
深度学习机器学习面试题——自然语言处理NLP,transformer,BERT,RNN,LSTM
深度学习机器学习面试题——自然语言处理NLP,transformer,BERT,RNN,LSTM
提示:互联网大厂常考的深度学习基础知识
LSTM与Transformer的区别
讲一下Bert原理,Bert好在哪里?
cbow 与 skip-gram 的区别和优缺点
Bert的MLM预训练任务mask的目的是什么
CRF原理
Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
如何优化BERT效果
BERT self-attention相比lstm优点是什么?
说说循环神经网络
说说LSTM
LSTM的结构
LSTM的三个门怎么运作的,写一下三个门的公式
LSTM为什么可以解决长期依赖,LSTM会梯度消失吗
LSTM相较于RNN的优势
讲一下LSTM,LSTM相对于RNN有哪些改进?LSTM为什么可以解决长期问题,相对与RNN改进在哪
讲一下LSTM吧,门都是怎么迭代的
RNN为什么难以训练,LSTM又做了什么改进
wide & deep 模型 wide 部分和 deep 部分分别侧重学习什么信息
deepfm 一定优于 wide & deep 吗
Bert的输入是什么?
Bert的词向量的embedding怎么训练得到的?
self-attention理解和作用,为什么要除以根号dk?
BERT中并行计算体现在哪儿
翻译中Q\K\V对应的是什么
attention和self attention的区别
介绍transformer以及讲优势
Transformer encoder和decoder的介绍
transformer的position encoding和BERT的position embedding的区别
文章目录
- 深度学习机器学习面试题——自然语言处理NLP,transformer,BERT,RNN,LSTM
-
- LSTM与Transformer的区别
- RNN 循环神经网络(Recurrent Neural Networks)
- LSTM原理,LSTM结构,LSTM的三个门怎么运作的,写一下三个门的公式
- Transformer原理
- 讲一下Bert原理,Bert好在哪里?
- cbow 与 skip-gram 的区别和优缺点
- Bert的MLM预训练任务mask的目的是什么
- CRF条件随机场原理
-
- Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
- 如何优化BERT效果
- BERT self-attention相比lstm优点是什么?
- LSTM为什么可以解决长期依赖,LSTM会梯度消失吗
- LSTM相较于RNN的优势,RNN为什么难以训练,LSTM又做了什么改进
- 讲一下LSTM,LSTM相对于RNN有哪些改进?LSTM为什么可以解决长期问题,相对与RNN改进在哪
- wide & deep 模型 wide 部分和 deep 部分分别侧重学习什么信息
- deepfm 一定优于 wide & deep 吗
- Bert的输入是什么?
- Bert的词向量的embedding怎么训练得到的?
- self-attention理解和作用,为什么要除以根号dk?
- BERT中并行计算体现在哪儿
- 翻译中Q\K\V对应的是什么
- attention和self attention的区别
- 介绍transformer以及讲优势
- transformer的position encoding和BERT的position embedding的区别
- BERT模型结构
- 总结
文章目录
- 深度学习机器学习面试题——自然语言处理NLP,transformer,BERT,RNN,LSTM
- LSTM与Transformer的区别
- RNN 循环神经网络(Recurrent Neural Networks)
- LSTM原理,LSTM结构,LSTM的三个门怎么运作的,写一下三个门的公式
- Transformer原理
- 讲一下Bert原理,Bert好在哪里?
- cbow 与 skip-gram 的区别和优缺点
- Bert的MLM预训练任务mask的目的是什么
- CRF条件随机场原理
- Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
- 如何优化BERT效果
- BERT self-attention相比lstm优点是什么?
- LSTM为什么可以解决长期依赖,LSTM会梯度消失吗
- LSTM相较于RNN的优势,RNN为什么难以训练,LSTM又做了什么改进
