
复盘:Python内存管理&垃圾回收原理
复盘:Python内存管理&垃圾回收原理
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
Python内存管理&垃圾回收原理

不够深入?面试官会继续追问的
神奇的狗链:环状双向链表
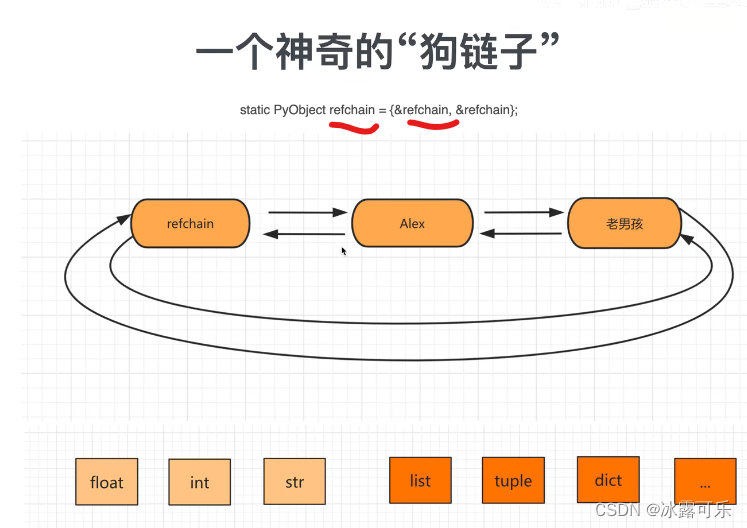
在python中的对象
都会放在refchain链表中
name='Alex'
boy = '老男孩'
age = 18
hobby = ['a','b']
python在创建对象时:每个数据都会干下面这些事情:
name=‘Alex’
内部会创建一个last指针,next指针,方便加入refchain
创建数据类型
创建引用的个数
开辟内存之后
ptr=name,这时候ptr直接指向同一块内存,叫引用
差异是:
age=18,还需要val=18
list的话,列表就还要创建items=元素
还要元素个数size,len
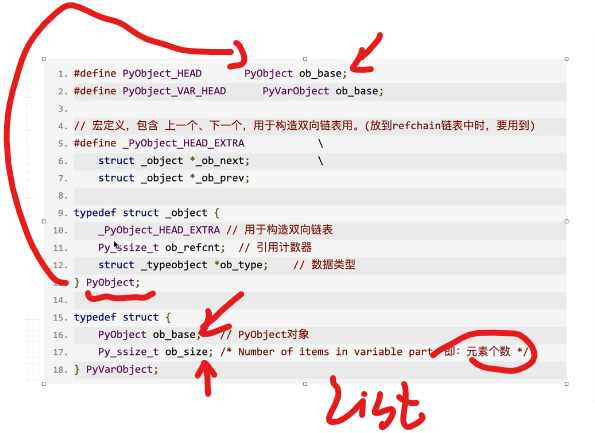
c语言源码中,是下面这么实现的??
