
LeetCode 1-5题 详解 Java版 (三万字 图文详解 LeetCode 算法题1-5 =====>>> <建议收藏>)

目录
第一题:TWO SUM
1. 题目描述 (简单难度)
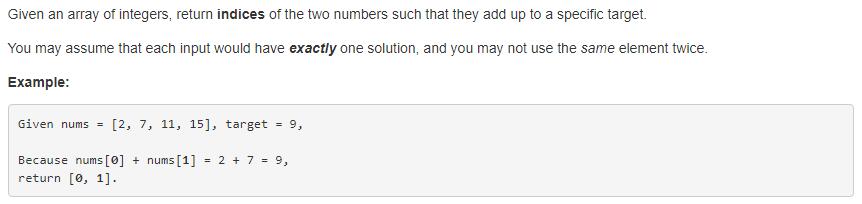
给定一个数组和一个目标和,从数组中找两个数字相加等于目标和,输出这两个数字的下标。
2. 解法一
简单粗暴些,两重循环,遍历所有情况看相加是否等于目标和,如果符合直接输出。
public int[] twoSum(int[] nums, int target) {
int []ans=new int[2];
for(int i=0;i<nums.length;i++){
for(int j=(i+1);j<nums.length;j++){
if(nums[i]+nums[j]==target){
ans[0]=i;
ans[1]=j;
return ans;
}
}
}
return ans;
}
时间复杂度:两层 for 循环,O(n²)
空间复杂度:O(1)
3. 解法二
在上边的解法中看下第二个 for 循环步骤。
for(int j=(i+1);j<nums.length;j++){
if(nums[i]+nums[j]==target){
我们换个理解方式:
for(int j=(i+1);j<nums.length;j++){
sub=target-nums[i]
if(nums[j]==sub){
第二层 for 循环无非是遍历所有的元素,看哪个元素等于 sub ,时间复杂度为 O(n)。
有没有一种方法,不用遍历就可以找到元素里有没有等于 sub 的?
hash table !!!
我们可以把数组的每个元素保存为 hash 的 key,下标保存为 hash 的 value 。
这样只需判断 sub 在不在 hash 的 key 里就可以了,而此时的时间复杂度仅为 O(1)!
需要注意的地方是,还需判断找到的元素不是当前元素,因为题目里讲一个元素只能用一次。
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
map.put(nums[i],i);
}
for(int i=0;i<nums.length;i++){
int sub=target-nums[i];
if(map.containsKey(sub)&&map.get(sub)!=i){
return new int[]{i,map.get(sub)};
}
}
throw new IllegalArgumentException("No two sum solution");
}
时间复杂度:比解法一少了一个 for 循环,降为 O(n)
空间复杂度:所谓的空间换时间,这里就能体现出来, 开辟了一个 hash table ,空间复杂度变为 O(n)
4. 解法三
看解法二中,两个 for 循环,他们长的一样,我们当然可以把它合起来。复杂度上不会带来什么变化,变化仅仅是不需要判断是不是当前元素了,因为当前元素还没有添加进 hash 里。
public int[] twoSum(int[] nums, int target) {
Map<Integer,Integer> map=new HashMap<>();
for(int i=0;i<nums.length;i++){
int sub=target-nums[i];
if(map.containsKey(sub)){
return new int[]{i,map.get(sub)};
}
map.put(nums[i], i);
}
throw new IllegalArgumentException("No two sum solution");
}
5. 总结
题目比较简单,毕竟暴力的方法也可以解决。唯一闪亮的点就是,时间复杂度从 O(n²)降为 O(n) 的时候,对 hash 的应用,有眼前一亮的感觉。
第二题: Add-Two-Numbers
1. 题目描述(中等难度)
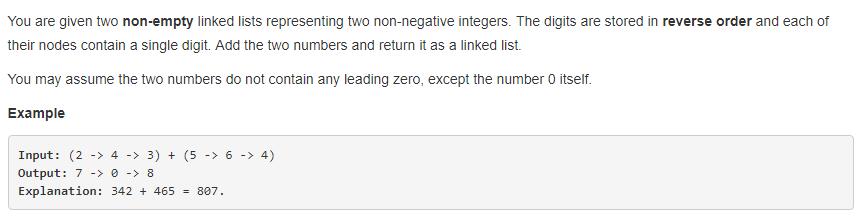
就是两个链表表示的数相加,这样就可以实现两个很大的数相加了,无需考虑数值 int ,float 的限制了。
由于自己实现的很乱,直接按答案的讲解了。
2. 图示
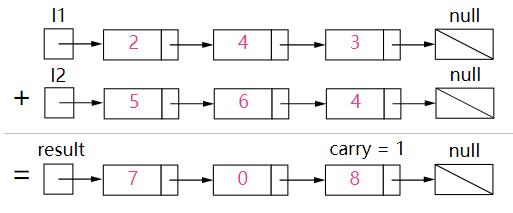
链表最左边表示个位数,代表 342 + 465 =807 。
3. 思路
首先每一位相加肯定会产生进位,我们用 carry 表示。进位最大会是 1 ,因为最大的情况是无非是 9 + 9 + 1 = 19 ,也就是两个最大的数相加,再加进位,这样最大是 19 ,不会产生进位 2 。下边是伪代码。
- 初始化一个节点的头,dummy head ,但是这个头不存储数字。并且将 curr 指向它。
- 初始化进位 carry 为 0 。
- 初始化 p 和 q 分别为给定的两个链表 l1 和 l2 的头,也就是个位。
- 循环,直到 l1 和 l2 全部到达 null 。
- 设置 x 为 p 节点的值,如果 p 已经到达了 null,设置 x 为 0 。
- 设置 y 为 q 节点的值,如果 q 已经到达了 null,设置 y 为 0 。
- 设置 sum = x + y + carry 。
- 更新 carry = sum / 10 。
- 创建一个值为 sum mod 10 的节点,并将 curr 的 next 指向它,同时 curr 指向变为当前的新节点。
- 向前移动 p 和 q 。
- 判断 carry 是否等于 1 ,如果等于 1 ,在链表末尾增加一个为 1 的节点。
- 返回 dummy head 的 next ,也就是个位数开始的地方。
初始化的节点 dummy head 没有存储值,最后返回 dummy head 的 next 。这样的好处是不用单独对 head 进行判断改变值。也就是如果一开始的 head 就是代表个位数,那么开始初始化的时候并不知道它的值是多少,所以还需要在进入循环前单独对它进行值的更正,不能像现在一样只用一个循环简洁。
4. 代码
class ListNode {
int val;
ListNode next;
ListNode(int x) { val = x; }
}
public ListNode addTwoNumbers(ListNode l1, ListNode l2) {
ListNode dummyHead = new ListNode(0);
ListNode p = l1, q = l2, curr = dummyHead;
int carry = 0;
while (p != null || q != null) {
int x = (p != null) ? p.val : 0;
int y = (q != null) ? q.val : 0;
int sum = carry + x + y;
carry = sum / 10;
curr.next = new ListNode(sum % 10);
curr = curr.next;
if (p != null) p = p.next;
if (q != null) q = q.next;
}
if (carry > 0) {
curr.next = new ListNode(carry);
}
return dummyHead.next;
}
时间复杂度:O(max(m,n)),m 和 n 代表 l1 和 l2 的长度。
空间复杂度:O(max(m,n)),m 和 n 代表 l1 和 l2 的长度。而其实新的 List 最大长度是 O(max(m,n))+ 1,因为我们的 head 没有存储值。
5. 扩展
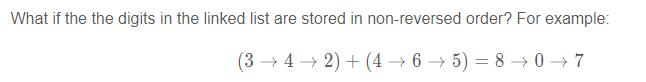
如果链表存储的顺序反过来怎么办?
我首先想到的是链表先逆序计算,然后将结果再逆序呗,这就转换到我们之前的情况了。不知道还有没有其他的解法。下边分析下单链表逆序的思路。
6. 迭代思想
首先看一下原链表。

