
JVM内存溢出问题排查
内存溢出 out of memory : 通俗理解就是内存不够用了,是我们工作当中经常会遇到的问题,内存溢出有可能发生在正常的情况下,而非代码层面问题导致,比如高并发下,大量的请求占用内存,垃圾回收机制无法进行回收,而导致的内存溢出,这种情况就需要我们去调整架构了。一但出现内存溢出问题,我们需要快速定位并解决,尤其是生产环境,所以针对内存溢出问题,我们需要掌握一些常用的排查工具,针对不同场景、现象有快速排查思路。引起内存溢出的原因有很多种,常见的有以下几种:
● 内存中加载的数据量过于庞大,如一次从数据库取出过多数据;
● 资源使用之后没有及时关闭,导致对象无法被GC回收;
● 代码中存在死循环或循环产生过多重复的对象实体;
● 使用的第三方软件中的BUG;
● 启动参数内存值设定的过小;
排查辅助技术介绍
01
排查内存问题的常用命令:
● Jps:是java提供的一个显示当前所有java进程pid的命令

● Jstat 命令:查看堆内存各部分的使用量,加载类的数量以及GC的情况

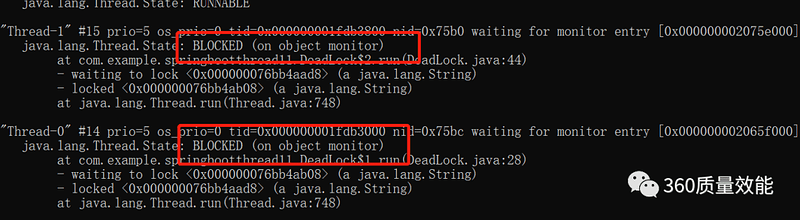
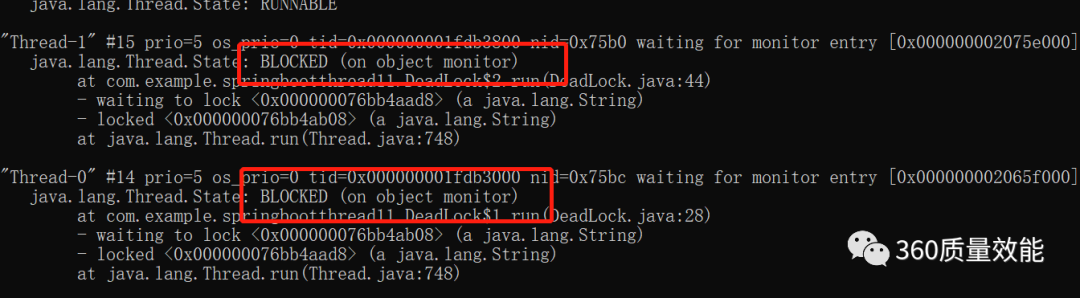
● Jstack命令:主要是用来查看java线程的堆栈信息,分析线程有没有死锁,比如下面的这个两个线程互相等待对方释放锁而产生的死锁信息
{kind=link}
● Jmap:主要是用来dump java进程内存快照的,便于我们去分析内存中对象的存储情况
02
内存文件分析工具:
● MemoryAnalyzer:这是一款Eclipse提供的内存分析工具,可以结合Eclipse使用,也可独立使用
● JProfiler,:这是由ej-technologies GmbH公司开发的一款内存分析工具,可以结合IDEA使用
● Jconsole:是一个用java写的GUI程序,用来监控VM,并可监控远程的VM
案例说明
正常情况下,我们生产环境都会配置监控措施,服务器资源比如CPU、内存的使用达到我们预设的报警阈值,就会触发报警,提示我们相应的维护人员,这时我们开发人员就需要快速定位原因,采取相应措施。下面结合我之前的一个例子来说下:
1.一天晚上19点30左右线上32服务器开始持续出现cpu占用率高的现象,最高已达到90%左右,同时伴随的其他现象还有内存占用率稍高,达到60%左右,因为当时监控配置的是机器的监控,并没有直接收到java服务内存溢出的报警,所以当时是从cpu异常开始排查。
2.收到报警后,第一感觉存在代码死循环,或者请求线程太多。但这个时间点请求量很少,也没有修改过代码。
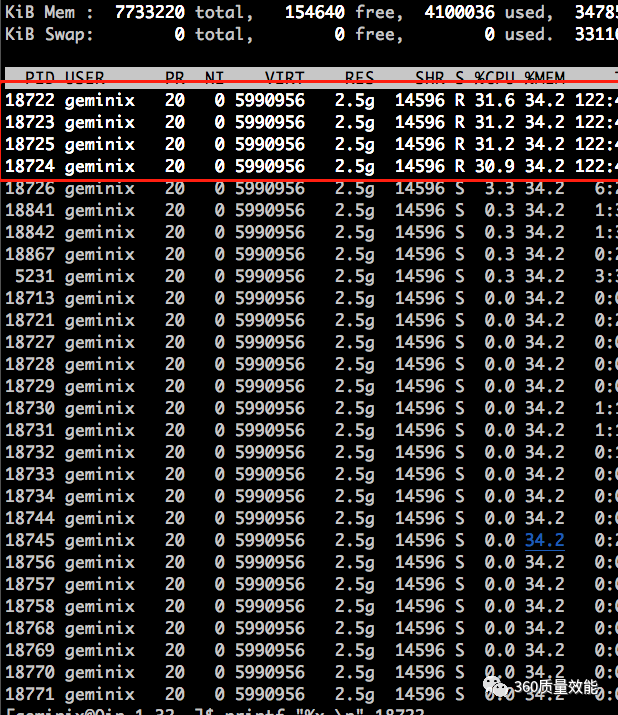
3.cpu占用率高基本和进程/线程有关,使用top查看一下cpu占用率高的进程,进程id是18713

