
复盘:推荐系统—— 负采样策略
复盘:推荐系统—— 负采样策略
提示:系列被面试官问的问题,我自己当时不会,所以下来自己复盘一下,认真学习和总结,以应对未来更多的可能性
关于互联网大厂的笔试面试,都是需要细心准备的
(1)自己的科研经历,科研内容,学习的相关领域知识,要熟悉熟透了
(2)自己的实习经历,做了什么内容,学习的领域知识,要熟悉熟透了
(3)除了科研,实习之外,平时自己关注的前沿知识,也不要落下,仔细了解,面试官很在乎你是否喜欢追进新科技,跟进创新概念和技术
(4)准备数据结构与算法,有笔试的大厂,第一关就是手撕代码做算法题
面试中,实际上,你准备数据结构与算法时以备不时之需,有足够的信心面对面试官可能问的算法题,很多情况下你的科研经历和实习经历足够跟面试官聊了,就不需要考你算法了。但很多大厂就会面试问你算法题,因此不论为了笔试面试,数据结构与算法必须熟悉熟透了
秋招提前批好多大厂不考笔试,直接面试,能否免笔试去面试,那就看你简历实力有多强了。
什么是负采样?为什么要进行负采样?
负采样,顾名思义,就是从一堆负样本中采样出一部分负样本,用于模型的训练。
之所以不采用所有的负样本,主要是为了降低模型的训练复杂度。
在负采样过程中,有几个问题需要重点考虑:
(1)这么多负样本中,到底需要采出哪一部分负样本呢,需要采出多少才合适呢?
换句话说就是,如何保证负样本的质量?
(2)还有考虑采样效率问题,比如需要采出多大数量的负样本?
在推荐系统中,用户喜欢的物品我们认为是正样本,
用户不喜欢物品我们认为是负样本。
而一般情况下,我们很难收集到负样本,且正样本占整个样本集又很少,
所以为了更好地训练模型,我们需要进行负采样,
而且从中采出一部分负例来协助模型的学习,提高模型的性能。
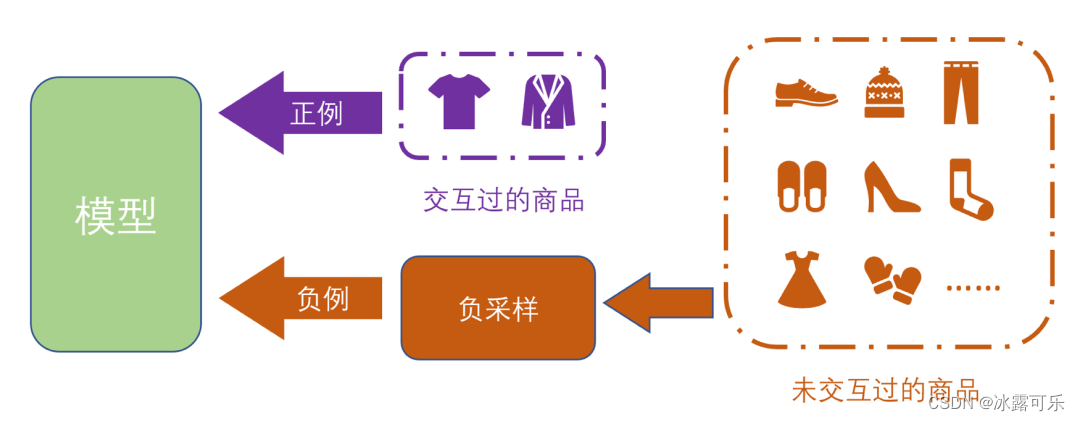
需要注意的是,在推荐系统中,还有一个概念叫伪负样本。
我们一般假设与用户交互过的物品属于正样本,未交互过的都是负样本。
但是这个假设还是比较强的,用户未购买过的物品并不一定是不喜欢的,
也有可能是因为用户没看到,或者是用户在未来会发生交互。
这类样本我们称为伪负样本。
因此,就有对应的问题需要考虑,如何避免、减少这些伪负样本的影响呢?
在Word2Vec中,也有负采样的操作。
在预测单词时,理论上需要对全部单词进行预测,然后取预测值最大的单词。
但是全部单词的数量太多了,计算复杂度太高了,
所以为了降低复杂度,从全部单词中进行采样(这个过程叫负采样),
采出部分单词和目标单词,让模型从中取出预测值最大的单词就行。
负样本的分类?
