
c#的三个高级参数ref out 和Params
前言:在我们学习c#基础的时候,我们会学习到c#的三个高级的参数,分别是out .ref 和Params,在这里我们来分别的讲解一下,在这里的我们先不做具体的解释,我会通过几个例子来做分别的解释。
一:out参数
1.首先我先给大家一个题:我们来写一个方法,来求一个数组中的最大值,最小值,总和,平均值。代码如下:
int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
通过分析我们会发现如果我们写一个方法的时候,当我们需要返回值的时候,我们只能返回一个值,这个时候我们需要求最大值,最小值,总和和平均值。我们该如何的写呢??假如我们没有学习过out参数,这时候我们可以考虑返回一个数组,并且分别的假定数组中的元素的最大值,最小值,总和。(当总和求出来之后,平均值也就出来了)。详细的代如下:

//我们声明一个长度为4的数组,假设 res[0] 最大值 res[1]最小值 res[2]总和 res[3]平均值
int[] res = new int[4];
//假定数组中的第一个元素为最大值
res[0] = nums[0];//max
//假定数组中的第二个元素为最小值
res[1] = nums[0];//min
//假定数组中的第三个元素为总和
res[2] = 0;//sum
注:num[0]:这只是我们假定的值。
2.这时候我们需要遍历for循环,如果当前循环到的元素比我的最大值还要大,就把当前的元素赋值给我的最大值,如果当前循环到的元素比我的最小值还要小,就把当前的元素赋值给我的最小值,总和就是所有的元素相加,平均值为总和/数组的长度。详细的代码如下:
for (int i = 0; i < nums.Length; i++)
{
//如果当前循环到的元素比我假定的最大值还大
if (nums[i] > res[0])
{
//将当前循环到的元素赋值给我的最大值
res[0] = nums[i];
}
//如果当前循环到的元素比我的最小值还要小
if (nums[i] < res[1])
{
//就把当前的元素赋值给我的最小值
res[1] = nums[i];
}
//总和
res[2] += nums[i];
}
3.这时候直接返回数组就行了,完整的代码如下:
1 /// <summary>
2 /// 计算一个数组的最大值、最小值、总和、平均值
3 /// </summary>
4 /// <param name="nums"></param>
5 /// <returns></returns>
6 public static int[] GetMaxMinSumAvg(int[] nums)
7 {
8 //我们声明一个长度为4的数组,假设 res[0] 最大值 res[1]最小值 res[2]总和 res[3]平均值
9 int[] res = new int[4];
10 //假定数组中的第一个元素为最大值
11 res[0] = nums[0];//max
12 //假定数组中的第二个元素为最小值
13 res[1] = nums[0];//min
14 //假定数组中的第三个元素为总和
15 res[2] = 0;//sum
16 for (int i = 0; i < nums.Length; i++)
17 {
18 //如果当前循环到的元素比我假定的最大值还大
19 if (nums[i] > res[0])
20 {
21 //将当前循环到的元素赋值给我的最大值
22 res[0] = nums[i];
23 }
24 //如果当前循环到的元素比我的最小值还要小
25 if (nums[i] < res[1])
26 {
27 //就把当前的元素赋值给我的最小值
28 res[1] = nums[i];
29 }
30 //总和
31 res[2] += nums[i];
32 }
33 //平均值
34 res[3] = res[2] / nums.Length;
35 return res;
36 }
4.接下来就是在Main方法的中调用,截图如下: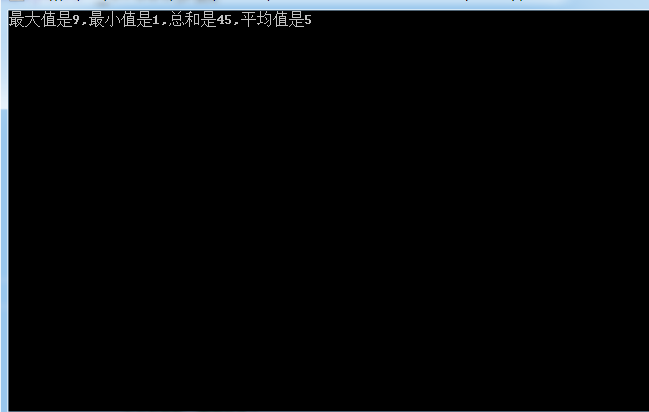
5.这时候我们需要考虑一个问题,我想要在数组中返回bool类型的值或者返回string类型的值,这时候我们怎么办呢??这时候需要我们的out参数登场了,out参数就侧重于在一个方法中返回多个不同类型的值,但是它有一个重要的特点是:必须在方法的内部为其赋值。
