
复盘:手推LR(逻辑回归logistics regression),它和线性回归linear regression的区别是啥
复盘:手推LR(逻辑回归logistics regression),它和线性回归linear regression的区别是啥?
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
面试官:请你手推LR,它的梯度是啥?
我们首先会介绍一个函数,也就是我们sigmoid的函数,
有些场景下,也会叫logistic函数,
这个函数其实非常简单,也就是我们这张图,
输入是X,然后,我们有个参数theta,
我们的输入,做了一下加权求和theta*x
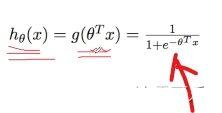
这个是什么样的,我们说它是个典型的一个S型的一个图像,对?这图像有什么特点?
首先,就在原点零的情况?我们说可以往这画对,零,它其实对应的,是等于0.5
可以把零带进去是什么?E的零次方是等于1的,
整体也就是1/2
也就是说我们在原点的时候的话,它是等于0.5,
那么如果随着我们横轴,X轴往右一直是趋向于正无穷大的时候,你这个函数是什么趋向于一的。
也就是说,这个theta乘以X是趋向于无穷大,
那么负C大X趋向负无穷大,
e的负无穷大是等于什么是等于0的,
那么一加零,就等于一和1/1?
总之函数长下面这样
就是说它的值域,是在零到一之间的。
还有是什么?还有就是说它是一个平滑的,对不对,
平滑就方便什么,方便我们做,求微分,
或者说要求导对?
这个函数的一个导数,有一个非常好的一个结果,大家可以去求一下,下图我画出来了
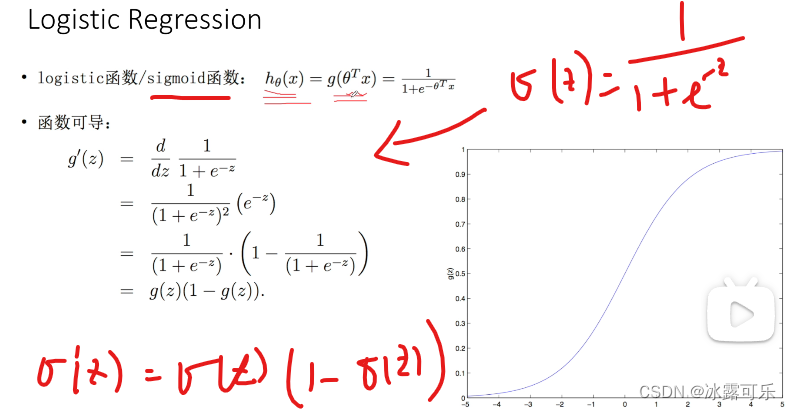
求得的会发现这个函数的导数,就是等于原先的值乘以一减去原先的值,
也就是说它的导数,非常容易求,很简单,
线性回归linear regression的话,直接是说一个线性函数,直接把它值输出了,

