
深入剖析行溢出的存储结构
1什么时候触发行溢出
SQL Server的行溢出数据只会发生在变长字段上,变长列的长度不能超过标准变长列最大值8000个字节的限制,而且还要满足:
包括行头系统信息和所有定长列和变长系统信息的所有长度不能超过8060字节,要想存储8000字节以上的数据,应该使用LOB(text、ntext或者image)或者MAX数据类型;
变长列的实际长度一定要超过24个字节(因为行溢出需要额外的24个字节行溢出指针,如果变长字段值不超过24个字节,完全没有必要把它作为行溢出数据存储);
变长列不能是聚集索引键的一部分(如果行溢出是聚集索引键的一部分,那么表的查询性能会是一个噩梦);
2行溢出的存储结构
为了了解Overflow的结构,我们创建表HeapPage_Overflow,并插入测试数据:

查看这行记录对于Page的内容:
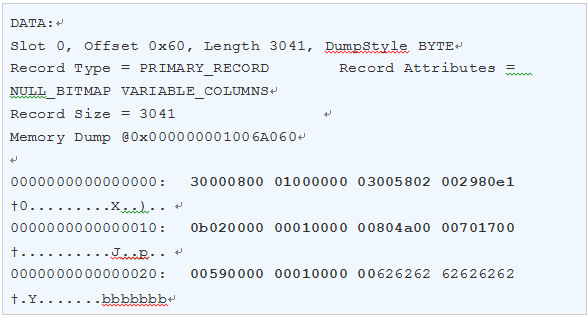
上面Page数据中的一行记录可以格式化为下图所示:

图1:堆表HeapPage_Overflow记录结构
其中几个重要部分结构解释如下:
0x2980这是包含后面指向存储行溢出的变长字段偏移量。把0x2980逆序成0x8029,再把0x8029转换为二进制1000000000101001,去除高2位(也就是粗体部分),取101001,转换为十进制就是41,高2位的目的其实只是一个标识,为了跟普通记录的变长字段偏移量进行区分。
第一个变长字段偏移量41是由17个字节系统信息加上24个字节的行溢出指针共同组成,计算公式为:41=17+24,下面对这24个字节的行溢出指针进行结构分析:
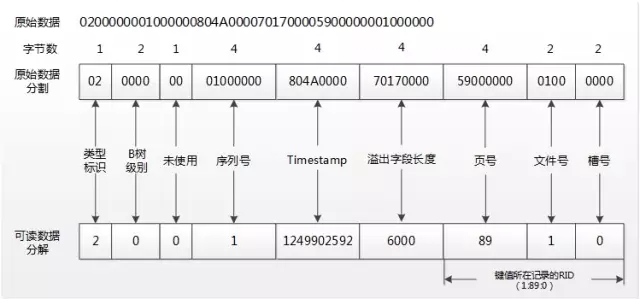
图2:堆表HeapPage_Overflow的行溢出指针结构
0x0000,表示B树中的层级,行溢出的记录,这个值为始终为0,在LOB记录的ROOT记录中这个值为0x0100;
0x01000000,一个序列号,每次行溢出或LOB数据被更新时这个值加1,并在乐观并发控制为游标使用;
0x804A0000,Timestamp值,用于使用DBCC CHECKTABLE检查表索引、行内、LOB 以及行溢出数据页是否已正确链接。在LOB的行内数据、LOB的ROOT指针以及存储LOB的数据结构中都存储了这个值,而且他们的值都是一样的。0x804A0000逆序之后是0x0004A80,再向0x0004A80后面追加4个0得到0x0004A800000,转换为十进制为1249902592;要验证这个标识值的算法,可以使用工具Winhex修改0x804A0000值并使用DBCC PAGE(Overflow,1,93,3) 查看Timestamp值。
0x70170000,溢出字段长度,0x70170000逆序之后是0x00001770,用十进制表示是6000,这个跟前面插入记录时字段的大小完全吻合;
0x5900000001000000表示一个8个字节的RID地址,指向行溢出字段VarCol存储6000字节所在数据页的RID地址为:(1:89:0)。
上面已经分析了在行内数据中存储的行溢出指针的结构,接下来将分析存储行溢出数据的物理结构。
查看行溢出存储Page的内容: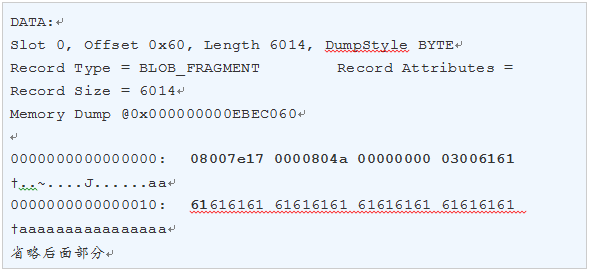
上面Page数据中的一行记录可以格式化为下图所示:
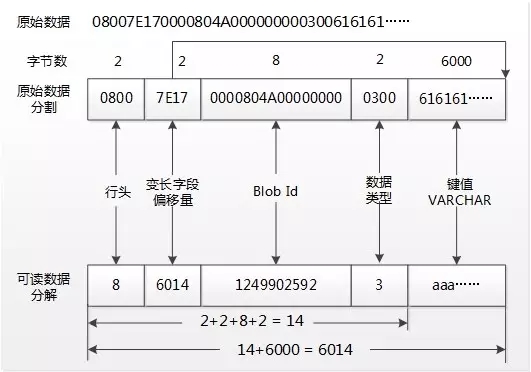
图3:堆表HeapPage_Overflow的行溢出数据结构
0x0800是这一行记录的行头数据,分解为Byte#0的十六进制是0x08和Byte#1的十六进制是0x00,0x08转换为二进制是:00001000,各个bit表示的含义如下:
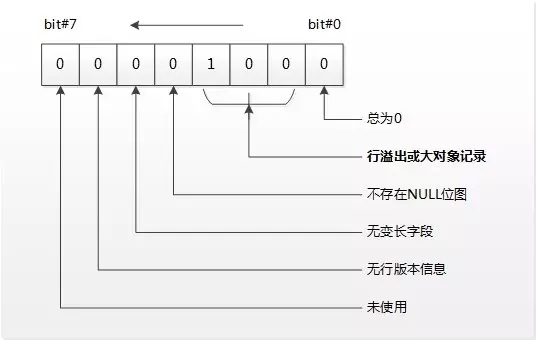
图4:堆表HeapPage_Overflow的行溢出行头结构
0x7E17是变长偏移量,经过逆序之后是0x177E,用十进制表示是6014,这个偏移量包含了14个字节的行溢出系统数据和6000个字节的行溢出字段值;
0x0000804A00000000是Blob Id值,跟IN_ROW_DATA记录中24个字节的行溢出指针的Timestamp值是相等的。要验证这个标识值的算法,可以使用工具Winhex修改0x0000804A00000000的值并使用DBCC PAGE(Overflow,1,89,3)查看这个Blob Id值。如果不相等,虽然SELECT一样能查询数据,但是在进行DBCC CHECKDB将会报引用不匹配的错误信息。
0x0300是数据类型,转换为十进制是3,Type=3表示DATA,即表示这行记录是用于存储数据的。
3行溢出的整体逻辑结构图
根据上面对行记录存储结构的分析,行溢出的逻辑可以通过下面的图来表示:
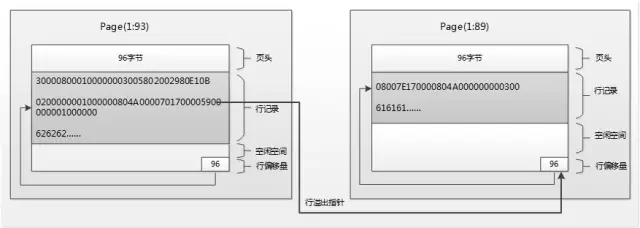
图5:堆表HeapPage_Forward第一行记录行溢出后的存储结构示意图
4总结上文以堆表的行溢出数据为例讲解它的存储结构,从结构来看一行记录的存储跨越了两个Page,相比于一条记录存储在一个Page里,查询的时候增加了1个IO,当表比较大的时候,随机IO将会猛增,将会出现性能上的问题,一般建议控制好变长字段的大小,或者使用其它数据类型避免行溢出,也可以考虑表的垂直拆分。
更多关于SQL Server存储结构请参考《SQL Server性能调优实战》
作者介绍:陈畅亮
微软SQL Server方向最有价值专家(MVP),《SQL Server性能调优实战》作者,《Windows PowerShell实战指南(第2版)》译者。
【每日一题Day42】最大频率栈 | 哈希表+大顶堆 哈希表+栈 思路:在本题中,每次需要优先弹出频率最大的元素,如果频率最大元素有多个,则优先弹出靠近栈顶的元素。因此,我们可以考虑将栈序列分解为多个频率不同的栈序列,每个栈维护同一频率的元素。当元素入栈时频率增加,将元素加入到更高频率的栈中,低频率栈中的元素不需要出栈。当元素出栈时,将频率最高的栈的栈顶元素出栈即可。
相关文章
- 【存储】如何计算IOPS ?
- 数据存储之第三方FMDB优化
- Centos7.4安装openstack(queens)详细安装部署(七)块存储服务
- Android 数据存储(XML解析)
- Qt音视频开发9-ffmpeg录像存储
- Sql Server 存储过程基础
- Sql Server 存储过程基础
- Atitit mysql存储过程编写指南 1. 定义变量1 1.1. 变量名以@开头用户变量 会话变量1 1.2. 以declare关键字声明 存储过程变量2 1.3. @是用户自定义变量,
- BigData之Hadoop:Hadoop框架(分布式系统基础架构)的简介(两大核心【HDFS存储和MapReduce计算】)、深入理解、下载、案例应用之详细攻略
- 原生js本地存储、获取、删除、清空
- 一文详解RocketMQ的存储模型
- PyTorch存储和加载模型并查看参数,load_state_dict(),state_dict() + 使用多张GPU进行训练以及推理调用模型
- 【C++学习笔记】存储类
- 冰河,能不能讲讲如何实现MySQL数据存储的无限扩容?
- 初识Hadoop,轻松应对海量数据存储与分析所带来的挑战