
Pandas数据处理|筛选与兼职打卡时间差异在一分钟内的全职打卡数据
2023-09-11 14:14:31 时间
需求与背景
某公司旗下有很多便利店,但近期却发现个别门店存在全职帮兼职打卡的情况,为此总部领导决定对所有门店的打卡时间数据进行分析,将每一个门店,全职人员和兼职人员上班卡、下班卡其中之一相差1分钟以内的数据找出来,然后再具体调查。
下面我们的任务就是以兼职人员数据为基准,找出相同门店下全职人员上班卡、下班卡其中之一相差1分钟以内的数据:
解决需求
首先读取数据(已脱敏):
import pandas as pd
excel = pd.ExcelFile("全职与兼职相差一分钟.xlsx")
df_fulltime = excel.parse("全职")
df_parttime = excel.parse("兼职")
display(df_fulltime.head())
print(df_fulltime.shape)
display(df_parttime.head())
print(df_parttime.shape)

由于两张表的数据列名一致,我们可以将两张表拼接起来,方便分组:
df_fulltime["类型"] = "全职"
df_parttime["类型"] = "兼职"
df = pd.concat([df_fulltime, df_parttime], ignore_index=True)
df
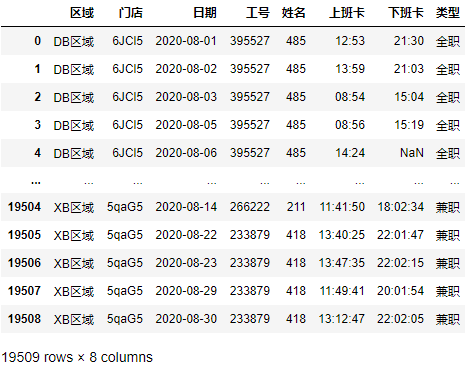
测试分组和拆分:
for (area, store, time), df_split in df.groupby(["区域", "门店", "日期"]):
print(area, store, time)
df_fulltime_split = df_split.query("类型=='全职'")
df_parttime_split = df_split.query("类型=='兼职'")
display(df_fulltime_split)
display(df_parttime_split)
break
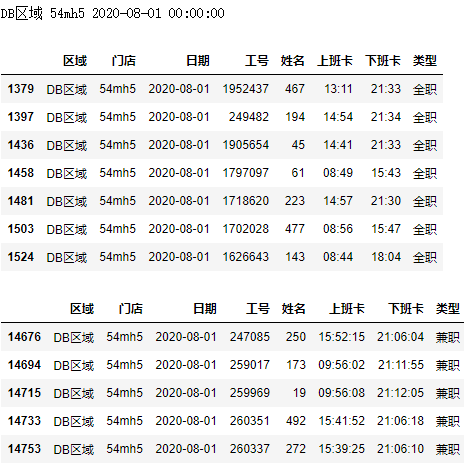
不过上述数据并没有能够匹配的数据,我们选个有结果的分组进行测试:
g = df.groupby(["区域", "门店", "日期"])
df_split = g.get_group(("DB区域", "54mh5", "2020-08-04"))
df_fulltime_split = df_split.query("类型=='全职'")
df_parttime_split = df_split.query("类型=='兼职'")
display(df_fulltime_split)
display(df_parttime_split)
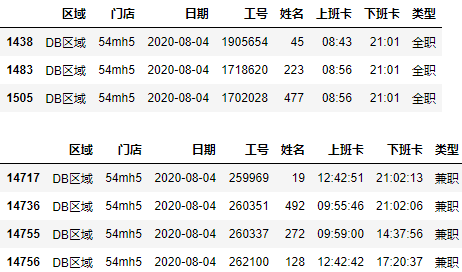
为了方便计算,获取上下班时间的分钟数:
def func(time_str):
if not isinstance(time_str, str):
return 0
time_arr = time_str.split(":")
return int(time_arr[0])*60+int(time_arr[1])
df_fulltime_time = df_fulltime_split[["上班卡", "下班卡"]].applymap(func)
df_parttime_time = df_parttime_split[["上班卡", "下班卡"]].applymap(func)
display(df_fulltime_time)
display(df_parttime_time)

测试数据筛选:
for (time1, time2), row in zip(df_parttime_time.values, df_parttime_split.values[:, :-1]):
print(time1, time2)
print(row)
idx = df_fulltime_time.query(
f"{time1-1}<=上班卡<={time1+1} or {time2-1}<=下班卡<={time2+1}").index
display(df_fulltime_split.loc[idx])
break
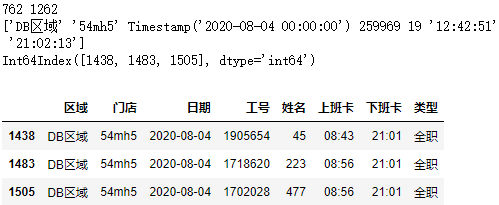
测试数据整理:
result = []
data = df_fulltime_split.loc[idx].values[:, 3:-1]
row = row.tolist()
row.extend(data)
result.append(row)
result = pd.DataFrame(result)
result.rename(columns=dict(
enumerate(["区域", "门店", "日期", "工号", "姓名", "上班卡", "下班卡"])), inplace=True)
