
聚类算法实现流程
2023-09-11 14:15:15 时间
聚类算法实现流程
k-means其实包含两层内容:
- K : 初始中心点个数(计划聚类数)
- means:求中心点到其他数据点距离的平均值
1 k-means聚类步骤
- 1、随机设置K个特征空间内的点作为初始的聚类中心
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
- 4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程
通过下图解释实现流程:
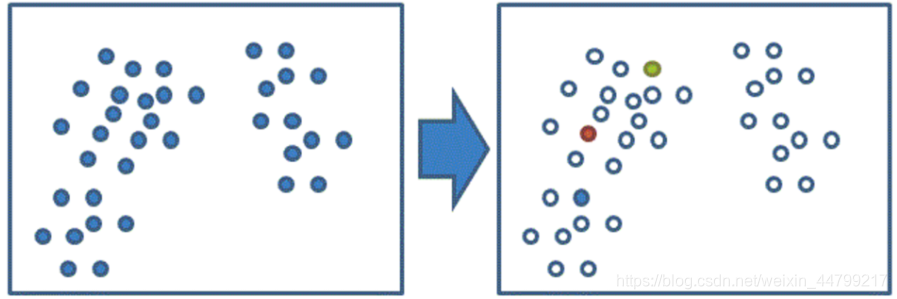

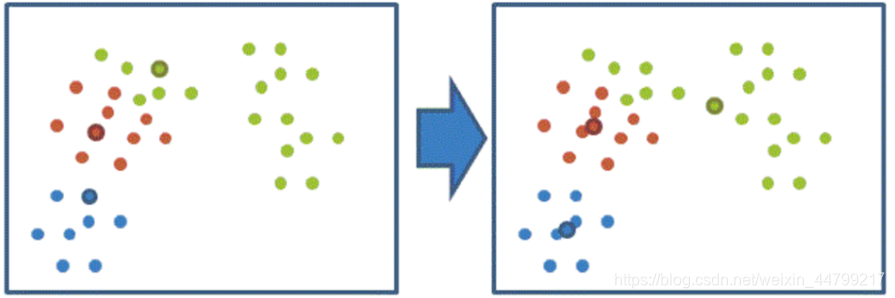
k聚类动态效果图
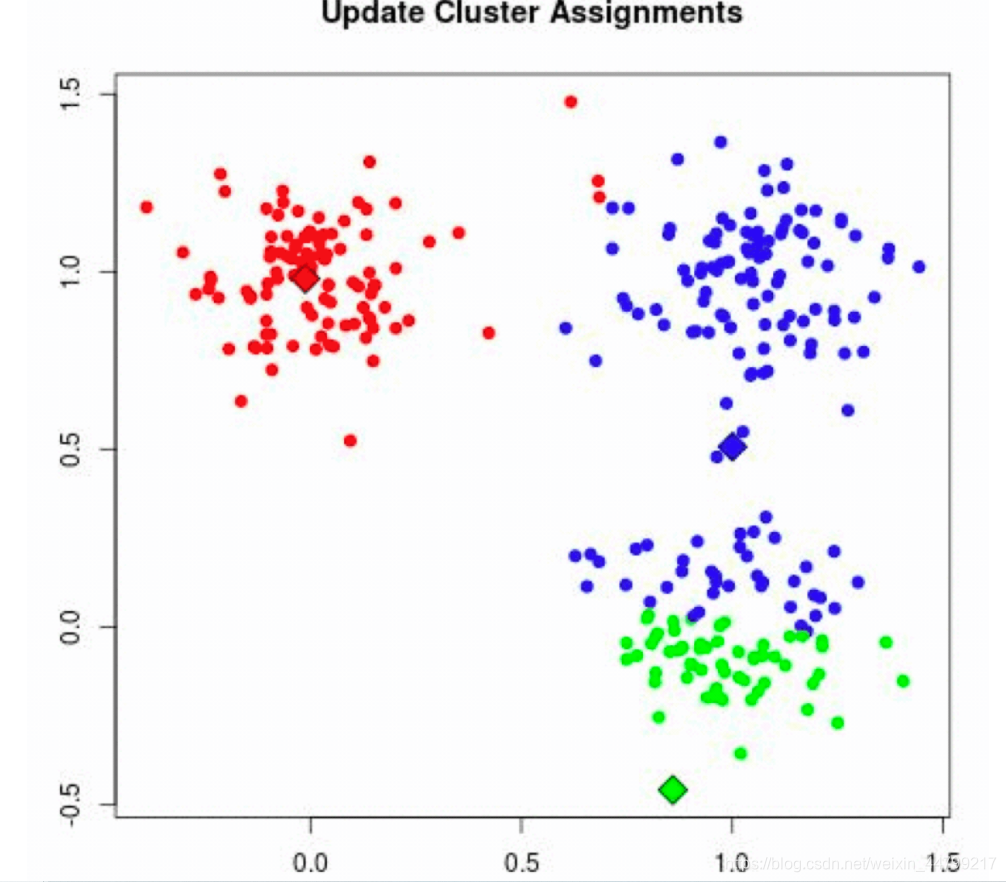
2 案例练习
- 案例:【选取15个点】