- 讲一下LSTM,LSTM相对于RNN有哪些改进?LSTM为什么可以解决长期问题,相对与RNN改进在哪
- wide & deep 模型 wide 部分和 deep 部分分别侧重学习什么信息
- deepfm 一定优于 wide & deep 吗
- Bert的输入是什么?
- Bert的词向量的embedding怎么训练得到的?
- self-attention理解和作用,为什么要除以根号dk?
- BERT中并行计算体现在哪儿
- 翻译中Q\K\V对应的是什么
- attention和self attention的区别
- 介绍transformer以及讲优势
- transformer的position encoding和BERT的position embedding的区别
- BERT模型结构
- 总结
LSTM与Transformer的区别
(1)Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成,前后没有“时序”,可以实现并行计算,更高效;
而LSTM是传统的RNN改进结构,有时序的概念,不能并行计算
(2)LSTM引入三个控制门,拥有了长期记忆,更好的解决了RNN的梯度消失和梯度爆炸的问题;而Transformers 依然存在顶层梯度消失的问题。?transformer不是有残差连接吗?为毛会有梯度消失的问题
(3)LSTM的输入具备时序;而Transformers还需要利用positional encoding加入词序信息,但效果不好,而且无法捕获长距离的信息,单独说transformer,可能就有bug,需要各种改进才能搞定。
(4)LSTM针对长序列依然计算有效;而Transformers针对长序列低效,计算量太大,self.attention的复杂度是n的2次方
(5)CNN和RNN结构的可解释性并不强 ,LSTM也一样;而Transformers的自注意力可以产生更具可解释性的模型。
RNN 循环神经网络(Recurrent Neural Networks)
人对一个问题的思考不会完全从头开始。
比如你在阅读本片文章的时,**你会根据之前理解过的信息来理解下面看到的文字。**在理解当前文字的时候,你并不会忘记之前看过的文字,从头思考当前文字的含义。
传统的神经网络并不能做到这一点,这是在对这种序列信息(如语音)进行预测时的一个缺点。比如你想对电影中的每个片段去做事件分类,传统的神经网络是很难通过利用前面的事件信息来对后面事件进行分类。
而循环神经网络(下面简称RNNs)可以通过不停的将信息循环操作,保证信息持续存在,从而解决上述问题。RNNs如下图所示
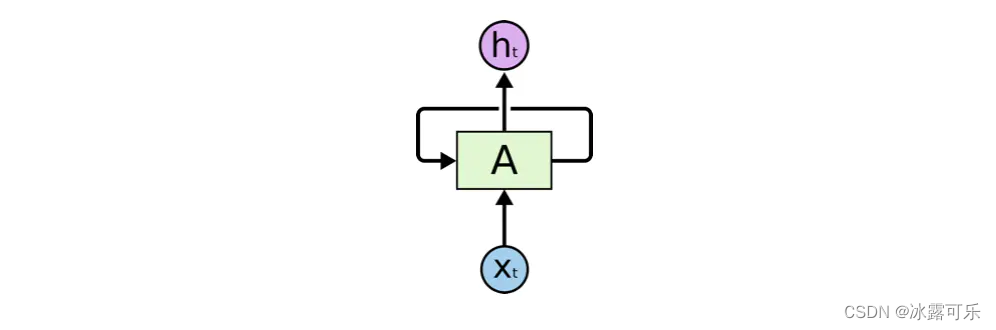
可以看出A是一组神经网络(可以理解为一个网络的自循环),它的工作是不停的接收xt并且输出ht。从图中可以看出A允许将信息不停的再内部循环,这样使得它可以保证每一步的计算都保存以前的信息。
这样讲可能还是有点晕,更好的理解方式,也是很多文章的做法,将RNNs的自循环结构展开,像是将同一个网络复制并连成一条线的结构,将自身提取的信息传递给下一个继承者,如下图所示。
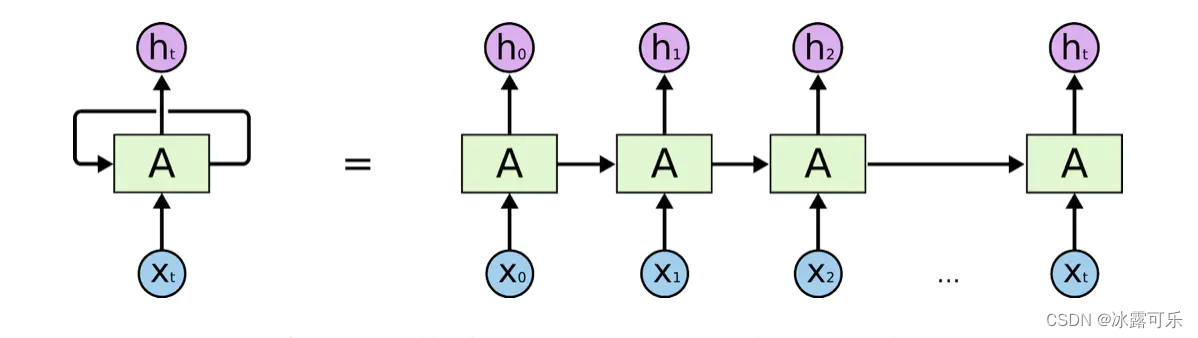
但是RNN有梯度消失的问题,太长了就炸了,梯度没了
假设现在有个更为复杂的任务,**考虑到下面这句话“I grew up in France… I speak fluent French.”,**现在需要语言模型通过现有以前的文字信息预测该句话的最后一个字。
通过以前文字语境可以预测出最后一个字是某种语言,但是要猜测出French,要根据之前的France语境。
这样的任务,不同之前,**因为这次的有用信息与需要进行处理信息的地方之间的距离较远,**这样容易导致RNNs不能学习到有用的信息,最终推导的任务可能失败。如下图所示。
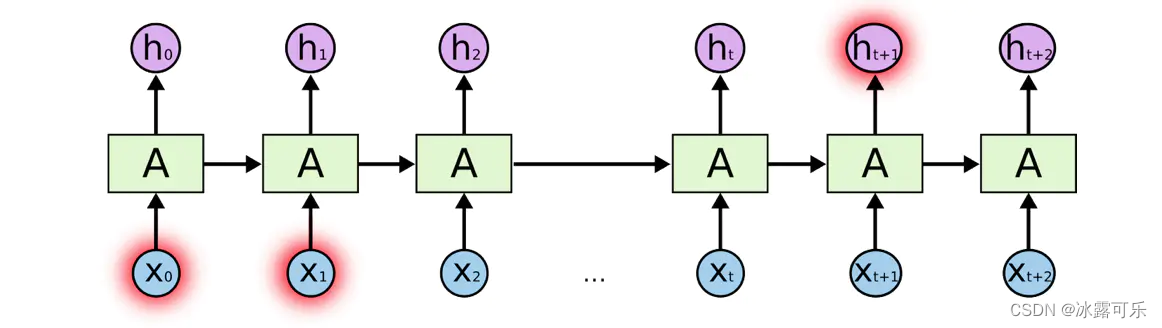
为了解决这个问题,解决长时间的依赖性,设计改进了LSTM,下面说
LSTM原理,LSTM结构,LSTM的三个门怎么运作的,写一下三个门的公式
Long Short Term Memory networks(以下简称LSTMs),一种特殊的RNN网络,该网络设计出来是为了解决长依赖问题。该网络由 Hochreiter & Schmidhuber (1997)引入,并有许多人对其进行了改进和普及。他们的工作被用来解决了各种各样的问题,直到目前还被广泛应用。
所有循环神经网络都具有神经网络的重复模块链的形式。 在标准的RNN中,该重复模块将具有非常简单的结构,例如单个tanh层。标准的RNN网络如下图所示
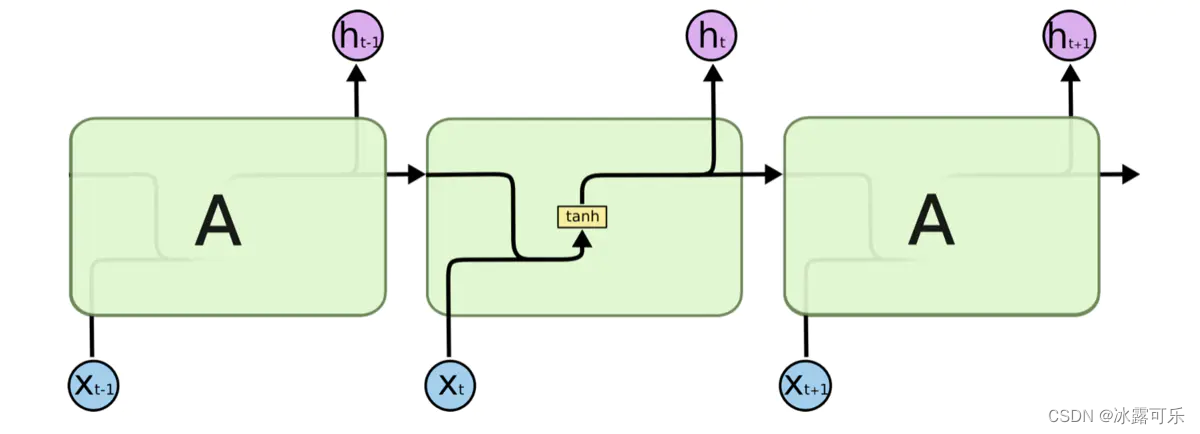
