
复盘:池化层(Pooling)的反向传播过程,平均池化,最大值池化都是如何反向传播的
复盘:池化层(Pooling)的反向传播过程,平均池化,最大值池化都是如何反向传播的?
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
Pooling池化操作的反向梯度传播
CNN网络中另外一个不可导的环节就是Pooling池化操作,
因为Pooling操作使得feature map的尺寸变化,假如做2×22×2的池化,
假设那么第l+1l+1层的feature map有16个梯度,
那么第ll层就会有64个梯度,这使得梯度无法对位的进行传播下去。
其实解决这个问题的思想也很简单,
就是把1个像素的梯度传递给4个像素,
但是需要保证传递的loss(或者梯度)总和不变。
根据这条原则,mean pooling和max pooling的反向传播也是不同的。
mean pooling
mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,
那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,
这样就保证池化前后的梯度(残差)之和保持不变,还是比较理解的,图示如下
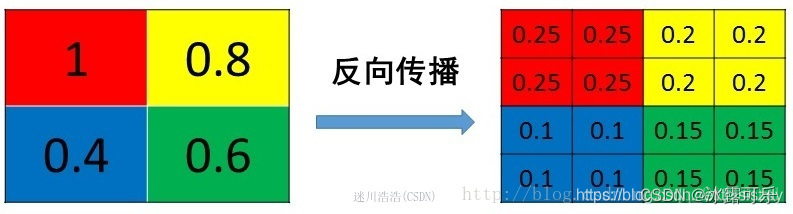
mean pooling比较容易让人理解错的地方就是
会简单的认为直接把梯度复制N遍之后直接反向传播回去,
但是这样会造成loss之和变为原来的N倍,
网络是会产生梯度爆炸的。
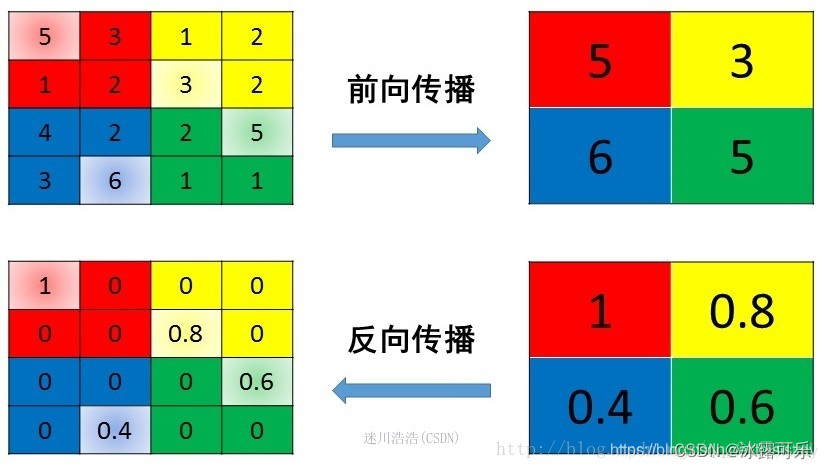
max pooling
max pooling也要满足梯度之和不变的原则,
max pooling的前向传播是把patch中最大的值传递给后一层,
而其他像素的值直接被舍弃掉。
那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。
当初你从哪里取的max,就返回去传给它
所以max pooling操作和mean pooling操作不同点在于
需要记录下池化操作时到底哪个像素的值是最大,
也就是max id,这个变量就是记录最大值所在位置的,
因为在反向传播中要用到,
那么假设前向传播和反向传播的过程就如下图所示 :
总结
提示:重要经验:
1)很容易,我们的目标就是梯度总和是不能变的,mean池化的话,直接将梯度均分n份,返回去传
2)max池化的话,需要记录当初池化的位置,梯度回传只传给这个位置
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
相关文章
- 如何将rpm软件包及其所有的依赖,都下载到本地的一个目录中?
- 如何卸载自己在Python中用pip安装的OpenCV(详细过程记录)
- JAVA开发过程中如何通过互联网解决问题
- 使用docker build命令构建docker镜像时apt-get install安装软件过程很慢如何解决?
- linux下如何使make只输出执行过程中的命令序列
- 如何集成华为AGC远程配置-React Native
- 《C++编程规范:101条规则、准则与最佳实践》——2.3编程中应知道何时和如何考虑可伸缩性
- 《团队软件过程(修订版)》—第2章2.5节团队如何发展
- 如何通过细节来看业务流程ERP管理系统的成熟度?
- 摘要:我们经常会用到递归函数,但是如果递归深度太大时,往往导致栈溢出。而递归深度往往不太容易把握,所以比较安全一点的做法就是:用循环代替递归。文章最后的原文里面讲了如何用10步实现这个过程,相当精彩。本文翻译了这篇文章,并加了自己的一点注释和理解。
- 【JDBC】02-如何获取数据库连接(展示迭代过程)
- 浅析sql的存储过程是什么及作用以及如何使用存储过程
- 2023最新后端中大厂面经&在面试过程中如何反问?
- 如何缓解安防PPP模式的忧愁
- 恢复过程痛苦?该如何应对服务器数据丢失
- 【FAQ】【JAVA UI】HarmonyOS 如何获取uid和pid
- 软件测试过程中如何区分什么是功能bug,什么是需求bug,什么是设计bug?
- 关于Unity中如何判断一个动画播放结束
- 详解NGINX如何统计网站的PV、UV、独立IP
- SQLServer存储过程如何获取异常信息
- CAD软件中如何进行平面设备布置?
- 云迁移过程如何避免停机
- Java 中图片与二进制之间如何相互转换?