
复盘:Batch Normalization 和 Dropout在训练和测试的不同
复盘:Batch Normalization 的均值和方差数量, Dropout在训练和测试的不同
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
面试问:Batch Normalization 和 Dropout在训练和测试的不同
batch normalization
训练和测试的参数是否一致?
不一致!
对于BN,训练的时候是对每一批数据操作,所以用到的均值方差都是一批的。
而测试的时候,没有一批的概念,这时候的均值和方差用到的是全量训练数据的,这些都是在训练时保存下来的
BN中均值 方差 训练不用全局的原因?
在训练的第一个完整epoch过程中是无法得到输入层之外其他层全量训练集的均值和方差,只能在前向传播过程中获取已训练batch的均值和方差。
每一批数据的均值、方差都会有差别,会增加模型的鲁棒性
Batch Normalization 的均值和方差数量
将输入的图像shape记为[N, C, W, H]
batchNorm是在batch上,对CHW做归一化,对小batchsize效果不好;
相当于有多少batch,就有多少组待计算均值和方差数据,
因为是在Batch上进行的,均值的维度应该为CWH
def Batchnorm(x, gamma, beta, bn_param):
# x_shape:[B, C, H, W]
running_mean = bn_param['running_mean']
running_var = bn_param['running_var']
results = 0.
eps = 1e-5
x_mean = np.mean(x, axis=0, keepdims=True)
x_var = np.var(x, axis=0, keepdims=True0)
x_normalized = (x - x_mean) / np.sqrt(x_var + eps)
results = gamma * x_normalized + beta
# 因为在测试时是单个图片测试,这里保留训练时的均值和方差,用在后面测试时用
running_mean = momentum * running_mean + (1 - momentum) * x_mean
running_var = momentum * running_var + (1 - momentum) * x_var
bn_param['running_mean'] = running_mean
bn_param['running_var'] = running_var
return results, bn_param
在batchsize上
对比:
layerNorm在通道方向上,对CHW归一化,主要对RNN作用明显;
相当于有多少个channel,就有多少组待计算均值和方差数据,
均值的维度应该为NWH
instanceNorm在图像像素上,对HW做归一化,用在风格化迁移;
相当于有N*C组待计算均值和方差数据,均值的维度应该为W*H
GroupNorm将channel分组,然后再做归一化;
相当于有N*G组待计算均值和方差数据,
其中G为group数,均值的维度应该为(N*C//G)WH
dropout
Dropout就是:我们在前向传播的时候,让某个神经元的激活值以一定的概率p停止工作,这样可以使模型泛化性更强,因为它不会太依赖某些局部的特征。
训练阶段
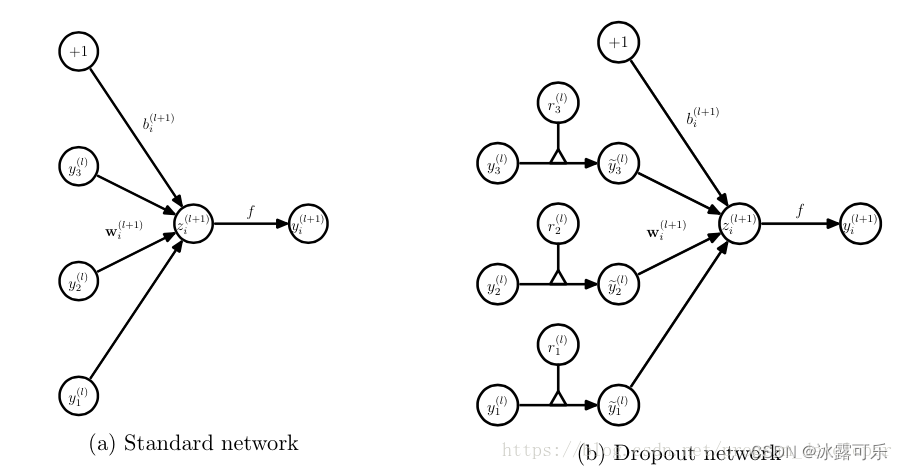
没有Dropout的网络计算公式:全部输出
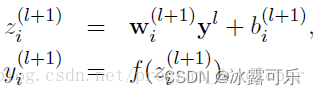
加一个概率则:
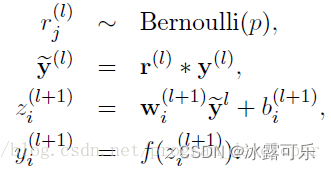
上面公式中Bernoulli函数是为了生成概率r向量,也就是随机生成一个0、1的向量。
