
Python: Log Analysis
2023-09-11 14:16:16 时间


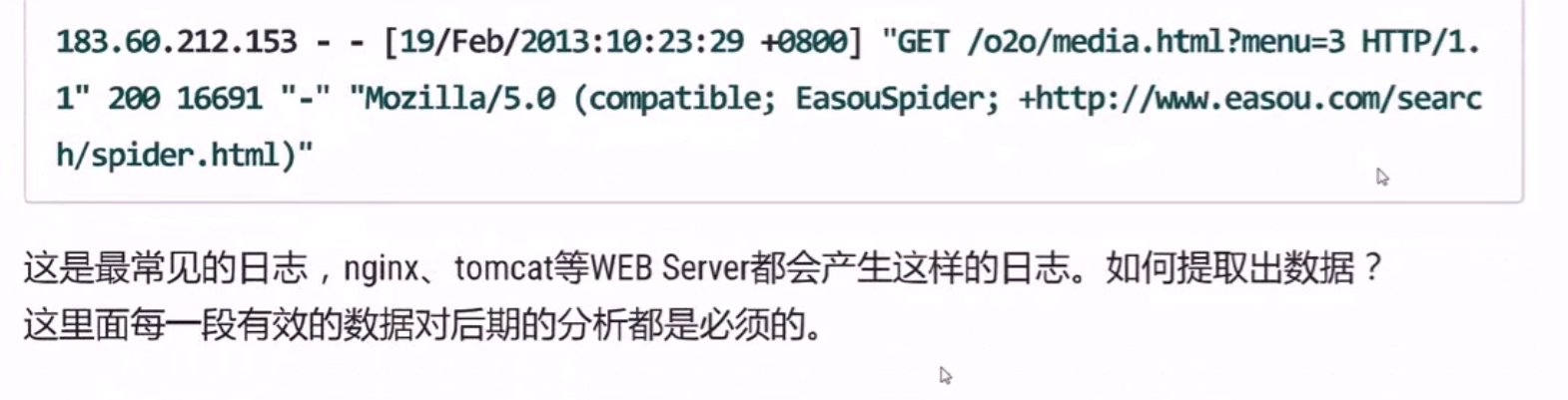
with open(file) as f: for line in f: for field in line.split(): print(filed)

import re from collections import defaultdict valve = '''51.222.253.18 - - [02/Mar/2022:02:30:16 +0800] "GET /robots.txt HTTP/1.1" 301 169 "-" "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)" "-" ''' def valour(b: str): valor = list() flag = False tmp = '' for word in b.split(): if not flag and (word.startswith('[') or word.startswith('"')): if word.endswith(']') or word.endswith('"'): valor.append(word.strip('[]"')) continue flag = True tmp = word[1:] continue if flag: if word.endswith(']') or word.endswith('"'): tmp += f' {word[:-1]}' valor.append(tmp) flag = False continue else: tmp += f' {word}' continue valor.append(word) return valor print(valour(valve))
import re, datetime from collections import defaultdict valve = '''51.222.253.18 - - [02/Mar/2022:02:30:16 +0800] "GET /robots.txt HTTP/1.1" 301 169 "-" "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)" "-" ''' def normalize_time(timestr): # 02/Mar/2022:02:30:16 +0800 fmtstr = '%d/%b/%Y:%H:%M:%S %z' dt = datetime.datetime.strptime(timestr, fmtstr) return dt def normalize_request(request: str): return dict(zip(('method', 'url', 'protocol'), request.split())) names = ['remote', '', '', 'datetime', 'request', 'status', 'size', '', 'useragent'] dispose = [None, None, None, normalize_time, normalize_request, int, int, None, None] def valour(b: str): valor = [] vamp = '' flag = False for word in b.split(): if not flag: if word.startswith('[') or word.startswith('"'): if word.endswith(']') or word.endswith('"'): valor.append(word.strip('[]"')) else: flag = True