总共需要添加两个指针,pre 和 next。
初始化 pre 指向 NULL 。

然后就是迭代的步骤,总共四步,顺序一步都不能错。
-
next 指向 head 的 next ,防止原链表丢失

-
head 的 next 从原来链表脱离,指向 pre 。

-
pre 指向 head

-
head 指向 next

一次迭代就完成了,如果再进行一次迭代就变成下边的样子。

可以看到整个过程无非是把旧链表的 head 取下来,添加的新的链表上。代码怎么写呢?
next = head -> next; //保存 head 的 next , 以防取下 head 后丢失
head -> next = pre; //将 head 从原链表取下来,添加到新链表上
pre = head;// pre 右移
head = next; // head 右移
接下来就是停止条件了,我们再进行一次循环。

可以发现当 head 或者 next 指向 null 的时候,我们就可以停止了。此时将 pre 返回,便是逆序了的链表了。
7. 迭代代码
public ListNode reverseList(ListNode head){
if(head==null) return null;
ListNode pre=null;
ListNode next;
while(head!=null){
next=head.next;
head.next=pre;
pre=head;
head=next;
}
return pre;
}
8. 递归思想
-
首先假设我们实现了将单链表逆序的函数,ListNode reverseListRecursion(ListNode head) ,传入链表头,返回逆序后的链表头。
-
接着我们确定如何把问题一步一步的化小,我们可以这样想。
把 head 结点拿出来,剩下的部分我们调用函数 reverseListRecursion ,这样剩下的部分就逆序了,接着我们把 head 结点放到新链表的尾部就可以了。这就是整个递归的思想了。
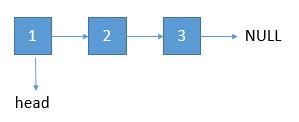
-
head 结点拿出来
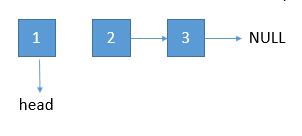
-
剩余部分调用逆序函数 reverseListRecursion ,并得到了 newhead
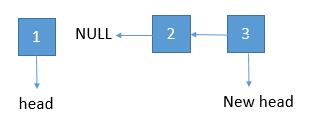
-
将 2 指向 1 ,1 指向 null,将 newhead 返回即可。

-
-
找到递归出口
当然就是如果结点的个数是一个,那么逆序的话还是它本身,直接 return 就够了。怎么判断结点个数是不是一个呢?它的 next 等于 null 就说明是一个了。但如果传进来的本身就是 null,那么直接找它的 next 会报错,所以先判断传进来的是不是 null ,如果是,也是直接返回就可以了。
9. 代码
public ListNode reverseListRecursion(ListNode head){
ListNode newHead;
if(head==null||head.next==null ){
return head;
}
newHead=reverseListRecursion(head.next); //head.next 作为剩余部分的头指针
head.next.next=head; //head.next 代表新链表的尾,将它的 next 置为 head,就是将 head 加到最后了。
head.next=null;
return newHead;
}
第三题: Longest Substring Without Repeating Characters
1. 题目描述(中等难度)

给定一个字符串,找到没有重复字符的最长子串,返回它的长度。
2. 解法一
简单粗暴些,找一个最长子串,那么我们用两个循环穷举所有子串,然后再用一个函数判断该子串中有没有重复的字符。
public int lengthOfLongestSubstring(String s) {
int n = s.length();
int ans = 0;//保存当前得到满足条件的子串的最大值
for (int i = 0; i < n; i++)
for (int j = i + 1; j <= n; j++) //之所以 j<= n,是因为我们子串是 [i,j),左闭右开
if (allUnique(s, i, j)) ans = Math.max(ans, j - i); //更新 ans
return ans;
}
public boolean allUnique(String s, int start, int end) {
Set<Character> set = new HashSet<>();//初始化 hash set
for (int i = start; i < end; i++) {//遍历每个字符
Character ch = s.charAt(i);
if (set.contains(ch)) return false; //判断字符在不在 set 中
set.add(ch);//不在的话将该字符添加到 set 里边
}
return true;
}
时间复杂度:两个循环,加上判断子串满足不满足条件的函数中的循环,O(n³)。
空间复杂度:使用了一个 set,判断子串中有没有重复的字符。由于 set 中没有重复的字符,所以最长就是整个字符集,假设字符集的大小为 m ,那么 set 最长就是 m 。另一方面,如果字符串的长度小于 m ,是 n 。那么 set 最长也就是 n 了。综上,空间复杂度为 O(min(m,n))。
3. 解法二
遗憾的是上边的算法没有通过 leetCode,时间复杂度太大,造成了超时。我们怎么来优化一下呢?
上边的算法中,我们假设当 i 取 0 的时候,
j 取 1,判断字符串 str[0,1) 中有没有重复的字符。
j 取 2,判断字符串 str[0,2) 中有没有重复的字符。
j 取 3,判断字符串 str[0,3) 中有没有重复的字符。
j 取 4,判断字符串 str[0,4) 中有没有重复的字符。
做了很多重复的工作,因为如果 str[0,3) 中没有重复的字符,我们不需要再判断整个字符串 str[0,4) 中有没有重复的字符,而只需要判断 str[3] 在不在 str[0,3) 中,不在的话,就表明 str[0,4) 中没有重复的字符。
如果在的话,那么 str[0,5) ,str[0,6) ,str[0,7) 一定有重复的字符,所以此时后边的 j 也不需要继续增加了。i ++ 进入下次的循环就可以了。
此外,我们的 j 也不需要取 j + 1,而只需要从当前的 j 开始就可以了。
综上,其实整个关于 j 的循环我们完全可以去掉了,此时可以理解变成了一个「滑动窗口」。

整体就是橘色窗口在依次向右移动。
判断一个字符在不在字符串中,我们需要可以遍历整个字符串,遍历需要的时间复杂度就是 O(n),加上最外层的 i 的循环,总体复杂度就是 O(n²)。我们可以继续优化,判断字符在不在一个字符串,我们可以将已有的字符串存到 Hash 里,这样的时间复杂度是 O(1),总的时间复杂度就变成了 O(n)。
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length();
Set<Character> set = new HashSet<>();
int ans = 0, i = 0, j = 0;
while (i < n && j < n) {
if (!set.contains(s.charAt(j))){
set.add(s.charAt(j++));
ans = Math.max(ans, j - i);
}
else {
set.remove(s.charAt(i++));
}
}
return ans;
}
}
时间复杂度:在最坏的情况下,while 循环中的语句会执行 2n 次,例如 abcdefgg,开始的时候 j 一直后移直到到达第二个 g 的时候固定不变 ,然后 i 开始一直后移直到 n ,所以总共执行了 2n 次,时间复杂度为 O(n)。
空间复杂度:和上边的类似,需要一个 Hash 保存子串,所以是 O(min(m,n))。
4. 解法三
继续优化,我们看上边的算法的一种情况。

当 j 指向的 c 存在于前边的子串 abcd 中,此时 i 向前移到 b ,此时子串中仍然含有 c,还得继续移动,所以这里其实可以优化。我们可以一步到位,直接移动到子串 c 的位置的下一位!

实现这样的话,我们将 set 改为 map ,将字符存为 key ,将对应的下标存到 value 里就实现了。
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
Map<Character, Integer> map = new HashMap<>();
for (int j = 0, i = 0; j < n; j++) {
if (map.containsKey(s.charAt(j))) {
i = Math.max(map.get(s.charAt(j)), i);
}
ans = Math.max(ans, j - i + 1);
map.put(s.charAt(j), j + 1);//下标 + 1 代表 i 要移动的下个位置
}
return ans;
}
}
与解法二相比
由于采取了 i 跳跃的形式,所以 map 之前存的字符没有进行 remove ,所以 if 语句中进行了Math.max ( map.get ( s.charAt ( j ) ) , i ),要确认得到的下标不是 i 前边的。
还有个不同之处是 j 每次循环都进行了自加 1 ,因为 i 的跳跃已经保证了 str[ i , j] 内没有重复的字符串,所以 j 直接可以加 1 。而解法二中,要保持 j 的位置不变,因为不知道和 j 重复的字符在哪个位置。
最后个不同之处是, ans 在每次循环中都进行更新,因为 ans 更新前 i 都进行了更新,已经保证了当前的子串符合条件,所以可以更新 ans 。而解法二中,只有当当前的子串不包含当前的字符时,才进行更新。
时间复杂度:我们将 2n 优化到了 n ,但最终还是和之前一样,O(n)。
空间复杂度:也是一样的,O(min(m,n))。
5. 解法四
和解法三思路一样,区别的地方在于,我们不用 Hash ,而是直接用数组,字符的 ASCII 码值作为数组的下标,数组存储该字符所在字符串的位置。适用于字符集比较小的情况,因为我们会直接开辟和字符集等大的数组。
public class Solution {
public int lengthOfLongestSubstring(String s) {
int n = s.length(), ans = 0;
int[] index = new int[128];
for (int j = 0, i = 0; j < n; j++) {
i = Math.max(index[s.charAt(j)], i);
ans = Math.max(ans, j - i + 1);
index[s.charAt(j)] = j + 1;//(下标 + 1) 代表 i 要移动的下个位置
}
return ans;
}
}
和解法 3 不同的地方在于,没有了 if 的判断,因为如果 index[ s.charAt ( j ) ] 不存在的话,它的值会是 0 ,对最终结果不会影响。
时间复杂度:O(n)。
空间复杂度:O(m),m 代表字符集的大小。这次不论原字符串多小,都会利用这么大的空间。
6. 总结
综上,我们一步一步的寻求可优化的地方,对算法进行了优化。又加深了 Hash 的应用,以及利用数组巧妙的实现了 Hash 的作用。
第四题 :Median of Two Sorted Arrays
1. 题目描述(困难难度)

