
通过EM算法的参数辨识和分类识别matlab仿真
up目录
一、理论基础
EM(expectation-maximization)算法是统计学中求统计模型的最大似然和最大后验参数估计的一种迭代式算法,模型一般是依赖于不可观测的潜在变量。EM迭代算法交替E步(使用当前参数创造一个log-likelihood函数,并求期望)和M步(求使得E步骤log-likelihood函数期望最大的参数)。然后M步参数估计的结果用作下一个E步骤中潜在变量的分布。
EM算法是1977年Arthur等人的论文。EM算法通常是用来寻找一个统计模型中最大似然参数的。通常这些模型都是涉及到一些无法观测的未知量以及可观测的数据。也就是说,要么数据中包含丢失的值,要么模型的存在要依赖于其他因变量的存在。比如,一个混合模型可以假设每个观测值都与一个相关的但却无法观测的隐变量相关,该隐变量是确定当前观测值属于哪个混合部分的变量。使用极大似然估计的方法求解后验概率通常需要我们推导关于所有未知变量、因变量参数等的似然函数,同时需要能求解该函数。在带有因变量的统计模型中,这通常都不可能。该似然函数的结果通常都依赖于隐变量的值,也就是说求解该似然函数需要知道因变量结果,而求解因变量的结果又依赖于该似然函数。正常情况下,这是无法得到结果的。而EM算法的来源是作者观察到如下的情况可以解决这些问题。即我们可以先任意对一种未知变量任意赋值,然后利用这个值去求解另一个变量,再用求到的结果反过来求事先任意赋值的变量。如此交替循环直到二者的结果基本不变为止。虽然这个方法并不总是奏效,但是可以证明的是,在二者几乎不变的情况下,似然函数的结果要么是最大值要么是鞍点(saddle point)。一般情况下,我们可能能发现多个最大值,该方法无法保证求得全局最大值。
EM算法的好处,或者说它被需要的原因是什么?其实之前我已经在HMM模型的参数估计章节中,对EM算法的具体应用已经有了一个专门的描述。从HMM的例子中,我们知道当一个实际问题中,除了可观测的变量外,还需要一些隐变量帮助我们去建模,此时EM算法可以帮助对这种包含隐变量的问题进行参数估计,除了HMM外,还有k-means聚类算法也运用了EM算法,它的隐变量可以说是具体的那些聚类本身。
EM算法全称Expectation-Maximization算法,即最大化期望算法。根据这个名字就能很清楚知道这个算法的核心元素,一个是期望,另一个是期望的最大化。而这两个元素代表了EM算法的两个流程。首先EM算法是一个迭代性质的算法,即每个迭代都能得到新的经过学习后的参数,迭代的结束标志一般是人为定义阈值或者参数收敛。其次EM算法每个迭代主要执行两个步骤:
1.求期望,得到一个关于参数的期望函数式。类似于我将样本数据输入到

2.对期望函数式求使其最大化的参数。
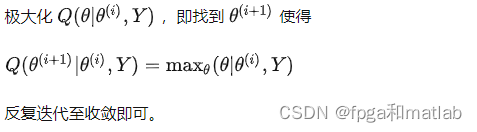
二、核心程序
function [gamma,llm]=em1k(r,k)
load ('data.mat')
x=dataset1;
L=size(x);
l=L(1);
zc=zeros(r,40);llm=-inf;
for zzz=1:r
sigma=zeros(2,2,k);
mu=zeros(k,2);
pik=ones(k,1)/k;
[mu,sigma]=km1s(2);
for zz=1:40
p=zeros(l,k);
for ii=1:k
p(:,ii)=mvnpdf(x,mu(ii,:),sigma(:,:,ii));
end
gamma=zeros(l,k);
for ii=1:l
su=0;
for jj=1:k
su=pik(jj)*p(ii,jj)+su;
end
for jj=1:k
gamma(ii,jj)=pik(jj)*p(ii,jj)/su;
end
end
nk=zeros(k,1);
for ii=1:k
nk(ii)=sum(gamma(:,ii));
end
pik=nk/l;
for ii=1:k
mu(ii,1)=sum(gamma(:,ii).*x(:,1))/nk(ii);
mu(ii,2)=sum(gamma(:,ii).*x(:,2))/nk(ii);
end
