
99 python高级 - 垃圾回收(二)
1. Garbage collection(GC垃圾回收)
现在的高级语言如java,c#等,都采用了垃圾收集机制,而不再是c,c++里用户自己管理维护内存的方式。自己管理内存极其自由,可以任意申请内存,但如同一把双刃剑,为大量内存泄露,悬空指针等bug埋下隐患。 对于一个字符串、列表、类甚至数值都是对象,且定位简单易用的语言,自然不会让用户去处理如何分配回收内存的问题。 python里也同java一样采用了垃圾收集机制,不过不一样的是: python采用的是引用计数机制为主,标记-清除和分代收集两种机制为辅的策略
引用计数机制:
python里每一个东西都是对象,它们的核心就是一个结构体:PyObject
typedef struct_object {
int ob_refcnt;
struct_typeobject *ob_type;
} PyObject;
PyObject是每个对象必有的内容,其中ob_refcnt就是做为引用计数。当一个对象有新的引用时,它的ob_refcnt就会增加,当引用它的对象被删除,它的ob_refcnt就会减少。
#define Py_INCREF(op) ((op)->ob_refcnt++) //增加计数
#define Py_DECREF(op) \ //减少计数
if (--(op)->ob_refcnt != 0) \
; \
else \
__Py_Dealloc((PyObject *)(op))
当引用计数为0时,该对象生命就结束了。
引用计数机制的优点:
- 简单
- 实时性:一旦没有引用,内存就直接释放了。不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时。
引用计数机制的缺点:
- 维护引用计数消耗资源
- 循环引用
list1 = []
list2 = []
list1.append(list2)
list2.append(list1)
list1与list2相互引用,如果不存在其他对象对它们的引用,list1与list2的引用计数也仍然为1,所占用的内存永远无法被回收,这将是致命的。 对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制。(标记清除和分代收集)。
2.画说 Ruby 与 Python 垃圾回收
英文原文: http://patshaughnessy.net/2013/10/24/visualizing-garbage-collection-in-ruby-and-python
2.1 应用程序那颗跃动的心
GC系统所承担的工作远比"垃圾回收"多得多。实际上,它们负责三个重要任务。它们
- 为新生成的对象分配内存
- 识别那些垃圾对象,并且
- 从垃圾对象那回收内存。
如果将应用程序比作人的身体:所有你所写的那些优雅的代码,业务逻辑,算法,应该就是大脑。以此类推,垃圾回收机制应该是那个身体器官呢?(我从RuPy听众那听到了不少有趣的答案:腰子、白血球 ? )
我认为垃圾回收就是应用程序那颗跃动的心。像心脏为身体其他器官提供血液和营养物那样,垃圾回收器为你的应该程序提供内存和对象。如果心脏停跳,过不了几秒钟人就完了。如果垃圾回收器停止工作或运行迟缓,像动脉阻塞,你的应用程序效率也会下降,直至最终死掉。
2.2 一个简单的例子
运用实例一贯有助于理论的理解。下面是一个简单类,分别用Python和Ruby写成,我们今天就以此为例:

顺便提一句,两种语言的代码竟能如此相像:Ruby 和 Python 在表达同一事物上真的只是略有不同。但是在这两种语言的内部实现上是否也如此相似呢?
2.3 Ruby 的对象分配
当我们执行上面的Node.new(1)时,Ruby到底做了什么?Ruby是如何为我们创建新的对象的呢? 出乎意料的是它做的非常少。实际上,早在代码开始执行前,Ruby就提前创建了成百上千个对象,并把它们串在链表上,名曰:可用列表。下图所示为可用列表的概念图:

想象一下每个白色方格上都标着一个"未使用预创建对象"。当我们调用 Node.new ,Ruby只需取一个预创建对象给我们使用即可:

上图中左侧灰格表示我们代码中使用的当前对象,同时其他白格是未使用对象。(请注意:无疑我的示意图是对实际的简化。实际上,Ruby会用另一个对象来装载字符串"ABC",另一个对象装载Node类定义,还有一个对象装载了代码中分析出的抽象语法树,等等)
如果我们再次调用 Node.new,Ruby将递给我们另一个对象:

这个简单的用链表来预分配对象的算法已经发明了超过50年,而发明人这是赫赫有名的计算机科学家John McCarthy,一开始是用Lisp实现的。Lisp不仅是最早的函数式编程语言,在计算机科学领域也有许多创举。其一就是利用垃圾回收机制自动化进行程序内存管理的概念。
标准版的Ruby,也就是众所周知的"Matz’s Ruby Interpreter"(MRI),所使用的GC算法与McCarthy在1960年的实现方式很类似。无论好坏,Ruby的垃圾回收机制已经53岁高龄了。像Lisp一样,Ruby预先创建一些对象,然后在你分配新对象或者变量的时候供你使用。
2.4 Python 的对象分配
我们已经了解了Ruby预先创建对象并将它们存放在可用列表中。那Python又怎么样呢?
尽管由于许多原因Python也使用可用列表(用来回收一些特定对象比如 list),但在为新对象和变量分配内存的方面Python和Ruby是不同的。
例如我们用Pyhon来创建一个Node对象:
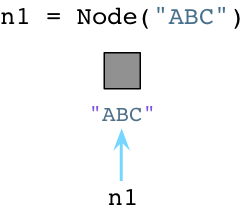
与Ruby不同,当创建对象时Python立即向操作系统请求内存。(Python实际上实现了一套自己的内存分配系统,在操作系统堆之上提供了一个抽象层。但是我今天不展开说了。)
当我们创建第二个对象的时候,再次像OS请求内存:
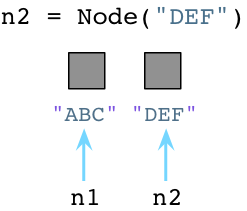
看起来够简单吧,在我们创建对象的时候,Python会花些时间为我们找到并分配内存。
2.5 Ruby 开发者住在凌乱的房间里

Ruby把无用的对象留在内存里,直到下一次GC执行
回过来看Ruby。随着我们创建越来越多的对象,Ruby会持续寻可用列表里取预创建对象给我们。因此,可用列表会逐渐变短:

…然后更短:

请注意我一直在为变量n1赋新值,Ruby把旧值留在原处。“ABC”,"JKL"和"MNO"三个Node实例还滞留在内存中。Ruby不会立即清除代码中不再使用的旧对象!Ruby开发者们就像是住在一间凌乱的房间,地板上摞着衣服,要么洗碗池里都是脏盘子。作为一个Ruby程序员,无用的垃圾对象会一直环绕着你。
2.6 Python 开发者住在卫生之家庭

用完的垃圾对象会立即被Python打扫干净
Python与Ruby的垃圾回收机制颇为不同。让我们回到前面提到的三个Python Node对象:
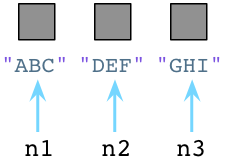
在内部,创建一个对象时,Python总是在对象的C结构体里保存一个整数,称为 引用数。期初,Python将这个值设置为1:
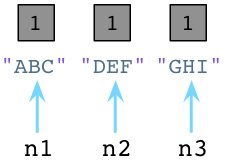
值为1说明分别有个一个指针指向或是引用这三个对象。假如我们现在创建一个新的Node实例,JKL:

与之前一样,Python设置JKL的引用数为1。然而,请注意由于我们改变了n1指向了JKL,不再指向ABC,Python就把ABC的引用数置为0了。 此刻,Python垃圾回收器立刻挺身而出!每当对象的引用数减为0,Python立即将其释放,把内存还给操作系统:

上面Python回收了ABC Node实例使用的内存。记住,Ruby弃旧对象原地于不顾,也不释放它们的内存。
Python的这种垃圾回收算法被称为引用计数。是George-Collins在1960年发明的,恰巧与John McCarthy发明的可用列表算法在同一年出现。就像Mike-Bernstein在6月份哥谭市Ruby大会杰出的垃圾回收机制演讲中说的: “1960年是垃圾收集器的黄金年代…”
Python开发者工作在卫生之家,你可以想象,有个患有轻度OCD(一种强迫症)的室友一刻不停地跟在你身后打扫,你一放下脏碟子或杯子,有个家伙已经准备好把它放进洗碗机了!
现在来看第二例子。加入我们让n2引用n1:
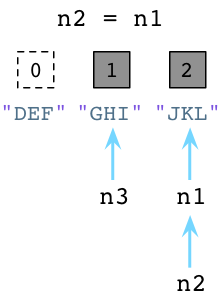
上图中左边的DEF的引用数已经被Python减少了,垃圾回收器会立即回收DEF实例。同时JKL的引用数已经变为了2 ,因为n1和n2都指向它。
2.7 标记-清除
最终那间凌乱的房间充斥着垃圾,再不能岁月静好了。在Ruby程序运行了一阵子以后,可用列表最终被用光光了:
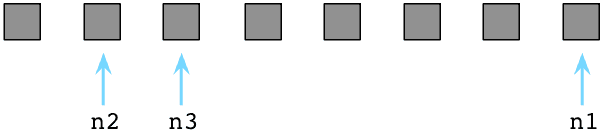
此刻所有Ruby预创建对象都被程序用过了(它们都变灰了),可用列表里空空如也(没有白格子了)。
此刻Ruby祭出另一McCarthy发明的算法,名曰:标记-清除。首先Ruby把程序停下来,Ruby用"地球停转垃圾回收大法"。之后Ruby轮询所有指针,变量和代码产生别的引用对象和其他值。同时Ruby通过自身的虚拟机便利内部指针。标记出这些指针引用的每个对象。我在图中使用M表示。