已知两个有序数组,找到两个数组合并后的中位数。
2. 解法一
简单粗暴,先将两个数组合并,两个有序数组的合并也是归并排序中的一部分。然后根据奇数,还是偶数,返回中位数。
3. 代码
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int[] nums;
int m = nums1.length;
int n = nums2.length;
nums = new int[m + n];
if (m == 0) {
if (n % 2 == 0) {
return (nums2[n / 2 - 1] + nums2[n / 2]) / 2.0;
} else {
return nums2[n / 2];
}
}
if (n == 0) {
if (m % 2 == 0) {
return (nums1[m / 2 - 1] + nums1[m / 2]) / 2.0;
} else {
return nums1[m / 2];
}
}
int count = 0;
int i = 0, j = 0;
while (count != (m + n)) {
if (i == m) {
while (j != n) {
nums[count++] = nums2[j++];
}
break;
}
if (j == n) {
while (i != m) {
nums[count++] = nums1[i++];
}
break;
}
if (nums1[i] < nums2[j]) {
nums[count++] = nums1[i++];
} else {
nums[count++] = nums2[j++];
}
}
if (count % 2 == 0) {
return (nums[count / 2 - 1] + nums[count / 2]) / 2.0;
} else {
return nums[count / 2];
}
}
时间复杂度:遍历全部数组,O(m + n)
空间复杂度:开辟了一个数组,保存合并后的两个数组,O(m + n)
4. 解法二
其实,我们不需要将两个数组真的合并,我们只需要找到中位数在哪里就可以了。
开始的思路是写一个循环,然后里边判断是否到了中位数的位置,到了就返回结果,但这里对偶数和奇数的分类会很麻烦。当其中一个数组遍历完后,出了 for 循环对边界的判断也会分几种情况。总体来说,虽然复杂度不影响,但代码会看起来很乱。然后在 这里 找到了另一种思路。
首先是怎么将奇数和偶数的情况合并一下。
用 len 表示合并后数组的长度,如果是奇数,我们需要知道第 (len + 1)/ 2 个数就可以了,如果遍历的话需要遍历 int ( len / 2 ) + 1 次。如果是偶数,我们需要知道第 len / 2 和 len / 2 + 1 个数,也是需要遍历 len / 2 + 1 次。所以遍历的话,奇数和偶数都是 len / 2 + 1 次。
返回中位数的话,奇数需要最后一次遍历的结果就可以了,偶数需要最后一次和上一次遍历的结果。所以我们用两个变量 left 和 right ,right 保存当前循环的结果,在每次循环前将 right 的值赋给 left 。这样在最后一次循环的时候,left 将得到 right 的值,也就是上一次循环的结果,接下来 right 更新为最后一次的结果。
循环中该怎么写,什么时候 A 数组后移,什么时候 B 数组后移。用 aStart 和 bStart 分别表示当前指向 A 数组和 B 数组的位置。如果 aStart 还没有到最后并且此时 A 位置的数字小于 B 位置的数组,那么就可以后移了。也就是aStart < m && A[aStart] < B[bStart]。
但如果 B 数组此刻已经没有数字了,继续取数字B [ bStart ],则会越界,所以判断下 bStart 是否大于数组长度了,这样 || 后边的就不会执行了,也就不会导致错误了,所以增加为 aStart < m && ( bStart >= n || A [ aStart ] < B [ bStart ] ) 。
5. 代码
public double findMedianSortedArrays(int[] A, int[] B) {
int m = A.length;
int n = B.length;
int len = m + n;
int left = -1, right = -1;
int aStart = 0, bStart = 0;
for (int i = 0; i <= len / 2; i++) {
left = right;
if (aStart < m && (bStart >= n || A[aStart] < B[bStart])) {
right = A[aStart++];
} else {
right = B[bStart++];
}
}
if ((len & 1) == 0)
return (left + right) / 2.0;
else
return right;
}
时间复杂度:遍历 len/2 + 1 次,len = m + n ,所以时间复杂度依旧是 O(m + n)。
空间复杂度:我们申请了常数个变量,也就是 m,n,len,left,right,aStart,bStart 以及 i 。
总共 8 个变量,所以空间复杂度是 O(1)。
6. 解法三
上边的两种思路,时间复杂度都达不到题目的要求 O ( log ( m + n ) )。看到 log ,很明显,我们只有用到二分的方法才能达到。我们不妨用另一种思路,题目是求中位数,其实就是求第 k 小数的一种特殊情况,而求第 k 小数有一种算法。
解法二中,我们一次遍历就相当于去掉不可能是中位数的一个值,也就是一个一个排除。由于数列是有序的,其实我们完全可以一半儿一半儿的排除。假设我们要找第 k 小数,我们可以每次循环排除掉 k / 2 个数。看下边一个例子。
假设我们要找第 7 小的数字。
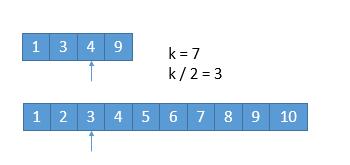
我们比较两个数组的第 k / 2 个数字,如果 k 是奇数,向下取整。也就是比较第 3 个数字,上边数组中的 4 和 下边数组中的 3 ,如果哪个小,就表明该数组的前 k / 2 个数字都不是第 k 小数字,所以可以排除。也就是 1,2,3 这三个数字不可能是第 7 小的数字,我们可以把它排除掉。将 1349 和 45678910 两个数组作为新的数组进行比较。
更一般的情况 A [ 1 ],A [ 2 ],A [ 3 ],A [ k / 2] … ,B[ 1 ],B [ 2 ],B [ 3 ],B[ k / 2] … ,如果 A [ k / 2 ] < B [ k / 2 ] ,那么 A [ 1 ],A [ 2 ],A [ 3 ],A [ k / 2] 都不可能是第 k 小的数字。
A 数组中比 A [ k / 2 ] 小的数有 k / 2 - 1 个,B 数组中,B [ k / 2 ] 比 A [ k / 2 ] 大,假设 B [ k / 2 ] 前边的数字都比 A [ k / 2 ] 小,也只有 k / 2 - 1 个,所以比 A [ k / 2 ] 小的数字最多有 k / 2 - 1 + k / 2 - 1 = k - 2 个,所以 A [ k / 2 ] 最多是第 k - 1 小的数。而比 A [ k / 2 ] 小的数更不可能是第 k 小的数了,所以可以把它们排除。
橙色的部分表示已经去掉的数字。
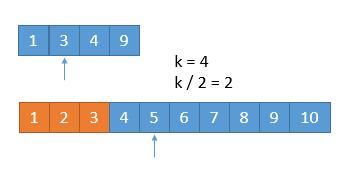
由于我们已经排除掉了 3 个数字,就是这 3 个数字一定在最前边,所以在两个新数组中,我们只需要找第 7 - 3 = 4 小的数字就可以了,也就是 k = 4 。此时两个数组,比较第 2 个数字,3 < 5,所以我们可以把小的那个数组中的 1 ,3 排除掉了。
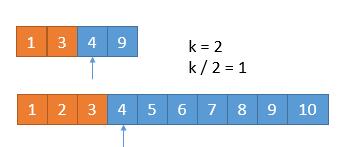
我们又排除掉 2 个数字,所以现在找第 4 - 2 = 2 小的数字就可以了。此时比较两个数组中的第 k / 2 = 1 个数,4 == 4 ,怎么办呢?由于两个数相等,所以我们无论去掉哪个数组中的都行,因为去掉 1 个总会保留 1 个的,所以没有影响。为了统一,我们就假设 4 > 4 吧,所以此时将下边的 4 去掉。
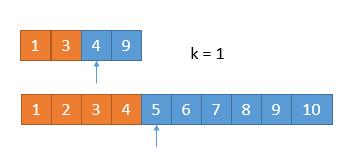
由于又去掉 1 个数字,此时我们要找第 1 小的数字,所以只需判断两个数组中第一个数字哪个小就可以了,也就是 4 。
所以第 7 小的数字是 4 。
我们每次都是取 k / 2 的数进行比较,有时候可能会遇到数组长度小于 k / 2 的时候。

