
GPGPU&&渲染GPU的工作原理和认知总结
GPGPU代表general purpose computing on graphics procesing unit,就是“图形处理器通用计算技术”。这种新型的加速技术试图把个人计算机上的显卡当作CPU这样的通用处理器来用,使显卡的强劲动力不仅仅发挥在图形处理上。从2009年开始,利用显卡进行计算已经渐成主流。
GPU的工作过程,它从CPU处获得三维模型,这些模型是用顶点坐标和色彩信息组成的,GPU对这些顶点的位置进行一系列的变换,然后投影到帧缓存上。投影的同时,GPU根据显示其的大小和分辨率对投影结果进行裁减,光栅化,每个帧缓存里的像素或者像素多边形的色彩经过GPU的一系列变换,最后的结果被GPU输出到显示器上。
GPU在计算机中的位置:

这一系列的工作是先后有序,不可颠倒的,前面步骤的输出是后面步骤的输入,这一连串的图形处理任务被成为图形流水线,图形流水线的入口是顶点坐标和颜色信息,输出是一帧适合当前显示器显示的图像,流水线以较高的频率工作(高于显示器的刷新频率),期间不断有数据从中流过,同时连续的一帧帧图像被输出到显示器上。
应用程序输入GPU的是三维的点云数据,从流水线输入端直到顶点着色器,流水线计算的对象都是三维几何模型,从光栅化器开始,所有操作都帧度二维像素了。

1.在计算机科学史上,某个算法一旦被设计出来就会被持续不断的改进,来达到更高的直行效率,一般来说,某个算法若在改进后比原来快了20%或者50%,就会被认为是个显著的贡献,并有机会发表在学术论文中。但显著改进某个算法的性能绝非易事,除了要深入了解算法的内涵,还要求算法设计者有较深厚的理论基础和很强的创新能力。
2.2004年之后,CPU发展已经告别了主频时代,单核CPU的性能自此之后很难靠提高主频来提高性能。然而依靠重新设计算法来显著提高程序的运行效率是一项艰巨的脑力劳动,且成效较为有限。所以,为了充分利用CPU的计算资源,越来越多的算法被重新设计成并行结构,以适应多核CPU架构,但是,和主频一样,多核CPU的核心数目也受到各种因素的限制,比如成本,散热灯技术难题。
3.专用硬件相对于软件的优势仅仅是速度,但速度至关重要,要使用GPU做并行计算,就要保证并行计算算法满足几个条件,首先每个线程的任务互不相关,其次,每个线程执行相同的指令。与之相应,具有以下特点的算法能够在GPU上达到最高的直行效率,首先每个数据(数据包)都需要经过相同的流程来处理,其次数据之间没有相干性,即某些数据的计算不依赖于另一些数据的计算结果,最后,数据量庞大。需要注意的事,以上的要求都是针对局部算法而言的,比如,算法中的一步操作,一个循环语句等等,并不要求整个程序都满足线程的不相干性和指令一致性,一个完整的程序可以是由多个满足以上条件的部分接合起来的,而对程序全剧的控制和个部分的协调可以放在CPU上完成,这也就是所谓的异构并行计算。也就是说,计算资源含有多个不同的处理器,比如由GPU,CPU,甚至还有其他的处理器比如NPU,组成的处理器阵列,而GPGPU的计算过程是由CPU和GPU等共同完成的,开发人员可以将算法复杂的,要求精度高的数据量小的部分交给CPU,而将算法枯燥的,对精度要求不是很高的,数据量庞大的部分交给GPU来完成。CPU擅长逻辑,GPU和其它加速器针对某个特定算法进行算法加速。
