
Python的Numpy库的ndarray对象常用构造方法及初始化方法
Python的Numpy库的ndarray对象常用构造方法及初始化方法
本文收集Python的Numpy库的ndarray对象常用的构造方法及初始化方法,会不断更新。
目录
1 直接赋值初始化一个ndarray对象
示例代码如下:
A = np.array([[1, 2, 3, 4, 5],
[6, 7, 8, 9, 10],
[11, 12, 13, 14, 15],
[16, 17, 18, 19, 20],
[21, 22, 23, 24, 25]], dtype='int8')
上面代码中的第二个参数dtype是可选的,如果不填,则系统根据矩阵元素的数据大小来确定。
上面的代码创建的是二维矩阵,我们再看一个创建三维矩阵的例子。
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import numpy as np
B = np.array([[[11, 12, 13, 14],
[15, 16, 17, 18]],
[[19, 20, 21, 22],
[23, 24, 25, 26]],
[[27, 28, 29, 30],
[31, 32, 33, 34]]])
运行结果如下图所示:
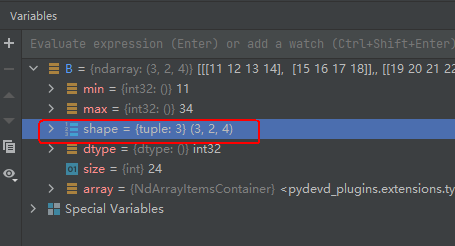
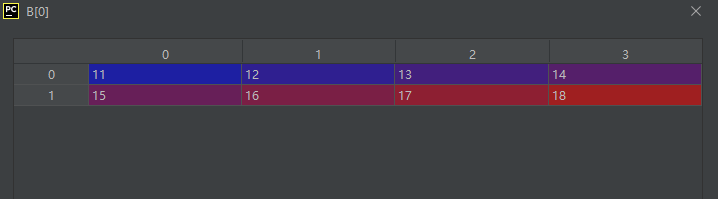
从其shape属性可以看出,B矩阵的尺寸为三通道,两行,四列。其内容如下:


2 浅拷贝与深拷贝
2-1 通过"="赋值初始化一个新的ndarray对象(浅拷贝)
示例代码如下:
import numpy as np
B = np.array([[[11, 12, 13, 14],
[15, 16, 17, 18]],
[[19, 20, 21, 22],
[23, 24, 25, 26]],
[[27, 28, 29, 30],
[31, 32, 33, 34]]])
C = B
C[0, 0, 0] = 100
运行结果如下所示:
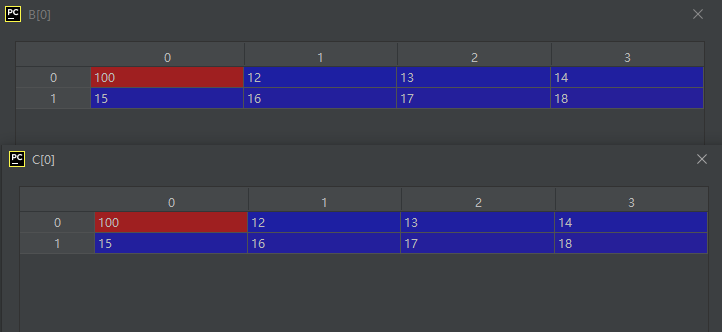
从上图的结构中我们可以看到,对于ndarray对象,通过“=”赋值得到的新对象和原对象共用数据存储区,即实现的是浅拷贝,修改其中一个对象的数据值会影响到另一个对象的数据值。
2-2 通过copy()方法实现深拷贝
示例代码如下:
import numpy as np
A1 = np.zeros((4, 4), dtype='uint8')
# 通过函数copy()实现深拷贝
B1 = A1.copy()
B1[1, 1] = 1
运行结果如下:

从运行结果中可以看出,对B1[1, 1]的修改没有影响到A中对应元素的值,所以通过方法cpoy()实现的是深拷贝。
3 创建和原矩阵大小一样、通道一样,但是数据类型和原矩阵不一样的全0矩阵
示例代码如下:
import numpy as np
B = np.array([[[11, 12, 13, 14],
[15, 16, 17, 18]],
[[19, 20, 21, 22],
[23, 24, 25, 26]],
[[27, 28, 29, 30],
[31, 32, 33, 34]]])
C = B
C = 0*C
C = C.astype('float32')
运行结果如下:
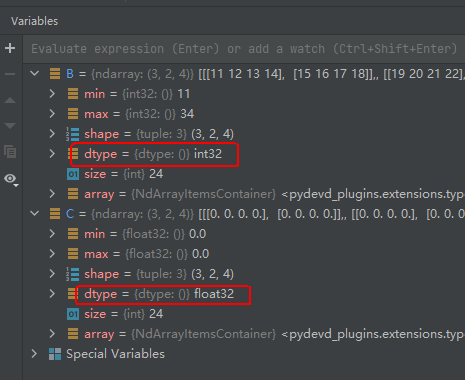
注意:在2中提到通过“=”赋值得到的新ndarray对象和原对象共享存储空间(浅拷贝),但由于这里使用了乘法运算符,所以会为结果构建一个新的ndarray对象,并为其分配新的存储空间,所以通过上面代码的一系列操作得到的是深拷贝。
4 通过函数ones()、zeros()创建指定大小和数据类型且元素值全为1或0的二维或多维矩阵
我们可以通过函数ones()、zeros()创建二维或多维矩阵,比如我们可以通过下面这条语句创建二通道、三行、四列的三维矩阵。
示例代码如下:
4-1 创建元素值全为1的二维矩阵
import numpy as np
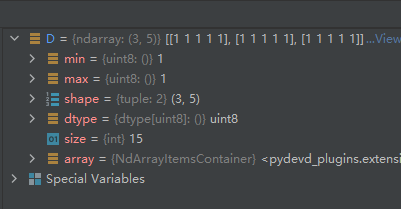
D = np.ones((3, 5), dtype='uint8')
运行结果如下:
4-2 创建元素值全为0的二通道、三行、四列的三维矩阵