此时 k / 2 等于 3 ,而上边的数组长度是 2 ,我们此时将箭头指向它的末尾就可以了。这样的话,由于 2 < 3 ,所以就会导致上边的数组 1,2 都被排除。造成下边的情况。

由于 2 个元素被排除,所以此时 k = 5 ,又由于上边的数组已经空了,我们只需要返回下边的数组的第 5 个数字就可以了。
从上边可以看到,无论是找第奇数个还是第偶数个数字,对我们的算法并没有影响,而且在算法进行中,k 的值都有可能从奇数变为偶数,最终都会变为 1 或者由于一个数组空了,直接返回结果。
所以我们采用递归的思路,为了防止数组长度小于 k / 2 ,所以每次比较 min ( k / 2,len ( 数组 ) ) 对应的数字,把小的那个对应的数组的数字排除,将两个新数组进入递归,并且 k 要减去排除的数字的个数。递归出口就是当 k = 1 或者其中一个数字长度是 0 了。
7. 代码
public double findMedianSortedArrays(int[] nums1, int[] nums2) {
int n = nums1.length;
int m = nums2.length;
int left = (n + m + 1) / 2;
int right = (n + m + 2) / 2;
//将偶数和奇数的情况合并,如果是奇数,会求两次同样的 k 。
return (getKth(nums1, 0, n - 1, nums2, 0, m - 1, left) + getKth(nums1, 0, n - 1, nums2, 0, m - 1, right)) * 0.5;
}
private int getKth(int[] nums1, int start1, int end1, int[] nums2, int start2, int end2, int k) {
int len1 = end1 - start1 + 1;
int len2 = end2 - start2 + 1;
//让 len1 的长度小于 len2,这样就能保证如果有数组空了,一定是 len1
if (len1 > len2) return getKth(nums2, start2, end2, nums1, start1, end1, k);
if (len1 == 0) return nums2[start2 + k - 1];
if (k == 1) return Math.min(nums1[start1], nums2[start2]);
int i = start1 + Math.min(len1, k / 2) - 1;
int j = start2 + Math.min(len2, k / 2) - 1;
if (nums1[i] > nums2[j]) {
return getKth(nums1, start1, end1, nums2, j + 1, end2, k - (j - start2 + 1));
}
else {
return getKth(nums1, i + 1, end1, nums2, start2, end2, k - (i - start1 + 1));
}
}
时间复杂度:每进行一次循环,我们就减少 k / 2 个元素,所以时间复杂度是 O(log(k)),而 k = (m + n)/ 2 ,所以最终的复杂也就是 O(log(m + n))。
空间复杂度:虽然我们用到了递归,但是可以看到这个递归属于尾递归,所以编译器不需要不停地堆栈,所以空间复杂度为 O(1)。
8. 解法四
我们首先理一下中位数的定义是什么
中位数(又称中值,英语:Median),统计学中的专有名词,代表一个样本、种群或概率分布中的一个数值,其可将数值集合划分为相等的上下两部分。
所以我们只需要将数组进行切。
一个长度为 m 的数组,有 0 到 m 总共 m + 1 个位置可以切。
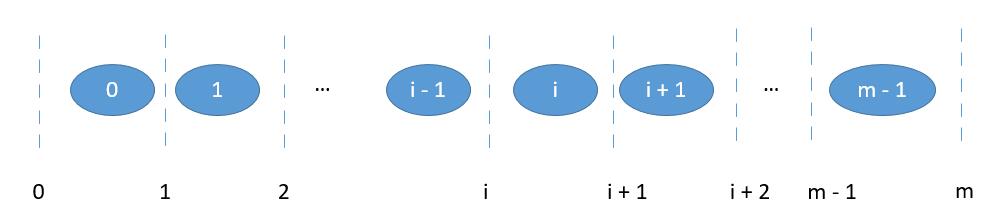
我们把数组 A 和数组 B 分别在 i 和 j 进行切割。

将 i 的左边和 j 的左边组合成「左半部分」,将 i 的右边和 j 的右边组合成「右半部分」。
-
当 A 数组和 B 数组的总长度是偶数时,如果我们能够保证
-
左半部分的长度等于右半部分
i + j = m - i + n - j , 也就是 j = ( m + n ) / 2 - i
-
左半部分最大的值小于等于右半部分最小的值 max ( A [ i - 1 ] , B [ j - 1 ])) <= min ( A [ i ] , B [ j ]))
那么,中位数就可以表示如下
(左半部分最大值 + 右半部分最小值 )/ 2 。
(max ( A [ i - 1 ] , B [ j - 1 ])+ min ( A [ i ] , B [ j ])) / 2
-
-
当 A 数组和 B 数组的总长度是奇数时,如果我们能够保证
-
左半部分的长度比右半部分大 1
i + j = m - i + n - j + 1也就是 j = ( m + n + 1) / 2 - i
-
左半部分最大的值小于等于右半部分最小的值 max ( A [ i - 1 ] , B [ j - 1 ])) <= min ( A [ i ] , B [ j ]))
那么,中位数就是
左半部分最大值,也就是左半部比右半部分多出的那一个数。
max ( A [ i - 1 ] , B [ j - 1 ])
-
上边的第一个条件我们其实可以合并为 j = ( m + n + 1) / 2 - i,因为如果 m + n 是偶数,由于我们取的是 int 值,所以加 1 也不会影响结果。当然,由于 0 <= i <= m ,为了保证 0 <= j <= n ,我们必须保证 m <= n 。
m≤n,i<m,j=(m+n+1)/2−i≥(m+m+1)/2−i>(m+m+1)/2−m=0m\leq n,i<m,j=(m+n+1)/2-i\geq(m+m+1)/2-i>(m+m+1)/2-m=0m≤n,i<m,j=(m+n+1)/2−i≥(m+m+1)/2−i>(m+m+1)/2−m=0
m≤n,i>0,j=(m+n+1)/2−i≤(n+n+1)/2−i<(n+n+1)/2=nm\leq n,i>0,j=(m+n+1)/2-i\leq (n+n+1)/2-i<(n+n+1)/2=nm≤n,i>0,j=(m+n+1)/2−i≤(n+n+1)/2−i<(n+n+1)/2=n
最后一步由于是 int 间的运算,所以 1 / 2 = 0。
而对于第二个条件,奇数和偶数的情况是一样的,我们进一步分析。为了保证 max ( A [ i - 1 ] , B [ j - 1 ])) <= min ( A [ i ] , B [ j ])),因为 A 数组和 B 数组是有序的,所以 A [ i - 1 ] <= A [ i ],B [ i - 1 ] <= B [ i ] 这是天然的,所以我们只需要保证 B [ j - 1 ] < = A [ i ] 和 A [ i - 1 ] <= B [ j ] 所以我们分两种情况讨论:
-
B [ j - 1 ] > A [ i ],并且为了不越界,要保证 j != 0,i != m
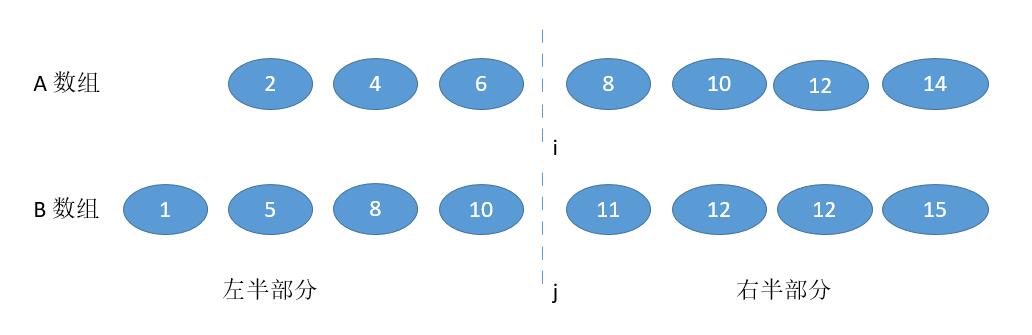
此时很明显,我们需要增加 i ,为了数量的平衡还要减少 j ,幸运的是 j = ( m + n + 1) / 2 - i,i 增大,j 自然会减少。
-
A [ i - 1 ] > B [ j ] ,并且为了不越界,要保证 i != 0,j != n

