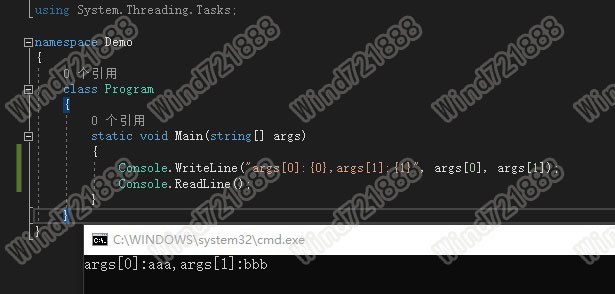
什么是进程线程:我们来看一下自己的任务管理器
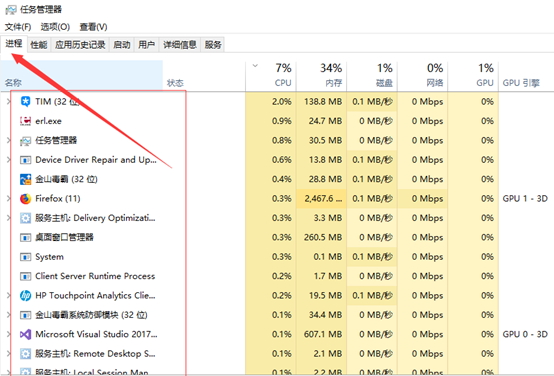
这里的每一项都是一个进程,我们的发布的每一个应用程序都需要一个进程去运行,在一个进程内可以有多个线程去计算执行程序。我们看下面的图片:
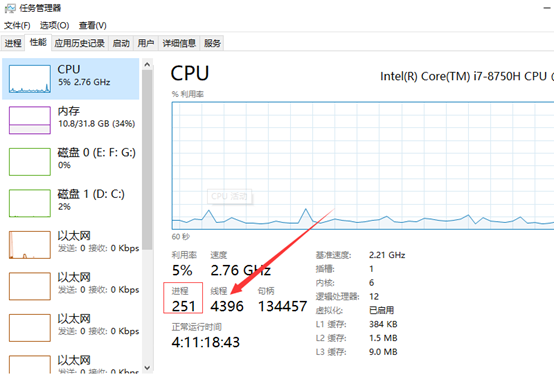
我们可以看一下进程和线程的数量,很明显可以看出,线程和进程的关系。我们的每一个操作都需要一个线程来执行,鼠标的点击就需要线程去响应我们的操作。
现在我们不难理解,我们一个应用程序就代表一个进程,想让我们的程序高效的运行我们就可以启用多个线程去执行了,当然采用多线程的话有好处也是有代价的,好处合理的利用计资源了,但是线程过多了,你的CPU利用率就加大了,也有可能导致电脑的卡死。
在我们的程序中线程的代表就是:Thread本篇文章我们就说一下线程。我们先了解一下同步异步。
同步:指的是在同一线程下执行,并且会等待结果执行完毕。
异步:不再同一个线程下执行,并且执行得顺序不可控,不会等待执行结果完毕。
我们先用委托来演示一下多线程,如果不怎么了解委托得可以看一下上一篇文章:
DelegateMethod Method = () =>
{
Console.WriteLine($"我的线程ID是:{Thread.CurrentThread.ManagedThreadId}");
};
Method.BeginInvoke(null, null);
Method.Invoke();
本来想用上面的代码去先简单的演示一下,谁知道NetCore 的程序集提供了,但是平台目前还不支持。 我们可以私下使用NET 试一下。

使用Thread 演示
Console.WriteLine($"*********************************我是同步方法 *******************************");
for (int i = 0; i < 10; i++)
{
Console.WriteLine($"我的线程ID是:{Thread.CurrentThread.ManagedThreadId}");
}
Console.WriteLine($"*********************************同步方法结束 *******************************");
Console.WriteLine($"*********************************我是异步方法 *******************************");
for (int i = 0; i < 10; i++)
{
Thread thread = new Thread(() => { Console.WriteLine($"我的线程ID是:{Thread.CurrentThread.ManagedThreadId}"); });
thread.Start();
}
Console.WriteLine($"*********************************异步方法结束 *******************************");
Console.ReadKey();
执行结果:

