作者:13
GitHub:https://github.com/ZHENFENG13
版权声明:本文为原创文章,未经允许不得转载。
此篇已收录至《大型网站技术架构:核心原理与案例分析》读书笔记系列,点击访问该目录获取完整内容。
前言
所谓架构,一种通俗的说法就是“最高层次的规划,难以改变的决定”,这些规划和决定奠定了事物未来发展的方向和最终的蓝图。
而软件架构即“有关软件整体结构与组件的抽象描述,用于指导大型软件系统各方面的设计”。
一般来说软件架构需要关注性能、可用性、伸缩性、扩展性和安全性这5个架构要素。

性能
性能是网站架构设计的一个重要方面,任何软件架构设计方案都必须考虑可能带来的性能问题,也正因为性能问题几乎无处不在,所以优化网站性能的手段也非常多。
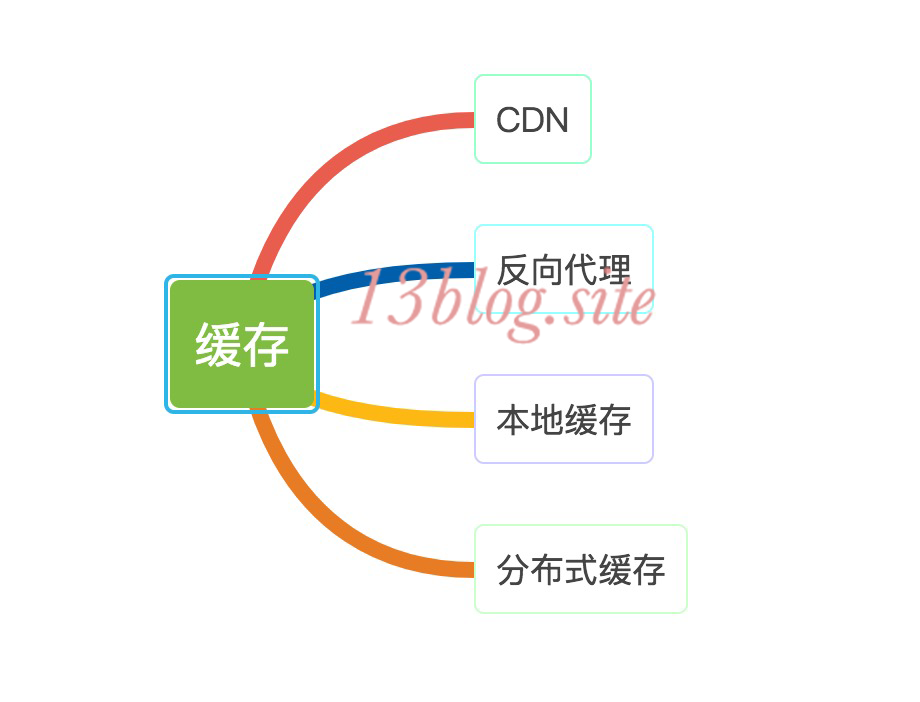
- 浏览器端:可以通过浏览器缓存、页面压缩传输、合理布局页面、减少Cookie传输等手段,甚至可以使用CDN加速功能。
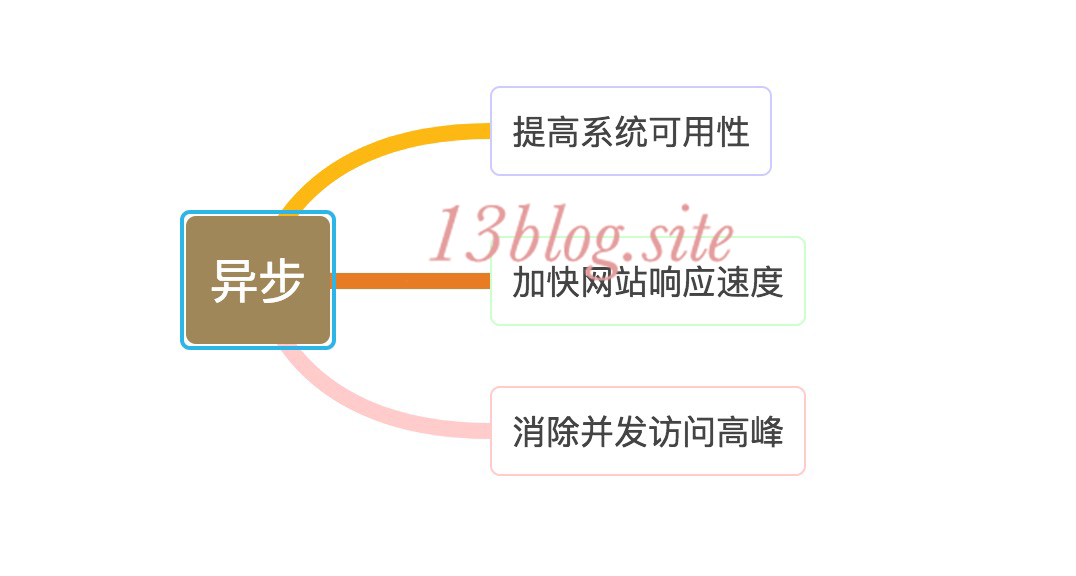
- 应用服务器端:可以使用服务器本地缓存和分布式缓存,也可以通过异步操作方式来加快响应,在高并发请求的情况下,可以将多台应用服务器组成一个集群共同对外服务,提高整体处理能力,改善性能。
- 数据库服务器端:可用使用索引、缓存、SQL性能优化等手段,还可以使用NoSQL数据库来优化数据模型、存储结构等。
衡量网站性能有一系列指标,重要的有响应时间、TPS、系统性能计数器等,通过这些指标以确定系统设计是否达到目标。

