
中断与性能
感谢同事【空蒙】的投稿
中断,会导致正在运行的CPU要停下手头的工作去响应,这需要工作任务的切换,就带来了我们熟知的上下文切换,而频繁上下文切换,是对系统性能的重要影响因素。
那怎么减少中断带来的影响呢?现在CPU往往是多核,如16、32核,是否可以把中断绑定到其中一个CPU上,再把其他剩余的cpu用于应用的计算。因为之前是单核的原因,传统的很多做法是会把中断扔给cpu0处理,在linux下,可执行mpstat -P ALL 1,查看各个cpu上的中断情况。

这虚拟机可以看到cpu2上的中断明显偏多,每秒有6k次,这样会对性能产生什么样的影响呢?再看上下文切换的情况
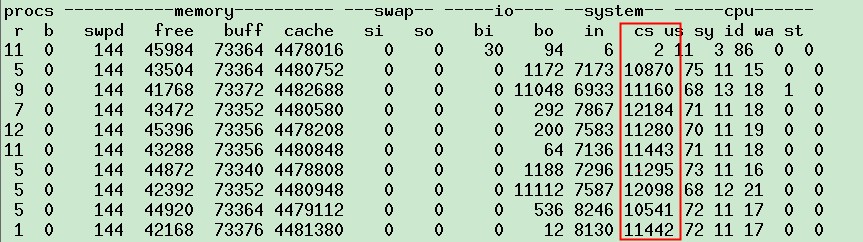
此时上下文切换大于1w次,再看top里面cpu对软中断与硬中断的处理情况

对应的也可发现,CPU2上处里更多的中断,hi与si。如果此时我们的应用跑在CPU2上,结果可想而知就是每秒约6k次的上下文切换。既然如此那我就设置下应用使用的CPU,让java进程不在CPU2上跑,会有什么效果呢?

立马可以看到,cpu2上的us变的很低了,java进程在其他的cpu上运行了,但cpu2上继续响应hi与si,再看上下文切换情况
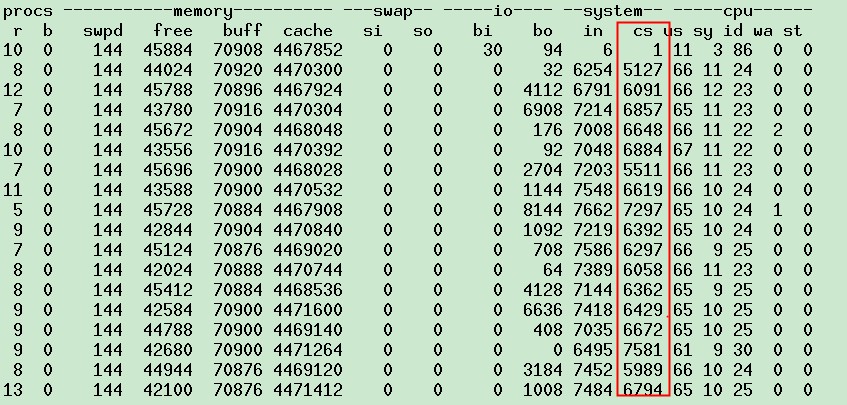
可以看到,现在上下文切换,明显比之前的少了5~6k,基本上就是之前在cpu2上的中断次数,稍做改动,就把上下文切换减少了很多
那整体的cpu利用率情况呢:
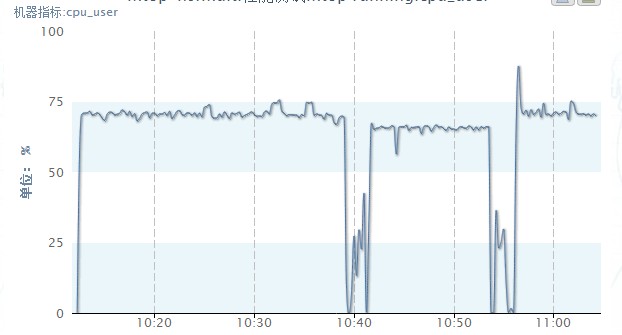
如上图中间这段的数据,是设置了java进程运行在CPU0、1、3、4上的,前后两段是全部CPU跑的,大概us比不设置降低了5%,us降低了点,性能上当然可以提升点了。
当其中一个CPU的hi和si明显比其他的高,而且系统的吞吐能力上不去,很可能是中断处理不均衡的问题,当中断的数量一个CPU够处理的时候,利用亲缘绑定CPU,减少中断引起的上下文切换,但当一个CPU中断处理不够时候,就用多个CPU处理,或者所有CPU平均分摊,但所有的CPU分摊,上下文切换的次数不会减少。所以真正如何处理这个中断,还是看系统与应用的实际情况。
网卡的中断网卡接收数据后会产生中断,让CPU来处理,一个CPU没话说,只有它干活,多核时代怎么搞呢,很多老的设备还是绑定一个CPU上。为了能充分利用多核,Google的牛人搞了个RPS、RFS的patch,能够将网卡中断分散到多个CPU,主要就是hash到固定的CPU上,具体可google查看。
但是,这明显是我等屌丝的玩法,现在高富帅的玩法是,高级的网卡是支持多队列的,找新机器cat /proc/interrupts |grep eth0,可以看到eth0-TxRx-0 ~~eth0-TxRx-7,同时每个队列的中断对应一个CPU,这样就把中断响应分摊了。
但现在cpu32核,还是显得不够平均,所以这时候还可以使用RFS,看看效果,当然RFS需要linux 2.6.35以上支持,所以那些2.6.18内核的机器,快点退休吧。
T4的机器目前虚拟机对cpu的分配,是用cgroup跨core绑定的,也就是会跨物理cpu组成一个虚拟机,这会带来cache miss的问题,至于为什么不选择一个虚拟机尽量在一个core上,大师的答复是主要是为充分利用资源,我们的应用,还没有到cache miss影响更大,还是充分利用cpu运算能力先。
文章转自 并发编程网-ifeve.com
高并发的中断下半部tasklet实例解析 最近为了解决一个技术问题,需要用到内核里中断下半部的tasklet机制,使用过程遇到了非常有趣的问题。在解决问题过程中,也逐步加深了对tasklet机制的理解。本文把这些收获记录下来和大家一起分享,经3.10测试通过