全问题不容忽视
- 传说中的相关部门 靠什么来存储数据?
- 开始云私有云存储系统:让数据更安全高效
- 贵阳高新区发布促进大数据技术创新十条政策措施
- 分布式服务框架 Zookeeper -- 管理分布式环境中的数据--转载
- 三星收购云计算公司剑指“大数据”,IBM“跨界”合作打造智慧医疗
- 分布式概念简单了解:数据一致性、CAP、BASE、分布式事务、分布式锁
- 分布式概念简单了解:数据一致性、CAP、BASE、分布式事务、分布式锁
- 传统媒体转型:借力大数据 重建用户连接
- SQL条件!=null查不出数据
- 什么是SQL Server2019大数据群集?
- SQL通过一个表数据更新另外一个表
- Python实战案例分享:爬取当当网商品数据