puObject结构体,内部封装了四个值
last指针,next指针,引用计数和类型

对于list,还要一个ob_size,就是元素的个数
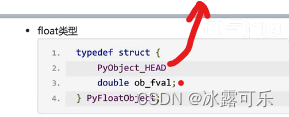
其他的数据类型怎么封装
data = 3.14
float
基础那些成员变量
再加ob_favl
实际就是

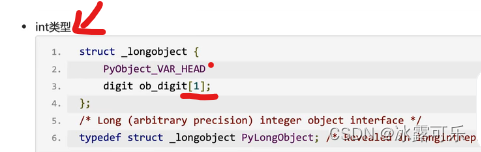
int
再如

引用计数器
基于上面那些东西来实现引用计数器
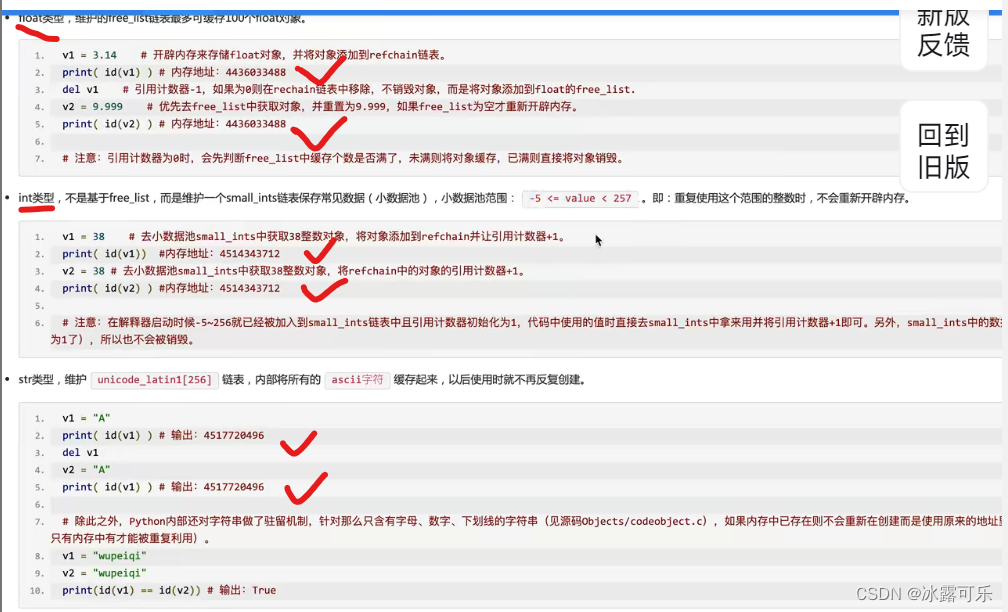
v1 = 3.14
v2 = 999
v3 = (1,2,3)
python程序运行时,根据数据类型,找到不同结构体,根据结构体来创建相关的数据
然后将对象添加到的refchain双向链表中
c源码中,有俩关键的结构体:PyObject,PyVarObject
多个元素就是Var实现的
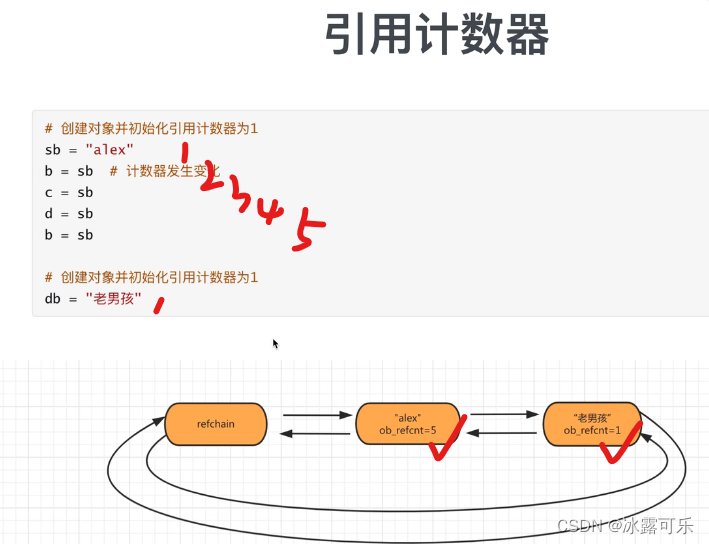
每个对象都有ob_refcnt就是引用计数器,默认为1
当有其他变量引用这个对象时,引用计数器发生变化
a = 999
b = a
b的ob_refcnt=2
当删除引用
del b
b变量干掉,同时b对象的引用计数器变1
del a
a变量干掉,同时a对象的引用计数器变0
b指向a的
当引用计数器ob_refcnt=0,说明没人用它了,它就是垃圾!!!!!!!
那就回收对象 —— 干俩建时
(1)移除链表refchain中的a对象
(2)销毁对象的内存,将内存归还给操作系统
实际上呢,也不是真的销毁,而是将其缓存起来,做别的事情
现在当做删除吧
举例,创建对象时,开始引用了,ob_refcnt=1,然后不断++
删除呢?