我们现在logistics regression干啥呢?把y做了一个非线性变换,
那么这个非线性变换拿到这样的一个值相当于什么?
相当于把它压缩到零到一之间,那么压缩到零到一之间,又有什么特点?
因为我们说概率一个元素,它的概率的值是零到一的。
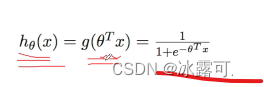
所以我们可以近似的把这个函数的值域表示成什么?表示成一个概率,
或者说它表示,我们就可以把它近似的看成是一个概率,它主观就是概率的一个定义,对不对?
这个时候我们说我们再来重新的看一下我们这个函数,
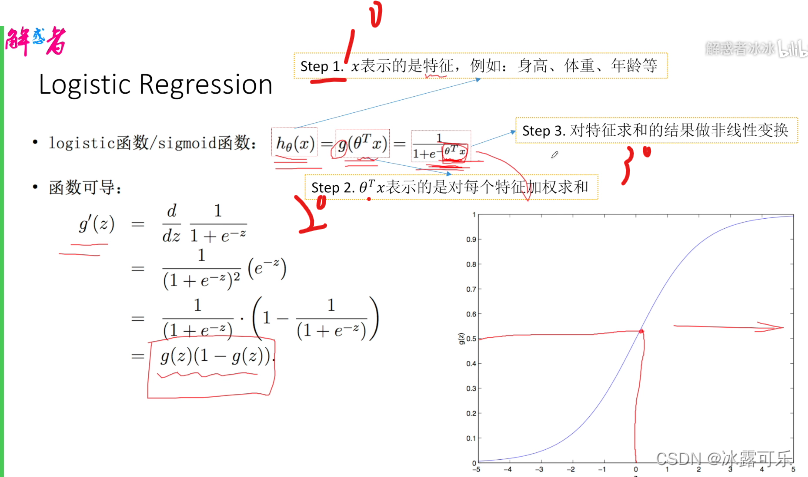
首先,我们说这个函数,对我们原始的输入,就是X,就是我们的特征,
然后我们身高体重等等值得你关注的目标是相关的一些特征
首先对每个特征做一下价值求和,做完加权求和之后,我们就拿到了汇总
线性回归拿到的一个值,然后对这个值做一下非线性变换,
压缩到零到一之间,已使得这个零到之间的值,能够表示成概率。
LR的典型应用场景:二分类
那么我们说这个LR的一个典型的一个场景,就是我们一个二分类的一个任务,
我输入我们的一个X,我们希望它输出是零或者是一,
那么我们对应到我们的LR模型,它用到了sigmoid函数

首先,我们对我们抽取出来的特征做一个线性变换,
就就直接是对我们加权求和,
再经过一个logistics函数,映射到零到一之间,就认为它是个概率,
我们再加上这个概率的值,与我们的一个阈值0.5进行比较,
那如果大于这个值,我们认为它就是一
小于我们的阈值0.5,认为它就是零,
这样的话,就能够得到我们的一个标签,
也就是说我们的这样的一个变化,
如果为一的概率,是大于0.5的,我们认为什么为一
如果小于0.5个,概率是零
就能够把它标记设置成零,
这个就是我们的一个函数。
经过y预测为1或者0的表达式各种转化

我们说一个更简便的方式,如上图
也就是说,我不管你的样本是等于Y是等于几,我都可以用这种方式来表示。
现在,假设我们有m个样本,训练样本是独立的,
我假设M的训练样本是独立的,
那么你需要解释每一个样本出现的概率
也就是说在X给定的情况下,我们的Y指定的概率是多少,
就等于它的一个乘积,对不对?【上图】
说白了我们就要求theta
使得上面L(theta)这个最大似然函数尽可能的大
相当于逼迫y_predict=y_groundtruth
但是直接求还不好求,我们讲L取对数吧

连乘变累加和
咋求l最大值呢,不就是对theta求导数吗?

经过我文章开头求过的sigmoid的函数的导数公式
各种化简,求到,整理
最后得到了梯度时间上很简单
即使(y-y_predict)*x
y就是真实值,标签
ypredict就是咱们LR模型输出的值
x是训练样本,梯度一出来
更新theta岂不就是很简单
这样就用梯度下降法,将LR的参数theta优化好了
LR就手动推导完成!!!
面试官常问的问题哦这可是
总结
提示:重要经验:
1)LR是线性回归用sigmoid激活之后的概率,线性回归是线性回归问题,而逻辑回归是二分类问题,sigmoid求到很重要,另外,LR的最大似然函数求到很重要
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
相关文章
- 获取所有逻辑磁盘目录
- mysql 重新整理——逻辑架构[二]
- SAP CRM系统里文本决定的二次执行逻辑调试
- SAP CRM Attachment 数据物理存放的逻辑
- CRM One order里user status和system status的mapping逻辑
- SAP S/4HANA的扩展字段的渲染逻辑
- SAP Spartacus 2.1.0 加载homepage的逻辑
- 云小课|打造企业数据“高内聚,低耦合”--试试GaussDB(DWS)逻辑集群,实现数据物理隔离
- Verilog 逻辑与(&&)、按位与(&)、逻辑或(||)、按位或(|)、等于(==)、全等(===)的区别
- shell之逻辑判断&&和-a区别(八)