
torchserver模型本地部署和docker部署
https://www.zhihu.com/question/389731764
https://zhuanlan.zhihu.com/p/263865832
https://blog.csdn.net/qq_28613337/article/details/110438060
https://jishuin.proginn.com/p/763bfbd2c54d
https://zhuanlan.zhihu.com/p/344364948
https://zhuanlan.zhihu.com/p/344364948
真实案例介绍:
https://blog.csdn.net/weixin_34910922/article/details/114550772
https://blog.csdn.net/weixin_34910922/article/details/114550772
torch serverGPU部署
https://www.icode9.com/content-4-1139862.html
本地运行三个关键步骤
步骤一、安装环境,下载目录
pip install torchserve torch-model-archiver
git clone https://gitee.com/AI-Mart/serve.git
步骤二、打包模型文件
torch-model-archiver 命令来打包模型
1.checkpoint.pth.tar
从命名就应该知道,这就是我们在训练过程中通过 torch.save 获得的模型权重文件,注意该文件内容只能包含模型的权重。参考文件:https://github.com/louis-she/torch-serve-mnist/blob/main/mnist/mnist.pth.tar
- model.py
该文件应该包含单个模型的类,该模型类应该可以使用 load_state_dict 来成功加载 checkpoint.pth.tar 提供的权重。参考文件 https://github.com/louis-she/torch-serve-mnist/blob/main/mnist/model.py
- handler.py (可选)
如果希望加入一些自定义的 preprocessing 和 postprocessing,可以加入该文件。比如,对于视觉类任务,我们至少需要对输入图片进行一些 resize,归一化操作,还会对模型输出做一些后处理。这些都可以在 handler.py 中来定义。
torch-model-archiver --model-name mnist --serialized-file mnist.pth.tar --model-file model.py --handler handler --runtime python3 --version 1.0
这里的参数都比较容易理解,但注意 --model-name 参数我们可以取一个有意义的名称(但最好不要加中文或空格),该参数会影响到我们之后的调用服务的 URL 链接。
调用过后我们将会获得一个 mnist.mar 文件,这就是我们打包好的文件。
步骤三、启动模型服务
1启动服务
创建一个目录,名称为 model-store,将第一步打包好的 .mar 复制到这个目录中,然后我们就可以启动 TorchServe 服务器程序了:
torchserve --start --model-store $model-store-path
$model-store-path 替换为 model-store 的绝对路径即可。
2 注册模型
服务进程启动后,model-store 中的 mar 文件不会自动注册到 TorchServe 中,我们需要通过 TorchServe 提供的 Management API 来注册 model-store 中的 mar 文件。
API 的调用都将使用 curl 命令,如果你对该命令不熟悉,也可以使用 http GUI 客户端。
首先注册 mar 文件,这里依然以 MNIST 为例子:
curl -X POST "http://localhost:8081/models?url=mnist.mar"
注意 url= 后面的值必须是在 model-store 目录中有的文件。
3 分配进程
然后为 mnist 分配工作进程,你可以根据 CPU 核心数来分配
curl -v -X PUT "http://localhost:8081/models/mnist?min_worker=1&max_worker=1&synchronous=true"
4访问接口
现在我们的 mnist.mar 就可以对外提供服务了,准备一张手写数字图片 test.png,
curl "http://127.0.0.1:8080/predictions/mnist" -T test.png
{
“8”: 0.9467765688896179,
“3”: 0.023649968206882477,
“5”: 0.019438084214925766,
“9”: 0.008277446031570435,
“2”: 0.001520493533462286
}
