
机器学习算法集锦:从贝叶斯到深度学习及各自优缺点
在我们日常生活中所用到的推荐系统、智能图片美化应用和聊天机器人等应用中,各种各样的机器学习和数据处理算法正尽职尽责地发挥着自己的功效。本文筛选并简单介绍了一些最常见算法类别,还为每一个类别列出了一些实际的算法并简单介绍了它们的优缺点。
https://static.coggle.it/diagram/WHeBqDIrJRk-kDDY
目录
它是另一种方法(通常是回归方法)的拓展,这种方法会基于模型复杂性对其进行惩罚,它喜欢相对简单能够更好的泛化的模型。
例子:
集成方法是由多个较弱的模型集成模型组,其中的模型可以单独进行训练,并且它们的预测能以某种方式结合起来去做出一个总体预测。
该算法主要的问题是要找出哪些较弱的模型可以结合起来,以及结合的方法。这是一个非常强大的技术集,因此广受欢迎。
决策树学习使用一个决策树作为一个预测模型,它将对一个 item(表征在分支上)观察所得映射成关于该 item 的目标值的结论(表征在叶子中)。
树模型中的目标是可变的,可以采一组有限值,被称为分类树;在这些树结构中,叶子表示类标签,分支表示表征这些类标签的连接的特征。
例子:
回归是用于估计两种变量之间关系的统计过程。当用于分析因变量和一个 多个自变量之间的关系时,该算法能提供很多建模和分析多个变量的技巧。具体一点说,回归分析可以帮助我们理解当任意一个自变量变化,另一个自变量不变时,因变量变化的典型值。最常见的是,回归分析能在给定自变量的条件下估计出因变量的条件期望。
回归算法是统计学中的主要算法,它已被纳入统计机器学习。
例子:
人工神经网络是受生物神经网络启发而构建的算法模型。
它是一种模式匹配,常被用于回归和分类问题,但拥有庞大的子域,由数百种算法和各类问题的变体组成。
例子:
模型处于「黑箱状态」,难以理解内部机制
元参数(Metaparameter)与网络拓扑选择困难。
深度学习(Deep Learning)
深度学习是人工神经网络的最新分支,它受益于当代硬件的快速发展。
众多研究者目前的方向主要集中于构建更大、更复杂的神经网络,目前有许多方法正在聚焦半监督学习问题,其中用于训练的大数据集只包含很少的标记。
例子:

给定一组训练事例,其中每个事例都属于两个类别中的一个,支持向量机(SVM)训练算法可以在被输入新的事例后将其分类到两个类别中的一个,使自身成为非概率二进制线性分类器。
SVM 模型将训练事例表示为空间中的点,它们被映射到一幅图中,由一条明确的、尽可能宽的间隔分开以区分两个类别。
随后,新的示例会被映射到同一空间中,并基于它们落在间隔的哪一侧来预测它属于的类别。
优点:
在非线性可分问题上表现优秀
缺点:
和集簇方法类似,降维追求并利用数据的内在结构,目的在于使用较少的信息总结或描述数据。
这一算法可用于可视化高维数据或简化接下来可用于监督学习中的数据。许多这样的方法可针对分类和回归的使用进行调整。
例子:
聚类算法是指对一组目标进行分类,属于同一组(亦即一个类,cluster)的目标被划分在一组中,与其他组目标相比,同一组目标更加彼此相似(在某种意义上)。
例子:
基于实例的算法(有时也称为基于记忆的学习)是这样学 习算法,不是明确归纳,而是将新的问题例子与训练过程中见过的例子进行对比,这些见过的例子就在存储器中。
之所以叫基于实例的算法是因为它直接从训练实例中建构出假设。这意味这,假设的复杂度能随着数据的增长而变化:最糟的情况是,假设是一个训练项目列表,分类一个单独新实例计算复杂度为 O(n)
例子:
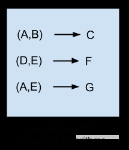
关联规则学习方法能够提取出对数据中的变量之间的关系的最佳解释。比如说一家超市的销售数据中存在规则 {洋葱,土豆}= {汉堡},那说明当一位客户同时购买了洋葱和土豆的时候,他很有可能还会购买汉堡肉。
例子:
图模型或概率图模型(PGM/probabilistic graphical model)是一种概率模型,一个图(graph)可以通过其表示随机变量之间的条件依赖结构(conditional dependence structure)。
例子:
Interview:机器学习算法工程师求职九大必备技能之【数学基础、工程能力、特征工程、模型评估、优化算法、机器学习基本概念、经典机器学习模型、深度学习模型、业务与应用】(建议收藏,持续更新) Interview:机器学习算法工程师求职九大必备技能之【数学基础、工程能力、特征工程、模型评估、优化算法、机器学习基本概念、经典机器学习模型、深度学习模型、业务与应用】(建议收藏,持续更新)
深度学习在最近两年非常火爆,它迅速地成长起来了,并且以其疯狂的实证结果着实令我们惊奇。 但深度学习是否真的就取代了传统或者其他机器学习算法了呢?那么,传统的机器学习还有必要去学习吗? 首先来看一位同学的心得:
Google DeepMind研发工程师Jack 谈及深度学习会导致其他学习算法濒临灭绝,我不赞同,也不反对,因为学习成本和时间是成正比的。
相关文章
- (《机器学习》完整版系列)第16章 强化学习——16.8 异策略蒙特卡罗强化学习算法(换分布)
- (《机器学习》完整版系列)第13章 半监督学习——13.5 基于分歧的方法(多学习器间的差异、协同训练算法)
- (《机器学习》完整版系列)第11章 特征选择与稀疏学习——11.6 压缩感知(RIP算法竟将要解的方程式视为约束条件)
- 腾讯面试——机器学习/算法面试案例集
- C#,人工智能,机器学习,聚类算法,训练数据集生成算法、软件与源代码
- 机器学习笔记之Sigmoid信念网络(三)KL散度角度观察醒眠算法
- 机器学习笔记之EM算法(二)EM算法公式推导过程
- 机器学习算法一览(附python和R代码)
- 机器学习算法与理论用到的数学知识
- 机器学习九大算法---随机森林
- 机器学习九大算法---支持向量机
- 机器学习九大算法---朴素贝叶斯分类器
- 《Python机器学习——预测分析核心算法》——导读
- Python数据处理Tips机器学习英文数据集8种算法应用
- 【AI理论学习】机器学习算法的分类