(1).在我们需要返回的值的前面加out关键字。
(2).当我们在Main方法中调用我们的方法的时候,首先需要先声明变量。
解题的思路跟上面的一样这里就不做过多的解释了,直接完整的代码奉上:
/// <summary>
/// 计算一个整数数组的最大值、最小值、平均值、总和
/// </summary>
/// <param name="nums">要求值得数组</param>
/// <param name="max">多余返回的最大值</param>
/// <param name="min">多余返回的最小值</param>
/// <param name="sum">多余返回的总和</param>
/// <param name="avg">多余返回的平均值</param>
public static void Test(int[] nums, out int max, out int min, out int sum, out int avg)
{
//out参数要求在方法的内部必须为其赋值
//我们假设数组中的第一个元素为最大值
max = nums[0];
//假设数组中的第一个元素为最小值
min = nums[0];
//总和设置为零
sum = 0;
for (int i = 0; i < nums.Length; i++)
{
if (nums[i] > max)
{
max = nums[i];
}
if (nums[i] < min)
{
min = nums[i];
}
sum += nums[i];
}
avg = sum / nums.Length;
}
1 static void Main(string[] args)
2 {
3 //写一个方法 求一个数组中的最大值、最小值、总和、平均值
4 int[] numbers = { 1, 2, 3, 4, 5, 6, 7, 8, 9 };
5 //变量的声明
6 int max1;
7 int min1;
8 int sum1;
9 int avg1;
10 //方法的调用
11 Test(numbers, out max1, out min1, out sum1, out avg1);
12 Console.WriteLine(max1);
13 Console.WriteLine(min1);
14 Console.WriteLine(sum1);
15 Console.WriteLine(avg1);
16 Console.ReadKey();
17
18 }
调试的结果如下:
6.现在我么用out参数做一个练习:分别的提示用户输入用户名和密码,写一个方法来判断用户输入的是否正确,返回给用户一个登录的结果,并且还要单独的返回给用户一个登录的信息,如果用户名错误,除了返回登录结果之外,还要返回一个“用户名错误”,如果密码错误,除了返回登录结果之外,还要返回一个“密码错误”。
分析的思路:通过上面的题我们分析我们不仅要返回一个登录结果,还要多余的返回一个登录的信息(是登录名错误还是密码错误还是未知的错误),这时候我们需要考虑使用out参数了。完整的代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace _08使用out参数做登陆
{
class Program
{
static void Main(string[] args)
{
Console.WriteLine("请输入用户名");
string userName = Console.ReadLine();
Console.WriteLine("请输入密码");
string userPwd = Console.ReadLine();
string msg;
bool b = IsLogin(userName, userPwd, out msg);
Console.WriteLine("登陆结果{0}",b);
Console.WriteLine("登陆信息{0}",msg);
Console.ReadKey();
}
/// <summary>
/// 判断登陆是否成功
/// </summary>
/// <param name="name">用户名</param>
/// <param name="pwd">密码</param>