CPU是图灵完备的,但是GPU不要求是图灵完备的。对CPU来说,图灵完备是必要条件,但不是充分条件。但是对于GPU来说,图灵完备既不充分也不必要。

doorbell机制
GPGPU的编程模型如下图所示,在第二阶段,主机将设备计算所需要的数据以packet的形式传递到GPU和CPU共享的ringbuffer之中,并通过某种手段同志GPU去执行。
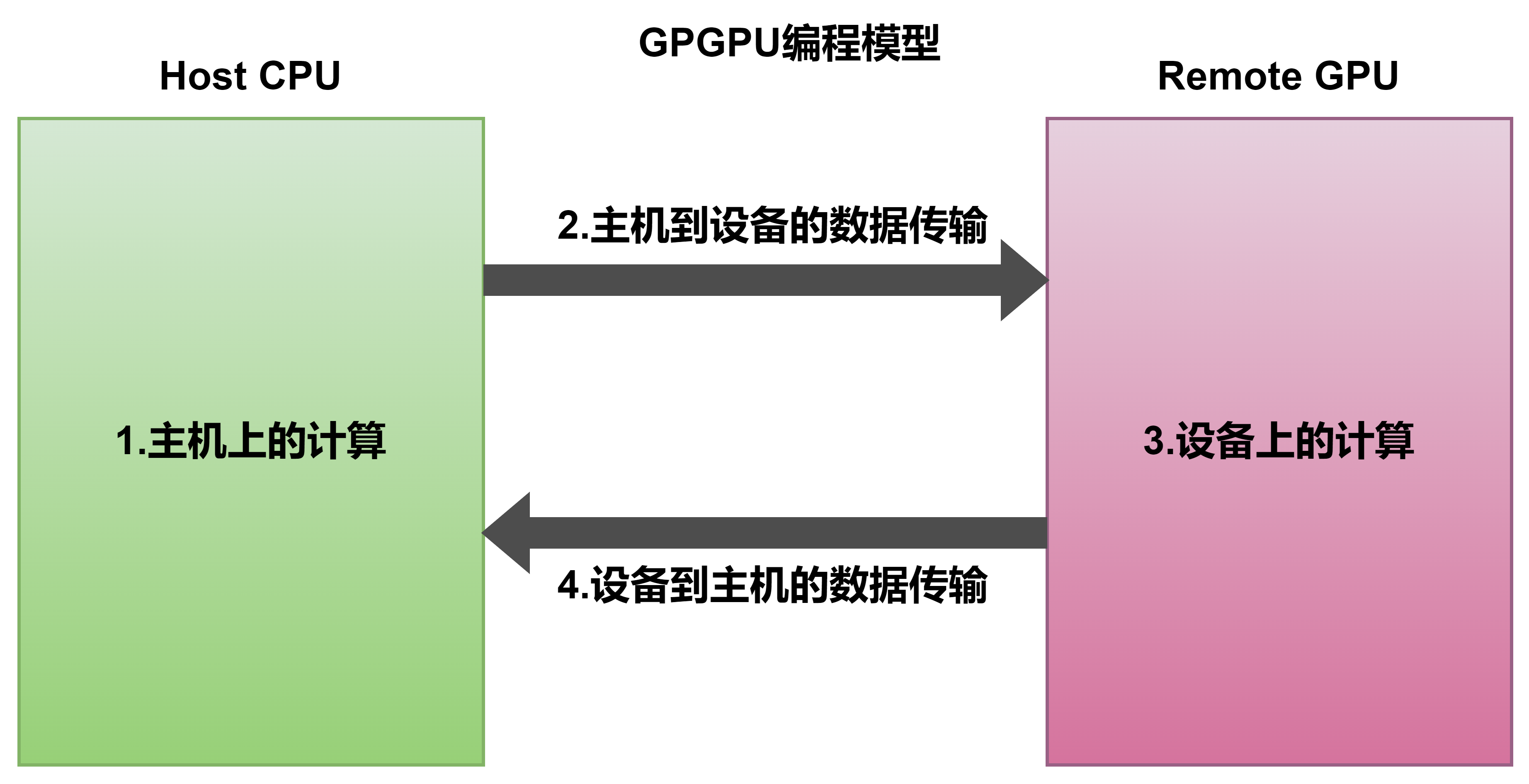
为了提高效率,通常通知GPU执行采用的机制为doorbell, HOST CPU会写command queue对应的 PCIe BAR空间的doorbell寄存器,一个驱动在多次将请求入队ringbuffer后产生一次doorbell。类似于家庭中的门铃。
Wikipedia上的解释:
in a push button analogy applied to computer systems, the term doorbell or doorbell interrupt is often used to describe a mechanism whereby a software system can signal or notify a computer hardware device that there is some work to be done. Typically, the software system will place data in some well-known and mutually agreed upon memory locations, and “ring the doorbell” by writing to a different memory location. This different memory location is often called the doorbell region, and there may even be multiple doorbells serving different purposes in this region. It is this act of writing to the doorbell region of memory that “rings the bell” and notifies the hardware device that the data are ready and waiting. The hardware device would now know that the data are valid and can be acted upon. It would typically write the data to a hard disk drive, or send them over a network, or encrypt them, etc.For GPGPU, it will push gpu to work for compute.
