
python集合set用法详解(创建、增加、删除、复制、查找、合并、判断、差集、交集、对称差集)
1. 创建集合
s1 = {10, 20, 30, 40, 50}
print(s1)
s2 = {10, 30, 20, 10, 30, 40, 30, 50}
print(s2)
s3 = set('abcdefg') # 生成了无序集合
print(s3)
s4 = set()
print(type(s4)) # set
s5 = {}
print(type(s5)) # dict
运行结果:

- 集合可以去掉重复数据;
- 集合数据是⽆序的,故不⽀持下标
2. 集合常⻅操作⽅法
2.1 增加数据
s1 = {10, 20}
s1.add(100)
s1.add(10)
print(s1) # {100, 10, 20}
运行结果:

s1 = {10, 20}
# s1.update(100) # 报错 【不能直接放int型数字】
s1.update([100, 200])
s1.update('abc')
print(s1)运行结果:

示例代码2:
a = {"apple", "banana", "cherry"}
b = {"google", "microsoft", "apple"}
a.update(b)
print(a)运行结果:

2.2 删除数据
s1 = {10, 20}
s1.remove(10)
print(s1)
s1.remove(10) # 报错
print(s1)

remove()方法不同,因为如果指定的元素不存在,
remove()方法会引发错误,而
discard()方法则不会。
s1 = {10, 20}
s1.discard(10)
print(s1)
s1.discard(10)
print(s1)
s1 = {10, 20, 30, 40, 50}
del_num = s1.pop()
print(del_num)
print(s1)运行结果:

clear()方法删除集合中的所有元素。
示例代码:
x = {"a", "b", "c"}
print(x)
x.clear()
print(x)
运行结果:

2.3 查找数据
- in:判断数据在集合序列
- not in:判断数据不在集合序列
s1 = {10, 20, 30, 40, 50}
print(10 in s1)
print(10 not in s1)示例代码:

2.4 合并数据
union() 方法返回两个集合的并集,即包含了所有集合的元素,重复的元素只会出现一次。
语法结构:
set.union(set1, set2...)参数:
- set1 -- 必需,合并的目标集合
- set2 -- 可选,其他要合并的集合,可以多个,多个使用逗号 , 隔开。
- return 一个新集合。
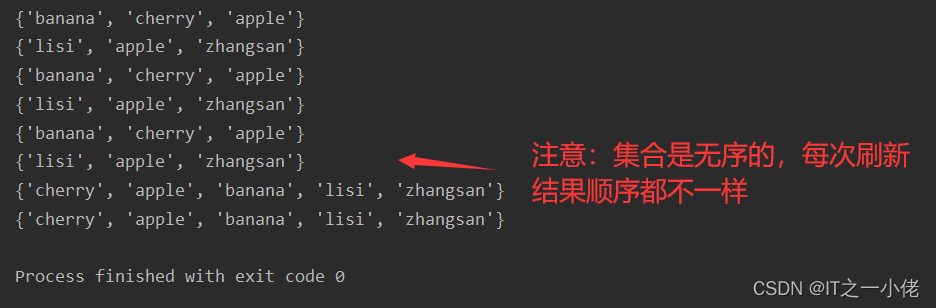
示例代码1: 【合并两个集合,重复元素只会出现一次】【注意:集合合并后不会改变原集合】
x = {"apple", "banana", "cherry"}
y = {"zhangsan", "lisi", "apple"}
print(x)
print(y)
result1 = x.union(y)
print(x)
print(y)
result2 = set.union(x, y)
print(x)
print(y)
print(result1)
print(result2)运行结果:
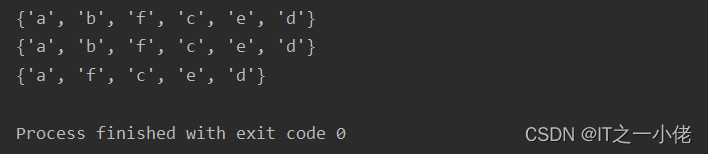
示例代码2: 【合并多个集合】
x = {"a", "b", "c"}
y = {"f", "d", "a"}
z = {"c", "d", "e"}
result1 = x.union(y, z)
result2 = set.union(x, y, z)
result3 = set.union(y, y, z)
print(result1)
print(result2)
print(result3)运行结果:
2.5 判断数据
issubset() 方法用于判断集合的所有元素是否都包含在指定集合中,如果是则返回 True,否则返回 False。
语法如下:
set.issubset(set)- set -- 必需,要比查找的集合
- 返回布尔值,如果都包含返回 True,否则返回 False
示例代码1:
x = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b", "a"}
z = x.issubset(y)
print(z)
运行结果:

示例代码2:
x = {"a", "b", "c"}
y = {"f", "e", "d", "c", "b"}
z = x.issubset(y)
print(z)
运行结果:

isdisjoint()方法:如果两个集合中都没有相同的元素,则返回True,否则返回False。
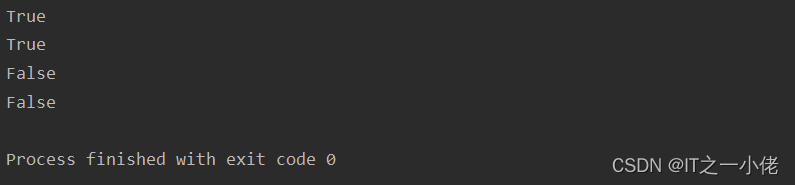
示例代码:
a = {"apple", "banana", "cherry"}
b = {"google", "microsoft", "facebook"}
c = {"aa", "bb"}
d = {"bb", "cc"}
x = a.isdisjoint(b)
y = set.isdisjoint(a, b)
print(x)
print(y)
m = c.isdisjoint(d)
n = set.isdisjoint(c, d)
print(m)
print(n)
运行结果:
issuperset():如果指定集合中的所有元素都存在于原集合中,则返回True,否则返回False。
示例代码:
a = {"f", "e", "d", "c", "b", "a"}
b = {"a", "b", "c"}
c = {"a", "d"}
x = a.issuperset(b)
y = set.issuperset(a, b)
print(x)
print(y)
print(a)
print(b)
z = b.issuperset(c)
print(z)运行结果:

2.6 复制数据
copy()方法复制该集合
示例代码:
x = {"a", "b", "c"}
print(x)
y = x.copy()
print(y)
print(type(y))
运行结果:

2.7 差集数据
difference()方法返回一个包含两个集合之间的差异的集合。就是返回的集合包含仅存在于第一个集合中而不存在于两个集合中的元素。
示例代码1: 【返回一个集合,其中包含只存在于集合x中而不存在于集合y中的元素】
x = {"apple", "banana", "cherry"}
y = {"google", "microsoft", "apple"}
z = x.difference(y)
print(z)运行结果:

示例代码2:【反转示例1。返回一个集合,其中包含只存在于集合y中而不存在于集合x中的元素】
x = {"apple", "banana", "cherry"}
y = {"google", "microsoft", "apple"}
z = y.difference(x)
print(z)运行结果:

difference_update()方法删除两个集中存在的元素。
注意:difference_update()方法与difference()方法不同,因为difference()方法返回一个新的集合,不包含不需要的元素,而difference_update()方法从原始集合中删除不需要的元素。
示例代码: 【删除两个集合中都存在的元素】
x = {"apple", "banana", "cherry"}
y = {"google", "microsoft", "apple"}
x.difference_update(y)
print(x)运行结果:

2.8 交集数据
intersection()方法用于返回两个或更多集合中都包含的元素,即交集。返回的集合仅包含两个集合中都存在的元素,或者如果使用两个以上的集合进行比较,则包含所有集合中的元素。
语法结构:
set.intersection(set1, set2 ... etc)示例代码1: 【返回一个包含同时存在于x和y中的元素的集合:】
a = {"apple", "banana", "cherry"}
b = {"google", "microsoft", "apple"}
x = a.intersection(b)
y = set.intersection(a, b)
print(x)
print(y)运行结果:

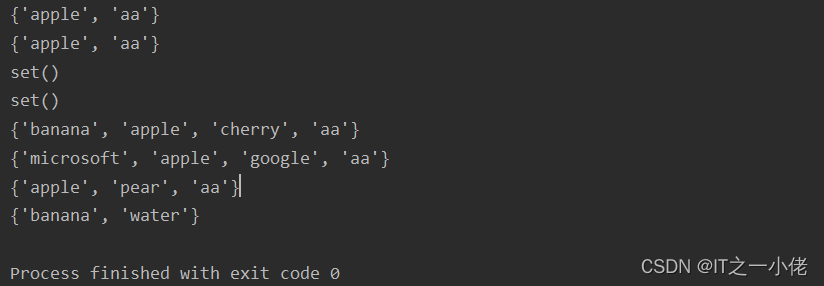
示例代码2:【比较多个集合,返回一个集合,其中包含所有集合中存在的元素:】
a = {"apple", "banana", "cherry", "aa"}
b = {"google", "microsoft", "apple", "aa"}
c = {"apple", "pear", "aa"}
d = {"banana", 'water'}
x = a.intersection(b, c)
y = set.intersection(a, b, c)
print(x)
print(y)
# m = a.intersection(a, b, d)
m = a.intersection(b, d)
n = set.intersection(a, b, d)
print(m)
print(n)
print(a)
print(b)
print(c)
print(d)运行结果:
intersection_update()方法删除两个集合中不存在的元素(如果在两个以上集合之间进行比较,则删除所有集合中不存在的元素),即计算交集。
注意:intersection_update()方法与intersection()方法不同,因为intersection()方法返回一个新的集合,不包含不需要的元素,而intersection_update()方法则从原始集合中删除不需要的元素。
语法结构:
set.intersection_update(set1, set2 ... etc)示例代码1: 【删除x和y都不存在的元素】
x = {"apple", "banana", "cherry"}
y = {"google", "microsoft", "apple"}
a = x.intersection_update(y)
print(x)
print(y)
print(a)
运行结果:

示例代码2:
a = {"apple", "banana", "cherry", "aa"}
b = {"google", "microsoft", "apple", "aa"}
c = {"apple", "pear", "aa"}
d = {"google", 'water'}
print(a)
print(b)
print(c)
print(d)
x = a.intersection_update(b, c) # 注意,必须是a,b,c共同的交集
set.intersection_update(b, c, d)
set.intersection_update(c, d)
print(x)
print(a)
print(b)
print(c)
print(d)
运行结果:

2.9 对称差集数据
symmetric_difference()方法返回一个集合,其中包含两个集合中的所有元素,但不包含两个集合中都存在的元素。就是返回的集合包含两个集合中都不存在的元素。
示例代码:
a = {"apple", "banana", "cherry"}
b = {"google", "microsoft", "apple"}
x = a.symmetric_difference(b)
y = set.symmetric_difference(a, b)
print(x)
print(y)运行结果:

symmetric_difference_update()方法移除当前集合中在另外一个指定集合相同的元素,并将另外一个指定集合中不同的元素插入到当前集合中。
示例代码:
a = {"apple", "banana", "cherry"}
b = {"google", "microsoft", "apple"}
x = a.symmetric_difference_update(b)
# set.symmetric_difference_update(a, b) # 注意,这行代码不能同时和上面那行代码同时运行,否则影响输出结果
print(x)
print(a)
print(b)
运行结果:

相关文章
- Rabbitmq的connection连接池(Python版)
- 【Python】python 日期操作
- python的isocalendar()
- python之simplejson,Python版的简单、 快速、 可扩展 JSON 编码器/解码器
- Python(可变/不可变类型,list,tuple,dict,set)
- 使用Python创建AI比你想象的轻松
- python的dict,set,list,tuple应用详解
- 【Python五篇慢慢弹(4)】模块异常谈python
- Python中内置数据类型list,tuple,dict,set的区别和用法
- python:pip升级pip本身和setuptools(Python 3.7.15)
- Python: 爬虫入门-python爬虫入门教程(非常详细)
- 我00后,会Python,月薪5000,兼职1.5w
- Python:利用python代码编程实现将视频的avi格式转换为MP4格式
- Python:python语言中与时间有关的库函数简介、安装、使用方法(获取当前时间/计算程序块前后运行时间/模型训练时间或耗费时间)之详细攻略
- Python之多线程:python多线程设计之同时执行多个函数命令详细攻略
- Python编程语言学习:python编程语言中重要函数讲解之map函数等简介、使用方法之详细攻略
- Python:更改默认启动的python程序及其对应的安装包路径(更改pip的默认安装包的路径)图文教程之详细攻略
- Python之tkinter:动态演示调用python库的tkinter带你进入GUI世界(text.insert/link各种事件)
- Python语言学习:解决python版本升级问题集合(python2系列→Python3系列)导致错误的总结集合
- Python编程语言学习:python的列表的特殊应用之一行命令实现if判断中的两类判断
- Python语言学习:利用python语言实现调用内部命令(python调用Shell脚本)—命令提示符cmd的几种方法
- python里的条件语句以及循环语句(基础小知识)
- 【昇腾】【玩转Atlas200DK系列】为Atlas 200 DK制作python环境离线安装包
- python中set()函数==》创建一个无序不重复的元素集(创将一个集合)
- 最全总结 | 聊聊 Python 数据处理全家桶(Mysql 篇)干货
- python基础===字符串的制表,换行基础操作
- Python: 爬虫入门-python爬虫入门教程(非常详细)