18713正是系统的跑批服务器,查看日志发现19:30左右执行了上传文件到oss服务器的批量任务,查看日志发现在下午执行了20几次
4.使用top -H -p 18713查看cpu占用率高的线程,存在4个
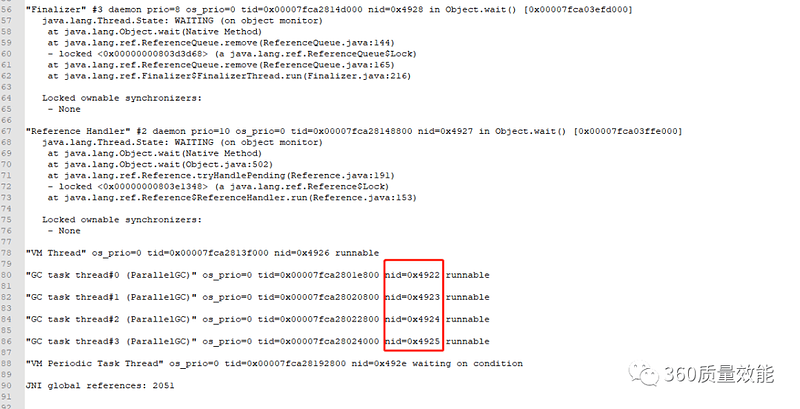
5.将这四个线程的线程id转换成16进制打印,分别是4922,4923,4924,4925