vamp = word[1:] continue else: valor.append(word) else: if word.endswith(']') or word.endswith('"'): flag = False vamp += f' {word[:-1]}' valor.append(vamp) else: vamp += f' {word}' return valor vandal = valour(valve) vane = {} for i, name in enumerate(names): if name: if dispose[i]: vane[name] = dispose[i](vandal[i]) else: vane[name] = vandal[i] print(vandal) print(vane)

import datetime def normalize_time(time_str): return datetime.datetime.strptime(time_str, '%d/%b/%Y:%H:%M:%S %z')







def distill(line) -> dict: matcher = regex.match(line) if matcher: return {k: ops.get(k, lambda v: v)(v) for k, v in matcher.groupdict().items()} else: raise Exception('Not Match')


import re, datetime valve = '''51.222.253.18 - - [02/Mar/2022:02:30:16 +0800] "GET /robots.txt HTTP/1.1" 301 169 "-" "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)" "-" ''' pattern = r'(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "(?P<referer>[^"]+)" "(?P<useragent>[^"]+)" "-"' regex = re.compile(pattern, flags = re.M) def normalize_time(time: str): # 02/Mar/2022:02:30:16 +0800 format = '%d/%b/%Y:%H:%M:%S %z' dt = datetime.datetime.strptime(time, format) return dt def normalize_request(request: str): return dict(zip(('method', 'url', 'protocol'), request.split())) names = ['remote', '', '', 'datetime', 'request', 'status', 'size', '', 'useragent'] dispose = { 'datetime': normalize_time, # 'request': normalize_request, 'request': lambda request: dict(zip(('method', 'url', 'protocol'), request.split())), 'status': int, 'size': int } def distill(line, regex: re.Pattern): matcher = regex.match(line) return matcher.groupdict() # vandal vane = {} # for k, v in distill(valve, regex).items(): # if dispose.get(k, None): # vane[k] = dispose.get(k)(v) # else: # vane[k] = v # vane.setdefault(k, dispose.get(k, lambda v: v)(v)) vane = {k: dispose.get(k, lambda v: v)(v) for k, v in distill(valve, regex).items()} print(vane)