LSTMs也具有这种链式结构,但是它的重复单元不同于标准RNN网络里的单元只有一个网络层,它的内部有四个网络层。LSTMs的结构如下图所示。
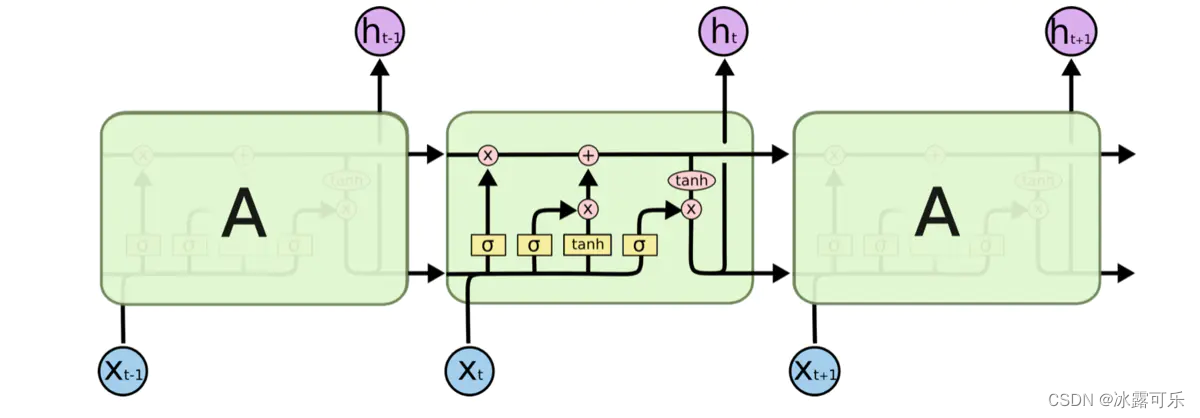
在解释LSTMs的详细结构时先定义一下图中各个符号的含义,符号包括下面几种

图中黄色类似于CNN里的激活函数操作,粉色圆圈表示点操作,单箭头表示数据流向,箭头合并表示向量的合并(concat)操作,箭头分叉表示向量的拷贝操作
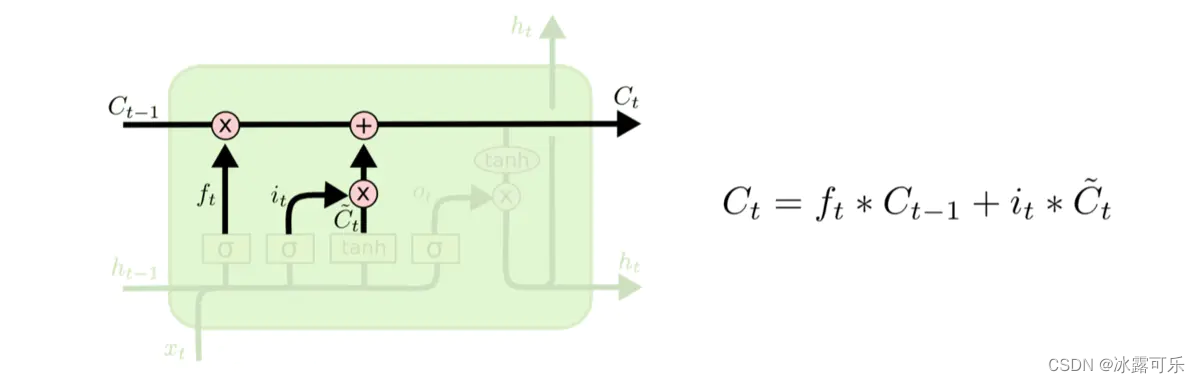
LSTMs的核心是细胞状态,用贯穿细胞的水平线表示。
细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。细胞状态如下图所示
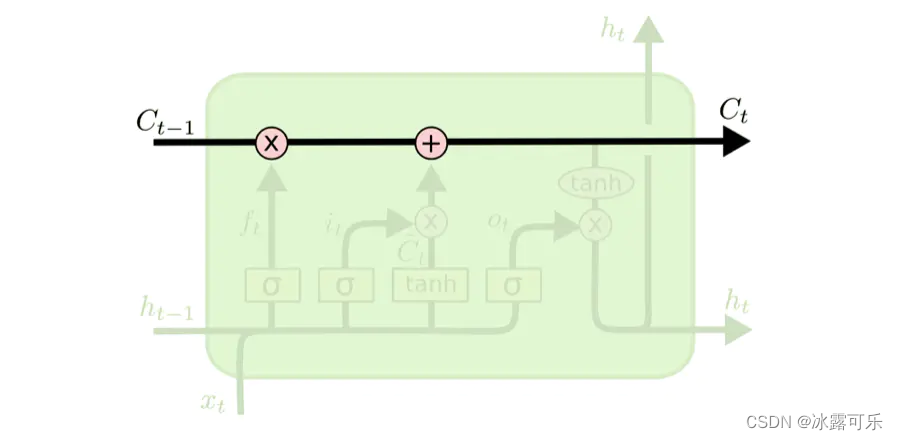
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。
门能够有选择性的决定让哪些信息通过。其实门的结构很简单,**就是一个sigmoid层和一个点乘操作的组合。**如下图所示
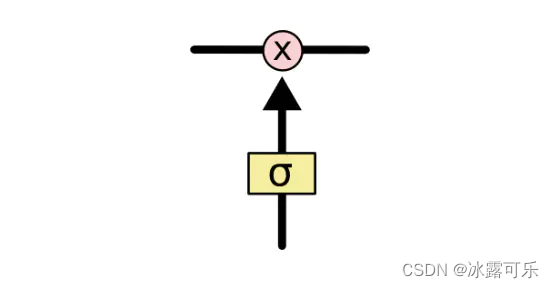
因为sigmoid层的输出是0-1的值,这代表有多少信息能够流过sigmoid层。**0表示都不能通过,1表示都能通过。**一个LSTM里面包含三个门来控制细胞状态。
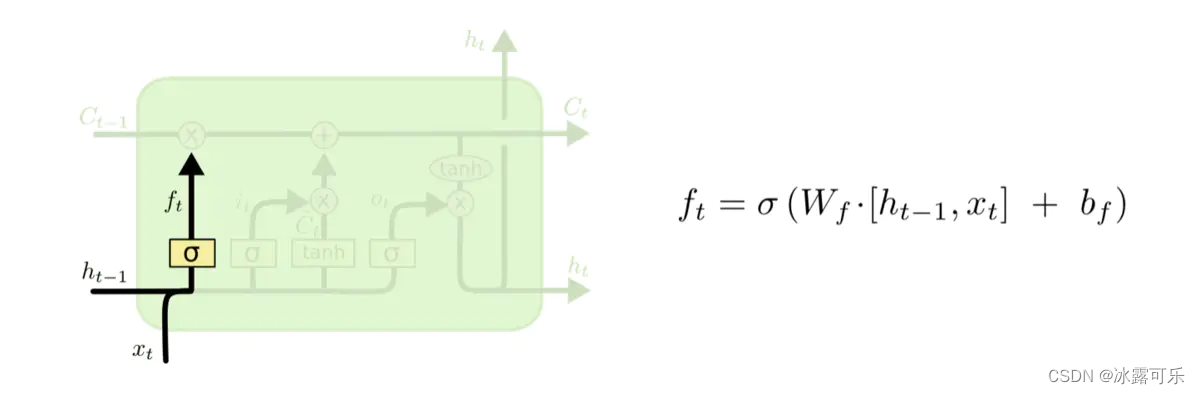
这三个门分别称为忘记门、输入门和输出门。


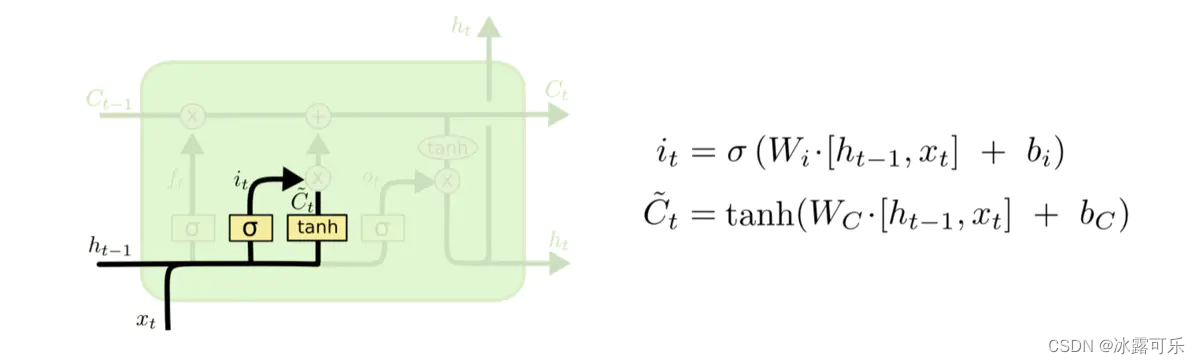


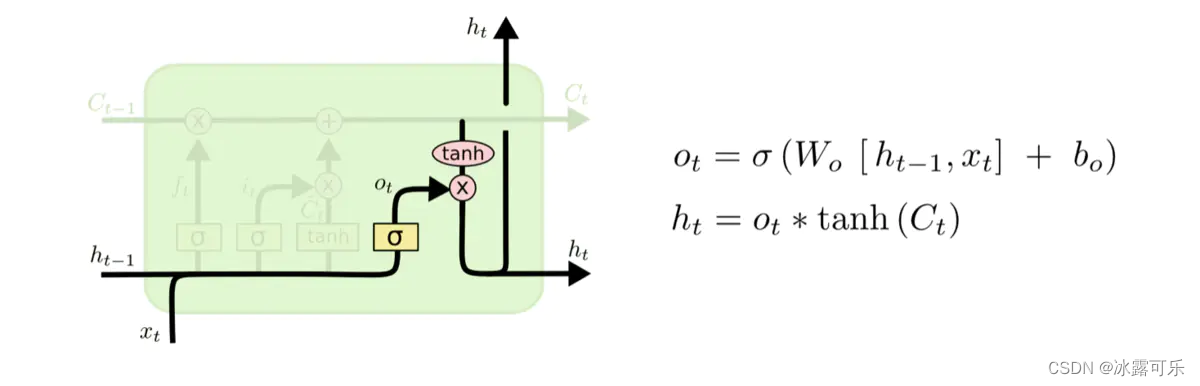
还是拿语言模型来举例说明,
在预测动词形式的时候,我们需要通过输入的主语是单数还是复数来推断输出门输出的预测动词是单数形式还是复数形式。
Transformer原理
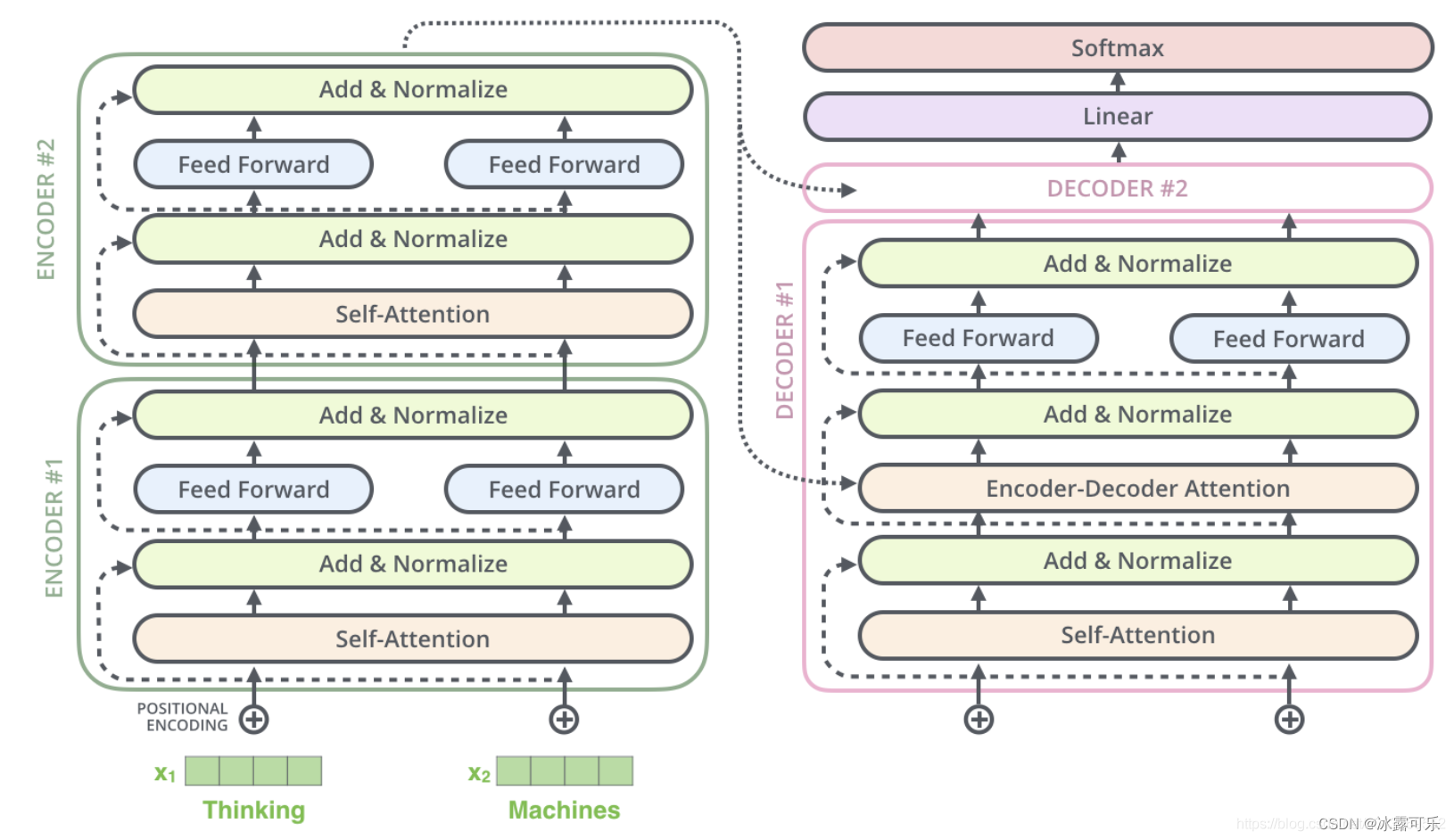
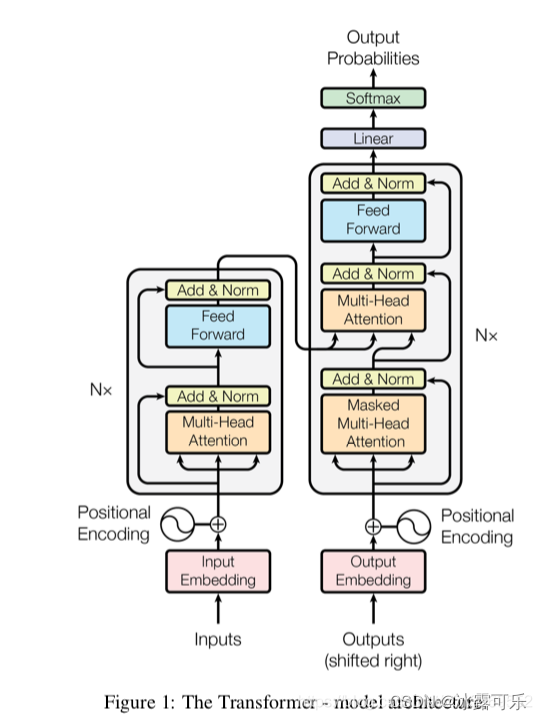
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中取得了BLEU值得新高。
Transformer的实验基于机器翻译

Transform本质是Encoder-Decoder的结构
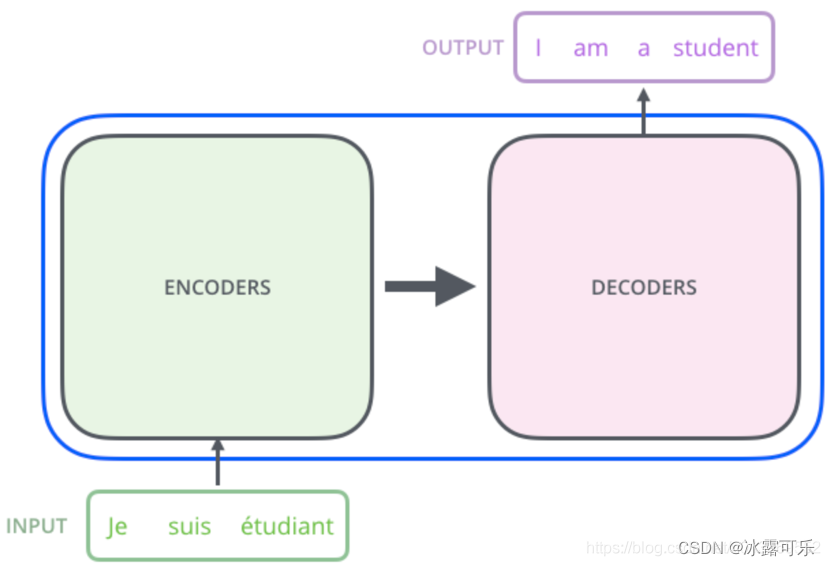
论文中所设置的,编码器由6个编码block组成,同样解码器是6个解码block组成。与所有的生成模型相同的是,编码器的输出会作为解码器的输入,如图3所示:
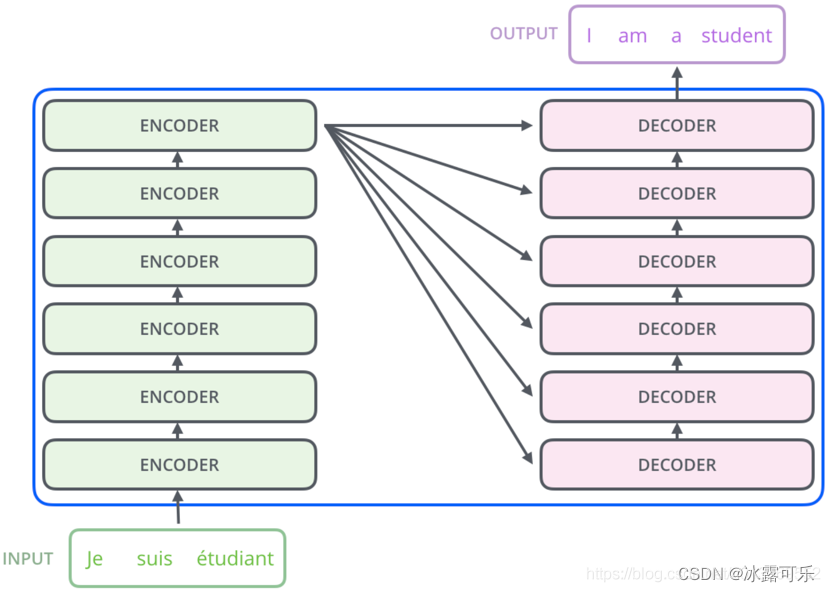
我们继续分析每个encoder的详细结构:
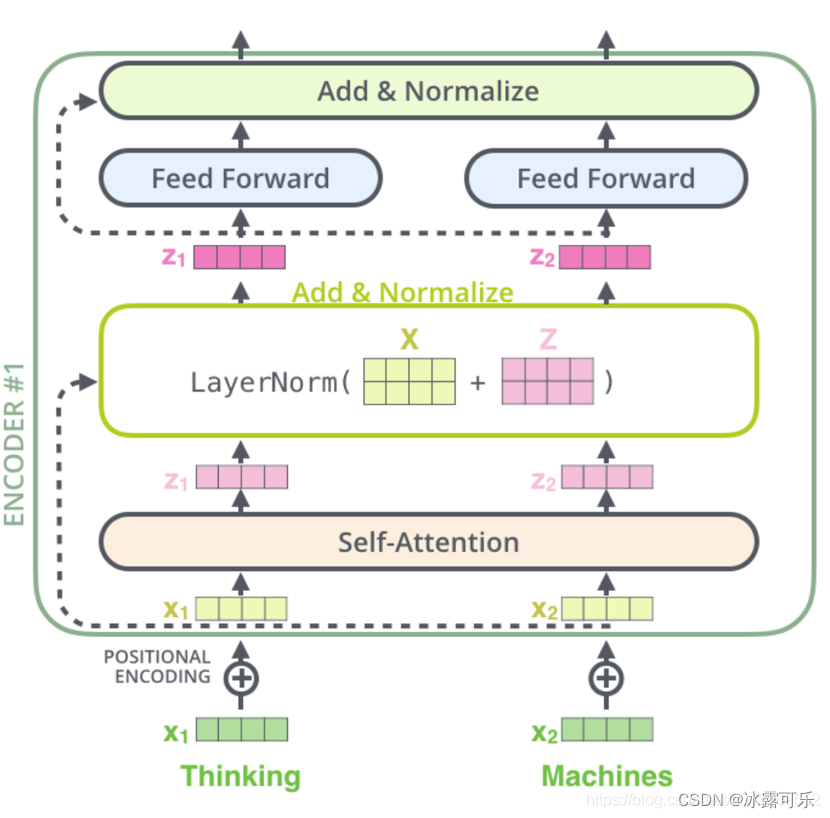
在Transformer的encoder中,数据首先会经过一个叫做**‘self-attention’的模块得到一个加权之后的特征向量 Z** ,这个Z 便是论文公式1中的 Attention(Q,K,V):
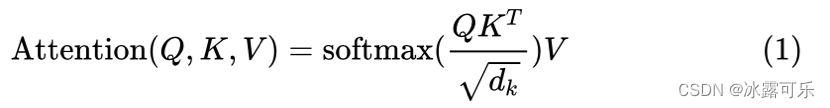
得到的Z,会被送到encoder的下一个模块,Feed Forward Neural Network,这个全连接有两层,第一层的激活函数是ReLU,第二层是一个线性激活函数,可以表示为:

Decoder的结构如图5所示,它和encoder的不同之处在于Decoder多了一个crross Attention,两个Attention分别用于计算输入和输出的权值:
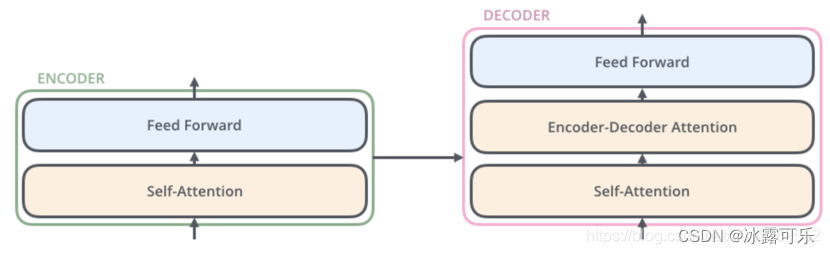
Self-Attention:当前翻译和已翻译的前文之间的关系;
Encoder-Decnoder Attention:当前翻译和编码的特征向量之间的关系。
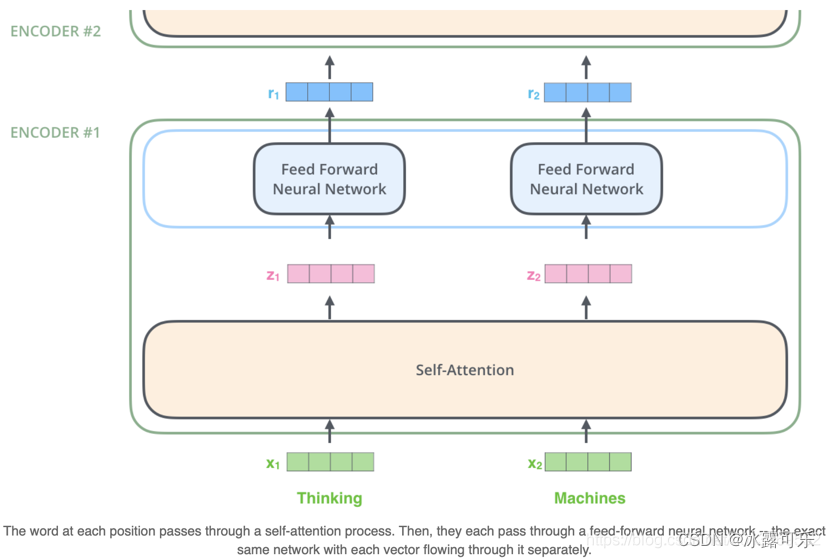
Transform encoder过程
首先将词通过word2vec表示为向量,第一层encoder的输入直接为词x的向量表示,而在其他层中,输入则是上一个block的输出。如下图所示
Attention
Attention模型并不只是盲目地将输出的第一个单词与输入的第一个词对齐。
Attention机制的本质来自于人类视觉注意力机制。人们在看东西的时候一般不会从到头看到尾全部都看,往往只会根据需求观察注意特定的一部分,
就是一种权重参数的分配机制,目标是协助模型捕捉重要信息。