result.rename(columns=lambda x: x if isinstance(
x, str) else f"全职打卡{x-1}", inplace=True)
result
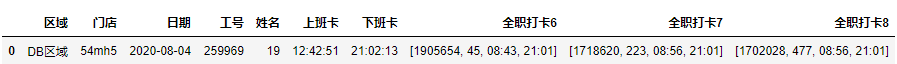
整理一下完整代码:
完整代码
import pandas as pd
excel = pd.ExcelFile("全职与兼职相差一分钟.xlsx")
df_fulltime = excel.parse("全职")
df_parttime = excel.parse("兼职")
df_fulltime["类型"] = "全职"
df_parttime["类型"] = "兼职"
df = pd.concat([df_fulltime, df_parttime], ignore_index=True)
def func(time_str):
if not isinstance(time_str, str):
return 0
time_arr = time_str.split(":")
return int(time_arr[0])*60+int(time_arr[1])
result = []
for (area, store, time), df_split in df.groupby(["区域", "门店", "日期"]):
df_fulltime_split = df_split.query("类型=='全职'")
df_parttime_split = df_split.query("类型=='兼职'")
df_fulltime_time = df_fulltime_split[["上班卡", "下班卡"]].applymap(func)
df_parttime_time = df_parttime_split[["上班卡", "下班卡"]].applymap(func)
for (time1, time2), row in zip(df_parttime_time.values, df_parttime_split.values[:, :-1]):
idx = df_fulltime_time.query(
f"{time1-1}<=上班卡<={time1+1} or {time2-1}<=下班卡<={time2+1}").index
if len(idx) > 0:
data = df_fulltime_split.loc[idx].values[:, 3:-1]
row = row.tolist()
row.extend(data)
result.append(row)
result = pd.DataFrame(result)
result.rename(columns=dict(
enumerate(["区域", "门店", "日期", "工号", "姓名", "上班卡", "下班卡"])), inplace=True)
result.rename(columns=lambda x: x if isinstance(
x, str) else f"全职打卡{x-1}", inplace=True)
result
最终结果:
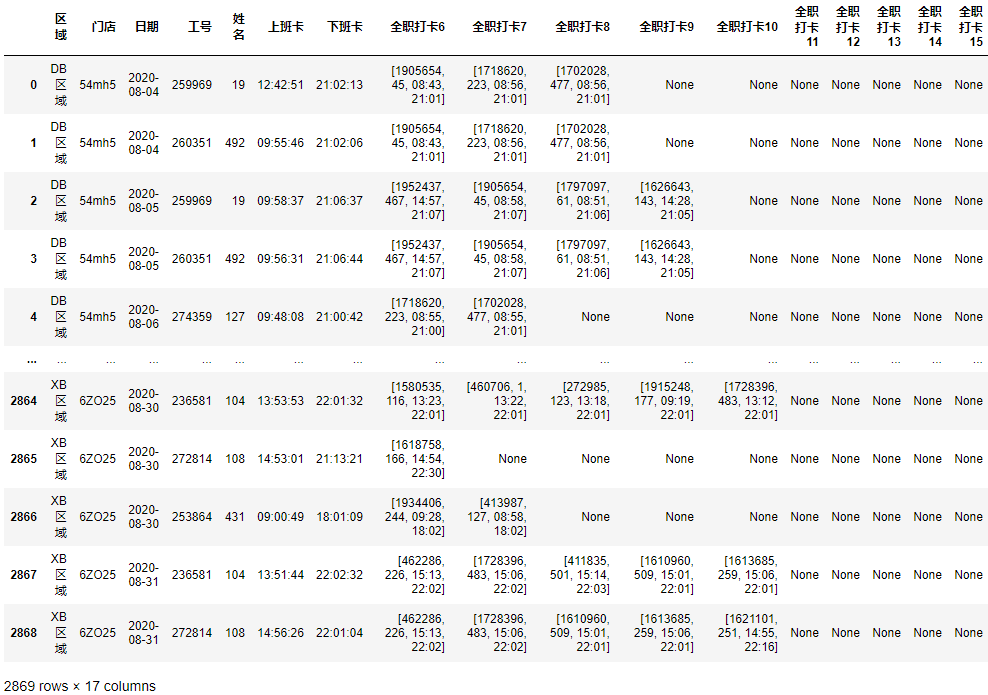
相关文章
- pandas常用数据清洗方法
- 如何使用pandas分析金融数据
- pandas 左右边界切割 用merge join和concat合并Pandas中的数据
- pandas用法总结
- 小白学 Python 数据分析(11):Pandas (十)数据分组
- 用Python的pandas框架操作Excel文件中的数据教程
- Python之pandas:对dataframe数据的时间日期格式类型字段进行标准化变换(比如将日期类型字段格式2014/1/1转换为2014-1-1)之详细攻略
- ML之FE:pandas库中数据分析利器之groupby分组函数、agg聚合函数、同时使用groupby与agg函数组合案例之详细攻略
- Python之pandas:对dataframe数据的时间日期格式类型字段进行标准化变换(比如将日期类型字段格式2014/1/1转换为2014-1-1)之详细攻略
- 100天精通Python(数据分析篇)——第54天:Pandas之Series对象基础大总结
- 已解决pandas.errors.InvalidIndexError: Reindexing only valid with uniquely valued Index objects
- 【阶段二】Python数据分析Pandas工具使用03篇:数据预处理:多表合并与连接
- python pandas使用数据透视表
- Python数据科学pandas终极指南【看这篇文章就够了】
- 数据分析工具Pandas基础--DataFrame的索引操作
- Python可视化数据分析08、Pandas_Excel文件读写
- pandas库(Python)
- 上手Pandas,带你玩转数据(5)-- 数据转换与数据定位