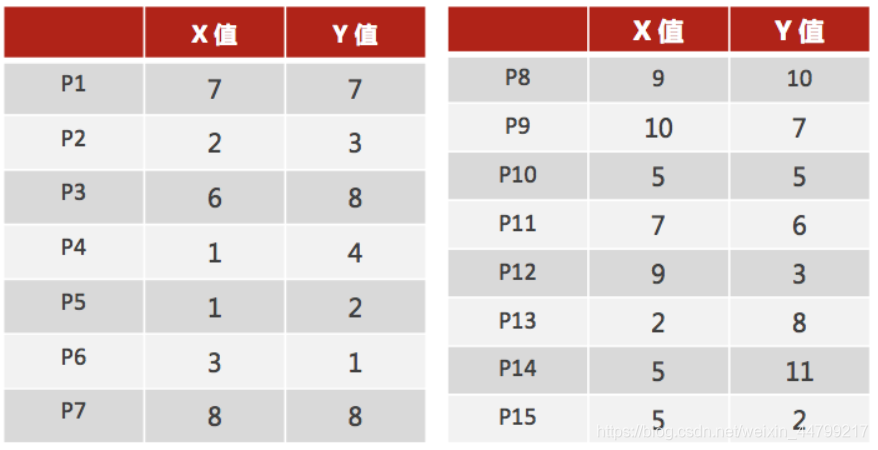
- 1、随机设置K个特征空间内的点作为初始的聚类中心(本案例中设置p1和p2)
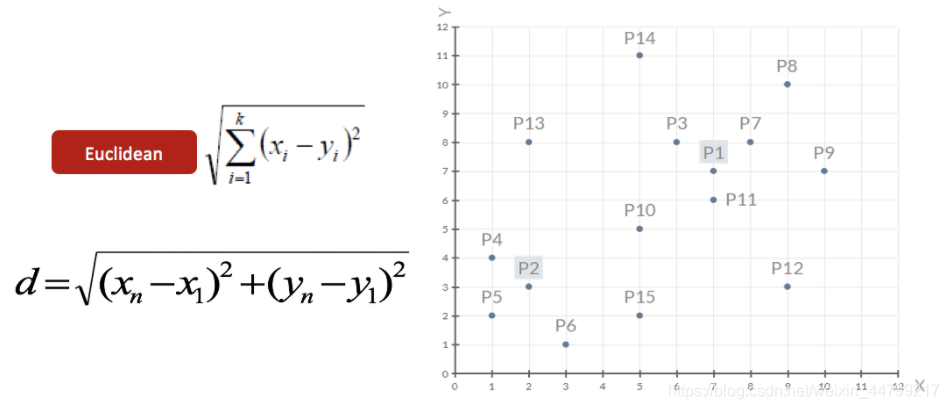
- 2、对于其他每个点计算到K个中心的距离,未知的点选择最近的一个聚类中心点作为标记类别
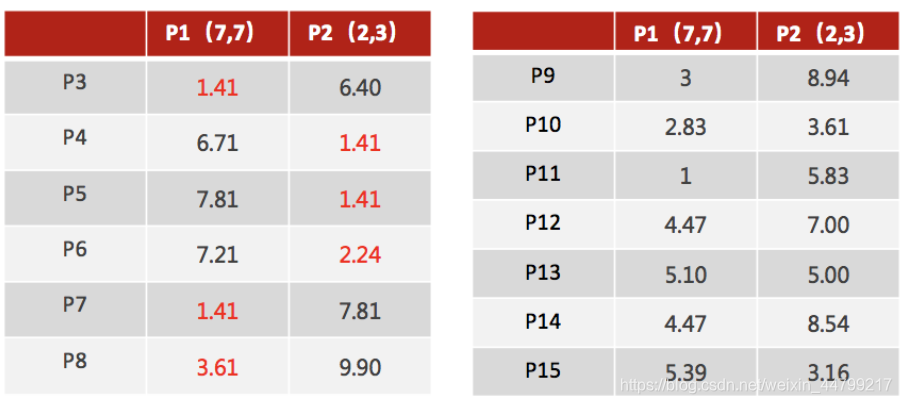

- 3、接着对着标记的聚类中心之后,重新计算出每个聚类的新中心点(平均值)
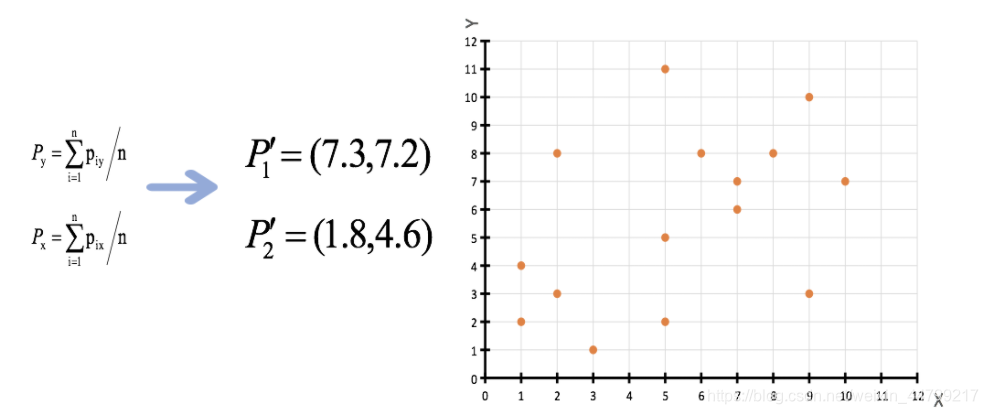
- 4、如果计算得出的新中心点与原中心点一样(质心不再移动),那么结束,否则重新进行第二步过程【经过判断,需要重复上述步骤,开始新一轮迭代】
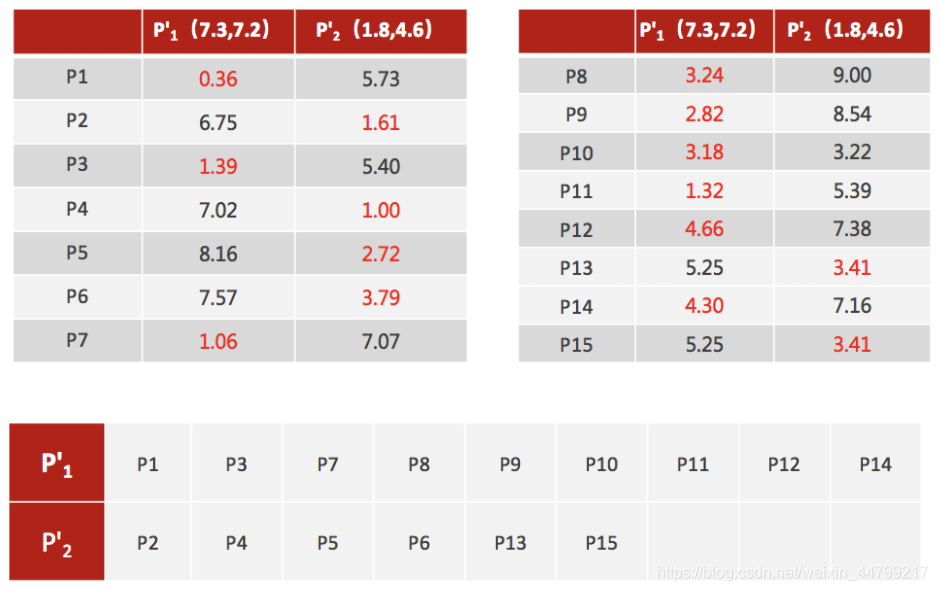