上面的代码执行结果中我们可以看到:同步方法 是同一个线程来执行的,之上而下有序的执行,但是异步方法启动了多个线程去执行的,并且线程是无序的。看到这样的情况我们就会知道如果我启动了很多线程线程用完之后也是有回收的,回收之后同样会分配的,也就是说同一个操作中线程的ID 可能会多次出现的。
Console.WriteLine($"*********************************异步启动线程数量计算 *******************************");
List<int> ListInt = new List<int>();
int Conut = 0;
for (int i = 0; i < 2000; i++)
{
Thread thread = new Thread(() =>
{
if (ListInt.Contains(Thread.CurrentThread.ManagedThreadId))
{
Conut++;
Console.WriteLine($"我的重复的线程我的 ID是:{Thread.CurrentThread.ManagedThreadId} 重复线程总数量:{Conut}");
}
ListInt.Add(Thread.CurrentThread.ManagedThreadId);
});
thread.Start();
}
Console.WriteLine($"*********************************异步启动线程数量计算结果:{ListInt.Count} *******************************");
结果:

上面的结果我们可以看到:线程回收再利用。其实thread线程的回收就是我们的GC来做的,这就是C# 的强大之处,自动帮助我们回收了。需要注意的是这样使用线程我们的回收过程是比较慢的,这个回收速度是我们计算机性能决定的。
在上面的结果中我们可以看到我们总共申请了1996个线程,其中有881个线程是重复的,线程的申请和销毁是耗费很多性能的,接下来我们看一下线程池。
线程thread有哪些可操作的属性
|
CurrentContext
|
获取线程正在其中执行的当前上下文。
|
|
CurrentCulture
|
获取或设置当前线程的区域性。
|
|
CurrentPrinciple
|
获取或设置线程的当前负责人(对基于角色的安全性而言)。
|
|
CurrentThread
|
获取当前正在运行的线程。
|
|
CurrentUICulture
|
获取或设置资源管理器使用的当前区域性以便在运行时查找区域性特定的资源。
|
|
ExecutionContext
|
获取一个 ExecutionContext 对象,该对象包含有关当前线程的各种上下文的信息。
|
|
IsAlive
|
获取一个值,该值指示当前线程的执行状态。
|
|
IsBackground
|
获取或设置一个值,该值指示某个线程是否为后台线程。
|
|
IsThreadPoolThread
|
获取一个值,该值指示线程是否属于托管线程池。
|
|
ManagedThreadId
|
获取当前托管线程的唯一标识符。
|
|
Name
|
获取或设置线程的名称。
|
|
Priority
|
获取或设置一个值,该值指示线程的调度优先级。
|
|
ThreadState
|
获取一个值,该值包含当前线程的状态。
|
线程池:ThreadPool
ThreadPool:线程池中的线程都是后台线程IsBackground属性都是True.不会影响所有的前台线程,也就是说不会影响用户体验。每个线程都有默认的堆栈大小和优先级,位于多线程池中。 一旦线程池中的线程完成任务,它将返回到等待线程队列中,这时我们就可以利用这些闲置的线程。通过这种重复使用,应用程序可以避免产生为每个任务创建新线程的开销。在每一个进程中都只会有一个线程池
//public static bool SetMaxThreads(int workerThreads, int completionPortThreads);
//public static bool SetMinThreads(int workerThreads, int completionPortThreads);
//workerThreads 工作线程数量 completionPortThreads I/O线程数量
ThreadPool.SetMaxThreads(12,12);
ThreadPool.SetMinThreads(12, 12);
我这里设置工作线程,I/O线程数量来源于我得计算机核心数量,保持每个核心最大最小线程都启动一个。查看计算机处理器核心数量。
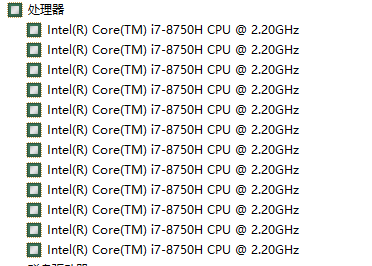
上面的设置是说我在线程池中给准备了数量为12 的线程。你可以申请最多12个线程,在使用完之后我会立马进行自动的回收,回收之后的线程继续存放在线程池中等待使用。相比于 Thread线程池ThreadPool对于线程的回收更快,性能更好。
代码看一下性能:
Stopwatch stopwatch = new Stopwatch();
stopwatch.Start();
for (int i = 0; i < 1000; i++)
{
Thread thread = new Thread(() =>
{
Console.WriteLine($"*********************************我是多线程Thread方法 *******************************");
});
thread.Start();
}
Console.WriteLine($"*********************************Thread方法结束 耗费时间 :{stopwatch.ElapsedMilliseconds} *******************************");
Console.WriteLine($"*********************************多线程ThreadPool启动 *******************************");
Stopwatch stopwatch1 = new Stopwatch();
stopwatch1.Start();
for (int i = 0; i < 1000; i++)
{
WaitCallback act = (t) =>
{
Console.WriteLine($"*********************************我是多线程ThreadPool方法 *******************************");
};
ThreadPool.QueueUserWorkItem(act);
}
Console.WriteLine($"*********************************ThreadPool方法结束 耗费时间 :{stopwatch1.ElapsedMilliseconds} *******************************");
结果:Thread

