
一文看懂推荐系统:排序14:PNN模型(Product-based Neural Networks),和FNN一个作者,干掉FM,加上LR+Product
一文看懂推荐系统:排序14:PNN模型(Product-based Neural Networks),和FNN一个作者,干掉FM,加上LR+Product
提示:最近系统性地学习推荐系统的课程。我们以小红书的场景为例,讲工业界的推荐系统。
我只讲工业界实际有用的技术。说实话,工业界的技术远远领先学术界,在公开渠道看到的书、论文跟工业界的实践有很大的gap,
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
看书学不到推荐系统的关键技术。
王树森娓娓道来**《小红书的推荐系统》**
GitHub资料连接:http://wangshusen.github.io/
B站视频合集:https://space.bilibili.com/1369507485/channel/seriesdetail?sid=2249610
基础知识:
【1】一文看懂推荐系统:概要01:推荐系统的基本概念
【2】一文看懂推荐系统:概要02:推荐系统的链路,从召回粗排,到精排,到重排,最终推荐展示给用户
【3】一文看懂推荐系统:召回01:基于物品的协同过滤(ItemCF),item-based Collaboration Filter的核心思想与推荐过程
【4】一文看懂推荐系统:召回02:Swing 模型,和itemCF很相似,区别在于计算相似度的方法不一样
【5】一文看懂推荐系统:召回03:基于用户的协同过滤(UserCF),要计算用户之间的相似度
【6】一文看懂推荐系统:召回04:离散特征处理,one-hot编码和embedding特征嵌入
【7】一文看懂推荐系统:召回05:矩阵补充、最近邻查找,工业界基本不用了,但是有助于理解双塔模型
【8】一文看懂推荐系统:召回06:双塔模型——模型结构、训练方法,召回模型是后期融合特征,排序模型是前期融合特征
【9】一文看懂推荐系统:召回07:双塔模型——正负样本的选择,召回的目的是区分感兴趣和不感兴趣的,精排是区分感兴趣和非常感兴趣的
【10】一文看懂推荐系统:召回08:双塔模型——线上服务需要离线存物品向量、模型更新分为全量更新和增量更新
【11】一文看懂推荐系统:召回09:地理位置召回、作者召回、缓存召回
【12】一文看懂推荐系统:排序01:多目标模型
【13】一文看懂推荐系统:排序02:Multi-gate Mixture-of-Experts (MMoE)
【14】一文看懂推荐系统:排序03:预估分数融合
【15】一文看懂推荐系统:排序04:视频播放建模
【16】一文看懂推荐系统:排序05:排序模型的特征
【17】一文看懂推荐系统:排序06:粗排三塔模型,性能介于双塔模型和精排模型之间
【18】一文看懂推荐系统:特征交叉01:Factorized Machine (FM) 因式分解机
【19】一文看懂推荐系统:物品冷启01:优化目标 & 评价指标
【20】一文看懂推荐系统:物品冷启02:简单的召回通道
【21】一文看懂推荐系统:物品冷启03:聚类召回
【22】一文看懂推荐系统:物品冷启04:Look-Alike 召回,Look-Alike人群扩散
【23】一文看懂推荐系统:物品冷启05:流量调控
【24】一文看懂推荐系统:物品冷启06:冷启的AB测试
【25】推荐系统最经典的 排序模型 有哪些?你了解多少?