此时和上边的情况相反,我们要减少 i ,增大 j 。
上边两种情况,我们把边界都排除了,需要单独讨论。
-
当 i = 0 , 或者 j = 0 ,也就是切在了最前边。
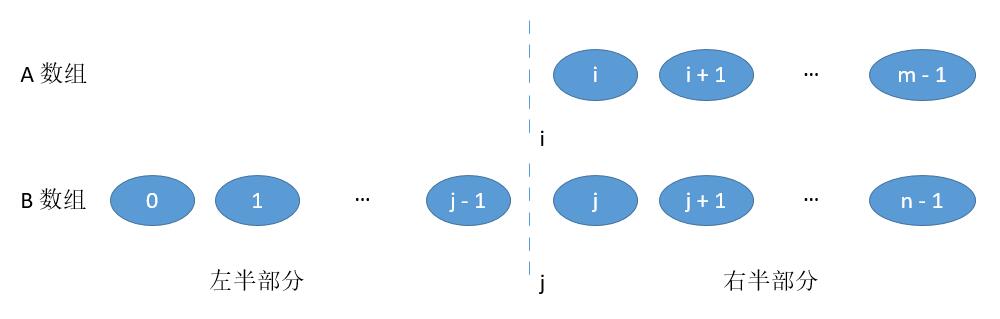
此时左半部分当 j = 0 时,最大的值就是 A [ i - 1 ] ;当 i = 0 时 最大的值就是 B [ j - 1] 。右半部分最小值和之前一样。
-
当 i = m 或者 j = n ,也就是切在了最后边。
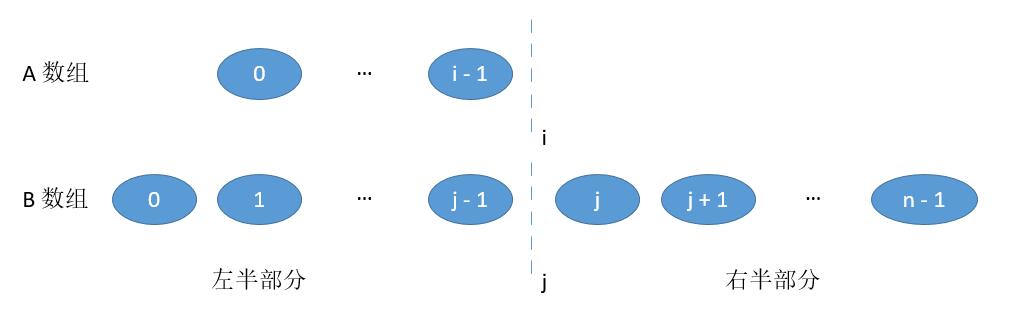
此时左半部分最大值和之前一样。右半部分当 j = n 时,最小值就是 A [ i ] ;当 i = m 时,最小值就是B [ j ] 。
所有的思路都理清了,最后一个问题,增加 i 的方式。当然用二分了。初始化 i 为中间的值,然后减半找中间的,减半找中间的,减半找中间的直到答案。
class Solution {
public double findMedianSortedArrays(int[] A, int[] B) {
int m = A.length;
int n = B.length;
if (m > n) {
return findMedianSortedArrays(B,A); // 保证 m <= n
}
int iMin = 0, iMax = m;
while (iMin <= iMax) {
int i = (iMin + iMax) / 2;
int j = (m + n + 1) / 2 - i;
if (j != 0 && i != m && B[j-1] > A[i]){ // i 需要增大
iMin = i + 1;
}
else if (i != 0 && j != n && A[i-1] > B[j]) { // i 需要减小
iMax = i - 1;
}
else { // 达到要求,并且将边界条件列出来单独考虑
int maxLeft = 0;
if (i == 0) { maxLeft = B[j-1]; }
else if (j == 0) { maxLeft = A[i-1]; }
else { maxLeft = Math.max(A[i-1], B[j-1]); }
if ( (m + n) % 2 == 1 ) { return maxLeft; } // 奇数的话不需要考虑右半部分
int minRight = 0;
if (i == m) { minRight = B[j]; }
else if (j == n) { minRight = A[i]; }
else { minRight = Math.min(B[j], A[i]); }
return (maxLeft + minRight) / 2.0; //如果是偶数的话返回结果
}
}
return 0.0;
}
}
时间复杂度:我们对较短的数组进行了二分查找,所以时间复杂度是 O(log(min(m,n)))。
空间复杂度:只有一些固定的变量,和数组长度无关,所以空间复杂度是 O ( 1 ) 。
9. 总结
解法二中体会到了对情况的转换,有时候即使有了思路,代码也不一定写的优雅,需要多锻炼才可以。解法三和解法四充分发挥了二分查找的优势,将时间复杂度降为 log 级别。
第五题: Longest Palindromic Substring
1. 题目描述(中等难度)
给定一个字符串,输出最长的回文子串。回文串指的是正的读和反的读是一样的字符串,例如 “aba”,“ccbbcc”。
2. 解法一 暴力破解
暴力求解,列举所有的子串,判断是否为回文串,保存最长的回文串。
public boolean isPalindromic(String s) {
int len = s.length();
for (int i = 0; i < len / 2; i++) {
if (s.charAt(i) != s.charAt(len - i - 1)) {
return false;
}
}
return true;
}
// 暴力解法
public String longestPalindrome(String s) {
String ans = "";
int max = 0;
int len = s.length();
for (int i = 0; i < len; i++)
for (int j = i + 1; j <= len; j++) {
String test = s.substring(i, j);
if (isPalindromic(test) && test.length() > max) {
ans = s.substring(i, j);
max = Math.max(max, ans.length());
}
}
return ans;
}
时间复杂度:两层 for 循环 O(n²),for 循环里边判断是否为回文,O(n),所以时间复杂度为 O(n³)。
空间复杂度:O(1),常数个变量。
3. 解法二 最长公共子串
根据回文串的定义,正着和反着读一样,那我们是不是把原来的字符串倒置了,然后找最长的公共子串就可以了。例如,S = " caba",S’ = " abac",最长公共子串是 “aba”,所以原字符串的最长回文串就是 “aba”。
关于求最长公共子串(不是公共子序列),有很多方法,这里用动态规划的方法,可以先阅读下边的链接。
https://blog.csdn.net/u010397369/article/details/38979077
https://www.kancloud.cn/digest/pieces-algorithm/163624
整体思想就是,申请一个二维的数组初始化为 0,然后判断对应的字符是否相等,相等的话
arr [ i ][ j ] = arr [ i - 1 ][ j - 1] + 1 。
当 i = 0 或者 j = 0 的时候单独分析,字符相等的话 arr [ i ][ j ] 就赋为 1 。
arr [ i ][ j ] 保存的就是公共子串的长度。
public String longestPalindrome(String s) {
if (s.equals(""))
return "";
String origin = s;
String reverse = new StringBuffer(s).reverse().toString(); //字符串倒置
int length = s.length();
int[][] arr = new int[length][length];
int maxLen = 0;
int maxEnd = 0;
for (int i = 0; i < length; i++)
for (int j = 0; j < length; j++) {
if (origin.charAt(i) == reverse.charAt(j)) {
if (i == 0 || j == 0) {
arr[i][j] = 1;
} else {
arr[i][j] = arr[i - 1][j - 1] + 1;
}
}
if (arr[i][j] > maxLen) {
maxLen = arr[i][j];
maxEnd = i; //以 i 位置结尾的字符
}
}
}
return s.substring(maxEnd - maxLen + 1, maxEnd + 1);
}
再看一个例子,S = “abc435cba”,S’ = “abc534cba” ,最长公共子串是 “abc” 和 “cba” ,但很明显这两个字符串都不是回文串。
所以我们求出最长公共子串后,并不一定是回文串,我们还需要判断该字符串倒置前的下标和当前的字符串下标是不是匹配。
比如 S = " caba ",S’ = " abac " ,S’ 中 aba 的下标是 0 1 2 ,倒置前是 3 2 1,和 S 中 aba 的下标符合,所以 aba 就是我们需要找的。当然我们不需要每个字符都判断,我们只需要判断末尾字符就可以。
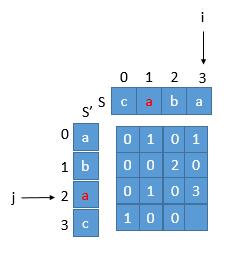
