
使用selenium的方式获取网页中图片的链接和网页的链接,来判断是否是死链(二)
2023-09-11 14:14:15 时间
上一篇使用Java正则表达式来判断和获取图片的链接以及跳转的网址,这篇使用selenium的自带的API(getAttribute)来获取网页中指定的内容
实现内容:获取下面所有图片的链接地址以及跳转地址,使用get请求判断是否有死链
页面内容如图:
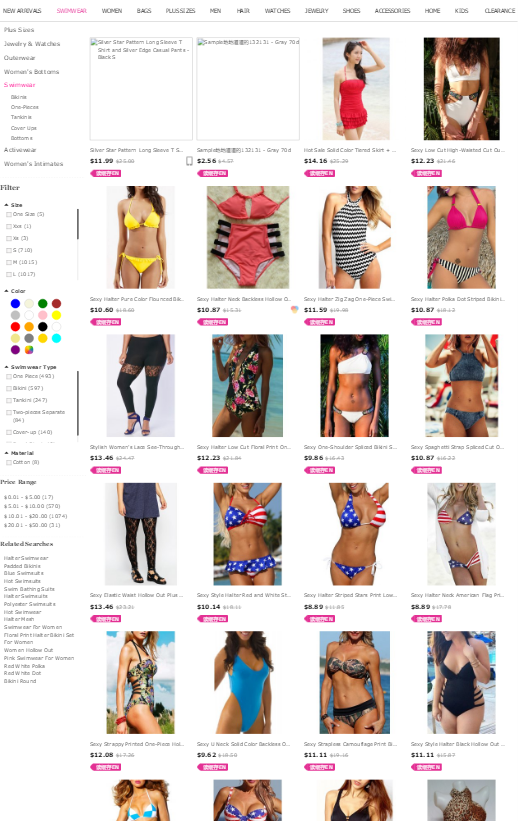
页面的源码,需要获取页面的href后的地址,以及src后的地址,:
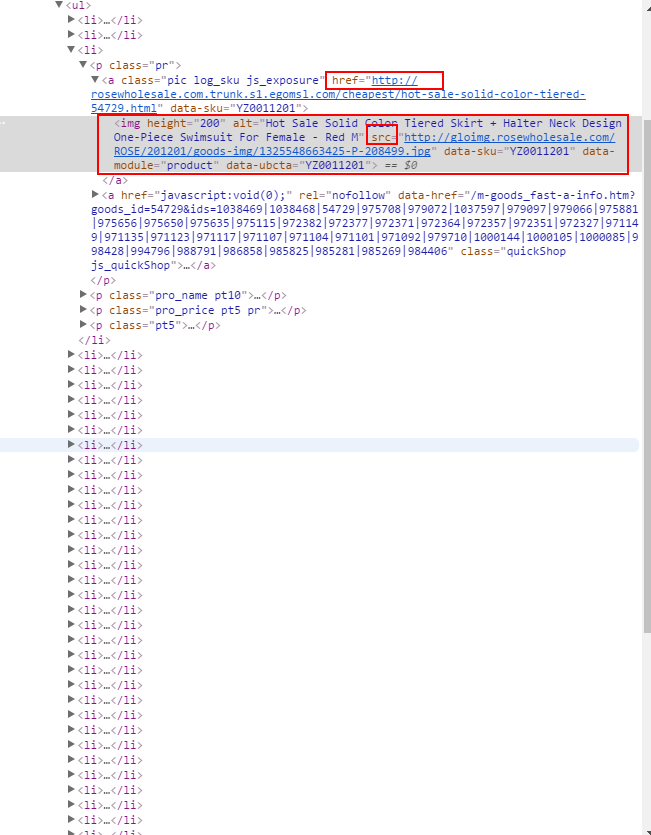
代码实现可以看出图片都在一个div中,实现的思想为:获取控件集合,在获取每一个li下的元素,在获取,在取出数据下的属性名的属性值
public void new_classification() throws Exception { op.loopGet(home, 40, 3, 60); op.loopClickElement("swimmer", 3, 10, explicitWaitTimeoutLoop);// 进入到某个页面 if (driver.getCurrentUrl().contains("swimwear")) { List<WebElement> newimage = driver.findElements(By.xpath("//*[@id='js_proList']/ul/li"));// 图片的控件集合 for (int i = 0; i < newimage.size(); i++) { String contentURL = newimage.get(i).findElement(By.xpath("p[1]/a[1]")).getAttribute("href");// 图片的跳转地址 String imageURL = newimage.get(i).findElement(By.xpath("p[1]/a[1]/img")).getAttribute("src");// 图片的链接地址 Pub.get(contentURL); System.out.println("**********************"); Pub.get(imageURL);//get请求 } } else { Log.logError("没有进入到new页面"); } }
结果展示

如果需要使用正则表达式,查看文章:http://www.cnblogs.com/chongyou/p/7286447.html
相关文章
- 微信企业号开发:微信用户信息和web网页的session的关系
- 三种简单的浏览器设置自动刷新网页
- PHP网页计数器
- 【Vue/html】如何解决csdn下载网页后打开自动跳转登陆的问题(已解决)
- Highmaps网页图表教程之图表配置项结构与商业授权
- 《网页设计心理学》一1.8 但是我们知道自己喜欢什么不喜欢什么,不是么?
- 《提高转化率!网页A/B测试与多变量测试实战指南》一2.2 掌控优化测试
- 《移动网页设计与开发 HTML5+CSS3+JavaScript》—— 1.5 CSS3及其他
- 《HTML5 开发实例大全》——1.20 分组列表显示网页中的内容
- 授予渔,从0开始搭建一个自己想要的网页
- 网页图片水平垂直居中对齐的方法
- 在一个Activity里面的TextView上面添加网页链接,启动后到另一个Activity里面!
- 微信点击超链接第一次不会有“微信中网页底部导航栏”,进入之后再点击链接就会有了,自己会新建窗口
- jQuery中json中关于带有html代码网页的处理
- word模版另存为网页(*.htm,*.html),转为jsp页面并加入数据后导出成word
- 解决网页对话框中链接和表单提交会在新窗口中打开的问题
- Lua访问网页
- iOS12网页视频播放点击全屏按钮会导致闪退
- PS网页设计教程——30个优秀的PS网页设计教程的中文翻译教程
- PS网页设计教程XXVII——设计一个大胆和充满活力的作品集