6.使用jstack -l 18713>> a.txt进行线程dump,如有必要可以多输出几次。根据上面4个线程的线程id在文件中查找,找到4条线程日志
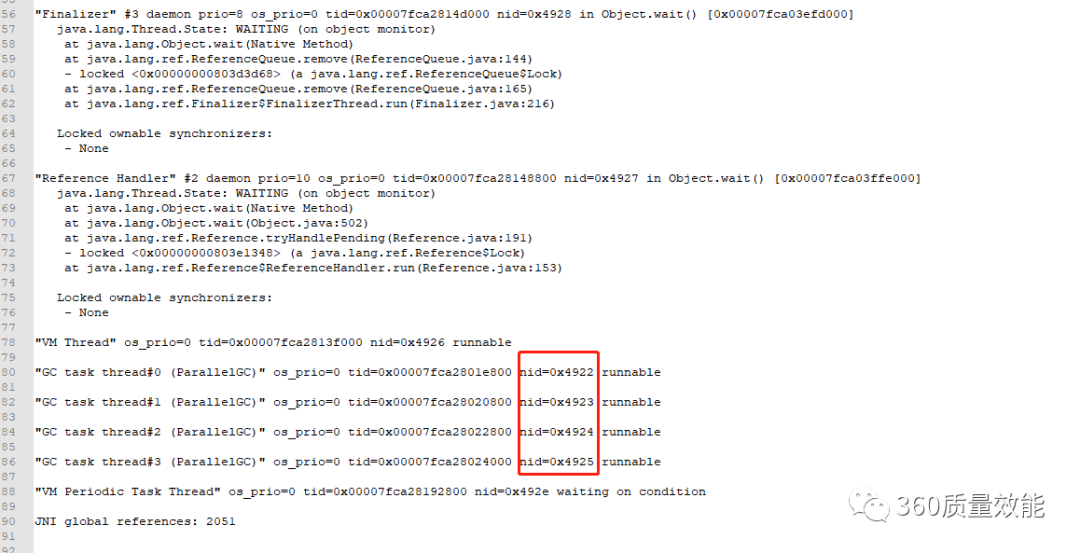{kind=link}
注意这四个线程是jvm垃圾回收线程,不是业务线程。
7.接着使用jstat -gc 18713 5000打印垃圾回收日志进行确认,发现jvm很短时间内进行了多次的fullgc操作
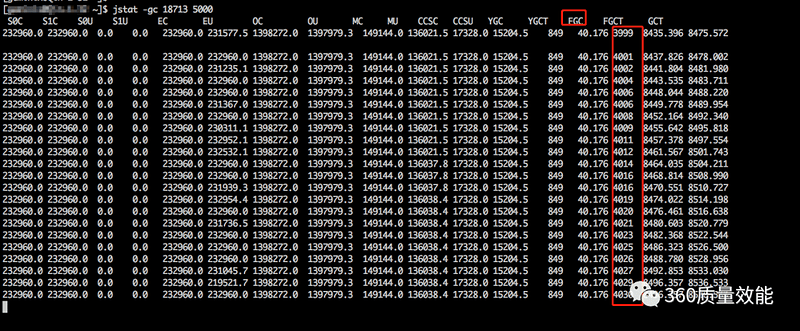
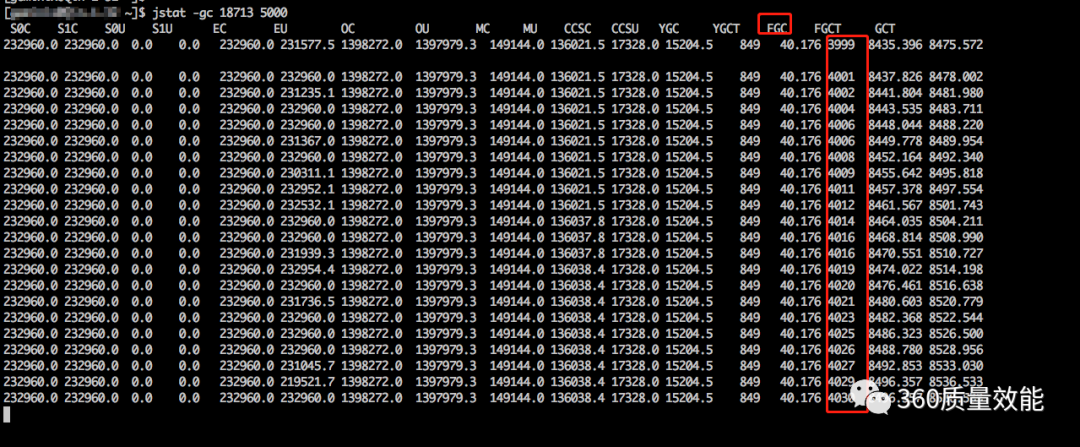{kind=link}
8.此时基本确定存在垃圾回收问题,只是还没有导致内存溢出,虽然线上配置了jvm溢出之后进行内存dump,但此时内存占用只有60%。

{kind=link}
9.只能使用jmap -dump:file=dump.hprof 18713强制进行一次内存dump。导出文件到本地目录,文件通常会很大。所以建议jvm堆内存上限不要设置的太大。否则内存分析工具分析也成问题。
- 下载MemoryAnalyzer内存分析工具,其他工具也可以。配置下MemoryAnalyzer.ini文件,将内存调的大一点,否则无法进行分析。