可用性
可用性即能够不间断提供服务的时间。几乎所有网站都承诺7×24小时可用,但事实上任何网站都不可能达到完全的7×24,总会有一些故障时间,扣除这些故障时间,就是网站的可用时间。一些大型网站可以做到4个9以上的可用性,也就是99.99%。
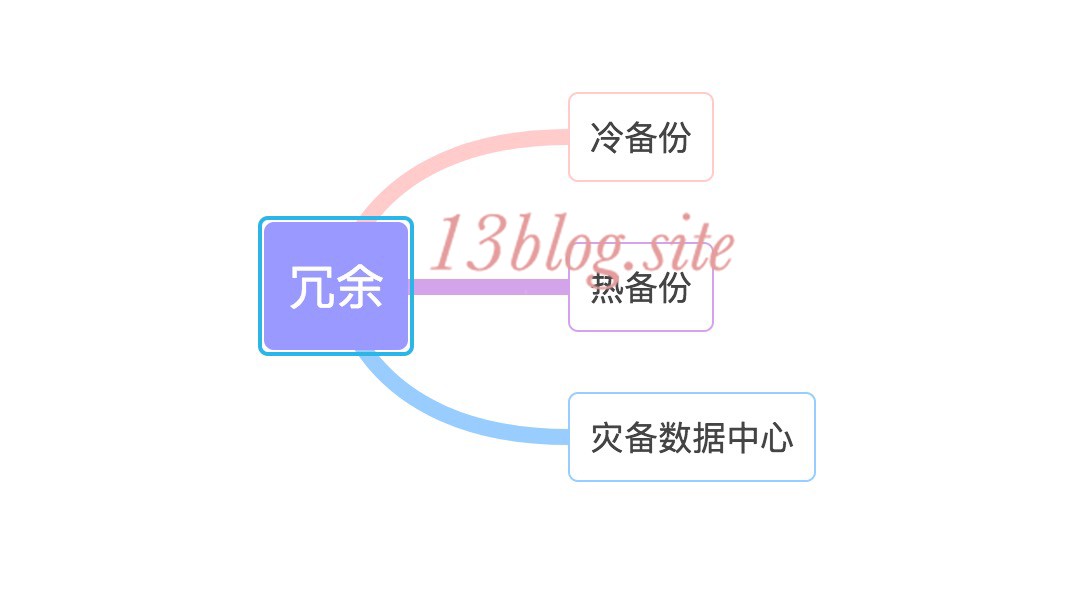
网站高可用的主要手段就是冗余,应用部署在多台服务器上同时提供服务,数据存储在多台服务器上相互备份,任何一台服务器都不会影响应用的整体可以,通常的实现手段即把多台服务器通过负载均衡设备组成一个集群。
衡量一个系统架构设计是否满足高可用的目标,就是假设系统中任何一台或者多台服务器宕机时,以及出现各种不可预期的问题时,系统整体是否依然可用。