ssig=zeros(2,2,l);
for ii=1:k
for jj=1:l
ssig(:,:,jj)=gamma(jj,ii).*(x(jj,:)-mu(ii,:))'*(x(jj,:)-mu(ii,:));
end
sigma(1,1,ii)=sum(ssig(1,1,:))/nk(ii);
sigma(1,2,ii)=sum(ssig(1,2,:))/nk(ii);
sigma(2,1,ii)=sum(ssig(2,1,:))/nk(ii);
sigma(2,2,ii)=sum(ssig(2,2,:))/nk(ii);
end
ll=0;
for ii=1:l
bb=0;
for jj=1:k
bb=bb+pik(jj)*mvnpdf(x(ii,:),mu(jj,:),sigma(:,:,jj));
end
ll=ll+log(bb)/log(exp(1));
end
zc(zzz,zz)=ll;
end
if llm<ll
llm=ll;
mii=zzz;
gam=gamma;
end
end
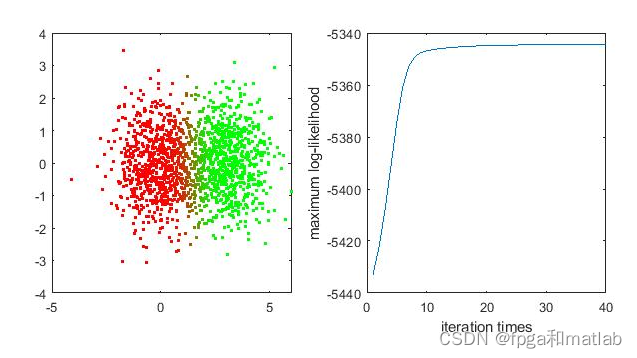
figure (5)
subplot(1,2,1);
colo=zeros(l,3);
colo(:,1:2)=gam;
for ii=1:l
plot(x(ii,1),x(ii,2),'.','color',colo(ii,:));
hold on
end
hold off;
subplot(1,2,2)
plot(1:40,zc(mii,:));
xlabel('iteration times')
ylabel('maximum log-likelihood')
end
up41三、测试结果

相关文章
- 【华为云技术分享】文字识别服务(OCR)基于对抗样本的模型可信安全威胁分析初析
- 文字检测与识别资料整理
- Intellij IDEA错误识别.xml文件
- Atitit 图像清晰度 模糊度 检测 识别 评价算法 原理
- atitit.短信 验证码 破解 v3 p34 识别 绕过 系统方案规划----业务相关方案 手机验证码 .doc
- Matlab:基于Matlab通过GUI实现自动驾驶的车牌智能识别
- Python之GUI:基于Python的GUI界面设计的一套AI课程学习(机器学习、深度学习、大数据、云计算等)推荐系统(包括语音生成、识别等前沿黑科技)
- 使用基于非支配排序的鲸鱼优化算法的生产过程中关键质量特征识别的多目标特征选择(Matlab代码实现)
- 【信号处理】基于到达角的超声多频信号手势识别(Matlab代码实现)
- 基于人工神经网络(ANN)的高斯白噪声的系统识别(Matlab代码实现)
- 【MATLAB】数学建模没有基础怎么办,看过来一篇文章带你入门 matlab
- 【图像处理】基于MATLAB的RGB车牌识别
- 【图像处理】基于 MATLAB 实现红绿灯识别
- PyTorch 实现孪生网络识别面部相似度
- 带你读AI论文丨针对文字识别的多模态半监督方法
- 基于React-Native0.55.4的语音识别项目全栈方案
- m基于HOG特征提取和GRNN网络的人体姿态识别算法matlab仿真,样本为TOF数据库的RGB-D深度图像
- m基于GRNN广义回顾神经网络的车牌字符分割和识别算法matlab仿真
- m基于MSER最大稳定极值区域和SVM的交通标志检测识别算法的matlab仿真
- m基于C3D-hog-GRNN广义回归神经网络模型的人员异常行为识别算法的matlab仿真
- m基于sift特征提取和模板匹配的车标识别算法matlab仿真
- m基于CNN卷积网络和GEI步态能量图的步态识别算法MATLAB仿真,测试样本采用现实拍摄的场景进行测试,带GUI界面
- m基于CNN卷积神经网络和GEI步态能量图的步态识别算法MATLAB仿真
- Win10语音识别无法启动怎么办?
- Matlab:MATLAB GUI不同控件函数间变量传递的三种方法详解
- 基于MFCC特征提取和神经网络的语音信号识别算法matlab仿真
- Matlab使用笔记(四):将编写完matlab函数放入simulink模型