{kind=link}
- 导入dump文件,时间稍长,慢慢等待。导入后有各种详细的展示视图。比如大对象,数量多的对象,泄露猜测等。
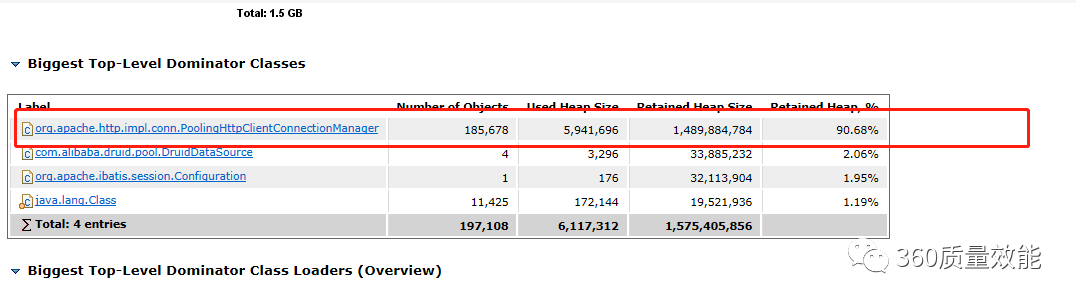
{kind=link}
- 发现占用内存90%多的是http连接对象,点击查询引用明细,发现是oss依赖库引用了大量http连接对象
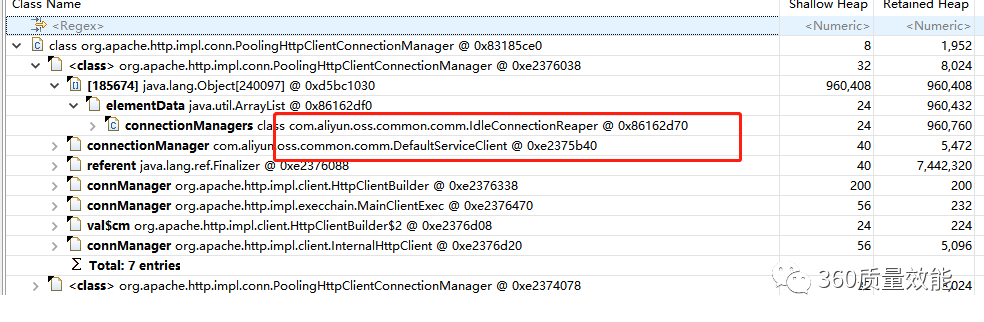
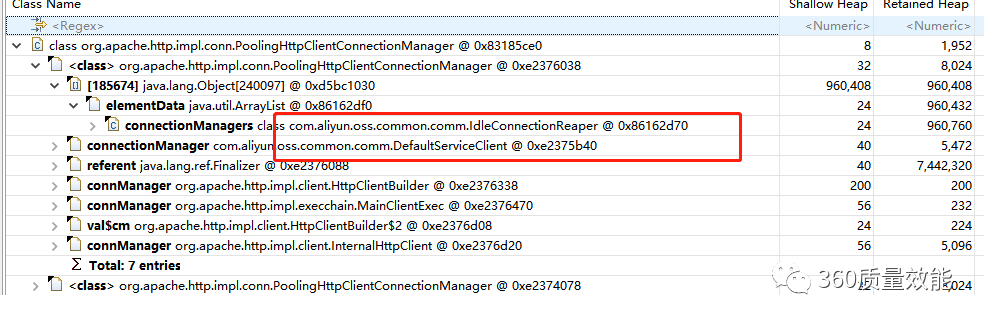{kind=link}
-
结合19:30左右的批量执行情况推断,这个批量存在内存泄露,使用后没有及时释放连接,造成内存占用率高,而垃圾回收在回收这部分内存的时候又造成了cpu占用率高。这次跑批的次数有点多。
-
排查代码发现果然如此:ossClient对象使用后没有关闭

{kind=link}
- 修复代码之后,再次重启跑批,发现问题也得到了解决。
总结
当然,分析和解决内存溢出相关问题的步骤,不是固定的,还需要根据实际情况去做调整,止损是第一位的,正常情况我们需要快速重启的先,重启可以使服务快速恢复,但是只重启,指标不治本,如果没有定位到溢出的原因,重启一段时间可能又会溢出。所以一定要留存排查依据,比如内存文件,线程的文件等。留存内存文件有两种方式:一是配置jvm启动参数: -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=xxxx(文件导出路径),JVM发生OOM时,自动生成dump文件;二是采用jmap命令,手动进行内存dump。
相关文章
- Tomcat中JVM内存溢出及合理配置
- JVM 内存模型概述
- 【转】JVM内存结构 VS Java内存模型 VS Java对象模型
- [转]Tomcat 内存溢出 "OutOfMemoryError" 问题总结 (JVM参数说明)
- JVM内存分析
- JVM调优
- JVM GC日志(一)
- JVM内存模型和结构
- 【jvm系列-06】深入理解对象的实例化、内存布局和访问定位
- JVM 面试题,安排上了!!!
- jvm(三)指令重排 & 内存屏障 & 可见性 & volatile & happen before
- 深入理解Java虚拟机:JVM高级特性与最佳实践
- 深入理解JVM虚拟机读书笔记——内存模型与线程
- 深入理解JVM虚拟机读书笔记——垃圾回收算法
- JVM_11 类加载与字节码技术 (类加载与类的加载器)
- JVM最多能创建多少个线程: unable to create new native thread
- JVM内存区域划分
- windows下配置tomcat服务器的jvm内存大小的两种方式
- version 1.5.2-04 of the jvm is not suitable for this product. version:1.6 or greater is required
- JVM学习笔记(一)------基本结构
- 【JVM译文】JVM问题定位前的准备工作有哪些
- JVM的内存分配策略。。。
- 深入理解JVM类加载机制