- 5、当每次迭代结果不变时,认为算法收敛,聚类完成,K-Means一定会停下,不可能陷入一直选质心的过程。
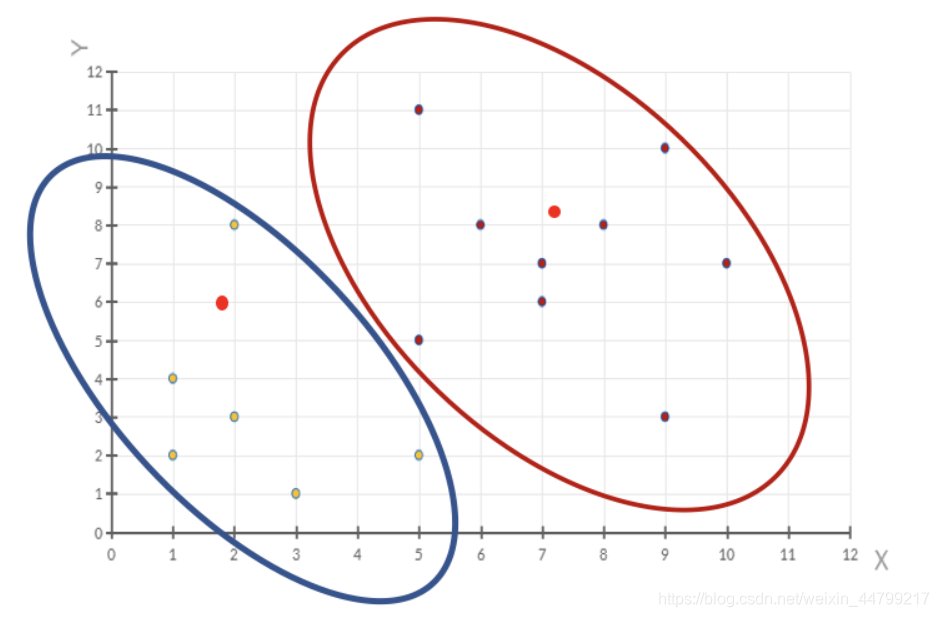
3 小结
流程:
- 事先确定常数K,常数K意味着最终的聚类类别数;
- 首先随机选定初始点为质心,并通过计算每一个样本与质心之间的相似度(这里为欧式距离),将样本点归到最相似的类中,
- 接着,重新计算每个类的质心(即为类中心),重复这样的过程,直到质心不再改变,
- 最终就确定了每个样本所属的类别以及每个类的质心。
注意:
- 由于每次都要计算所有的样本与每一个质心之间的相似度,故在大规模的数据集上,K-Means算法的收敛速度比较慢。
相关文章
- Python爬虫基本流程
- 17activiti - 流程管理定义(查询最新版本的流程定义)
- 软件测试缺陷的管理流程(上):构成要素与流程说明
- 邓白氏编码申请流程-Android平台签名证书(.keystore)生成指南
- 《Python机器学习——预测分析核心算法》——1.5 构建预测模型的流程
- ANDROID自定义视图——onMeasure流程,MeasureSpec详解
- rsync算法原理和工作流程分析
- Imu_tk算法流程及数据采集要求和标定程序参数设置
- 缺陷上报统一模板及缺陷管理流程
- 企业如何用CRM软件客户管理自动化优化流程?
- 浅析微信公众号订阅消息开发流程
- 浅析分布式一致性算法 - Raft算法:定义、为什么需要一致性、强/弱一致性分类区别、raft三种状态、领导选举算法流程、日志复制流程、安全选举限制、如何解决split brain的问题
- Shiro框架:Shiro简介、登陆认证入门程序、认证执行流程、使用自定义Realm进行登陆认证、Shiro的MD5散列算法
- 软件测试过程中对bug的处理流程
- 【framework】WMS启动流程
- 软件测试的Bug缺陷管理流程