即给定一组<key,value>,以及一个目标(查询)向量query,
attention机制就是通过计算query与每一组key的相似性,得到每个key的权重系数,再通过对value加权求和,得到最终attention数值。
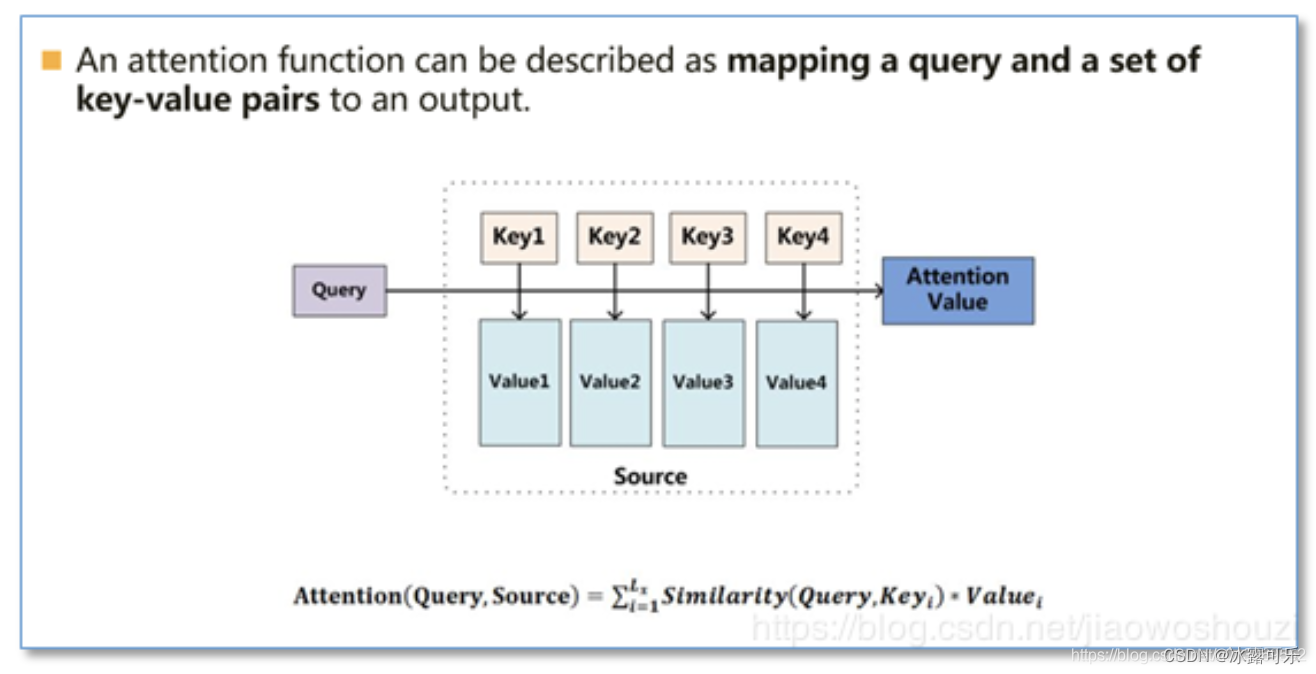
Self-Attention是Transformer最核心的内容,其核心内容是为输入向量的每个单词学习一个权重
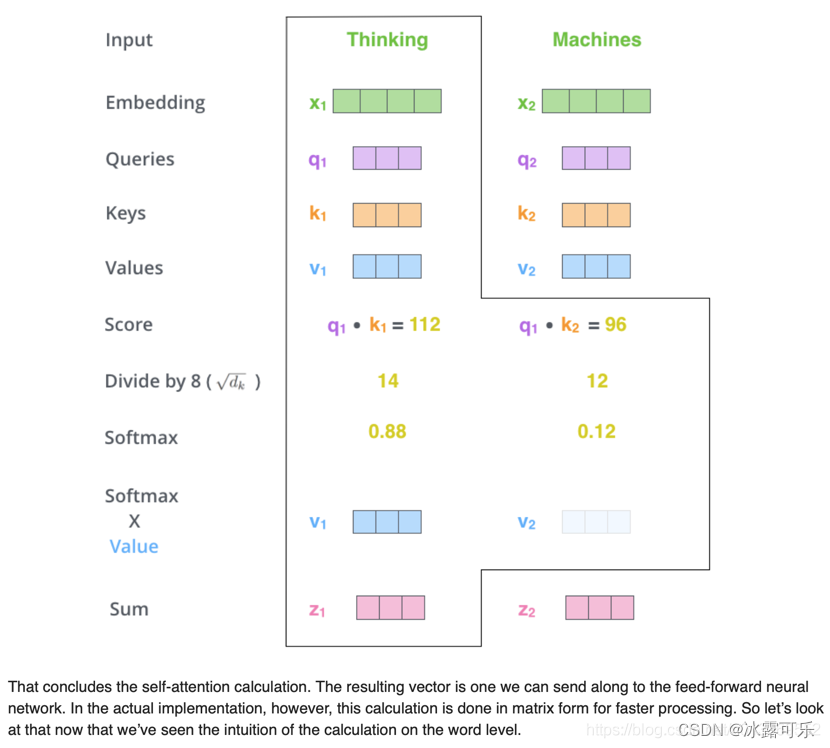
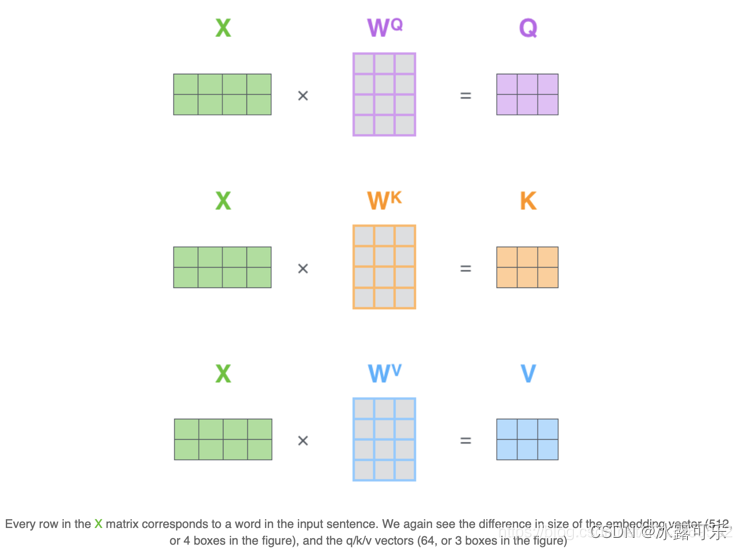
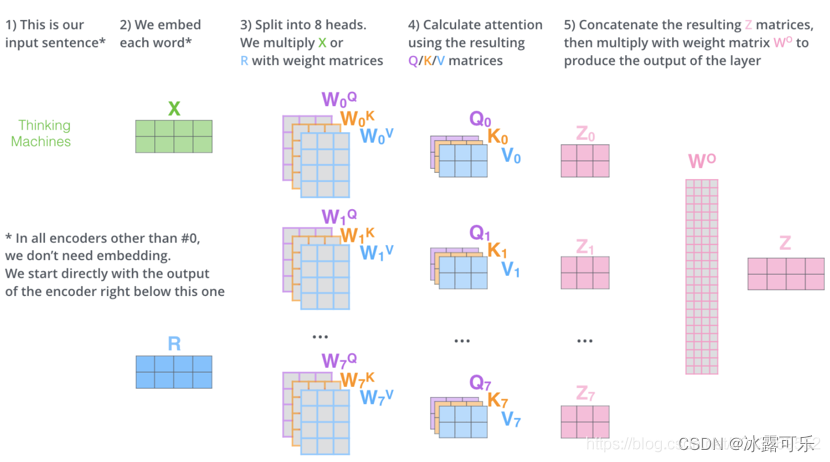
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K)和Value向量( V ),长度均是64。
它们是通过3个不同的权值矩阵由嵌入向量 X 乘以三个不同的权值矩阵 WQ,WK ,WV 得到,其中三个矩阵的尺寸也是相同的。均是 512*64;
Q,K,V这些向量的概念是很抽象,但是它确实有助于计算注意力。
相较于RNNs,transformer具有更好的并行性。

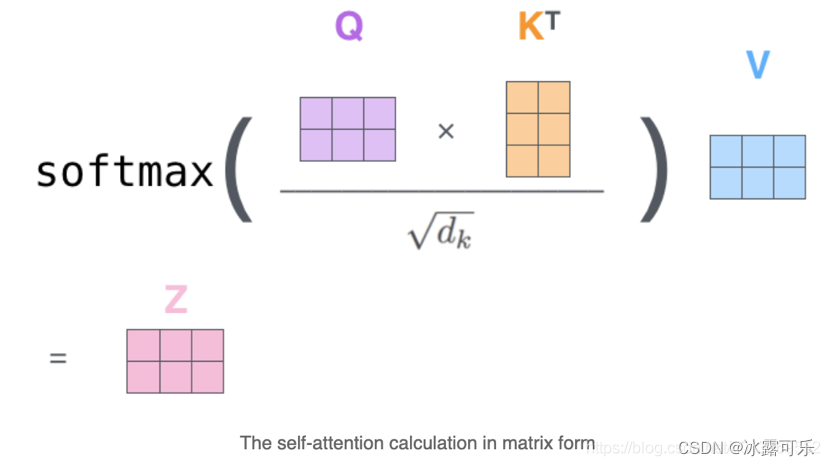
矩阵运算过程描述
Multi-Head Attention :

Transform的encoder整体结构
在self-attention需要强调的最后一点是其采用了残差网络 中的short-cut结构,目的当然是解决深度学习中的退化问题。
FFN 相当于将每个位置的Attention结果映射到一个更大维度的特征空间,然后使用ReLU引入非线性进行筛选,最后恢复回原始维度。
自注意机制的复杂度:
对于使用自注意力机制的原因,论文中提到主要从三个方面考虑(每一层的复杂度,是否可并行,长距离依赖学习),并给出了和RNN,CNN计算复杂度的比较。
可以看到,如果输入序列n小于表示维度d的话,每一层的时间复杂度self-attention是比较有优势的。
当n比较大时,作者也给出了一种解决方案self-attention(restricted)即每个词不是和所有词计算attention,而是只与限制的r个词去计算attention。
在并行方面,多头attention和CNN一样不依赖于前一时刻的计算,可以很好的并行,优于RNN。
在长距离依赖上,由于self-attention是每个词和所有词都要计算attention,所以不管他们中间有多长距离,最大的路径长度也都只是1。可以捕获长距离依赖关系

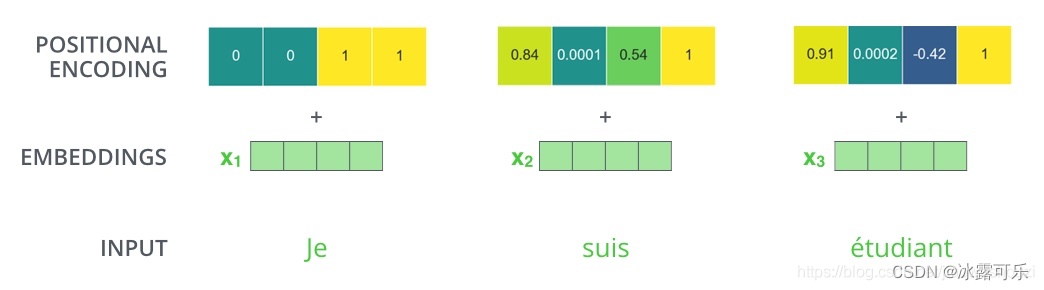
Positional Encoding:
transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。计算方法如下
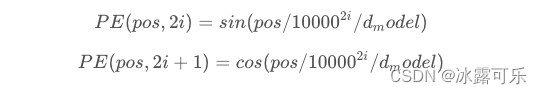
其中pos是指当前词在句子中的位置,i是指向量中每个值的index,可以看出,在偶数位置,使用正弦编码,在奇数位置,使用余弦编码。最后把这个Positional Encoding与embedding的值相加,作为输入送到下一层。
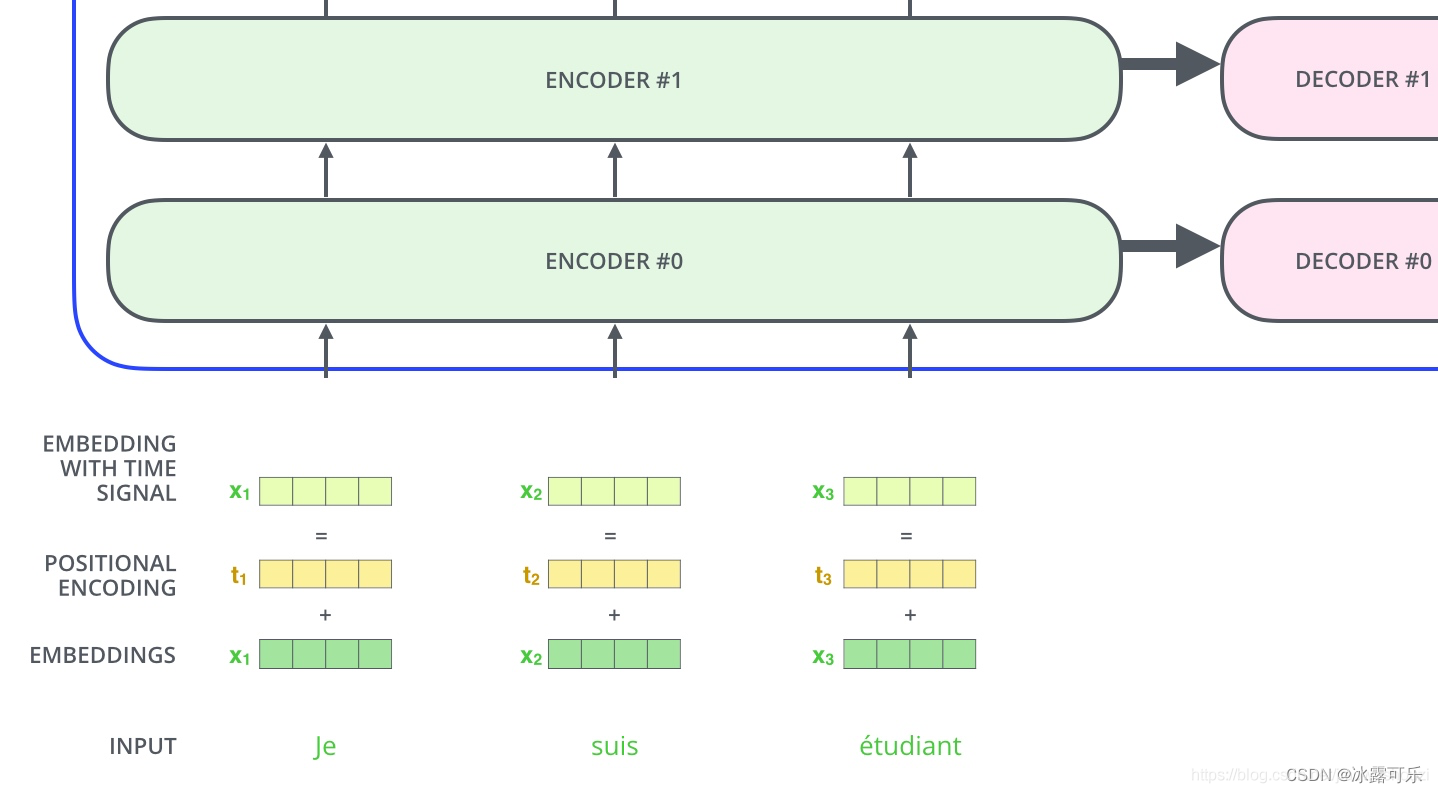
eg:嵌入维度为4,考虑位置编码的情况如下:
残差模块和Layer normalization
在transformer中,每一个子层(self-attetion,ffnn)之后都会接一个残差模块,并且有一个Layer normalization;
eg: 2个Encoder和2个Decoder的Transformer:
残差引入目的
随着网络深度的增加,训练变得愈加困难,这主要是因为在基于随机梯度下降的网络训练过程中,误差信号的多层反向传播非常容易引发**“梯度消失”(梯度过小会使回传的训练误差信号极其微弱)或者“梯度爆炸”(梯度过大导致模型出现NaN)的现象**。
目前一些特殊的权重**初始化策略和批规范化(BN)**等方法使这个问题得到了极大改善——网络可以正常训练了!!
但是实际情形不容乐观。
当模型收敛时,另外的问题又来了:随着网络深度的增加,训练误差没有降低反而升高。 这一现象与直觉极其不符,浅层网络可以被训练优化到一个很好的解,那么对应的更深层的网络至少也可以,而不是更差。这一现象在一段时间内困扰着更深层卷积神经网络的设计、训练和应用。

Normalization引入目的:
ormalization有很多种,但是它们都有一个共同的目的,那就是把输入转化成均值为0方差为1的数据。