那就删除呗
它有个bug!!!
循环引用的问题
比如
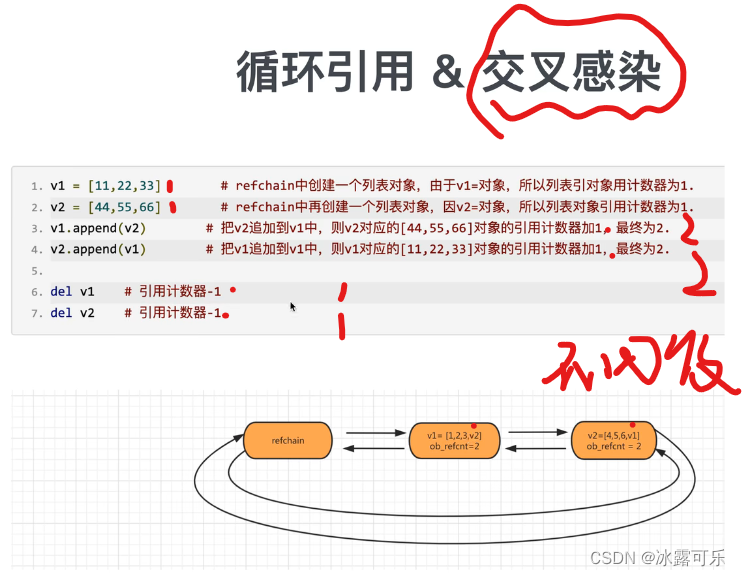
今后不再使用v1,v2
如果这些代码太多,内存慢慢慢慢滴满了,炸了就行
最后你的电脑卡死,但是重启就哦了,骚得很!!!!!!!!!
所以,python的内部,引入标记机制
python的标记机制:解决循环引用的不足产生的问题
在python的底层再去维护一个链表,空间换时间
放啥呢?
放那些可能存在循环引用的对象。
那即是那些可变对象,list,dict,tuple,set,可以改变的对象
就会再维护一个链表
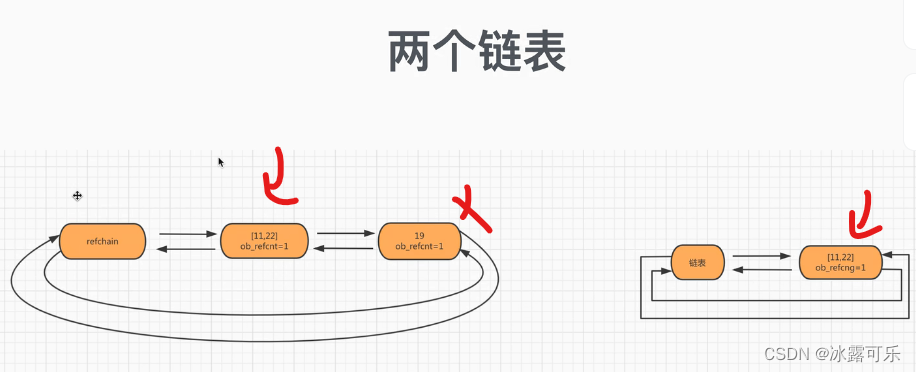
在python内部,在某种情况下,会扫描右边这个链表的每个元素,
如果存在循环引用,则让双方的引用计数器,都各自-1
如果cnt=0,就该删了,当垃圾回收
相当于提前让他们从上面那个缺陷的1–变化为0,彻底回收
问题:啥时候扫描呢???????