/// <param name="msg">多余返回的登陆信息</param>
/// <returns>返回登陆结果</returns>
public static bool IsLogin(string name, string pwd, out string msg)
{
if (name == "admin" && pwd == "888888")
{
msg = "登陆成功";
return true;
}
else if (name == "admin")
{
msg = "密码错误";
return false;
}
else if (pwd == "888888")
{
msg = "用户名错误";
return false;
}
else
{
msg = "未知错误";
return false;
}
}
}
}
结果如下截图:

二:那么接下来说一下ref参数的使用。
那么老规矩我们首先来看一下这道题:使用方法来交换两个int类型的变量。
思路分析:首先这个一道非常经典的面试题,我们可以使用两种方法来做这道题(这里不详细的解释)。
首先声明一个方法来实现两个int类型变量的交换。代码如下:
1 /// <summary>
2 /// 交换两个int类型的变量
3 /// </summary>
4 /// <param name="n1">第一个参数</param>
5 /// <param name="n2">第二个参数</param>
6 public static void Test(int n1, int n2)
7 {
8 n1 = n1 - n2;//-10 20
9 n2 = n1 + n2;//-10 10
10 n1 = n2 - n1;//20 10
11 }
在这个时候考虑我们在Main方法中调用就能实现结果吗??答案是不行的。这就设计到我们的值类型和引用类型(在后面做详细的解释)。这个时候我们就要用到我们的ref参数了。这个时候我们给ref参数做一个定义:ref参数可以将一个变量带入到一个方法中进行改变,改变完成后,在将改变完成后的值带出方法。特点:ref参数要求在方法的外部必须为其赋值,在方法的内部可以不赋值。
完整的代码如下:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace _11_ref练习
{
class Program
{
static void Main(string[] args)
{
//使用方法来交换两个int类型的变量
//必须在方法的外部为其赋值
int n1 = 10;
int n2 = 20;
Test(ref n1, ref n2);
Console.WriteLine(n1);
Console.WriteLine(n2);
Console.ReadKey();
}
/// <summary>
/// 交换两个int类型的变量
/// </summary>
/// <param name="n1">第一个参数</param>
/// <param name="n2">第二个参数</param>
public static void Test(ref int n1, ref int n2)
{
//方法的内部可以不赋值
n1 = n1 - n2;//-10 20
n2 = n1 + n2;//-10 10
n1 = n2 - n1;//20 10
}
}
}
代码的结果截图如下:
三:下面我们来介绍一下Params可变参数。
这次我们的题目是:求任意长度的数字的和(整数类型的)。
我们直接给出定义:将实参列表跟可变参数类型一致的元素都当作数组中的元素来处理。特点:Params可变参数必须是形参列表中的最后一个元素。
直接看代码:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
namespace _12params可变参数
{
class Program
{
static void Main(string[] args)
{
int sum = GetSum(8,9);
Console.WriteLine(sum);
Console.ReadKey();
}
/// <summary>
/// 求数组中的和
/// </summary>
/// <param name="n">数组</param>
/// <returns>返回总和</returns>