【26】一文看懂推荐系统:排序07:GBDT+LR模型
【27】一文看懂推荐系统:排序08:Factorization Machines(FM)因子分解机,一个特殊的案例就是MF,矩阵分解为uv的乘积
【28】一文看懂推荐系统:排序09:Field-aware Factorization Machines(FFM),从FM改进来的,效果不咋地
【29】一文看懂推荐系统:排序10:wide&deep模型,wide就是LR负责记忆,deep负责高阶特征交叉而泛化
【30】一文看懂推荐系统:排序11:Deep & Cross Network(DCN)
【31】一文看懂推荐系统:排序12:xDeepFM模型,并不是对DeepFM的改进,而是对DCN的改进哦
【32】一文看懂推荐系统:排序13:FNN模型(FM+MLP=FNN),与PNN同属上海交大张楠的作品
提示:文章目录
文章目录
一、动机
PNN模型(Product-based Neural Networks)和上一篇博客介绍的FNN模型一样,
都是出自交大张伟楠老师及其合作者,
这篇paper发表在ICDM’2016上,是个CCF-B类会议,
这个模型我个人基本上没听到过工业界哪个公司在自己的场景下实践过,
但我们依然可以看看这篇paper的成果,
也许能为自己的业务模型提供一些参考借鉴意义。
通过这个模型的名字Product-based Neural Networks,
我们也基本可以略知PNN是通过引入product(可以是内积也可以是外积)来达到特征交叉的目的。
这篇博客将从动机和模型细节两方面进行介绍。
动机方面:
这篇paper主要改进的是上一篇博客介绍的FNN,FNN主要存在两个缺点:
DNN的embedding层质量受限于FM的训练质量。
在FM中进行特征交叉时使用的是隐向量点积,
把FM预训练得到的embedding向量送入到MLP中的全链接层,
MLP的全链接层本质上做的是特征间的线性加权求和,即做的是『add』的操作,
这与FM有点不太统一。
另外,MLP中忽略了不同的field之间的区别,全部采用线性加权求和。
论文原文为:
the quality of embedding initialization is largely limited by the factorization machine.、