我们在把数据送入激活函数之前进行normalization(归一化),因为我们不希望输入数据落在激活函数的饱和区。
Batch Normalization:BN的主要思想就是:在每一层的每一批数据上进行归一化。我们可能会对输入数据进行归一化,但是经过该网络层的作用后,我们的数据已经不再是归一化的了。随着这种情况的发展,数据的偏差越来越大,我的反向传播需要考虑到这些大的偏差,这就迫使我们只能使用较小的学习率来防止梯度消失或者梯度爆炸。
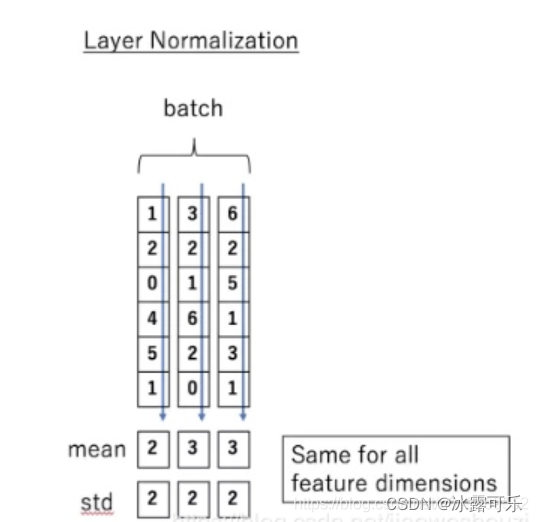
Layer normalization它也是归一化数据的一种方式,不过 LN 是在每一个样本上计算均值和方差,而每一个特征维度上进行归一化
Decoder层
transform的整体结构如下图所示;在解码器中,Transformer block比编码器中多了个encoder-decoder attention。在encoder-decoder attention中, Q 来自于解码器的上一个输出,K 和 V 则来自于与编码器的输出。
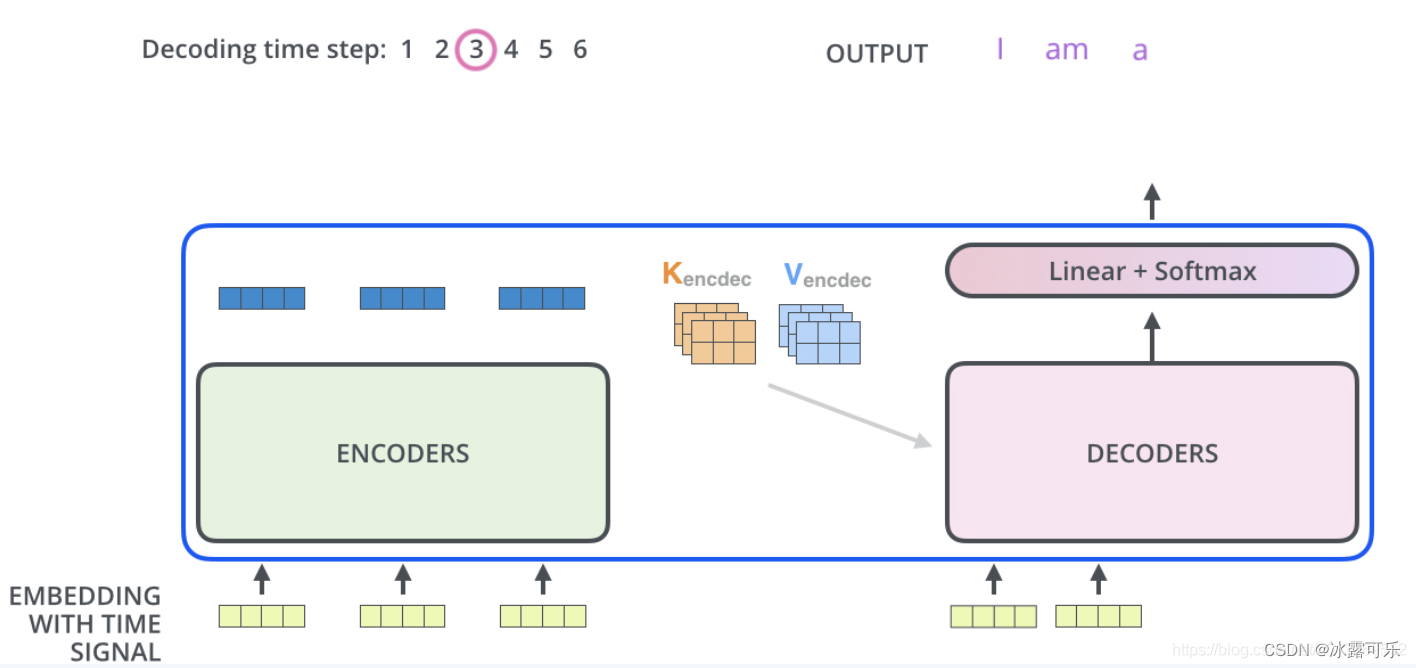
由于在机器翻译中,解码过程是一个顺序操作的过程,也就是当解码第 K 个特征向量时,我们只能看到第 K-1 及其之前的解码结果,论文中把这种情况下的multi-head attention叫做masked multi-head attention。transfrom的encoder和decoder整体架构如下:
输出层:
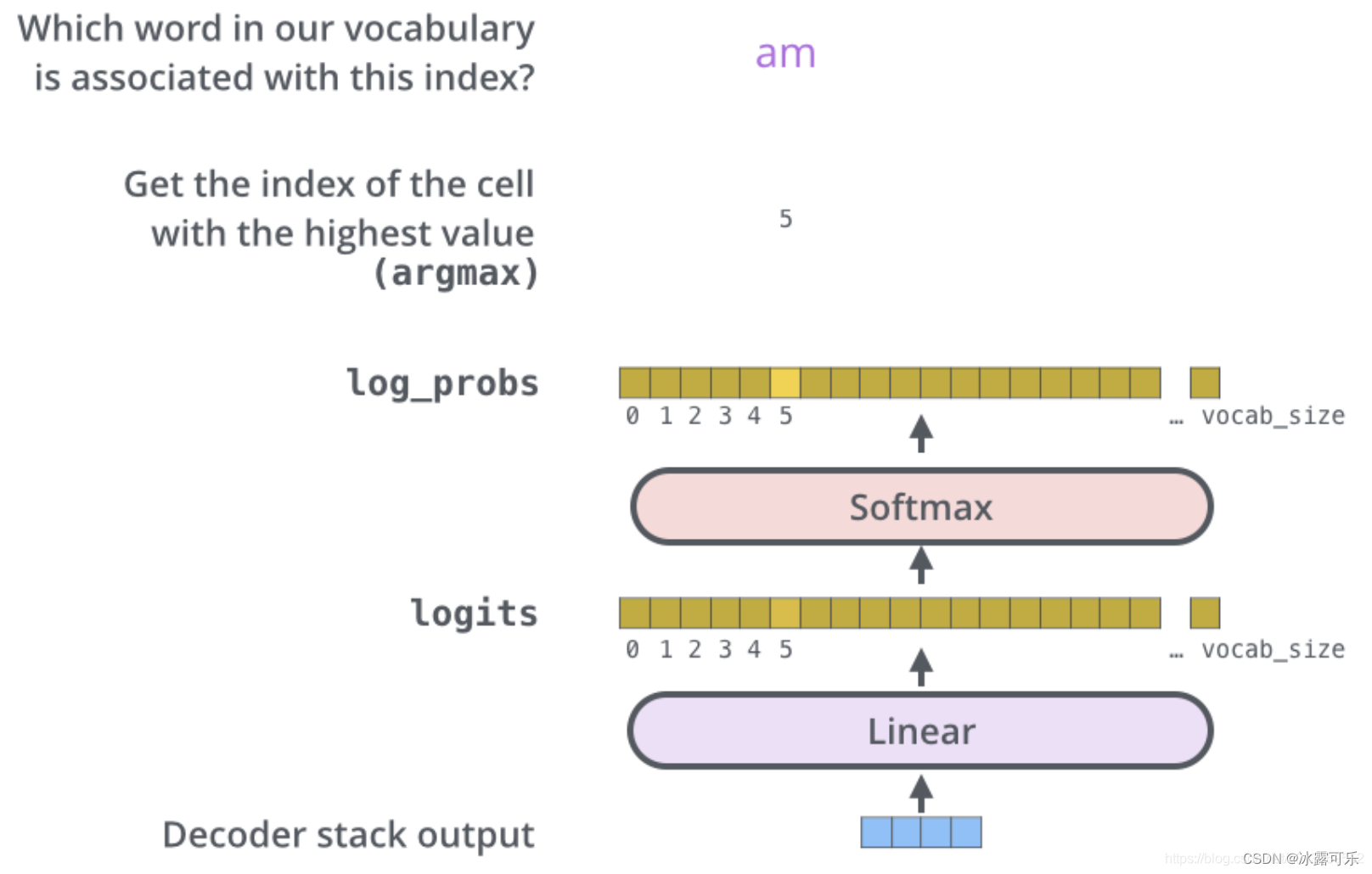
Decoder的输出是浮点数的向量列表。
把得到的向量映射为需要的词,需要线性层和softmax层获取预测为词的概率。
优点:
(1)虽然Transformer最终也没有逃脱传统学习的套路,Transformer也只是一个全连接(或者是一维卷积)加Attention的结合体。但是其设计已经足够有创新,因为其抛弃了在NLP中最根本的RNN或者CNN并且取得了非常不错的效果,算法的设计非常精彩,值得每个深度学习的相关人员仔细研究和品位。
(2)Transformer的设计最大的带来性能提升的关键是将任意两个单词的距离是1,这对解决NLP中棘手的长期依赖问题是非常有效的。
(3)Transformer不仅仅可以应用在NLP的机器翻译领域,甚至可以不局限于NLP领域,是非常有科研潜力的一个方向。现如今在CV中也直接开挂了
(4)算法的并行性非常好,符合目前的硬件(主要指GPU)环境。
缺点:
(1)粗暴的抛弃RNN和CNN虽然非常炫技,但是它也使模型丧失了捕捉局部特征的能力,RNN + CNN + Transformer的结合可能会带来更好的效果。
(2)Transformer失去的位置信息其实在NLP中非常重要,而论文中在特征向量中加入Position Embedding也只是一个权宜之计,并没有改变Transformer结构上的固有缺陷。
————————————————
原文链接:https://blog.csdn.net/u013069552/article/details/108074349
讲一下Bert原理,Bert好在哪里?
BERT:一切过往, 皆为序章
BERT的全称是Bidirectional Encoder Representation from Transformers,即双向Transformer的Encoder,因为decoder不能获得要预测的信息。
模型的主要创新点都在pre-train方法上,BERT的预训练阶段包括两个任务,
一个是MLM Masked Language Model,
还有一个是NSP Next Sentence Prediction,
两种方法分别捕捉词语和句子级别的特征表示。
BERT原理详解
从创新的角度来看,bert其实并没有过多的结构方面的创新点,其和GPT一样均是采用的transformer的结构,相对于GPT来说,其是双向结构的,而GPT是单向的,如下图所示
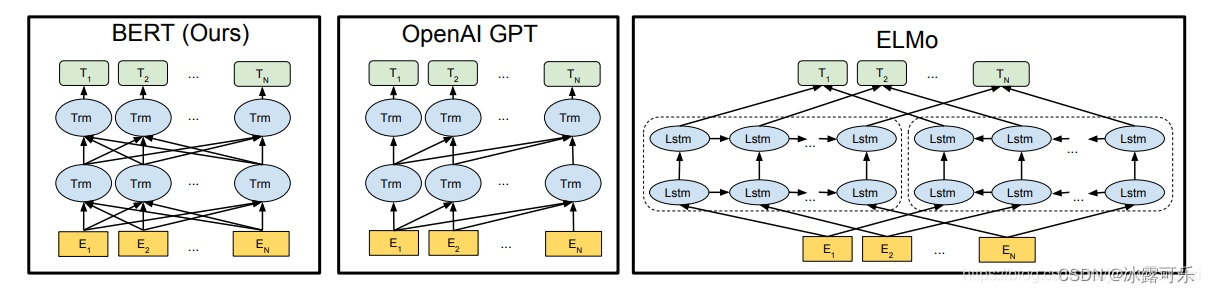
elmo:将上下文当作特征,但是无监督的语料和我们真实的语料还是有区别的,不一定的符合我们特定的任务,是一种双向的特征提取。
openai gpt就做了一个改进,也是通过transformer学习出来一个语言模型,不是固定的,通过任务 finetuning,用transfomer代替elmo的lstm。
openai gpt其实就是缺少了encoder的transformer。当然也没了encoder与decoder之间的attention。