而且每次扫描的话,时间复杂老高了,耗费时间,这个要优化的
python的分代回收:规定新技术,将可能存在循环引用的链表分成了3个链表
分别叫做:0代,1代,2代
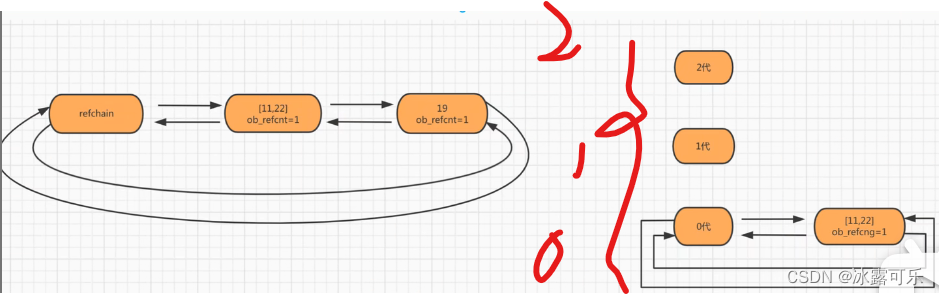
0代:0代中的对象个数达到700个,0代扫描1次
1代:0代扫描了10次,则1代扫描1次
2代:1代扫描了10次,则2代扫描1次
咋做?
0代扫描时:不是垃圾的对象,将他们全部升级放到1代,0代里面没有数据了
同理,1代升级到2代也是
懂了吧?
小结:

python内部还会继续优化源码!!!!
之所以大佬们考手撕代码,目的就是这么干的
python缓存机制
分为2大类:池,
池:避免重复的创建和销毁一些常见的对象,那就在内存维护一个池,备胎,今后再用的话,揪住直接用
v1 = 7
v2 = 9
python内部启动解释器,实际上python会提前先创建:
-5----257
这样的话,你上面那代码,不会真的创建,而是直接获取缓存区里面的东西,美滋滋
懂?
v4 = 999
这些对象时真的要创建
他们的id()
因此呢,最开始ob_refcnt=1
你再创建就相当于初始化为2,你以为是1,所以不会销毁哦
free_list机制:当你引用计数器ob_refcnt=0时,按理说该回收垃圾,但是python内部不会真的回收,而是将它加入free_list
当做缓存使用
今后啊,你再创建内存时,不要新开辟内存了
而是直接使用free_list
v1 = 3.14
del = v1
先创建,但是del的话,不会真的销毁哦
把v1放入free_list中
下次你要是再
v9 = 9.999
实际上v9指向了谁?v1,把val改为9.999
懂??刺激对吧
缓存池满了,那真的就销毁,销毁谁?最久未被使用那个对象:LRU
这就是数据结构与算法了
牛逼的
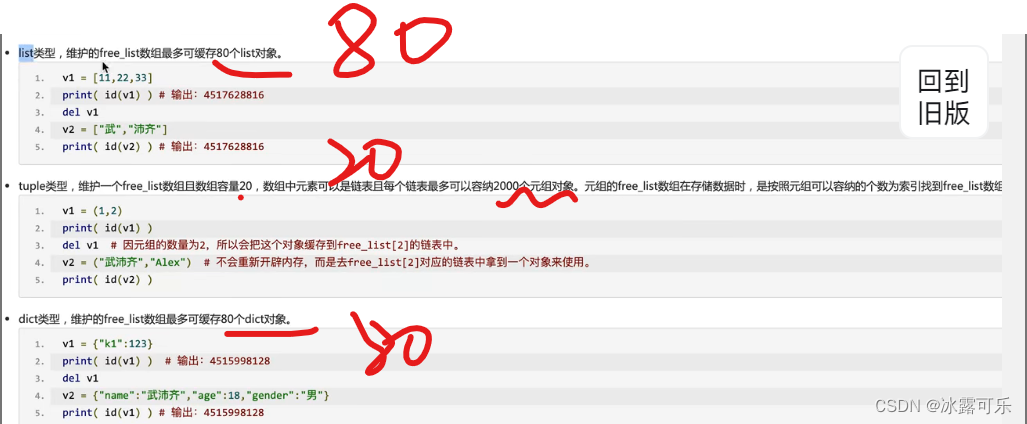
元组很特殊
外围是free_list
19个索引
但是每个索引都是一个元组,内部是可以放2000个节点
内部放0个元素,1个元素,2个元素…
根据元组中元素的个数不同,来索引下标
字符串也不同
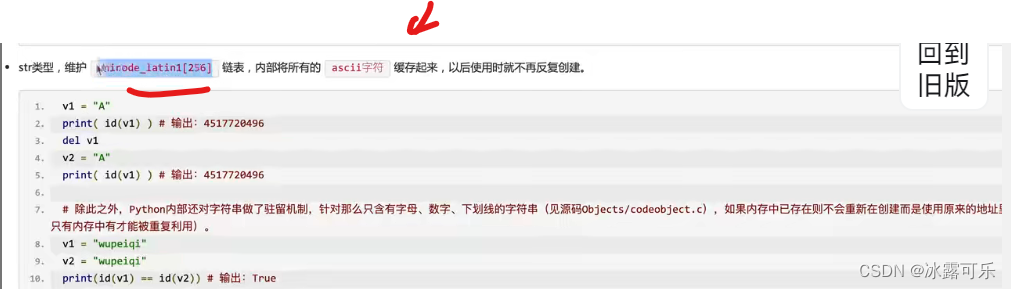
字符串驻留机制,字母,数字,下划线,长度不超20
上面就是常见的缓存机制
上面的源码怎么玩?c语言实现python是这样的
细节请看:
https://pythonav.com/wiki/detail/6/88/
当年就是一个博士生,自己绝c和c++写起来太烦人
就开发了python语言
就是通过上面的代码实现的python
从此你才能轻松简单滴用python了
够牛吧?
总结
提示:重要经验:
1)计数器加三代回收机制
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
相关文章
- 用生动的案例一步步带你学会python多线程模块
- python读取xml文件