首先 i ,j 始终指向子串的末尾字符。所以 j 指向的红色的 a 倒置前的下标是 beforeRev = length - 1 - j = 4 - 1 - 2 = 1,对应的是字符串首位的下标,我们还需要加上字符串的长度才是末尾字符的下标,也就是 beforeRev + arr[ i ] [ j ] - 1 = 1 + 3 - 1 = 3,因为 arr[ i ] [ j ] 保存的就是当前子串的长度,也就是图中的数字 3 。此时再和它与 i 比较,如果相等,则说明它是我们要找的回文串。
之前的 S = “abc435cba”,S’ = “abc534cba” ,可以看一下图示,为什么不符合。
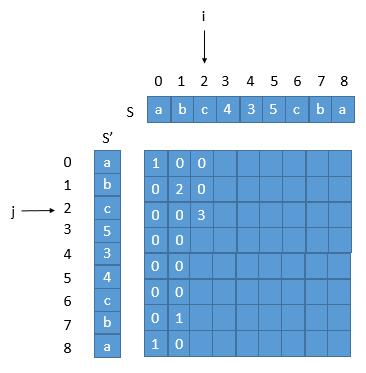
当前 j 指向的 c ,倒置前的下标是 beforeRev = length - 1 - j = 9 - 1 - 2 = 6,对应的末尾下标是 beforeRev + arr[ i ] [ j ] - 1 = 6 + 3 - 1 = 8 ,而此时 i = 2 ,所以当前的子串不是回文串。
代码的话,在上边的基础上,保存 maxLen 前判断一下下标匹不匹配就可以了。
public String longestPalindrome(String s) {
if (s.equals(""))
return "";
String origin = s;
String reverse = new StringBuffer(s).reverse().toString();
int length = s.length();
int[][] arr = new int[length][length];
int maxLen = 0;
int maxEnd = 0;
for (int i = 0; i < length; i++)
for (int j = 0; j < length; j++) {
if (origin.charAt(i) == reverse.charAt(j)) {
if (i == 0 || j == 0) {
arr[i][j] = 1;
} else {
arr[i][j] = arr[i - 1][j - 1] + 1;
}
}
/**********修改的地方*******************/
if (arr[i][j] > maxLen) {
int beforeRev = length - 1 - j;
if (beforeRev + arr[i][j] - 1 == i) { //判断下标是否对应
maxLen = arr[i][j];
maxEnd = i;
}
/*************************************/
}
}
return s.substring(maxEnd - maxLen + 1, maxEnd + 1);
}
时间复杂度:两层循环,O(n²)。
空间复杂度:一个二维数组,O(n²)。
空间复杂度其实可以再优化一下。
我们分析一下循环,i = 0 ,j = 0,1,2 … 8 更新一列,然后 i = 1 ,再更新一列,而更新的时候我们其实只需要上一列的信息,更新第 3 列的时候,第 1 列的信息是没有用的。所以我们只需要一个一维数组就可以了。但是更新 arr [ i ] 的时候我们需要 arr [ i - 1 ] 的信息,假设 a [ 3 ] = a [ 2 ] + 1,更新 a [ 4 ] 的时候, 我们需要 a [ 3 ] 的信息,但是 a [ 3 ] 在之前已经被更新了,所以 j 不能从 0 到 8 ,应该倒过来,a [ 8 ] = a [ 7 ] + 1,a [ 7 ] = a [ 6 ] + 1 , 这样更新 a [ 8 ] 的时候用 a [ 7 ] ,用完后才去更新 a [ 7 ],保证了不会出错。
public String longestPalindrome(String s) {
if (s.equals(""))
return "";
String origin = s;
String reverse = new StringBuffer(s).reverse().toString();
int length = s.length();
int[] arr = new int[length];
int maxLen = 0;
int maxEnd = 0;
for (int i = 0; i < length; i++)
/**************修改的地方***************************/
for (int j = length - 1; j >= 0; j--) {
/**************************************************/
if (origin.charAt(i) == reverse.charAt(j)) {
if (i == 0 || j == 0) {
arr[j] = 1;
} else {
arr[j] = arr[j - 1] + 1;
}
/**************修改的地方***************************/
//之前二维数组,每次用的是不同的列,所以不用置 0 。
} else {
arr[j] = 0;
}
/**************************************************/
if (arr[j] > maxLen) {
int beforeRev = length - 1 - j;
if (beforeRev + arr[j] - 1 == i) {
maxLen = arr[j];
maxEnd = i;
}
}
}
return s.substring(maxEnd - maxLen + 1, maxEnd + 1);
}
时间复杂度:O(n²)。
空间复杂度:降为 O(n)。
4. 解法三 暴力破解优化
解法一的暴力解法时间复杂度太高,在 leetCode 上并不能 AC 。我们可以考虑,去掉一些暴力解法中重复的判断。我们可以基于下边的发现,进行改进。
首先定义 P(i,j)。
P(i,j)={trues[i,j]是回文串falses[i,j]不是回文串P(i,j)=\begin{cases}true& \text{s[i,j]是回文串} \\false& \text{s[i,j]不是回文串}\end{cases}P(i,j)=⎩⎪⎨⎪⎧truefalses[i,j]是回文串s[i,j]不是回文串
接下来
P(i,j)=(P(i+1,j−1)&&S[i]==S[j])P(i,j)=(P(i+1,j-1)&&S[i]==S[j])P(i,j)=(P(i+1,j−1)&&S[i]==S[j])
所以如果我们想知道 P(i,j)的情况,不需要调用判断回文串的函数了,只需要知道 P(i + 1,j - 1)的情况就可以了,这样时间复杂度就少了 O(n)。因此我们可以用动态规划的方法,空间换时间,把已经求出的 P(i,j)存储起来。
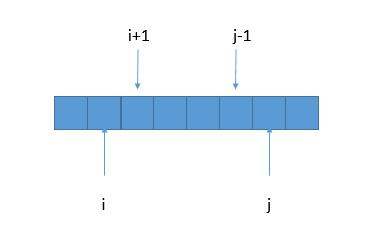
如果 S[i+1,j−1]S[i+1,j-1]S[i+1,j−1] 是回文串,那么只要 S [ i ] == S [ j ] ,就可以确定 S [ i , j ] 也是回文串了。
求 长度为 1 和长度为 2 的 P ( i , j ) 时不能用上边的公式,因为我们代入公式后会遇到 P[i][j]P[i][j]P[i][j] 中 i > j 的情况,比如求 P[1][2]P[1][2]P[1][2] 的话,我们需要知道 P[1+1][2−1]=P[2][1]P[1+1][2-1]=P[2][1]P[1+1][2−1]=P[2][1] ,而 P[2][1]P[2][1]P[2][1] 代表着 S[2,1]S[2,1]S[2,1] 是不是回文串,显然是不对的,所以我们需要单独判断。
所以我们先初始化长度是 1 的回文串的 P [ i , j ],这样利用上边提出的公式 P(i,j)=(P(i+1,j−1)&&S[i]==S[j])P(i,j)=(P(i+1,j-1)&&S[i]==S[j])P(i,j)=(P(i+1,j−1)&&S[i]==S[j]),然后两边向外各扩充一个字符,长度为 3 的,为 5 的,所有奇数长度的就都求出来了。