import numpy as np
D = np.zeros((2, 3, 4), dtype='uint8')
运行结果如下:
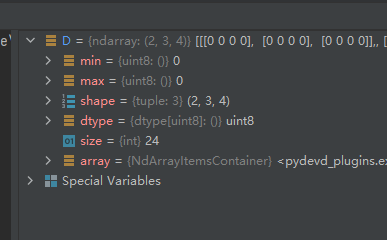
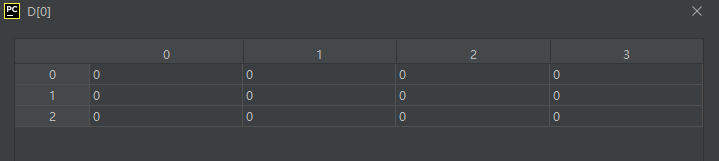
从这个结果我们可以看出,第一个索引代表通道数(也称为页数),第二个索引代表行数,第三个索引代表列数。要特别注意,OpenCV的函数imread()读到的图像数据的三个索引值并不是这个顺序,详情见 https://www.hhai.cc/thread-89-1-1.html
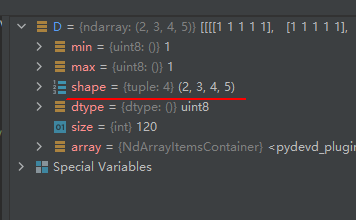
4-3 创建元素值全为1的四维矩阵
D = np.ones((2, 3, 4, 5), dtype='uint8')
5 创建指定大小、指定数据类型、数据值按均匀分布生成的整数矩阵
示例代码如下:
F = np.random.randint(0, 100, (3, 5), dtype='uint8')
运行结果略。
6 创建指定大小、数据值按正态分布(均值为0,标准差为1)生成的矩阵
K = np.random.randn(2, 3)
注意:函数randn()不能设置数据类型,也不能设置正态分布的均值和标准差,其原型如下:
random.randn(d0, d1, ..., dn)
运行结果如下:
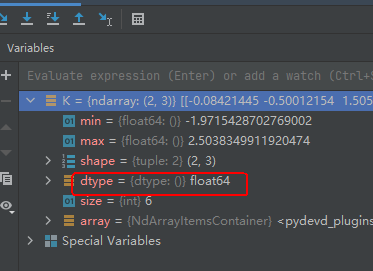
从上图我们可以看出,得到的ndarray对象的数据类型为float64。
相关文章
- python之微信公众号开发(基本配置和校验)
- Python 文件操作
- <<Python基础教程>>学习笔记 | 第10章 | 充电时刻
- Python 卸载python
- Python PIL(图像处理库)使用方法
- 地球引擎初级教程——Python API 介绍何安装(通过 Anaconda方法安装)
- Python初学者如何系统的学习python————Python入门学习指南--内附学习路径
- 零基础小白如何学Python?这些方法你需要了解!
- Python的Numpy库的函数astype()在将大范围数据类型转换为小范围数据类型时并不是做饱和(saturate)操作(附实现饱和操作的方法)
- 超详细python接口自动化测试requests实战教学(详全)
- 《Python数据挖掘:概念、方法与实践》一2.2 迈向关联规则
- 《python 与数据挖掘 》一 2.6 上机实验
- Python删除txt文档中含有特定词语的行
- 基于python的wav转txt的源码
- python 判断bytes是否相等的几种方法
- 利用Python的collections包下Counter的类统计每个数据出现的个数
- python之函数用法iter()
- 《Python面向对象编程指南》——2.7 __del__()方法
- 《Python算法教程》——第2章 基础知识 2.1 计算领域中一些核心理念
- Python 文件读写小结
- 数据科学必备Python使用Numpy方法汇总
- Python IDE 安装 PyCharm 的正确姿势以及更新方法
- Python测试前置操作的方法
- python迭代器协议支持的两种方法
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(6) —— Python版本实现的《2048》游戏环境运行性能对比
- Python itertools.combinations 和 itertools.permutations 等价代码实现
- Python Kivy安装及使用PyCharm进行简单测试(讲解如何参照kivy官方说明安装测试)
- 9. python爬虫——高性能单线程 / 多线程 / 线程池 / 异步爬虫使用方法教学
- Python数据结构与算法(7)--图及其算法
- Python 常见问题 之 python 安装包下载安装速度慢 的 快速解决方法(之一)
- Python django写视图函数request的方法和属性没有自动补全代码提示(包括写其他代码的时候函数参数的变量没有代码提示)
- Selenium4 Python实现Page Factory设计模式,python新的定位方法