public static int GetSum(params int[] n)
{
int sum = 0;
for (int i = 0; i < n.Length; i++)
{
sum += n[i];
}
return sum;
}
}
}
大家看见了吗,这时候我们将8 ,9 就当作我们形参列表数组中的元素来进行处理,这样的话我们就是实现了我们的功能了。
四:这个时候我们该讨论一下out参数和ref参数为什么可以实现这样的功能。比如拿ref参数做例子:
在讨论这个问题之前我们该说一下值类型和引用类型的区别了。
(1):值类型和引用类型在内存中存储的地方不一样。
(2):在传递值类型和传递引用类型的时候,传递的方式不一样,值类型我们称之为值传递,引用类型我们称之为引用传递。
值类型 :int double bool char decimal struct enum
引用类型:string 自定义类 数组 object 集合 接口
在举例子之前首先请允许我说两个重要的概念:
(1):值类型在复制的时候,传递的是这个值的本身。
(2):引用类型在复制的时候,传递的是对这个对象的引用。
首先我们先来句第一个例子,代码如下:
//值传递和引用传递 int n1 = 10; int n2 = n1; n2 = 20; Console.WriteLine(n1); Console.WriteLine(n2); Console.ReadKey();
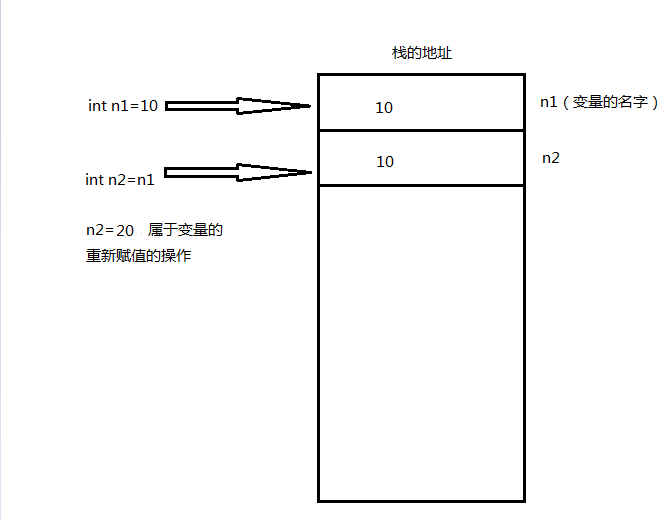
大家猜一下结果是多少??答案是:10 20,因为int是值类型,当我声明int n1=10,就相当于我们在内存的栈中开辟了一块内存地址,那我们如何在我们的内存中找到我们的值呢(也就是我们给这块内存区域取一个名字,也就是我们的变量名),ok,当执行int n2=n1的时候,也就是进行了一个赋值的操作,如上所说,值类型在传递的时候我们传递的是值的本身。所以当我们执行完第二行的代码的时候,n2=10,当执行完第三行的代码的时候,又重新给n2赋值n2=20,所有输出的结果就是:n1=10,n2=20。 画图表示如下:
接下来我们看第二个例子(Person默认是自定义类):
1 Person p1 = new Person(); 2 p1.Name = "张三"; 3 Person p2 = p1; 4 p2.Name = "李四"; 5 Console.WriteLine(p1.Name); 6 Console.ReadKey();
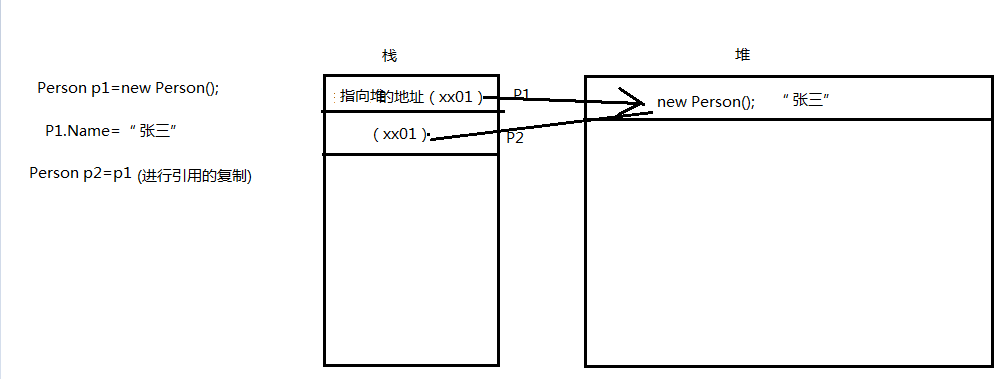
这个时候p1.Name为多少呢?? 答案是:李四。首先我们肯定是Person是自定义类,因为我们的自定义类为引用类型,所以在进行引用传递的时候传递的是对这个对象的引用(内存地址)。当我们声明第一行的代码的时候,会在内存的堆中开辟一块区域存储new Person();当为其Name赋值的时候,张三也存储在堆中,这时候也会在栈中开辟一块空间存储了指向这块区域的地址。所以当执行Person p2=p1,是把P1在栈中的引用复制了一份给了P2,所以现在他们两指向的是堆中同一块区域。所以当给Name重新赋值的时候,p1的值也会改变。截图如下:

画图表示如下:
第三个例子:,代码如下:
1 string s1 = "张三"; 2 string s2 = s1; 3 s2 = "李四"; 4 Console.WriteLine(s1); 5 Console.WriteLine(s2); 6 Console.ReadKey();
这个时候我们的s1和s2是多少呢??经过我的测试答案是:s1:张三,s2:李四。为什么呢?要是按照我们上面的过程应该都是李四呀?因为我们的字符串是非常特殊的,正是由于字符串的不可变性,没每当我们在为其赋值的时候都会在堆中重新开辟一块区域进行存储。所以两块区域没有任何的关系。

思考的问题:这时候我们回顾在一个方法中实现交换变量的例子,当我们没有用ref的时候,传递的是值的本身,当我们使用ref参数的时候传递的是这个对象的引用(内存地址)。所以我们总结出来ref的作用是:ref参数可以将一个值传递改变为引用传递。
好的,我们c#中的三个高级参数在这里就介绍完了,如果大家有什么疑问的话,可以留言,大家共同进步。
原文地址:http://www.cnblogs.com/MoRanQianXiao/p/7702587.html。