同理,初始化长度是 2 的回文串 P [ i , i + 1 ],利用公式,长度为 4 的,6 的所有偶数长度的就都求出来了。
public String longestPalindrome(String s) {
int length = s.length();
boolean[][] P = new boolean[length][length];
int maxLen = 0;
String maxPal = "";
for (int len = 1; len <= length; len++) //遍历所有的长度
for (int start = 0; start < length; start++) {
int end = start + len - 1;
if (end >= length) //下标已经越界,结束本次循环
break;
P[start][end] = (len == 1 || len == 2 || P[start + 1][end - 1]) && s.charAt(start) == s.charAt(end); //长度为 1 和 2 的单独判断下
if (P[start][end] && len > maxLen) {
maxPal = s.substring(start, end + 1);
}
}
return maxPal;
}
时间复杂度:两层循环,O(n²)。
空间复杂度:用二维数组 P 保存每个子串的情况,O(n²)。
我们分析下每次循环用到的 P(i,j),看一看能不能向解法二一样优化一下空间复杂度。
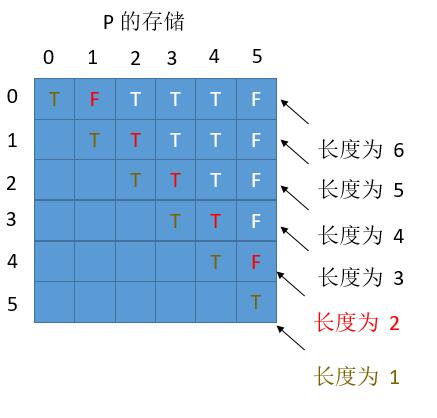
当我们求长度为 6 和 5 的子串的情况时,其实只用到了 4 , 3 长度的情况,而长度为 1 和 2 的子串情况其实已经不需要了。但是由于我们并不是用 P 数组的下标进行的循环,暂时没有想到优化的方法。
之后看到了另一种动态规划的思路
https://leetcode.com/problems/longest-palindromic-substring/discuss/2921/Share-my-Java-solution-using-dynamic-programming 。
公式还是这个不变
首先定义 P(i,j)。
P(i,j)={trues[i,j]是回文串falses[i,j]不是回文串P(i,j)=\begin{cases}true& \text{s[i,j]是回文串}\\false& \text{s[i,j]不是回文串}\end{cases}P(i,j)=⎩⎪⎨⎪⎧truefalses[i,j]是回文串s[i,j]不是回文串
接下来
P(i,j)=(P(i+1,j−1)&&S[i]==S[j])P(i,j)=(P(i+1,j-1)&&S[i]==S[j])P(i,j)=(P(i+1,j−1)&&S[i]==S[j])
递推公式中我们可以看到,我们首先知道了 i +1 才会知道 i ,所以我们只需要倒着遍历就行了。
public String longestPalindrome(String s) {
int n = s.length();
String res = "";
boolean[][] dp = new boolean[n][n];
for (int i = n - 1; i >= 0; i--) {
for (int j = i; j < n; j++) {
dp[i][j] = s.charAt(i) == s.charAt(j) && (j - i < 2 || dp[i + 1][j - 1]); //j - i 代表长度减去 1
if (dp[i][j] && j - i + 1 > res.length()) {
res = s.substring(i, j + 1);
}
}
}
return res;
}
时间复杂度和空间复杂和之前都没有变化,我们来看看可不可以优化空间复杂度。
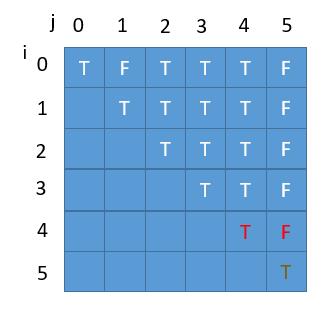
当求第 i 行的时候我们只需要第 i + 1 行的信息,并且 j 的话需要 j - 1 的信息,所以和之前一样 j 也需要倒叙。
public String longestPalindrome7(String s) {
int n = s.length();
String res = "";
boolean[] P = new boolean[n];
for (int i = n - 1; i >= 0; i--) {
for (int j = n - 1; j >= i; j--) {
P[j] = s.charAt(i) == s.charAt(j) && (j - i < 3 || P[j - 1]);
if (P[j] && j - i + 1 > res.length()) {
res = s.substring(i, j + 1);
}
}
}
return res;
}
时间复杂度:不变,O(n²)。
空间复杂度:降为 O(n ) 。
5. 解法四 扩展中心
我们知道回文串一定是对称的,所以我们可以每次循环选择一个中心,进行左右扩展,判断左右字符是否相等即可。
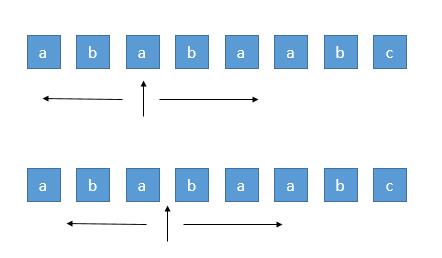
由于存在奇数的字符串和偶数的字符串,所以我们需要从一个字符开始扩展,或者从两个字符之间开始扩展,所以总共有 n + n - 1 个中心。
public String longestPalindrome(String s) {
if (s == null || s.length() < 1) return "";
int start = 0, end = 0;
for (int i = 0; i < s.length(); i++) {
int len1 = expandAroundCenter(s, i, i);
int len2 = expandAroundCenter(s, i, i + 1);
int len = Math.max(len1, len2);
if (len > end - start) {
start = i - (len - 1) / 2;
end = i + len / 2;
}
}
return s.substring(start, end + 1);
}
private int expandAroundCenter(String s, int left, int right) {
int L = left, R = right;
while (L >= 0 && R < s.length() && s.charAt(L) == s.charAt(R)) {
L--;
R++;
}
return R - L - 1;
}
时间复杂度:O(n²)。
空间复杂度:O(1)。
6. 解法五 Manacher’s Algorithm 马拉车算法。
马拉车算法 Manacher‘s Algorithm 是用来查找一个字符串的最长回文子串的线性方法,由一个叫Manacher的人在1975年发明的,这个方法的最大贡献是在于将时间复杂度提升到了线性。
主要参考了下边链接进行讲解。
https://segmentfault.com/a/1190000008484167
https://blog.crimx.com/2017/07/06/manachers-algorithm/
http://ju.outofmemory.cn/entry/130005
https://articles.leetcode.com/longest-palindromic-substring-part-ii/
首先我们解决下奇数和偶数的问题,在每个字符间插入"#",并且为了使得扩展的过程中,到边界后自动结束,在两端分别插入 “^” 和 “$”,两个不可能在字符串中出现的字符,这样中心扩展的时候,判断两端字符是否相等的时候,如果到了边界就一定会不相等,从而出了循环。经过处理,字符串的长度永远都是奇数了。