上图中那三个被标M的对象是程序还在使用的。在内部,Ruby实际上使用一串位值,被称为:可用位图(译注:还记得《编程珠玑》里的为突发排序吗,这对离散度不高的有限整数集合具有很强的压缩效果,用以节约机器的资源。),来跟踪对象是否被标记了。

如果说被标记的对象是存活的,剩下的未被标记的对象只能是垃圾,这意味着我们的代码不再会使用它了。我会在下图中用白格子表示垃圾对象:
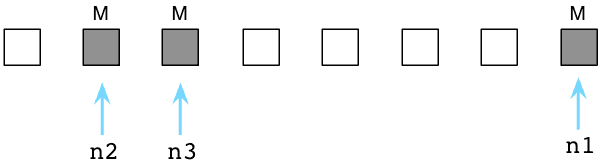
接下来Ruby清除这些无用的垃圾对象,把它们送回到可用列表中:

在内部这一切发生得迅雷不及掩耳,因为Ruby实际上不会吧对象从这拷贝到那。而是通过调整内部指针,将其指向一个新链表的方式,来将垃圾对象归位到可用列表中的。
现在等到下回再创建对象的时候Ruby又可以把这些垃圾对象分给我们使用了。在Ruby里,对象们六道轮回,转世投胎,享受多次人生。
2.8 标记-删除 vs. 引用计数
愿定期强制程序停止运行,也不使用Python的算法呢?
然而,引用计数并不像第一眼看上去那样简单。有许多原因使得不许多语言不像Python这样使用引用计数GC算法:
首先,它不好实现。Python不得不在每个对象内部留一些空间来处理引用数。这样付出了一小点儿空间上的代价。但更糟糕的是,每个简单的操作(像修改变量或引用)都会变成一个更复杂的操作,因为Python需要增加一个计数,减少另一个,还可能释放对象。
第二点,它相对较慢。虽然Python随着程序执行GC很稳健(一把脏碟子放在洗碗盆里就开始洗啦),但这并不一定更快。Python不停地更新着众多引用数值。特别是当你不再使用一个大数据结构的时候,比如一个包含很多元素的列表,Python可能必须一次性释放大量对象。减少引用数就成了一项复杂的递归过程了。
最后,它不是总奏效的。引用计数不能处理环形数据结构–也就是含有循环引用的数据结构。
相关文章
- Python dir
- Python中的高级数据结构(转)
- Python 日期和时间_python 当前日期时间_python日期格式化
- Python 字符串_python 字符串截取_python 字符串替换_python 字符串连接
- Windows环境下配置Python虚拟环境
- python实现收邮件判断模块poplib,email
- 使用Python读取照片的GPS信息
- 【Python五篇慢慢弹】数据结构看python
- Python实现的选择排序算法原理与用法实例分析
- 100天精通Python(基础篇)——第33天:数学相关模块math、decimal基础+代码实战
- 【python代码】:能在手机上敲 Python 代码几款App
- 〖Python WEB 自动化测试实战篇③〗- python-selenium环境配置搭建
- python迭代器高级例子
- 再见Pyechart,一个非常棒的 Python 统计图表库来了!
- python高级编程读书笔记(一)
- Python编程:python面向对象
- python 查询 elasticsearch 常用方法(Query DSL)
- 多版本Python共存时pip给指定版本的python安装package的方法
- Python 高级编程之面向对象(一)
- 【ML吴恩达】2 Python的机器学习相关库libraries
- 【异常】前端ERR! stack Error: Can‘t find Python executable “python“, you can set the PYTHON env variable.
- 〖Python自动化办公篇⑲〗 - python实现邮件自动化 - 邮件发送