结果:ThreadPool

上面的两个方法我们都只是输出一行字符,但是以1000次的来说看一下性能相差有多少。所以建议大家都使用线程池。
推荐官方文档:https://docs.microsoft.com/zh-cn/dotnet/standard/threading/?view=netframework-4.7.2
线程池:Task
随着框架的发展我们有了Task 他也是基于ThreadPool来重新封装的。他的出现方便了我们对多线程的回调等待更好的操作。
推荐一篇博客:https://www.cnblogs.com/lonelyxmas/p/9509298.html
并行计算的多线程 Parallel
Parallel 多线程,这个类似同步的,他是在Task的基础之上又一次的封装。假如说我们启动多个线程,她像其他的一样启动了很多的子线程去执行的,而是和当前线程一样并行去执行的。并且当前线程也参与执行。他会卡住线程,等到全部执行完毕后才会继续
这个操作上不如Task 灵活,比如Task 可以等待其中一个线程执行完成后继续主线程,Parallel 是必须等待全部执行完毕。
Parallel里面大致分为三个方法: For,ForEach,Invoke
Invoke:
Console.WriteLine($"*********************************我是主线程线程 ID:{Thread.CurrentThread.ManagedThreadId} *******************************");
Action act = () => {
Console.WriteLine($"我的线程ID是:{Thread.CurrentThread.ManagedThreadId}");
};
Parallel.Invoke(act, act, act, act, act);
结果:
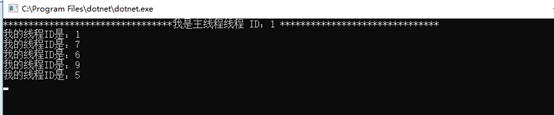
上面结果中我们可以看到主线程参与了进来。
ForEach:
List<int> vs = new List<int>() { 1, 2, 3, 4, 5 };
Parallel.ForEach<int>(vs, t =>
{
Console.WriteLine($"*********************************我是 {t} *******************************");
});
结果:

For
List<int> vs = new List<int>() { 1, 2, 3, 4, 5 };
//从零开始 循环多少次
Parallel.For(0, vs.Count,t=> {
Console.WriteLine($"*********************************我是 {t} *******************************");
});
结果:

上面的代码中我们可以看到Parallel 适合在我们循环的时候去使用这样并行的去执行,我们可以减少程序的执行时间。
如果当我们需要执行的集合过大有可能会 并行很多线程时我们怕会影响我们计算机的I/O 我们还可以设置最大的并行数防止程序执行时i/o风暴
//设置 Parallel 最大并行线程的数量
ParallelOptions options = new ParallelOptions();
//最大并行数为10;
options.MaxDegreeOfParallelism = 10;
Parallel 官方介绍:https://docs.microsoft.com/zh-cn/dotnet/api/system.threading.tasks.parallel?redirectedfrom=MSDN&view=netframework-4.7.2
获取当前计算机 最大线程数
int workerThreads;
int completionPortThreads;
ThreadPool.GetMaxThreads( out workerThreads, out completionPortThreads);
Console.WriteLine($"最大工作线程:{workerThreads} 最大I/O线程:{completionPortThreads} ");
ThreadPool.GetMinThreads(out workerThreads, out completionPortThreads);
Console.WriteLine($"最小工作线程:{workerThreads} 最小 I/O线程:{completionPortThreads} ");
结果:

有不足之处 希望大家指出相互学习,
转载请注明出处 谢谢!
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
/// <summary>
/// 递归一个List<ProvinceOrg>
/// </summary>
/// <returns></returns>
public void RecursionProvinceOrgs(List<ProvinceOrg> provinceOrgs, ref List<ProvinceOrg> _provinceOrgs)
{
if (provinceOrgs != null && provinceOrgs.Count() > 0)
{
var _provinceOrgs_ = provinceOrgs.Where(p => p.children.Count() == 0);
if (_provinceOrgs_.Count() > 0)
{
_provinceOrgs.AddRange(_provinceOrgs_);
}
var _provinceOrgs_Surplus = provinceOrgs.Where(p => p.children.Count() > 0);
foreach (ProvinceOrg provinceOrg in _provinceOrgs_Surplus)
{
ProvinceOrg provinceOrgClone = provinceOrg.Clone();
_provinceOrgs.Add(provinceOrgClone);
RecursionProvinceOrgs(provinceOrg.children, ref _provinceOrgs);
}
}
}
|
实体类:
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
public class ProvinceOrg : ICloneable
{
public int orgId { get; set; }
public int parentOrgId { get; set; }
public int areaId { get; set; }
public string areaCode { get; set; }
public string orgName { get; set; }
public string fullOrgName { get; set; }
public string orgType { get; set; }
public string state { get; set; }
public string orgCode { get; set; }
public int seq { get; set; }
public string isBusDep { get; set; }
public string depCateCode { get; set; }
public string legalPerson { get; set; }
public string contacts { get; set; }
public string phone { get; set; }
public string address { get; set; }
public string orgFunctions { get; set; }
public int num;
public List<ProvinceOrg> children { get; set; }
/// <summary>
/// 克隆并返回一个对象。
/// </summary>
/// <returns></returns>
public ProvinceOrg Clone()
{
ProvinceOrg p = (ProvinceOrg)this.MemberwiseClone();
p.children = new List<ProvinceOrg>();
return p;
}
object ICloneable.Clone()
{
return this.Clone();
}
}
|
转自:https://blog.csdn.net/jie_liang/article/details/77340905
用以记录:
在sql查询中为了提高查询效率,我们常常会采取一些措施对查询语句进行sql优化,下面总结的一些方法,有需要的可以参考参考。
1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 order by 涉及的列上建立索引。
2.应尽量避免在 where 子句中对字段进行 null 值判断,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num is null
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num=0
3.应尽量避免在 where 子句中使用!=或<>操作符,否则将引擎放弃使用索引而进行全表扫描。
4.应尽量避免在 where 子句中使用 or 来连接条件,否则将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or num=20
可以这样查询:
select id from t where num=10
union all
select id from t where num=20
5.in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)
对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3
6.下面的查询也将导致全表扫描:
select id from t where name like '%abc%'
7.应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2=100
应改为:
select id from t where num=100*2
8.应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3)='abc'--name以abc开头的id
应改为:
select id from t where name like 'abc%'
9.不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
10.在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,
否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
11.不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0
这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(...)
12.很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)
用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)
13.并不是所有索引对查询都有效,SQL是根据表中数据来进行查询优化的,当索引列有大量数据重复时,SQL查询可能不会去利用索引,
如一表中有字段sex,male、female几乎各一半,那么即使在sex上建了索引也对查询效率起不了作用。
14.索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,
因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。
一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有必要。
15.尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。
这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
16.尽可能的使用 varchar 代替 char ,因为首先变长字段存储空间小,可以节省存储空间,
其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
17.任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
18.避免频繁创建和删除临时表,以减少系统表资源的消耗。
19.临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件,最好使用导出表。
20.在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,
以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
21.如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
22.尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
23.使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
24.与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。
在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
25.尽量避免大事务操作,提高系统并发能力。26.尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。