1、从采样方法的角度来划分,有以下几种方法:基于启发式的算法,基于模型的算法;
基于启发式的算法有:
(1)曝光未点击的样本,当做负样本;
数量建议:按照1:X的比例选择负样本,X可根据数量适当决定,一般建议4、5比较合适。
(2)随机负采样:以用户A来说,从全部样本中,除去与A发生交过的物品外,随机选择物品,作为负样本;
(3)基于流行度的负采样:流行度越高的物品,被当做负样本的概率就越大。
其背后的想法是,越流行的物品,越容易被推荐给用户,
但尽管产品如此流行,用户还仍然没有与它发生交互,
那么用户有更大的概率不喜欢该物品;
(4)基于业务限制理解的生成hard样本,
例如Airbnb在《Real-time Personalization using Embeddings for Search Ranking at Airbnb》一文中的做法,
将与正样本同城的房间当做负样本,将“被房主拒绝”当做负样本;
(5)利用前一轮的模型来选择hard样本,例如把那些排名靠后的样本作为负样本,拿召回位置在101 ~ 500的物品。
基于模型的算法有:
(1)动态采样法:在模型训练过程中,利用上一轮对样本进行评分,
通过评分来修改负样本的采样概率,评分越高,被采样的概率越大。
背后的思想是,对于那些负样本,如果模型给出了更高的评分,
那说明模型认为用户可能会与该物品发生交互,
但实际情况却是用户没有与该物品发生交互,
那么这个物品有更大的概率成为负样本。
但是这有个问题,就是伪负样本的问题;
(2)基于GAN:可参考https://zhuanlan.zhihu.com/p/387378387,但是通过博客和一些评论,貌似在业界实践中,该方法不怎么work [3];
(3)SRNS:作者通过观察到的统计学特征作为先验知识,来协助负样本的采样,更好地区分伪负样本和强负样本。
2、从采样效率的角度来看,有以下几种方法:inbatch采样、uniform采样、MNS采样、CBNS采样;
(1)**inbatch采样:**即在模型训练过程中,对于batch中每一个用户,
将batch中的其他用户交互的物品,当做是该用户的负样本,
这样做可以提高模型训练的速度。
但是这种方法有问题,因为会有sample selection bias问题(简称SSB)
(2)**uniform采样:**即模型在训练之前,先给每个用户按照一定的方法(随机负采样、基于流行度负采样等)采出一定量的负样本,然后再继续模型训练。
(3)MNS采样(Mixed Negative Sampling):即简单粗暴地讲上述的inbatch采样和uniform采样进行融合
(4)CBNS采样(Cross-Batch Negative Sampling)[6]:其背后思想也是利用inbatch中的信息和cross batch中的信息,利用前后的batch中的信息来缓解SSB问题。
3、从推荐流程的角度来看,分为召回阶段的负采样方法,和排序阶段中的负采样方法。
推荐流程可以简单划分为召回 ->粗排 ->精排,不同阶段使用的负采样方法不太一样,也就是说学问不一样。
在排序阶段中,可以使用“曝光未点击”作为负样本,但在召回阶段,这种做法效果不佳。
这具体是什么原因呢?在博客https://www.jianshu.com/p/2f64f49e43cd中提到,提到了以下4个解释:
(1)排序算法是优中选优,曝光未点击天生就是负样本,召回算法面对的候选样本太多,鱼龙混杂,更需要具备在更大的数据集中增加自己的“见识”,也就是更需要见见那些曝光没那么高的样本
(2)曝光未点击的样本已经是经过召回,排序选出来的系统认为的用户喜欢的物品,也就是说这些样本已经是上一个版本召回模型选出来正样本了,如果我们把这些样本当作新召回模型的负样本,就有矛盾了
(3)如果选择曝光未点击的样本作为负样本,那么召回模型就会陷入“一叶障目,不见泰山”的困境,也就是说模型只会鉴别那些高曝光的样本了,对于那些没出现过,少出现的样本,它根本区分不出来这是正样本还是负样本
(4)最重要的还是因为实验中,这么做的话效果很差
那问题来了,召回阶段,我们该怎么做的?
最简单的做法是随机负采样,
或者是将前一轮召回模型中排名靠后的样本当做是负样本,
或者根据业务逻辑来产生hard负样本等等。
总结
提示:重要经验:
1)最常规的还是曝光未点击作为负样本:1:x=4,5的比例采样
2)然后就是未点击的所有样本随机采样
3)笔试求AC,可以不考虑空间复杂度,但是面试既要考虑时间复杂度最优,也要考虑空间复杂度最优。
相关文章
- 与答辩有关_推荐系统
- 监控系统-Grafana
- [Kernel]理解System call系统调用
- SOYO的主板如何进入BIOS系统
- 【学习总结】推荐系统-一句话总结各种问题版
- windows如何访问wsl系统下的文件
- 告别1人年,教你21天搭建推荐系统!
- 机器学习笔记 - 构建推荐系统(2) 深度推荐系统概览
- 在SAP CAL(Cloud Application Library)上搭建ABAP HANA系统
- 你不能错过的“推荐系统”资料合集
- Atitit 遗留系统的改造 微创技术 attilax总结 目录 1. 微创是高科技带来的革命!1 1.1. 早期微创1 1.2. 微创五大优点1 2. 常用辅助设备与模块2 2.1. 清晰
- 华为云PB级数据库GaussDB(for Redis)揭秘第13期:如何搞定推荐系统存储难题
- Python基于深度学习算法实现图书推荐系统项目实战
- 分布式消息系统Jafka入门指南
- 【推荐系统算法实战】Flink 架构及其工作原理
- 计算机毕设 SSM Vue 大学生就业推荐系统(含源码+论文)
- 08windows系统把docker 镜像保存gz.tar之后,再把gz.tar文件上传至Linux系统,如何用singularity打开docker的tar文件 并保存为sif文件
- 立波 iphone3gs越狱教程:成功把iphone3gs手机升级成ios6.1.3系统,完美越狱,解决no service和耗电量大的问题
- 菜鸟进阶数据大牛:如何系统学习BI商业智能
- 安装程序无法创建新的系统分区
- 20个Linux系统监视工具
- 推荐系统-Task05推荐系统流程构建
- 【2023年第十一届泰迪杯数据挖掘挑战赛】C题:泰迪内推平台招聘与求职双向推荐系统构建 建模及python代码详解 问题三
- 推荐系统(7):推荐算法之基于协同过滤推荐算法
- 推荐系统(1):推荐系统概述
- Tomcat 系统架构(下):聊聊多层容器的设计
- 推荐系统算法02:通俗易懂协同过滤算法实现
- 完美解决Ubuntu下无法获得锁 / 检测到系统程序错误 / E: Could not get lock /var/lib/apt/lists/lock
- PVE虚拟化平台之安装iStoreOS软路由系统