import random, datetime def semen(): while True: yield {'value': random.randrange(1, 100, 2), 'datetime': datetime.datetime.now()} germ = semen() items = [next(germ) for _ in range(3)] def handler(iterable): valor = [item['value'] for item in iterable] return sum(valor) / len(valor) print(items) print(f'{handler(items):.2f}')
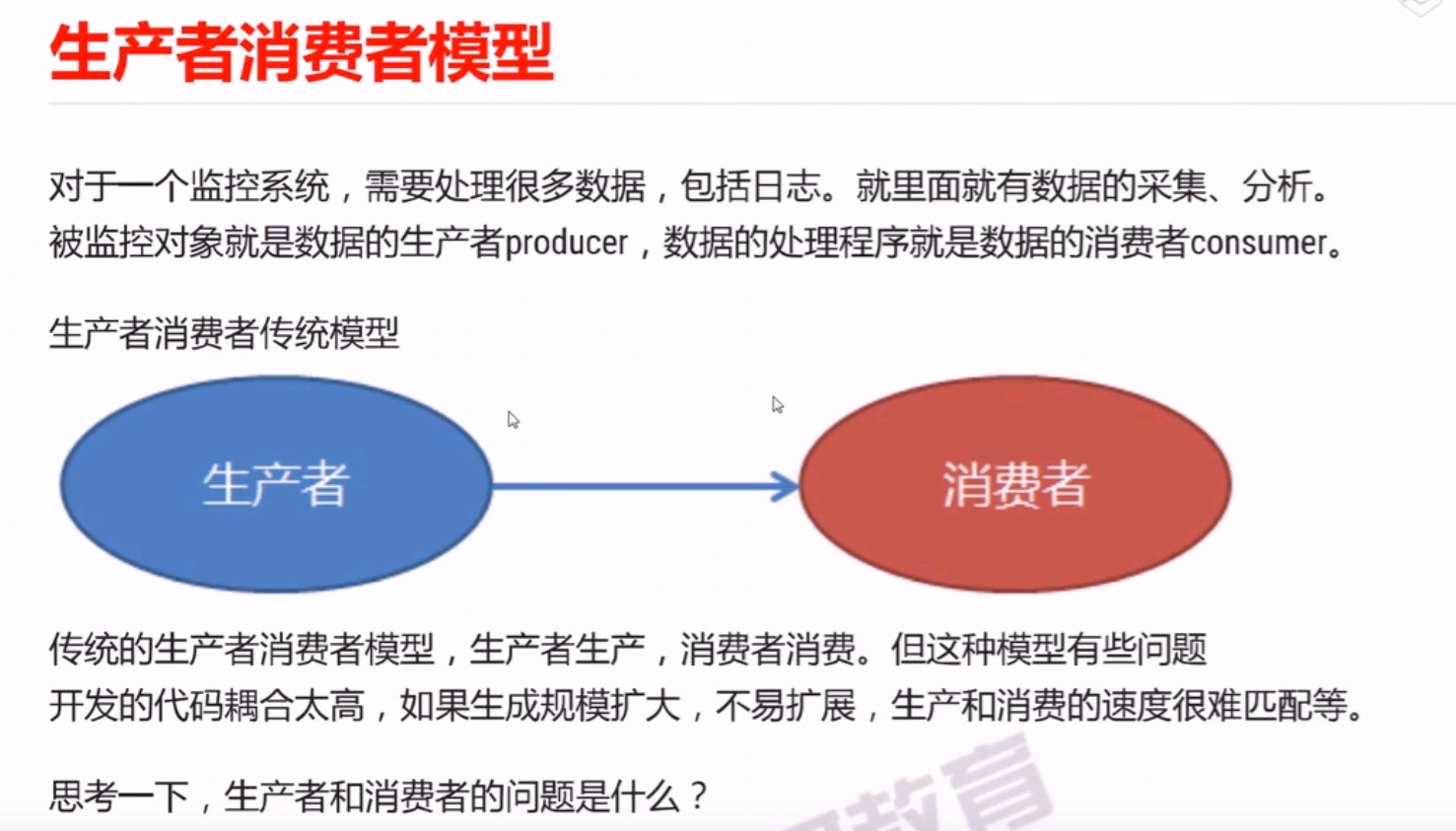
import random, datetime import time class UTC(datetime.tzinfo): def __init__(self, offset): self.__offset = offset def utcoffset(self, dt: datetime.datetime) -> datetime.timedelta: return datetime.timedelta(hours = self.__offset) def tzname(self, dt: datetime.datetime) -> str: return f'UTC+{self.__offset}' def dst(self, dt: datetime.datetime) -> datetime.timedelta: return datetime.timedelta(hours = self.__offset) def semen(): while True: yield {'value': random.randrange(1, 100, 2), 'datetime': datetime.datetime.now(UTC(8))} time.sleep(1) germ = semen() items = [next(germ) for _ in range(3)] def handler(iterable): valor = [item['value'] for item in iterable] return sum(valor) / len(valor) # print(items) # # print(f'{handler(items):.2f}') def window(semen, handler: callable, width: int, interval: int): """ 窗口函数 :param semen: data source, generator :param handler: deal data :param width: 数据窗口宽度 :param interval: 处理时间间隔 :return: """ start = datetime.datetime.strptime('2021-1-1 0:0:0 +0800', '%Y-%m-%d %H:%M:%S %z') current = start buffer = [] # 窗口中待计算数据 delta = datetime.timedelta(seconds = width - interval) while True: data = next(semen) if data: buffer.append(data) current = data['datetime'] if (current - start).total_seconds() >= interval: ret = handler(buffer) print(f'{ret:.2f}') buffer = [data for data in buffer if data['datetime'] > current - delta] start = current window(germ, handler, 5, 3)
import re, datetime valve = '''51.222.253.18 - - [02/Mar/2022:02:30:16 +0800] "GET /robots.txt HTTP/1.1" 301 169 "-" "Mozilla/5.0 (compatible; AhrefsBot/7.0; +http://ahrefs.com/robot/)" "(" ''' pattern = r'(?P<remote>[\d\.]{7,}) - - \[(?P<datetime>[^\[\]]+)\] "(?P<request>[^"]+)" (?P<status>\d+) (?P<size>\d+) "(?P<referer>[^"]+)" "(?P<useragent>[^"]+)" "(?P<x_forwarded_for>[^"]+)"' regex = re.compile(pattern, flags = re.M) dispose = { 'datetime': lambda time: datetime.datetime.strptime(time, '%d/%b/%Y:%H:%M:%S %z'), 'request': lambda request: dict(zip(('method', 'url', 'protocol'), request.split())), 'status': int, 'size': int } def distill(line, regex: re.Pattern): matcher = regex.match(line) if matcher: return {k: dispose.get(k, lambda v: v)(v) for k, v in matcher.groupdict().items()} else: return {} def vandal(file): with open(file = file, mode = 'r+t', encoding = 'utf8') as f: for line in f: d = distill(line, regex) if d: yield d else: print(f'unqualified line {line}') # for d in vandal('valour.log'): # print(d) # # print(distill(valve, regex)) def window(semen, handler: callable, width: int, interval: int): """ 窗口函数 :param semen: data source, generator :param handler: deal data :param width: 数据窗口宽度 :param interval: 处理时间间隔 :return: """ start = datetime.datetime.strptime('2021-1-1 0:0:0 +0800', '%Y-%m-%d %H:%M:%S %z') current = start buffer = [] # 窗口中待计算数据 delta = datetime.timedelta(seconds = width - interval) while