More importantly, the “add” operations of the perceptron layer might not be useful to explore the interactions of categorical data in multiple fields. Previous work [1], [6] has shown that local dependencies between features from different fields can be effectively explored by feature vector “product” operations instead of “add” operations.
其实个人认为FNN还有个很大的局限性:
FNN是个两阶段训练的模型,并不是个data-driven的end-to-end模型,
FNN身上还是有浓厚的传统机器学习的影子。
二、PNN模型细节
2.1 PNN模型整体结构
PNN的网络结构如下图所示(图片摘自原论文)
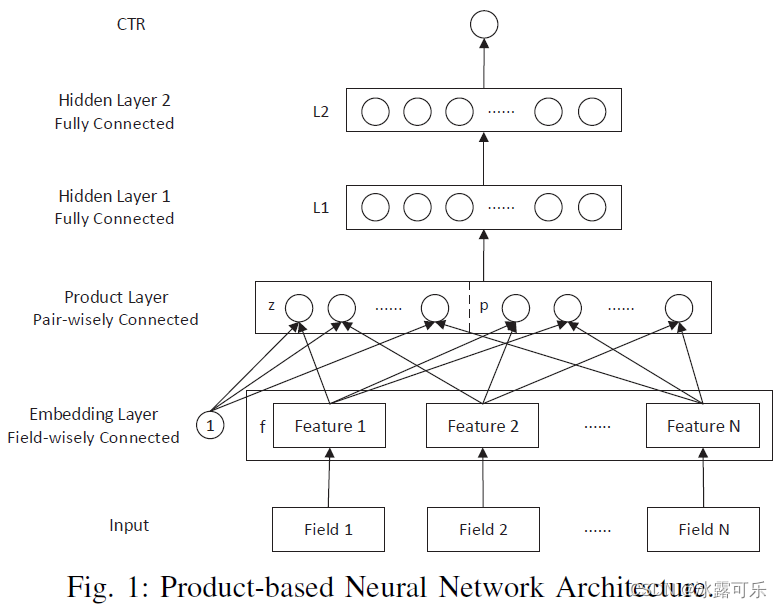

其实原图不应该画成那么简单
应该像下图一样
明确zp是要映射到lz lp的
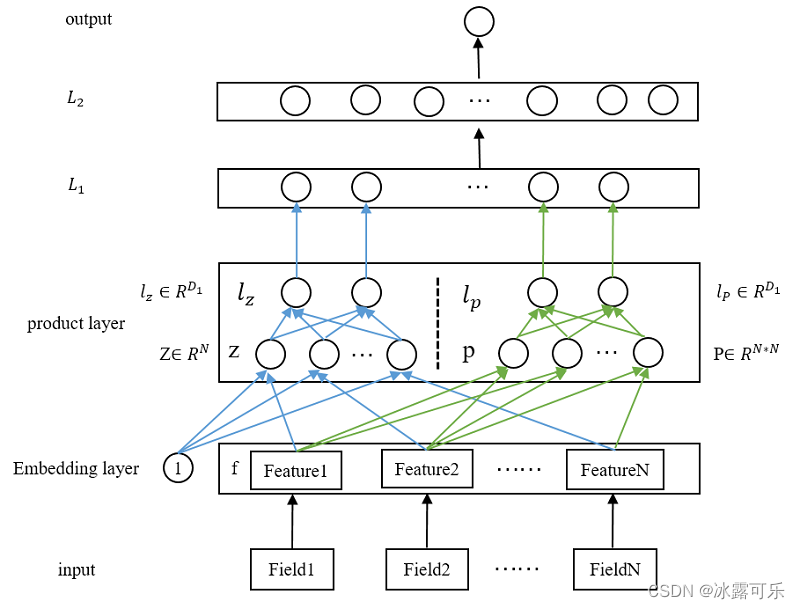
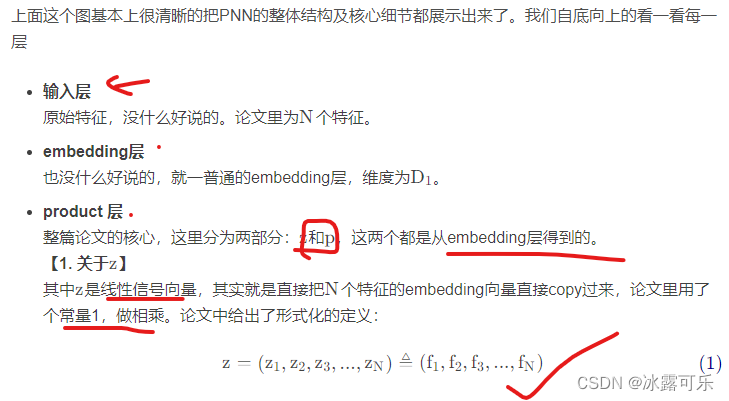
其实z就是LR部分
因此本模型实际上是LR+PNN




2.2 IPNN
在product层,对特征embedding向量做交叉,
理论上可以是任何操作,这篇paper给出了两种方式:内积和外积,
分别对应IPNN和OPNN。
从复杂度的角度来看,IPNN复杂度低于OPNN,
因此如果打算工业落地的话,就不要考虑OPNN了,因此我会比较详细的介绍IPNN。
IPNN,即在product层做内积操作,
依据上面给出的内积定义,能够看出两个向量的内积结果为一个标量。形式化的表示为:

上面这一串公式一上,估计还有兴趣看这篇博客的人不足10%了,太晦涩难懂了。
想要别人看的懂,最简单的办法就是举例子,
咱们直接上例子,
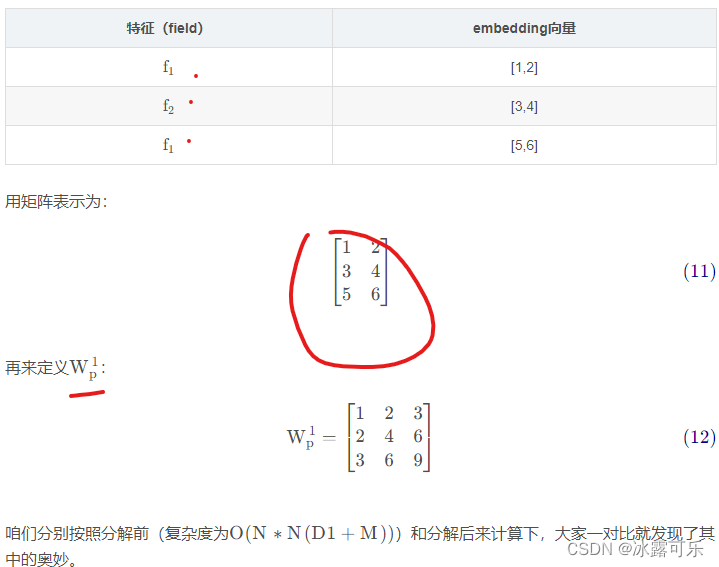