- 【转载】Python包管理工具pip与easy_install
- Python发送企业微信群机器人消息
- 华为OD机试 - 微服务的集成测试(Java & JS & Python)
- 华为OD机试 - 内存资源分配Ⅱ(Java & JS & Python)
- 华为OD机试 - 机房布局(Java & JS & Python)
- 华为OD机试 - 最大报酬(Java & JS & Python)
- 华为OD机试 - 连接器问题(Java & JS & Python)
- 华为OD机试 - 简易内存池(Java & JS & Python)
- 华为OD机试 - 羊、狼、农夫过河(Java & JS & Python)
- 华为OD机试 - 求解连续数列(Java & JS & Python)
- 华为OD机试 - TLV解析Ⅰ(Java & JS & Python)
- 华为OD机试 - 信道分配(Java & JS & Python)
- 华为OD机试 - 计算疫情扩散时间(Java & JS & Python)
- Python语言学习:Python语言学习之容器(列表&元组&字典&集合)简介、特点/意义/经验总结及容器魔法方法(定义可变&不可变容器的协议)的简介、案例应用之详细攻略
- Python编程语言学习:python语言中快速查询python自带模块&函数的用法及其属性方法、如何查询某个函数&关键词的用法、输出一个类或者实例化对象的所有属性和方法名之详细攻略
- Python之ffmpeg-python:ffmpeg-python库的简介、安装、使用方法之详细攻略
- Python编程语言学习:python语言中快速查询python自带模块&函数的用法及其属性方法、如何查询某个函数&关键词的用法、输出一个类或者实例化对象的所有属性和方法名之详细攻略
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 基于深度学习的大规模 MIMO电力系统功率分配研究(Matlab&Python代码实现)
- Python图像处理丨详解图像去雾处理方法
- 干货分享!5款超级实用的Python工具库!
- Python学习23:列表生成式
- 【LeetCode Python实现】9. 回文数(简单):=海象运算符的使用
- 【华为OD机试 2023】无向图染色(C++ Java JavaScript Python)
- Python:mysql-connector-python模块对MySQL数据库进行增删改查
- python爬百度首页
- 小学生蓝桥杯Python闯关 | 世界第二峰的高度
- 60集Python入门视频PPT整理 | Python函数
- python里使用正则表达式的后向搜索肯定模式
- Python OpenCV实现图像模板匹配详解
- 〖Python自动化办公篇⑳〗 - python实现邮件自动化 - 发送html邮件和带附件的邮件
- python二级练习(4)