这里注意 url 的格式为 /predictions/$model-name,因为我们之前指定的 model-name 是 mnist,所以链接为 /predictions/mnist
看到这里你应该已经猜到,我们甚至可以同时注册多个模型,只要将打包好的 mar 文件放入 model-store 目录中,然后调用 Management API 后即可。
案例实战
1 切换目录
cd /mart/pt_server/serve/examples/image_classifier
2 下载模型权重
wget https://download.pytorch.org/models/densenet161-8d451a50.pth
3 打包模型文件
torch-model-archiver --model-name densenet161 --version 1.0 --model-file densenet_161/model.py --serialized-file densenet161-8d451a50.pth --handler image_classifier --extra-files index_to_name.json
4 将模型放入存储目录
mkdir model_store
mv densenet161.mar model_store/
5 启动serve
torchserve --start --model-store model_store --models densenet161=densenet161.mar
注册服务,并且设置参数
https://blog.csdn.net/weixin_34910922/article/details/114552407
6 测试一张图

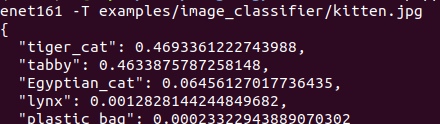
curl http://127.0.0.1:8080/predictions/densenet161 -T examples/image_classifier/kitten.jpg
结果
7 测试完毕后,关闭服务、删除日志
在服务终端,ctrl+C结束。
使用torchserve --stop,关闭服务。

DOCKER运行部署三个关键步骤
端口号说明
-p8080:8080 -p8081:8081 -p 8082:8082 -p 7070:7070 -p 7071:7071 TorchServe uses default ports 8080 / 8081 / 8082 for REST based inference, management & metrics APIs and 7070 / 7071 for gRPC APIs. You may want to expose these ports to the host for HTTP & gRPC Requests between Docker & Host.
1 下载项目文件
git clone https://github.com/pytorch/serve.git
cd serve/docker
2 构建docker image CPU
镜像下载列表https://hub.docker.com/r/pytorch/torchserve/tags?page=1&ordering=last_updated
docker pull pytorch/torchserve:latest
2 构建docker image GPU
1、需要安装nvidia docker,参照https://blog.csdn.net/qq_15821487/article/details/122664031?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164319182916780264058928%2522%252C%2522scm%2522%253A%252220140713.130102334.pc%255Fblog.%2522%257D&request_id=164319182916780264058928&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2blogfirst_rank_ecpm_v1~rank_v31_ecpm-1-122664031.nonecase&utm_term=docker%E9%83%A8%E7%BD%B2pytorch+gpu&spm=1018.2226.3001.4450
2、镜像下载列表https://hub.docker.com/r/pytorch/torchserve/tags?page=1&ordering=last_updated
nvidia-smi,根据机器得出的cuda型号下拉特定版本的镜像
cuda10.1版本只能下拉这个版本的镜像,其他的版本都是10.2以及以上
docker pull pytorch/torchserve:0.1-cuda10.1-cudnn7-runtime
3 切换目录
cd /mart/pt_server/serve/examples/image_classifier
4 下载模型权重
wget https://download.pytorch.org/models/densenet161-8d451a50.pth
5 新建模型保存文件夹
mkdir model-store