首先我们用一个数组 P 保存从中心扩展的最大个数,而它刚好也是去掉 “#” 的原字符串的总长度。例如下图中下标是 6 的地方。可以看到 P[ 6 ] 等于 5,所以它是从左边扩展 5 个字符,相应的右边也是扩展 5 个字符,也就是 “#c#b#c#b#c#”。而去掉 # 恢复到原来的字符串,变成 “cbcbc”,它的长度刚好也就是 5。

7. 求原字符串下标
用 P 的下标 i 减去 P [ i ],再除以 2 ,就是原字符串的开头下标了。
例如我们找到 P[ i ] 的最大值为 5 ,也就是回文串的最大长度是 5 ,对应的下标是 6 ,所以原字符串的开头下标是 (6 - 5 )/ 2 = 0 。所以我们只需要返回原字符串的第 0 到 第 (5 - 1)位就可以了。
8. 求每个 P [ i ]
接下来是算法的关键了,它充分利用了回文串的对称性。
我们用 C 表示回文串的中心,用 R 表示回文串的右边半径坐标,所以 R = C + P[ C ] 。C 和 R 所对应的回文串是当前循环中 R 最靠右的回文串。
让我们考虑求 P [ i ] 的时候,如下图。
用 i_mirror 表示当前需要求的第 i 个字符关于 C 对应的下标。
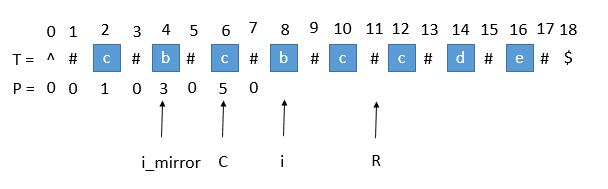
我们现在要求 P [ i ], 如果是用中心扩展法,那就向两边扩展比对就行了。但是我们其实可以利用回文串 C 的对称性。i 关于 C 的对称点是 i_mirror ,P [ i_mirror ] = 3,所以 P [ i ] 也等于 3 。
但是有三种情况将会造成直接赋值为 P [ i_mirror ] 是不正确的,下边一一讨论。
8.1. 1. 超出了 R
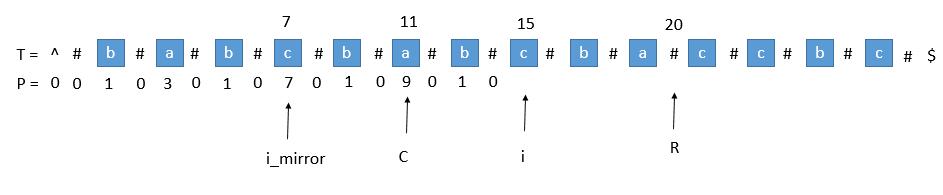
当我们要求 P [ i ] 的时候,P [ mirror ] = 7,而此时 P [ i ] 并不等于 7 ,为什么呢,因为我们从 i 开始往后数 7 个,等于 22 ,已经超过了最右的 R ,此时不能利用对称性了,但我们一定可以扩展到 R 的,所以 P [ i ] 至少等于 R - i = 20 - 15 = 5,会不会更大呢,我们只需要比较 T [ R+1 ] 和 T [ R+1 ]关于 i 的对称点就行了,就像中心扩展法一样一个个扩展。
8.2. 2. P [ i_mirror ] 遇到了原字符串的左边界
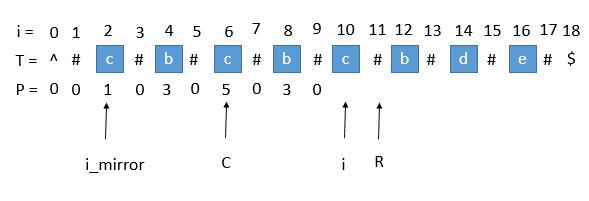
此时P [ i_mirror ] = 1,但是 P [ i ] 赋值成 1 是不正确的,出现这种情况的原因是 P [ i_mirror ] 在扩展的时候首先是 “#” == “#” ,之后遇到了 "^"和另一个字符比较,也就是到了边界,才终止循环的。而 P [ i ] 并没有遇到边界,所以我们可以继续通过中心扩展法一步一步向两边扩展就行了。
8.3. 3. i 等于了 R
此时我们先把 P [ i ] 赋值为 0 ,然后通过中心扩展法一步一步扩展就行了。
9. 考虑 C 和 R 的更新
就这样一步一步的求出每个 P [ i ],当求出的 P [ i ] 的右边界大于当前的 R 时,我们就需要更新 C 和 R 为当前的回文串了。因为我们必须保证 i 在 R 里面,所以一旦有更右边的 R 就要更新 R。
此时的 P [ i ] 求出来将会是 3 ,P [ i ] 对应的右边界将是 10 + 3 = 13,所以大于当前的 R ,我们需要把 C 更新成 i 的值,也就是 10 ,R 更新成 13。继续下边的循环。
public String preProcess(String s) {
int n = s.length();
if (n == 0) {
return "^$";
}
String ret = "^";
for (int i = 0; i < n; i++)
ret += "#" + s.charAt(i);
ret += "#$";
return ret;
}
// 马拉车算法
public String longestPalindrome(String s) {
String T = preProcess(s);
int n = T.length();
int[] P = new int[n];
int C = 0, R = 0;
for (int i = 1; i < n - 1; i++) {
int i_mirror = 2 * C - i;
if (R > i) {
P[i] = Math.min(R - i, P[i_mirror]);// 防止超出 R
} else {
P[i] = 0;// 等于 R 的情况
}
// 碰到之前讲的三种情况时候,需要利用中心扩展法
while (T.charAt(i + 1 + P[i]) == T.charAt(i - 1 - P[i])) {
P[i]++;
}
// 判断是否需要更新 R
if (i + P[i] > R) {
C = i;
R = i + P[i];
}
}
// 找出 P 的最大值
int maxLen = 0;
int centerIndex = 0;
for (int i = 1; i < n - 1; i++) {
if (P[i] > maxLen) {
maxLen = P[i];
centerIndex = i;
}
}
int start = (centerIndex - maxLen) / 2; //最开始讲的求原字符串下标
return s.substring(start, start + maxLen);
}
时间复杂度:for 循环里边套了一层 while 循环,难道不是 O ( n² )?不!其实是 O ( n )。不严谨的想一下,因为 while 循环访问 R 右边的数字用来扩展,也就是那些还未求出的节点,然后不断扩展,而期间访问的节点下次就不会再进入 while 了,可以利用对称得到自己的解,所以每个节点访问都是常数次,所以是 O ( n )。
空间复杂度:O(n)。
10. 总结
时间复杂度从三次方降到了一次,美妙!这里两次用到了动态规划去求解,初步认识了动态规划,就是将之前求的值保存起来,方便后边的计算,使得一些多余的计算消失了。并且在动态规划中,通过观察数组的利用情况,从而降低了空间复杂度。而 Manacher 算法对回文串对称性的充分利用,不得不让人叹服,自己加油啦!
今天我们一起学习了LeetCode 1-5题的算法分析,感谢大家阅读,觉得不错记得收藏哦!
喜欢 请点个 + 关注
相关文章
- Java反射机制详解(3) -java的反射和代理实现IOC模式 模拟spring
- 【JAVA】Eclipse中开启java和xml智能提示功能(图文,已解决!)
- 【LeetCode-面试算法经典-Java实现】【033-Search in Rotated Sorted Array(在旋转数组中搜索)】
- LeetCode 11-15 题 详解 Java版 ( 万字 图文详解 LeetCode 算法题11-15 =====>>> <建议收藏>)
- LeetCode 6-10 题 详解 Java版 ( 万字 图文详解 LeetCode 算法题6-10 =====>>> <建议收藏>)
- LeetCode 16-20 题 详解 Java版 ( 万字 图文详解 LeetCode 算法题16-20 =====>>> <建议收藏>)
- 回归JAVA: java文件编译后,出现xx$1.class的原因
- Java核心技术卷I基础知识3.5.8 括号与运算符级别
- Java: Method Reference
- Java项目(前端vue后台java微服务)在线考试系统(java+vue+springboot+mysql+maven)
- Java详解,java后端应届生面试题
- 【Java】整理关于java的String类,equals函数和比较操作符的区别
- JSON和JAVA的POJO的相互转换【转载】
- java.lang.OutOfMemoryError: Java heap space
- 【Java数据结构与算法】LeetCode面试题02.07 链表相交
- 【Java数据结构与算法】LeetCode 0206. 反转链表的三种Java实现方法
- 『Java练习生的自我修养』java-se进阶⁴ • IO流概览
- 华为OD机试 - 求最多可以派出多少支团队(Java) | 机试题+算法思路+考点+代码解析 【2023】
- 【JAVA】Exception in thread "main" java.lang.NoClassDefFoundError
- java学习路线-Java技术人员之路从0基础到高级
- 【LeetCode-面试算法经典-Java实现】【015-3 Sum(三个数的和)】
- JAVA学习(三):Java基础语法(变量、常量、数据类型、运算符与数据类型转换)
- 【深入JAVA】java注解
- 【LeetCode-面试算法经典-Java实现】【05-Longest Palindromic Substring(最大回文字符串)】
- JAVA基础(1 集合框架)
- 实操代码研究各种Java技术-java.toutiao.im
- [java][db]JAVA分布式事务原理及应用
- 【java养成】:案例(批量操作文件功能、商城进货交易记录程序设计)
- JAVA日常开发中常用的日志记录方式,攒个赞好不好?
- 什么是Java序列化,如何实现java序列化
- Java 报错 Information:java: javacTask: 源发行版 8 需要目标发行版 1.8
- 解决Java使用response下载文件报错,并总结可能出错的原因: java.io.IOException: 你的主机中的软件中止了一个已建立的连接。