openAI gpt虽然可以进行fine-tuning,但是有些特殊任务与pretraining输入有出入,单个句子与两个句子不一致的情况,很难解决,还有就是decoder只能看到前面的信息。
其次bert在多方面的nlp任务变现来看效果都较好,具备较强的泛化能力,对于特定的任务只需要添加一个输出层来进行fine-tuning即可。
BERT做:预训练模型
首先我们要了解一下什么是预训练模型,举个例子,假设我们有**大量的维基百科数据,**那么我们可以用这部分巨大的数据来训练一个泛化能力很强的模型,
当我们需要在特定场景使用时,例如做文本相似度计算,
那么,只需要简单的修改一些输出层,再用我们自己的数据进行一个增量训练,对权重进行一个轻微的调整。
预训练的好处在于在特定场景使用时不需要用大量的语料来进行训练,节约时间效率高效,bert就是这样的一个泛化能力较强的预训练模型。
BERT的预训练过程,BERT的预训练阶段包括两个任务,一个是Masked Language Model,还有一个是Next Sentence Prediction。
(1)Masked Language Model
MLM可以理解为完形填空,作者会随机mask每一个句子中15%的词,用其上下文来做预测,例如:my dog is hairy → my dog is [MASK]
此处将hairy进行了mask处理,然后采用非监督学习的方法预测mask位置的词是什么
(2)Next Sentence Prediction
选择一些句子对A与B,其中50%的数据:B是A的下一条句子,剩余50%的数据B是语料库中随机选择的,学习其中的相关性,添加这样的预训练的目的:是目前很多NLP的任务比如QA和NLI都需要理解两个句子之间的关系,从而能让预训练的模型更好的适应这样的任务。
cbow 与 skip-gram 的区别和优缺点
cbow和skip-gram都是在word2vec中用于将文本进行向量表示的实现方法
(1)在cbow方法中,是用周围词预测中心词,从而利用中心词的预测结果情况,使用梯度下降方法,不断的去调整周围词的向量。
当训练完成之后,每个词都会作为中心词,把周围词的词向量进行了调整,
这样也就获得了整个文本里面所有词的词向量;
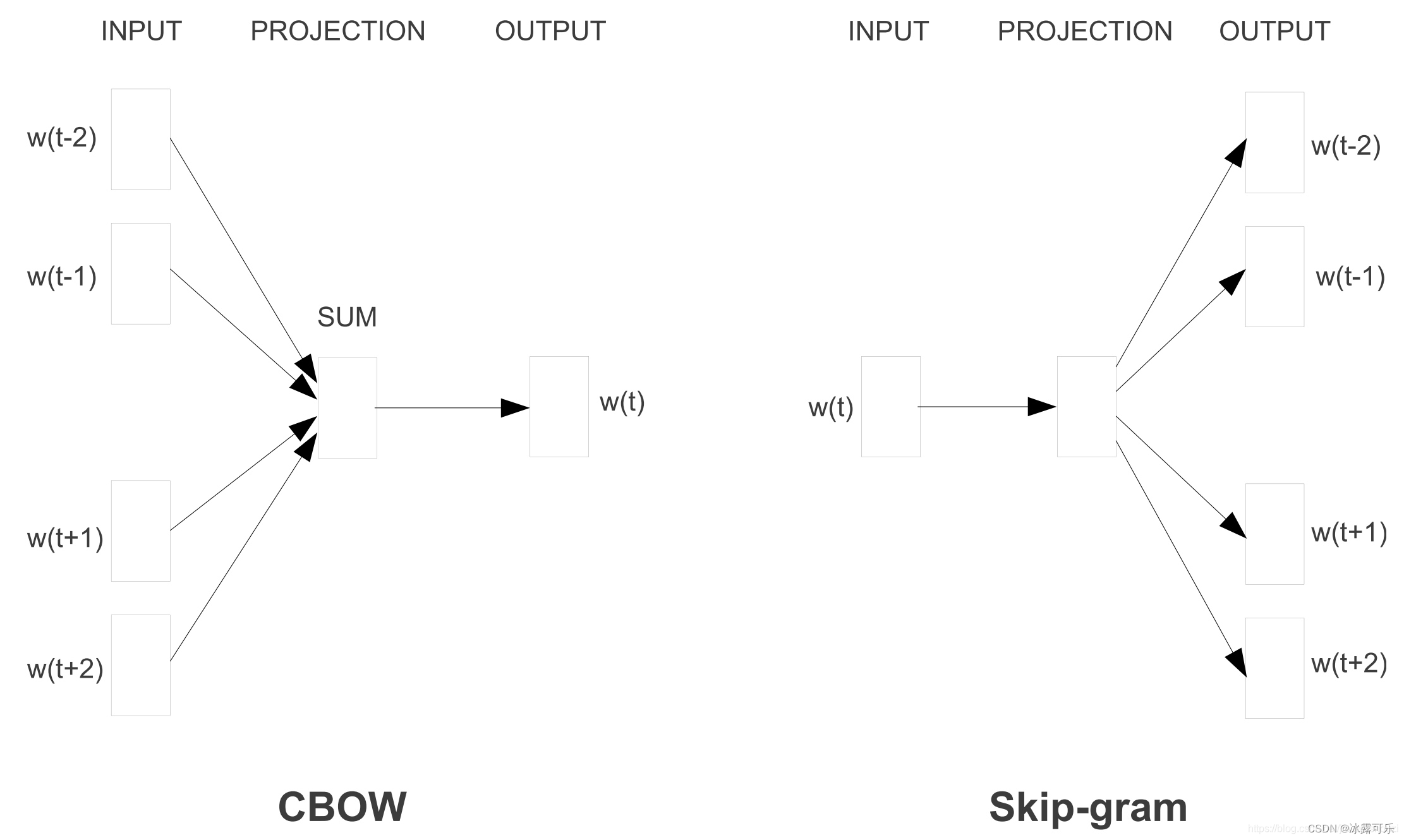
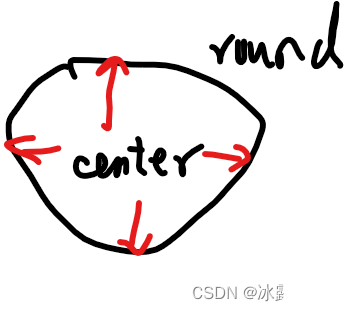
而skip-gram是用中心词来预测周围的词。
在skip-gram中,会利用周围的词的预测结果情况,使用梯度下降来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。
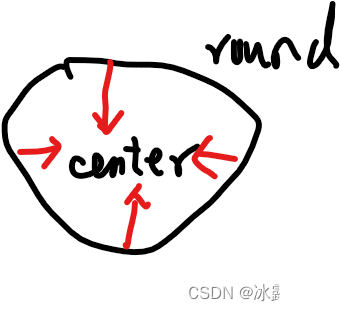
(2)可以看到,cbow预测行为的次数跟整个文本的词数几乎是相等的【因为每个次,做一次中心,被预测】(每次预测行为才会进行一次反向传播, 而往往这也是最耗时的部分),复杂度大概是O(V);
skip-gram进行预测的次数是要多于cbow的:因为每个词在作为中心词时,都要使用周围词进行预测一次【就是一个单词,都要去预测多个周围,所以计算多一些】。
这样相当于比cbow的方法多进行了K次(假设K为窗口大小),因此时间的复杂度为O(KV),训练时间要比cbow要长。
数据结构与算法告诉我们**o(kv)>>o(v)**的
除非k=固定的小常数,这样o(kv)=o(v)
简单说,skip-gram 出来的准确率比cbow 高,但训练时间要比cbow要长;
在计算时,cbow会将context word 加起来, 在遇到生僻词是,预测效果将会大大降低。
skip-gram则会预测生僻字的使用环境,预测效果更好。
总之skip-gram更好呗
Bert的MLM预训练任务mask的目的是什么
个人理解是让模型学习一个句子中词与词之间的关系。
说白了就是让模型理解词的语义,还有语法关系,跟人一样。
CRF条件随机场原理

举例说明什么事条件随机场:
链接:https://www.zhihu.com/question/35866596/answer/139485548
假设你有许多小明同学一天内不同时段的照片,从小明提裤子起床到脱裤子睡觉各个时间段都有(小明是照片控!)。
现在的任务是对这些照片进行分类。比如有的照片是吃饭,那就给它打上吃饭的标签;有的照片是跑步时拍的,那就打上跑步的标签;有的照片是开会时拍的,那就打上开会的标签。
问题来了,你准备怎么干?一个简单直观的办法就是,不管这些照片之间的时间顺序 ,想办法训练出一个多元分类器。就是用一些打好标签的照片作为训练数据,训练出一个模型,直接根据照片的特征来分类。
例如,如果照片是早上6:00拍的,且画面是黑暗的,那就给它打上睡觉的标签;
如果照片上有车,那就给它打上开车的标签。这样可行吗?