The term doorbell interrupt is usually a misnomer. It is similar to an interrupt, because it causes some work to be done by the device; however, the doorbell region is sometimes implemented as a polled region, sometimes the doorbell region writes through to physical device registers, and sometimes the doorbell region is hardwired directly to physical device registers. When either writing through or directly to physical device registers, this may cause a real interrupt to occur at the device’s central processor unit (CPU), if it has one.
Doorbell interrupts can be compared to Message Signaled Interrupts, as they have some similarities.
门铃,就是按钮按下以后, 门内铃声想起。doorbell理解,host操作指定位置(按钮), 客户端会立即触发(响铃)
1、 比如, AMDGPU的ring buffer 同步机制, 早期是mmio操作share regs, 后来使用doorbell, 可以达到省电和快速反应
2、 而且, doorbell是bar单出, 有很多ip都可以用, 增加了可操作数量.
intel集成显卡doorbell机制的实现
intel_gvt_init_workload_scheduler->kthread_run(workload_thread,, engine, ...);
workload_thread->complete_current_workload->update_guest_context->vgpu_vreg_t(vgpu, RING_TAIL(ring_base)) = tail;vgpu_vreg_t(vgpu, RING_HEAD(ring_base)) = head;

结束
相关文章
- "Android"牵手"iOS",WP滚蛋
- "XX cannot be resolved to a type "eclipse报错及解决说明
- [Redux-Observable && Unit Testing] Use tests to verify updates to the Redux store (rxjs scheduler)
- [Web] Preload & Prefetch
- 【网址收藏】dubbo特新概念及特性、环境搭建、dubbo-monitor安装、rpc原理以及dubbo原理:框架设计、启动解析&加载配置信息、服务暴露、服务引用及调用
- UDP"打洞"原理
- [namespace]PHP命名空间的动态访问 & 使用技巧
- 16进制字符-->10进制数字
- 华为OD机试 - 太阳能板最大面积(Java & JS & Python)
- High&NewTech:重磅!来自深度学习的三位大牛Yoshua、Hinton、LeCun荣获2018年图灵奖
- sql中datetime日期类型字段比较(mysql&oracle)
- 【nodejs原理&源码赏析(5)】net模块与通讯的实现
- 【nodejs原理&源码赏析(7)】【译】Node.js中的事件循环,定时器和process.nextTick
- JAVA中&&和&、||和|的区别?
- JUC并行计算框架 Fork/Join 原理图文详解&代码示例
- [1] MVC & MVP &MVVM
- 10gocm->session5->数据库管理实验->GC资源管理器的资源消耗组介绍
- 【课程分享】ASP.NET MVC5&微信公众平台整合开发实战(响应式布局、JQuery Mobile,Windows Azure、微信核心开发)
- 0x08 MySQL 超详细-索引原理&慢查询优化【转-多图】(重点)
- 黑马day15 文件上传&apche的工具包
- HDU 1164 Eddy's research I【素数筛选法】
- Kali 2023年最新版下载安装最全流程&功能介绍(内附安装包)
- 关系数据库——关系操作&&关系模型的完整性
- [spring学习]11、AOP使用,注解&xml配置
- 每日一练2——排序问题(Python&C语言实现)