代码层面实现让某个神经元以概率p停止工作,
其实就是让它的激活函数值以概率p变为0。
比如我们某一层网络神经元的个数为1000个,其激活函数输出值为y1、y2、y3、…、y1000,我们dropout比率选择0.4,
那么这一层神经元经过dropout后,1000个神经元中会有大约400个的值被置为0。
注意: 经过上面屏蔽掉某些神经元,使其激活值为0以后,
我们还需要对向量y1……y1000进行缩放,也就是乘以1/(1-p)。
如果你在训练的时候,经过置0后,没有对y1……y1000进行缩放(rescale),那么在测试的时候,就需要对权重进行缩放,操作如下。
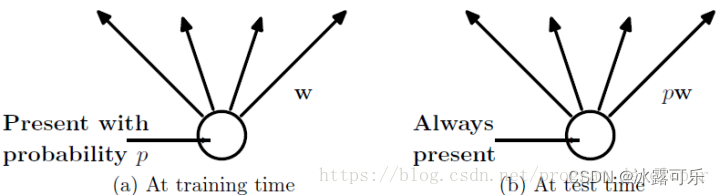
(2)在测试模型阶段
只有在训练阶段没有除(1-p)的,在测试的时候会乘P 否则不用
预测模型的时候,每一个神经单元的权重参数要乘以概率p。
测试阶段Dropout公式:

总结
提示:重要经验:
1)batchNorm是在batch上,对CHW做归一化,对小batchsize效果不好;相当于有多少batch,就有多少组待计算均值和方差数据
2)dropout是训练时没有被缩1/(1-p)的,测试扩p,BN训练时用一个批次的均值,而测试用整体均值
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
相关文章
- caffe学习系列(2):训练和测试自己的图片
- Java实现 蓝桥杯 算法训练 字符串长度(IO无敌)
- Java实现 蓝桥杯VIP 算法训练 比赛安排
- Java实现 蓝桥杯VIP 算法训练 最长字符串
- 训练集、测试集、验证集
- 训练集测试集划分 train_test_split(X, y, stratify=y)
- AI---训练集(train set) 验证集(validation set) 测试集(test set)
- 【 【henuacm2016级暑期训练】动态规划专题 G】 Palindrome pairs
- ML之FE:在特征工程/数据预处理阶段切分训练集、验证集、测试集的多种场景多种实现方法之详细攻略
- CV之NS之CycleGAN:基于apple2orange数据集利用TF框架的CycleGAN算法实现图像风格迁移/图像转换—训练&测试过程图文教程全记录
- ML之FE:数据处理—特征工程之数据集划分成训练集、验证集、测试集三部分简介、代码实现、案例应用之详细攻略
- DL之RNN:人工智能为你写歌词(林夕写给陈奕迅)——基于TF利用RNN算法实现【机器为你作词】、训练&测试过程全记录
- DL之RNN:人工智能为你写诗——基于TF利用RNN算法实现【机器为你写诗】、训练&测试过程全记录
- 为什么不使用多机训练神经网络
- 加载预训练模型解密
- MMDetection实战:MMDetection训练与测试
- 基于LSTM-RNN的深度学习网络的训练对比matlab仿真
- 受限波尔茨曼机RBM_DBN深度学习网络训练和测试matlab仿真,数据库为随机数矩阵
- sklearn中train_test_split详解(数据集划分为训练集与测试集)
- BERT预训练模型与结构原理简要介绍
- torch.dataset随机划分为训练集和测试集
- 第一周训练题汇总
- 深度学习:08 训练、测试和验证集的说明
- 语义实例分割1-02:snake(实时实例分割))-官方数据训练测试,环境搭建等
- 目标追踪00-02:FairMOT(实时追踪)-官方数据训练测试
- 人脸识别0-04:insightFace-模型训练注释详解-史上最全
- LPDDR4的训练(training)和校准(calibration)--ZQ校准(Calibration)
- 模型实战(1)之YOLOv5 实现目标检测+训练自己的数据集
- python工具方法 4 依据随机种子将数据划分为训练集、测试集、验证集
- 使用 keras 训练大规模数据