True: data = next(semen) if data: buffer.append(data) current = data['datetime'] if (current - start).total_seconds() >= interval: ret = handler(buffer) print(f'{ret:.2f}') buffer = [data for data in buffer if data['datetime'] > current - delta] start = current
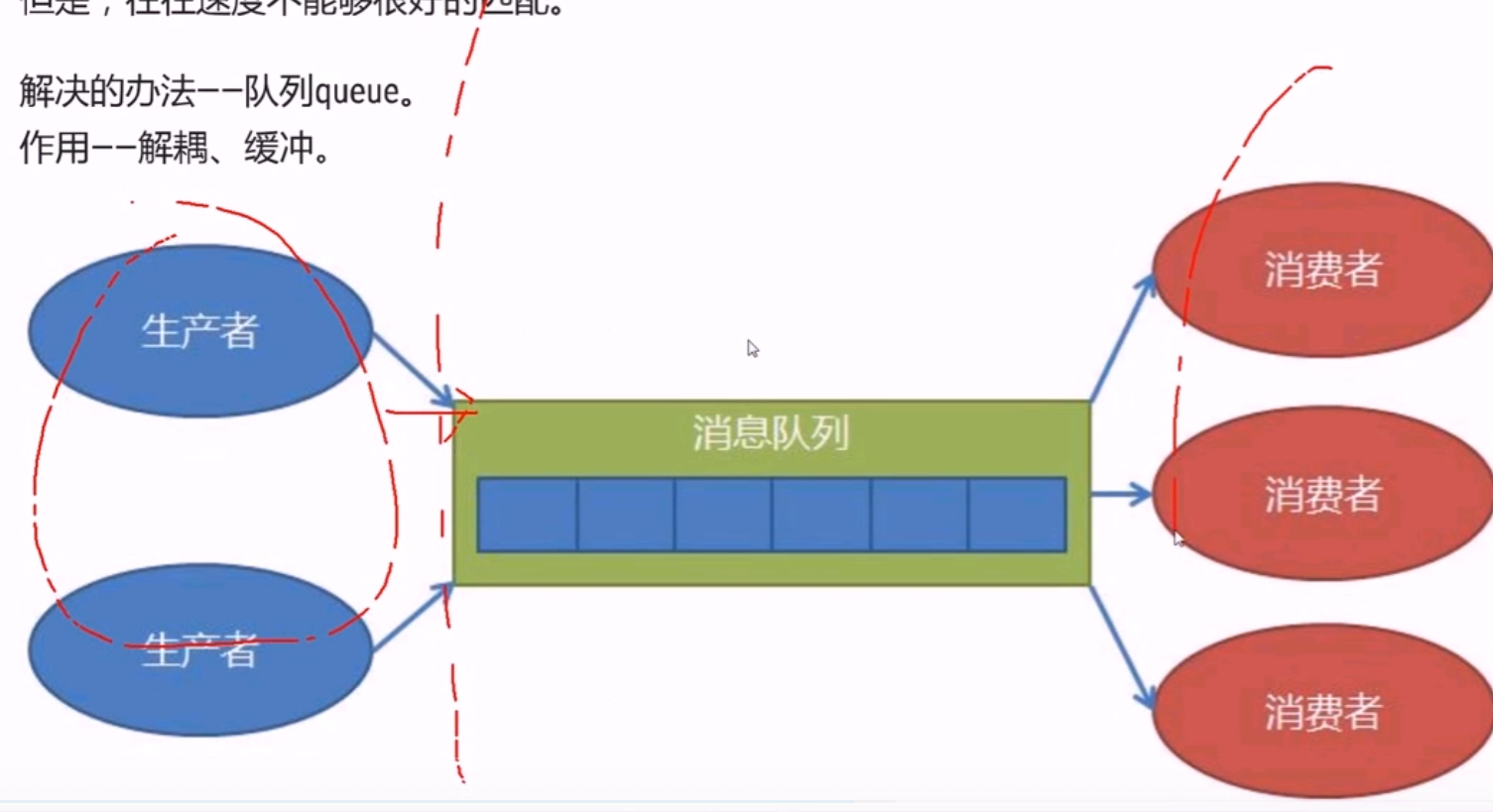


from queue import Queue import random q = Queue(maxsize = 0) q.put(random.randint(1, 100)) q.put(random.randint(1, 100)) print(q.get()) print(q.get()) # print(q.get()) print(q.get(block=True,timeout=2))


相关文章
- Python脚本扫描给定网段的MAC地址表(scapy或 python-nmap)
- Python基础入门知识
- python安装python-lzf包,报错lzf_module.c:3:20: fatal error: Python.h: No such file or directory
- How to run python interactive in current file's directory in Visual Studio Code? Python路径问题
- 【华为OD机试真题 python】最长的指定瑕疵度的元音子串 【2022 Q4 | 200分】
- 【华为OD机试真题 python】 翻牌求最大分【2022 Q4 | 100分】
- 【零基础学python】:清华官方出品的《看漫画学Python》全彩PDF,495页资源分享
- 中途转行python?怎么学?没有基础的我30了自学Python转行靠谱吗?
- python强大之处在哪里?为什么那么多人喜欢Python?
- 零基础自学Python需要多长时间从入门到精通?学python能兼职挣钱吗?怎么挣钱?
- 57 python - 异常
- python sys模块详解
- 《Python树莓派编程》——1.5 连接外围设备
- 20220721 python for循环学习
- Python中python-nmap模块的使用
- 【Python】【日志】log/logging
- 【Python】【PyPI】twine模块打包python项目上传pypi
- 基于Python+sqlite3实现(Web)图书管理系统【100010049】
- Python数据可视化 Pyecharts 制作 Scatter3D 3D散点图
- 华为OD机试 - 时间格式化(Python) | 机试题+算法思路+考点+代码解析 【2023】
- [Spark][python]从 web log 中提取出 UserID 作为key 值,形成新的 RDD
- 小学生python游戏编程arcade----坦克大战2
- Python 基础 之 Ubuntu 上安装 python 和 python-pip
- Unity 工具 之 报错 Jenkins 执行/调用 Python 脚本,报错提示 ‘python‘ 不是内部或外部命令,也不是可运行的程序或批处理文件
- 【Python注意事项】如何理解python中间generator functions和yield表情
- 【python百度智能云】:Python — 三种获取__VIEWSTATE、__VIEWSTATEGENERATOR、__EVENTVALIDATION方法。
- 【图像处理】——求解LBP特征Python