伸缩性
大型网站需要面对大量用户的高并发访问和存储海量数据,网站通过集群的方式将多台服务器组成一个整体共同提供服务。所谓伸缩性是指通过不断向集群中加入服务器的手段来缓解不断整体上市用户并发访问压力和不断增长的数据存储需求。
衡量架构伸缩性的主要标准就是是否可用多台服务器构建集群,是否容易向集群中添加新的服务器。加入新的服务器后是否可以提供和原来的服务器无差别的服务。集群中可容纳的总服务器数量是否有限制。

扩展性
不同于其他架构要素主要关注非功能性需求,网站的扩展性架构直接关注网站的功能需求。网站快速发展,功能不断扩展,如何设计网站的架构使其能够快速响应需求变化,是网站可扩展架构的主要目标。
衡量网站架构扩展性好坏的主要标准就是在网站增加新的业务产品时,是否可以实现对现有产品透明无影响,不同产品之间是否很少耦合等。
网站可扩展架构的主要手段是事件驱动架构和分布式服务。
- 事件驱动通常利用消息队列实现,通过这种方式将消息生产和处理逻辑分隔开。
- 服务器服务则是将业务和可复用服务分离开来,通过分布式服务框架调用。新增加产品可用通过调用可复用的服务来实现自身的业务逻辑,而对现有产品没有任何影响。

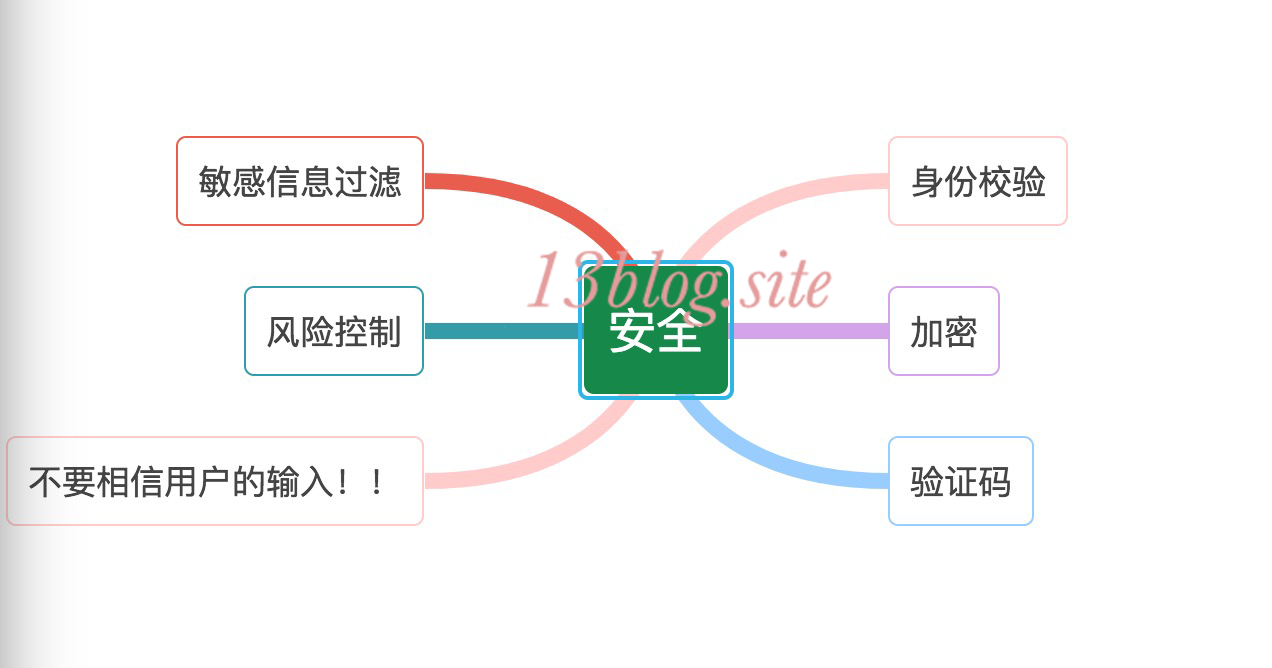
安全性
互联网是开发的,任何人在任何地方都可以访问网站。网站的安全架构就是保护网站不受恶意访问和攻击,保护网站的重要数据不被窃取。
衡量网站安全架构的标准就是针对现存和潜在的各种攻击和窃密手段,是否有可靠的应对策略。

这个世界没有绝对的安全,正如没有绝对的自由一样,很遗憾,这个世界上没有固若金汤的网站安全架构,我们只能每天打起百分百的精神,预防可能的漏洞或者攻击。
首发于我的个人博客,2017年5月18日。