假设咱们样本有3个特征,每个特征的embedding维度为2,即N = 3 , M = 2
所以咱们有如下一条样本:

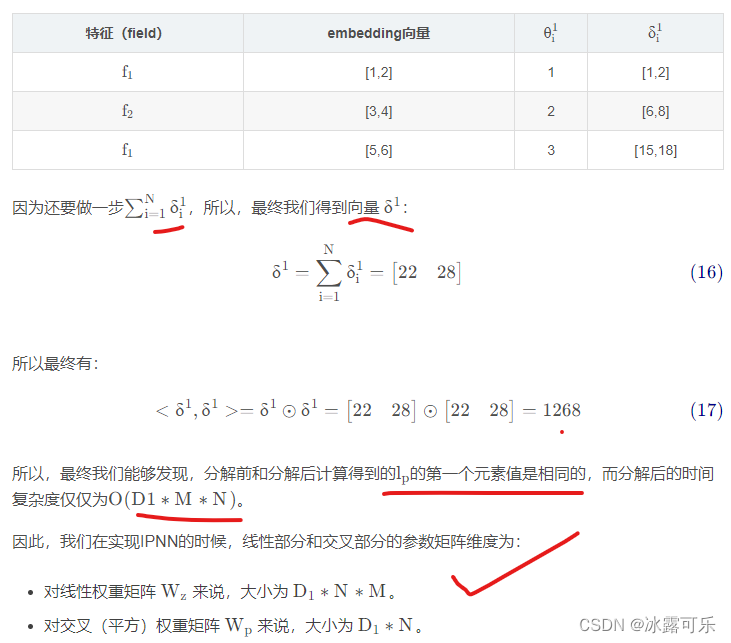
2.3 OPNN
总结
提示:如何系统地学习推荐系统,本系列文章可以帮到你
(1)找工作投简历的话,你要将招聘单位的岗位需求和你的研究方向和工作内容对应起来,这样才能契合公司招聘需求,否则它直接把简历给你挂了
(2)你到底是要进公司做推荐系统方向?还是纯cv方向?还是NLP方向?还是语音方向?还是深度学习机器学习技术中台?还是硬件?还是前端开发?后端开发?测试开发?产品?人力?行政?这些你不可能啥都会,你需要找准一个方向,自己有积累,才能去投递,否则面试官跟你聊什么呢?
(3)今日推荐系统学习经验:IPNN和OPNN,用IPNN吧,PNN就是对FNN的改进,干掉FM,然后用LR+Product
相关文章
- linux系统查看内存,按内存大小排序
- 亿级Web系统搭建——单机到分布式集群
- Egg.js《小小爬虫系统》抓取Api接口数据实现一个新闻系统
- 基于FPGA的波速形成系统的实现
- 一文看懂推荐系统:排序10:wide&deep模型,wide就是LR负责记忆,deep负责高阶特征交叉而泛化
- 一文看懂推荐系统:排序09:Field-aware Factorization Machines(FFM),从FM改进来的,效果不咋地
- 进行系统设计时,这4点一定要注意
- 分布式系统解决之道:目录、消息队列、事务系统及其他
- macOS SwiftUI 创建一个完整App需要的代码合集,开发macOS系统赚钱么
- Win10下C:UsersJohn以账户名称命名的系统文件夹用户名的修改
- ps -aux --sort -rss |head 列出进程拿物理内存占用排序 使用ps aux 查看系统进程时,第六列即 RSS列显示的就是进程使用的物理内存。
- 系统测试用例设计之判定表法
- 杭州中天微系统加入全球半导体联盟
- Windows和Linux网络安全应急响应基础技能——如何进行系统排查以及检测恶意用户登录和网络流量日志分析
- 【bzoj4383】[POI2015]Pustynia 线段树优化建图+差分约束系统+拓扑排序