6 打包模型文件,生产可部署的模型文件

handler 可用用默认的torchserve自带的处理函数,下拉镜像里面已经自带了,所以参数为对应的函数名即可
如果需要自定义,就自己编写相关的handler.py文件即可,参数也是这个文件,自定义的话文本类继承text_handler的基类,图像类继承vision_handler的基类
torch-model-archiver --model-name densenet161 --version 1.0 --model-file densenet_161/model.py --serialized-file densenet161-8d451a50.pth --export-path model-store --handler image_classifier --extra-files index_to_name.json -f
--model-name: 模型的名称,后来的接口名称和管理的模型名称都是这个
--serialized-file: 模型环境及代码及参数的打包文件
--export-path: 本次打包文件存放位置
--extra-files: handle.py中需要使用到的其他文件
--handler: 指定handler函数。(模型名:函数名)
-f 覆盖之前导出的同名打包文件
7.启动docker服务,CPU
docker run --rm -it -p 3000:8080 -p 3001:8081 --name densenet161 -v /mart/pt_server/serve/examples/image_classifier/model-store:/home/model-server/model-store pytorch/torchserve:latest
# docker 可选参数 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 \
# 切换到后台运行
ctrl + p + q
7.启动docker服务,GPU
docker run --rm -it --gpus all -p 3000:8080 -p 3001:8081 --name densenet161 -v /mart/pt_server/serve/examples/image_classifier/model-store:/home/model-server/model-store pytorch/torchserve:0.1-cuda10.1-cudnn7-runtime
# docker 可选参数 --shm-size=1g --ulimit memlock=-1 --ulimit stack=67108864 \
# 切换到后台运行
ctrl + p + q
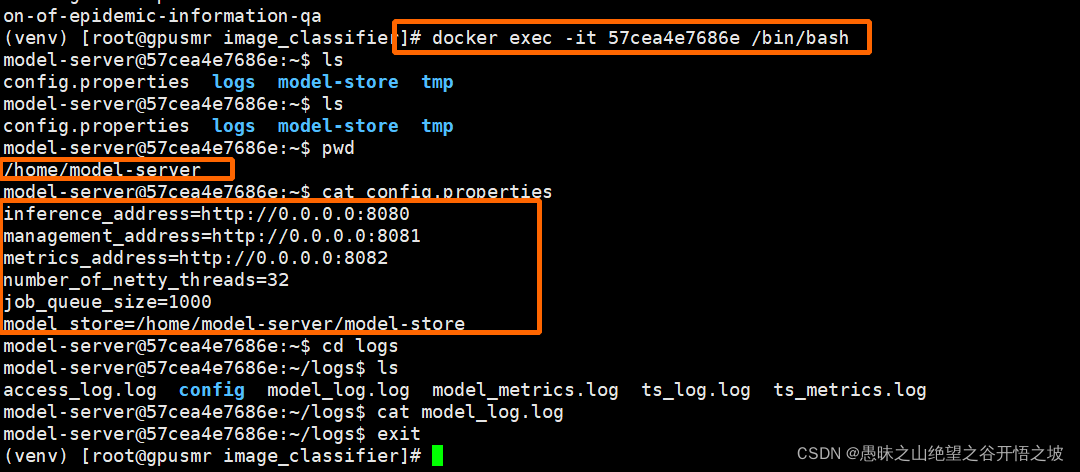
进入容器
docker exec -it densenet161 /bin/bash
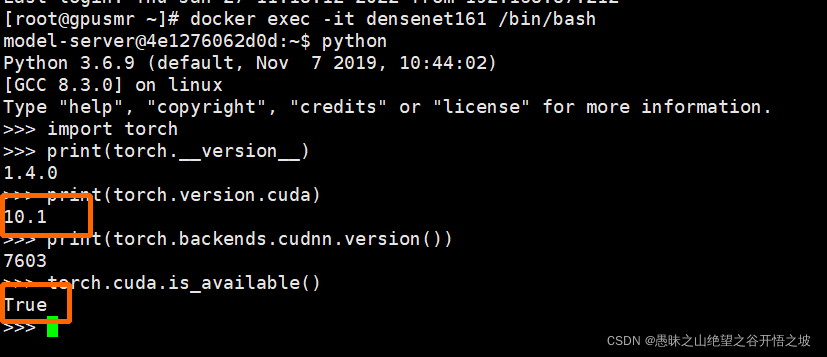
验证cuda是否可用以及版本号,发现和本地的版本不一致,会导致不可用,重新下拉镜像
import torch
print(torch.__version__)
print(torch.version.cuda)
print(torch.backends.cudnn.version())
torch.cuda.is_available()
#cuda是否可用;
torch.cuda.device_count()
#返回gpu数量;
torch.cuda.get_device_name(0)
#返回gpu名字,设备索引默认从0开始;
torch.cuda.current_device()
#返回当前设备索引
/home/model-server/model-store 是docker映射地址,不能更改
进入容器,可以发现各个端口的意义,8080是通信访问接口,8081是管理服务配置接口,8082是服务监控接口
和本地的版本匹配,gpu可用
8.torchserver配置接口
# 查询已注册的模型
curl "http://localhost:3001/models"
# 注冊模型并为模型分配资源
curl -v -X POST "http://localhost:3001/models?initial_workers=1&synchronous=false&url=densenet161.mar"
# 修改分配worker数量
curl -v -X PUT "http://localhost:3001/models/densenet161?min_worker=3"
# 查看注册模型基本信息
curl "http://localhost:3001/models/densenet161"
# 使用以下代码注销模型
curl -X DELETE http://localhost:3001/models/densenet161/
# 模型版本控制
要对模型进行版本控制,请在调用时torch-model-archiver,将版本号传递给--version,请参见以下代码:
torch-model-archiver --model-name densenet161 --version 1.0 ...