乍一看可以!
但实际上,由于我们忽略了这些照片之间的时间顺序这一重要信息,我们的分类器会有缺陷的。
举个例子,假如有一张小明闭着嘴的照片,怎么分类?
显然难以直接判断,需要参考闭嘴之前的照片,
如果之前的照片显示小明在吃饭,那这个闭嘴的照片很可能是小明在咀嚼食物准备下咽,可以给它打上吃饭的标签;
如果之前的照片显示小明在唱歌,那这个闭嘴的照片很可能是小明唱歌瞬间的抓拍,可以给它打上唱歌的标签。
所以,为了让我们的分类器能够有更好的表现,在为一张照片分类时,我们必须将与它相邻的照片的标签信息考虑进来。
这——就是条件随机场(CRF)大显身手的地方!
如果应用到自然语言处理中,你后面说了啥,前面的句子信息很重要的,前面没看懂,后面没法看,CRF就可以用来搞这个事
词性标注问题:
啥是词性标注问题?
非常简单的,就是给一个句子中的每个单词注明词性。
比如这句话:“Bob drank coffee at Starbucks”,
注明每个单词的词性后是这样的:
“Bob (名词)
drank(动词)
coffee(名词)
at(介词)
Starbucks(名词)”。
下面,就用条件随机场CRF来解决这个问题。
以上面的话为例,有5个单词,我们将:(名词,动词,名词,介词,名词)作为一个标注序列,称为l,
可选的标注序列有很多种,比如l还可以是这样:(名词,动词,动词,介词,名词),
我们要在这么多的可选标注序列中,挑选出一个最靠谱的作为我们对这句话的标注。
怎么判断一个标注序列靠谱不靠谱呢?
就我们上面展示的两个标注序列来说,第二个显然不如第一个靠谱,
因为它把第二、第三个单词都标注成了动词,**动词后面接动词 **,这在一个句子中通常是说不通的。
假如我们给每一个标注序列打分,打分越高代表这个标注序列越靠谱,我们至少可以说,凡是标注中出现了动词后面还是动词的标注序列,要给它减分!!
上面所说的动词后面还是动词就是一个特征函数,我们可以定义一个特征函数集合,用这个特征函数集合来为一个标注序列打分,并据此选出最靠谱的标注序列。
也就是说,每一个特征函数都可以用来为一个标注序列评分,把集合中所有特征函数对同一个标注序列的评分综合起来,就是这个标注序列最终的评分值。
CRF特征函数f
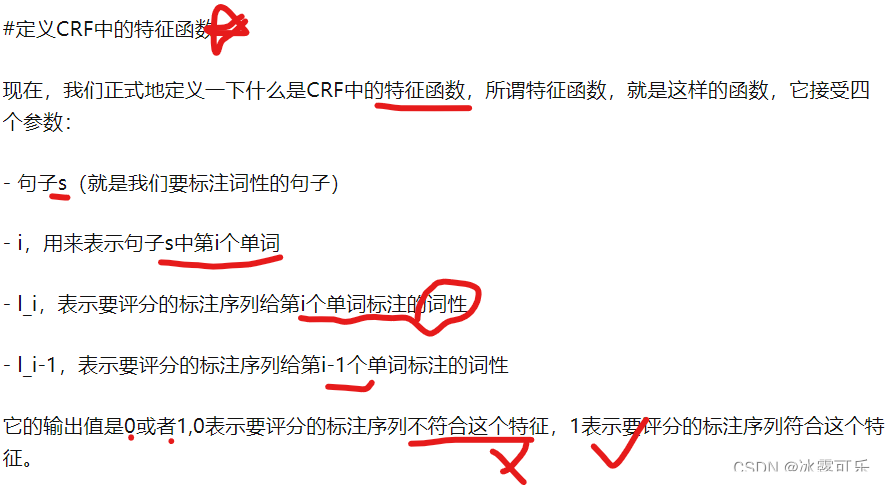
Note:这里,我们的特征函数仅仅依靠当前单词的标签和它前面的单词的标签对标注序列进行评判,这样建立的CRF也叫作线性链CRF,这是CRF中的一种简单情况。为简单起见,本文中我们仅考虑线性链CRF。
上式中有两个相加,外面的相加用来相加每一个特征函数f_j,
里面的相加用来相加句子中每个位置的单词的的特征值。
对这个分数进行指数化和标准化,经过softmax函数,我们就可以得到标注序列l的概率值p(l|s),如下所示:
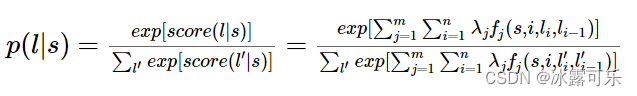
来看几个特征函数的例子
前面我们已经举过特征函数的例子,下面我们再看几个具体的例子,帮助增强大家的感性认识。
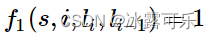

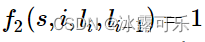

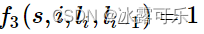

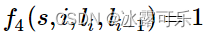

Bert 采用哪种Normalization结构,LayerNorm和BatchNorm区别,LayerNorm结构有参数吗,参数的作用?
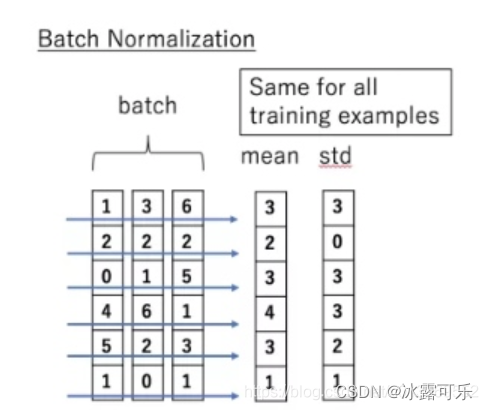
采用LayerNorm结构,和BatchNorm的区别主要是做规范化的维度不同。
BatchNorm针对一个batch里面的数据进行规范化,针对单个神经元进行,比如batch里面有64个样本,那么BatchNorm得到的结果就是输入的这64个样本各自经过这个神经元后的规范化值;
LayerNorm则是针对单个样本的所有维度特征做归一化。比如batch里面有64个样本,那么LayerNorm得到的结果就是每一个样本经过该隐藏层(所有神经元)后的规范化值。
简单来说就是:batch normalization对一个神经元的batch所有样本进行标准化,layer normalization对一个样本同一层所有神经元进行标准化,前者纵向 normalization,后者横向 normalization。
有参数,引入了b再平移参数和w再放缩参数。目的是为了恢复原始数据分布
如何优化BERT效果
感觉最有效的方式是数据扩增。
把现有的大模型ERNIE_2.0_large, Roberta,roberta_wwm_ext_large、roberta-pair-large等进行ensemble,然后蒸馏原始的bert模型,这是能有效提高的,只是操作代价比较大。
BERT上面加一些网络结构,比如attention,rcnn等,个人得到的结果感觉和直接在上面加一层transformer layer的效果差不多,模型更加复杂,效果略好,计算时间略增加。
文本对抗
BERT self-attention相比lstm优点是什么?
lstm的计算过程是从左到右从上到下(如果是多层lstm的话),后一个时间节点的embed需要等前面的计算完,;
而bert通过使用self-attention + position embedding对序列进行编码,与时序无关,可以并行计算,虽然模型复杂了很多,速度其实差不多,而且精度更高。
CNN和RNN结构的可解释性并不强,LSTM也一样;
而BERT 的自注意力可以产生更具可解释性的模型。
LSTM为什么可以解决长期依赖,LSTM会梯度消失吗
因为LSTM中有两个通道在保持记忆:
短期记忆h,保持非线性操作;
长期记忆C,保持线性操作。
因为线性操作是比较稳定的,所以C的变化相对稳定,保持了长期记忆。
而对有用信息的长期记忆是通过训练获得的,也就是说在内部的几个权值矩阵中。
LSTM总可以通过选择合适的参数,在不发生梯度爆炸的情况下,找到合理的梯度方向来更新参数,而且这个方向可以充分地考虑远距离的隐含层信息的传播影响。
另外需要强调的是,LSTM除了在结构上天然地克服了梯度消失的问题,更重要的是具有更多的参数来控制模型;**通过四倍于RNN的参数量,**可以更加精细地预测时间序列变量。
LSTM相较于RNN的优势,RNN为什么难以训练,LSTM又做了什么改进
RNN为什么难以训练
RNN在训练中很容易发生梯度爆炸和梯度消失,这导致训练时梯度不能在较长序列中一直传递下去,从而使RNN无法捕捉到长距离的影响。
LSTM引入三个控制门,拥有了长期记忆,更好的解决了RNN的梯度消失和梯度爆炸的问题。
与简单RNN结构中单一tanh循环体不同的是,LSTM使用三个“门”结构来控制不同时刻的状态和输出。
所谓的“门”结构就是使用了sigmoid激活函数的全连接神经网络和一个按位做乘法的操作,
sigmoid激活函数会输出一个0~1之间的数值,
这个数值描述的是当前有多少信息能通过“门”,
0表示任何信息都无法通过,1表示全部信息都可以通过。
其中,“遗忘门”和“输入门”是LSTM单元结构的核心。
讲一下LSTM,LSTM相对于RNN有哪些改进?LSTM为什么可以解决长期问题,相对与RNN改进在哪
LSTM引入三个控制门,拥有了长期记忆,更好的解决了RNN的梯度消失和梯度爆炸的问题。
与简单RNN结构中单一tanh循环体不同的是,LSTM使用三个“门”结构来控制不同时刻的状态和输出。所谓的“门”结构就是使用了sigmoid激活函数的全连接神经网络和一个按位做乘法的操作,sigmoid激活函数会输出一个0~1之间的数值,这个数值描述的是当前有多少信息能通过“门”,0表示任何信息都无法通过,1表示全部信息都可以通过。其中,“遗忘门”和“输入门”是LSTM单元结构的核心。
wide & deep 模型 wide 部分和 deep 部分分别侧重学习什么信息
在Wide & Deep模型中包括两部分,分别为 Wide模型和Deep模型。
Wide & Deep模型的思想来源是,根据人脑有不断记忆并泛化的过程,
这里将 宽线性模型(Wide Model,用于记忆) 和
深度神经网络模型(Deep Model,用于泛化) 相结合,汲取各自优势形成了Wide & Deep模型,以用于推荐排序。
记忆(Memorization)主要是学习特征的共性/相关性。wide 部分用来学习记忆
泛化(Generalization)可以被理解为相关性的传递(Transitivity),是指算法可以学会特征背后的规律。deep 部分用来学习泛化
deepfm 一定优于 wide & deep 吗
Wide&Deep:同时学习低阶和高阶组合特征,它混合了一个线性模型(Wide part)和Deep模型(Deep part)。这两部分模型需要不同的输入,而Wide part部分的输入,依旧依赖人工特征工程。
**DeepFM:**在Wide&Deep的基础上进行改进,不需要预训练FM得到隐向量,不需要人工特征工程,能同时学习低阶和高阶的组合特征;FM模块和Deep模块共享Feature Embedding部分,可以更快的训练,以及更精确的训练学习。
DeepFM在Wide&Deep的基础上进行改进,从理论上来说是优于wide & deep的,但不能说一定,还要考虑数据量、过拟合等诸多的问题。
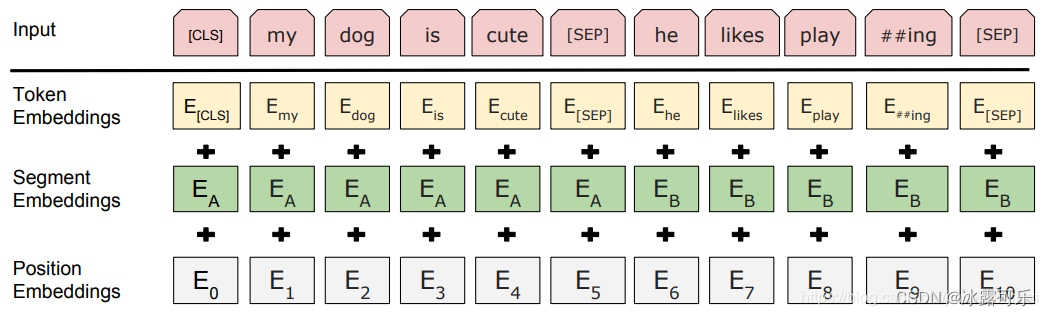
Bert的输入是什么?
输入由三部分组成:
(1)token embedding: token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
(2)segment embedding 段向量, 其中端对应的就是inputs的一句话, **句子末尾都有加[SEP]结尾符,两句拼接开头有[CLS]符号。**是因为BERT里面的下一句的预测任务,所以会有两句拼接起来,上句与下句,上句有上句段向量,下句则有下句段向量,也就是图中A与B。
(3)**position embedding:**是因为 Transformer 模型不能记住时序,所以人为加入表示位置的向量
之后这三个向量拼接起来的输入会喂入BERT模型,输出各个位置的表示向量
Bert的词向量的embedding怎么训练得到的?
token embedding 层是要将各个词转换成固定维度的向量。在BERT中,每个词会被转换成768维的向量表示。
输入文本在送入token embeddings 层之前要先进行tokenization处理。此外,两个特殊的token会被插入到tokenization的结果的开头 ([CLS])和结尾 ([SEP]) 。它们视为后面的分类任务和划分句子对服务的。
tokenization使用的方法是WordPiece tokenization.
这是一个数据驱动式的tokenization方法,旨在权衡词典大小和oov词的个数。
这种方法把例子中的“strawberries”切分成了“straw” 和“berries”。这种方法的详细内容不在本文的范围内。
self-attention理解和作用,为什么要除以根号dk?
稳定梯度!!!
稳定梯度!!!
稳定梯度!!!
Self-Attention是Transformer最核心的内容,其核心内容是为输入向量的每个单词学习一个权重
在self-attention中,每个单词有3个不同的向量,它们分别是Query向量( Q ),Key向量( K)和Value向量( V ),长度均是64。
它们是通过3个不同的权值矩阵由嵌入向量 X 乘以三个不同的权值矩阵 WQ,WK ,WV 得到,其中三个矩阵的尺寸也是相同的。均是 512*64;
Q,K,V这些向量的概念是很抽象,但是它确实有助于计算注意力。相较于RNNs,transformer具有更好的并行性。
作者在论文中的解释是点积后的结果大小是跟维度成正比的,所以经过softmax以后,梯度就会变很小,
除以 dk 后可以让 attention 的权重分布方差为 1,
否则会由于某个输入太大的话就会使得权重太接近于1(softmax 正向接近 1 的部分),梯度很小,造成参数更新困难。
目的就是为了稳定梯度。
BERT中并行计算体现在哪儿
不同于 RNN 计算当前词的特征要依赖于前文计算,有时序这个概念,BERT 的 Transformer-encoder 中的 self-attention 计算当前词的特征时候,没有时序这个概念,
是同时利用上下文信息来计算的,一句话的 token 特征是通过矩阵并行运算的,
故并行就体现在self-attention。
翻译中Q\K\V对应的是什么
分别是Query向量( Q ),
Key向量( K)和
Value向量( V )
attention和self attention的区别
attention 和 self-attention 的计算方法是一样的, 只不过是它们关注的对象不同而已。
attention主要应用在seq2seq+attention中。以seq2seq框架为例,输入Source和输出Target内容是不一样的,
比如对一件商品的评价和总结来说,
Source是一个对一件商品好评或差评的句子,
Target是对应的评价的总结,
Attention发生在Target的元素Query和Source中的所有元素之间。
Self Attention,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的Attention。
介绍transformer以及讲优势
Transformer中抛弃了传统的CNN和RNN,**整个网络结构完全是由Attention机制组成,前后没有“时序”,可以实现并行计算,更高效;**而LSTM是传统的RNN改进结构,有时序的概念,不能并行计算。
两个位置的关联性计算和距离无关,避免长期依赖的问题。
CNN和RNN结构的可解释性并不强,LSTM也一样;而Transformers的自注意力可以产生更具可解释性的模型。
transformer的position encoding和BERT的position embedding的区别
Transformer 中的 positional encoding是直接利用公式计算
BERT Position Embedding:**学习出来的embedding向量。**这与Transformer不同,Transformer中是预先设定好的值。
为什么需要positional encoding 或 position embedding?
在没有 Position embedding 的 Transformer 模型并不能捕捉序列的顺序,交换单词位置后 attention map 的对应位置数值也会进行交换,但并不会产生数值变化,即没有词序信息。所以这时候想要将词序信息加入到模型中。
Transformer 中的 positional encoding
transformer给encoder层和decoder层的输入添加了一个额外的向量Positional Encoding,维度和embedding的维度一样,这个向量采用了一种很独特的方法来让模型学习到这个值,这个向量能决定当前词的位置,或者说在一个句子中不同的词之间的距离。Transformer 是直接利用公式计算:
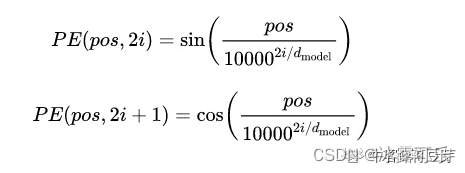
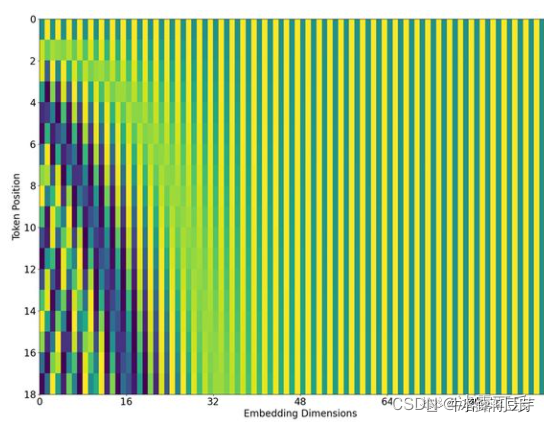
原公式中,pos 是词在词表中出现的位置序号,i 是维度序号。2i 和 2i+1 是交替出现的,所以结果类似下图2所示
ERT的position embedding
bert的位置编码是学出来的,所以称为position embedding。
Position Embedding:学习出来的embedding向量。这与Transformer不同,Transformer中是预先设定好的值。
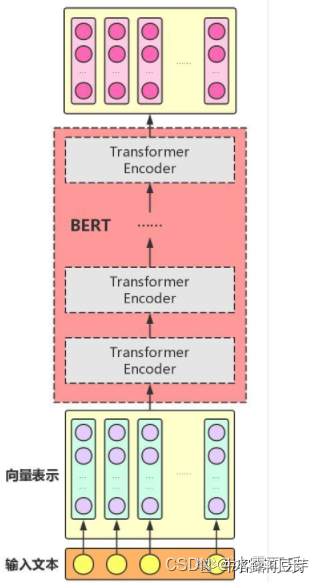
BERT模型结构
BERT模型的全称是:BidirectionalEncoder Representations from Transformer,也就是说,Transformer是组成BERT的核心模块,而Attention机制又是Transformer中最关键的部分,因此,利用Attention机制构建Transformer模块,在此基础上,用多层Transformer组装BERT模型。
Attention机制主要涉及到三个概念:Query、Key和Value。
在上面增强字的语义表示这个应用场景中,目标字及其上下文的字都有各自的原始Value,Attention机制将目标字作为Query、其上下文的各个字作为Key,并将Query与各个Key的相似性作为权重,把上下文各个字的Value融入目标字的原始Value中。该Attention机制也叫Self-Attention。
总结
提示:重要经验:
1)transformer是BERT的基本结构,self-attention又是transformer的重要核心,transformer比CNN,RNN,LSTM牛逼多了,BERT是预训练大模型。
2)Tranformer已经在CV中开挂了,所以不只是NLP里面有这个玩意
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
相关文章
- 2019年百度最新Java工程师面试题
- Java面试题汇总
- (剑指Offer)面试题40:数组中只出现一次的数字
- (剑指Offer)面试题5:从尾到头打印链表
- 2022年最新《Android面试题合集》(含答案解析)-1932页.pdf
- 【备战2022】Android大厂面试题汇总(持续更新中~)
- 18道经典MySQL面试题,祝您升职加薪
- 【面试】社招--三年后端20连问面试题(附答案)
- 面试题 17.10. 主要元素(C++)
- 面试题 17.09. 第 k 个数-动态规划
- 【深度学习】Pytorch面试题:什么是 PyTorch?PyTorch 的基本要素是什么?Conv1d、Conv2d 和 Conv3d 有什么区别?
- Java基础常见面试题总结
- 【面试题系列】Java多线程常见面试题