8模型预测接口(handler.py文件中的逻辑)
curl http://localhost:3000/predictions/densenet161 -T /mart/pt_server/serve/examples/image_classifier/kitten.jpg

9.进入docker 镜像停止或运行程序
# 进入docker容器
docker exec -it [容器名称] /bin/bash
# 停止服务
torchserve --stop
# 启动服务
torchserve --start --ncs --model-store /home/model-server/model-store --models densenet161.mar


通过TorchServe,可以轻松地在生产环境中大规模部署PyTorch模型。它以低延迟提供轻量级服务,因此您可以部署模型以进行高性能推理。它为最常见的应用程序提供了默认处理程序,例如目标检测和文本分类,因此您不必编写自定义代码即可部署模型。借助强大的TorchServe功能,包括多模型服务,用于A / B测试的模型版本控制,用于监视的指标以及用于应用程序集成的RESTful端点,您可以将模型从研究阶段快速投入生产。TorchServe支持任何机器学习环境,包括Amazon SageMaker,Kubernetes,Amazon EKS和Amazon EC2。
TorchServe采用Java开发,
而TensorFlow Serving一样采用更好性能的C++
讲一下这个框架的发展史:最开始本来是给MXNet做的。后来因为性能不好,同组大佬 (25年Java开发经验) 用netty在一个周末 (2万5千行) 重构了整个MXNet Model Server 也就是后来的 Multi Model Server 也就是后来的 TorchServe。当时PT感觉这个架构很好用,然后AWS和FB就一起针对Torch做了很多优化开发了这个东西。它运行速度相当快,而且支持热插拔,快速导入模型进行推理,无需重启机器。------ 后话然后大佬觉得,用Java host Python的server还是有 restful call的bottleneck。然后,然后一年多以后,我们一起就写了 DJL,一个完全用Java重构的框架。。——补充为什么要用Java host。1.基于Java的服务器目前来看还是市场占有第一。2. Java的Netty很稳定,用户量也大,社区较好。同比c++相同体量一个能打的都没有。然后,benchmark过,c++速度和jvm基本是一样的(offload benchmark).
相关文章
- 阿里云部署Docker(3)----指令学习
- Centos7二进制部署k8s-v1.20.2 ipvs版本(docker、etcd)
- Docker的三种网络代理配置:dockerd pull镜像代理;容器docker run网络代理;docker build代理--build-arg
- docker-compose部署nacos derby(官网文档)
- 【云原生 | 37】Docker快速部署编程语言Golang
- 【云原生 | 36】Docker快速部署主流脚本语言JavaScript
- 【云原生 | 35】Docker快速部署主流解释型语言Python
- 【云原生之Docker实战】使用docker部署mkdocs项目文档工具
- 【云原生之Docker实战】使用docker部署IT资产管理系统GLPI
- 【云原生之Docker实战】使用docker部署Ghost个人博客系统
- 【云原生之Docker实战】使用docker部署yesplaymusic个人音乐播放器
- 【云原生之Docker实战】使用Docker部署宝塔面板
- 【云原生之Docker实战】使用docker部署wiki.js知识库
- 【云原生之Docker实战】使用docker部署短链接服务YOURLS
- 【云原生之Docker实战】使用Docker部署Cloudreve公有云文件系统
- 中秋征文 | 【云原生之Docker】使用docker部署内网穿透工具FRP
- 【云原生之Docker实战】使用docker部署Memos碎片化知识管理工具
- 【云原生之Docker实战】使用docker部署o2oa企业OA平台
- Linux centos7 docker部署gitlab私有服务器
- 【Docker】之docker-compose的介绍与命令的使用
- Docker重学系列之高级网络篇
- Docker 部署 Tomcat
- 云原生之使用Docker部署docker-compose-ui工具
- docker cobbler批量部署Linux/windows系统(三)——筑梦之路