
Leetcode: LFU Cache && Summary of various Sets: HashSet, TreeSet, LinkedHashSet
Design and implement a data structure for Least Frequently Used (LFU) cache. It should support the following operations: get and set. get(key) - Get the value (will always be positive) of the key if the key exists in the cache, otherwise return -1. set(key, value) - Set or insert the value if the key is not already present. When the cache reaches its capacity, it should invalidate the least frequently used item before inserting a new item. For the purpose of this problem, when there is a tie (i.e., two or more keys that have the same frequency), the least recently used key would be evicted. Follow up: Could you do both operations in O(1) time complexity? Example: LFUCache cache = new LFUCache( 2 /* capacity */ ); cache.set(1, 1); cache.set(2, 2); cache.get(1); // returns 1 cache.set(3, 3); // evicts key 2 cache.get(2); // returns -1 (not found) cache.get(3); // returns 3. cache.set(4, 4); // evicts key 1. cache.get(1); // returns -1 (not found) cache.get(3); // returns 3 cache.get(4); // returns 4
referred to: https://discuss.leetcode.com/topic/69137/java-o-1-accept-solution-using-hashmap-doublelinkedlist-and-linkedhashset
Two HashMaps are used, one to store <key, value> pair, another store the <key, node>.
I use double linked list to keep the frequent of each key. In each double linked list node, keys with the same count are saved using java built in LinkedHashSet. This can keep the order.
Every time, one key is referenced, first find the current node corresponding to the key, If the following node exist and the frequent is larger by one, add key to the keys of the following node, else create a new node and add it following the current node.
All operations are guaranteed to be O(1).
1 public class LFUCache { 2 int cap; 3 ListNode head; 4 HashMap<Integer, Integer> valueMap; 5 HashMap<Integer, ListNode> nodeMap; 6 7 public LFUCache(int capacity) { 8 this.cap = capacity; 9 this.head = null; 10 this.valueMap = new HashMap<Integer, Integer>(); 11 this.nodeMap = new HashMap<Integer, ListNode>(); 12 } 13 14 public int get(int key) { 15 if (valueMap.containsKey(key)) { 16 increaseCount(key); 17 return valueMap.get(key); 18 } 19 return -1; 20 } 21 22 public void set(int key, int value) { 23 if (cap == 0) return; 24 if (valueMap.containsKey(key)) { 25 valueMap.put(key, value); 26 increaseCount(key); 27 } 28 else { 29 if (valueMap.size() < cap) { 30 valueMap.put(key, value); 31 addToHead(key); 32 } 33 else { 34 removeOld(); 35 valueMap.put(key, value); 36 addToHead(key); 37 } 38 } 39 40 } 41 42 public void increaseCount(int key) { 43 ListNode node = nodeMap.get(key); 44 node.keys.remove(key); 45 if (node.next == null) { 46 node.next = new ListNode(node.count+1); 47 node.next.prev = node; 48 node.next.keys.add(key); 49 } 50 else if (node.next.count == node.count + 1) { 51 node.next.keys.add(key); 52 } 53 else { 54 ListNode newNode = new ListNode(node.count+1); 55 newNode.next = node.next; 56 node.next.prev = newNode; 57 newNode.prev = node; 58 node.next = newNode; 59 node.next.keys.add(key); 60 } 61 nodeMap.put(key, node.next); 62 if (node.keys.size() == 0) remove(node); 63 } 64 65 public void remove(ListNode node) { 66 if (node.next != null) { 67 node.next.prev = node.prev; 68 } 69 if (node.prev != null) { 70 node.prev.next = node.next; 71 } 72 else { // node is head 73 head = head.next; 74 } 75 } 76 77 public void addToHead(int key) { 78 if (head == null) { 79 head = new ListNode(1); 80 head.keys.add(key); 81 } 82 else if (head.count == 1) { 83 head.keys.add(key); 84 } 85 else { 86 ListNode newHead = new ListNode(1); 87 head.prev = newHead; 88 newHead.next = head; 89 head = newHead; 90 head.keys.add(key); 91 } 92 nodeMap.put(key, head); 93 } 94 95 public void removeOld() { 96 if (head == null) return; 97 int old = 0; 98 for (int keyInorder : head.keys) { 99 old = keyInorder; 100 break; 101 } 102 head.keys.remove(old); 103 if (head.keys.size() == 0) remove(head); 104 valueMap.remove(old); 105 nodeMap.remove(old); 106 } 107 108 public class ListNode { 109 int count; 110 ListNode prev, next; 111 LinkedHashSet<Integer> keys; 112 public ListNode(int freq) { 113 count = freq; 114 keys = new LinkedHashSet<Integer>(); 115 prev = next = null; 116 } 117 } 118 } 119 120 /** 121 * Your LFUCache object will be instantiated and called as such: 122 * LFUCache obj = new LFUCache(capacity); 123 * int param_1 = obj.get(key); 124 * obj.set(key,value); 125 */
Summary of LinkedHashSet: http://www.programcreek.com/2013/03/hashset-vs-treeset-vs-linkedhashset/
A Set contains no duplicate elements. That is one of the major reasons to use a set. There are 3 commonly used implementations of Set: HashSet, TreeSet and LinkedHashSet. When and which to use is an important question. In brief, if you need a fast set, you should use HashSet; if you need a sorted set, then TreeSet should be used; if you need a set that can be store the insertion order, LinkedHashSet should be used.
1. Set Interface
Set interface extends Collection interface. In a set, no duplicates are allowed. Every element in a set must be unique. You can simply add elements to a set, and duplicates will be removed automatically.
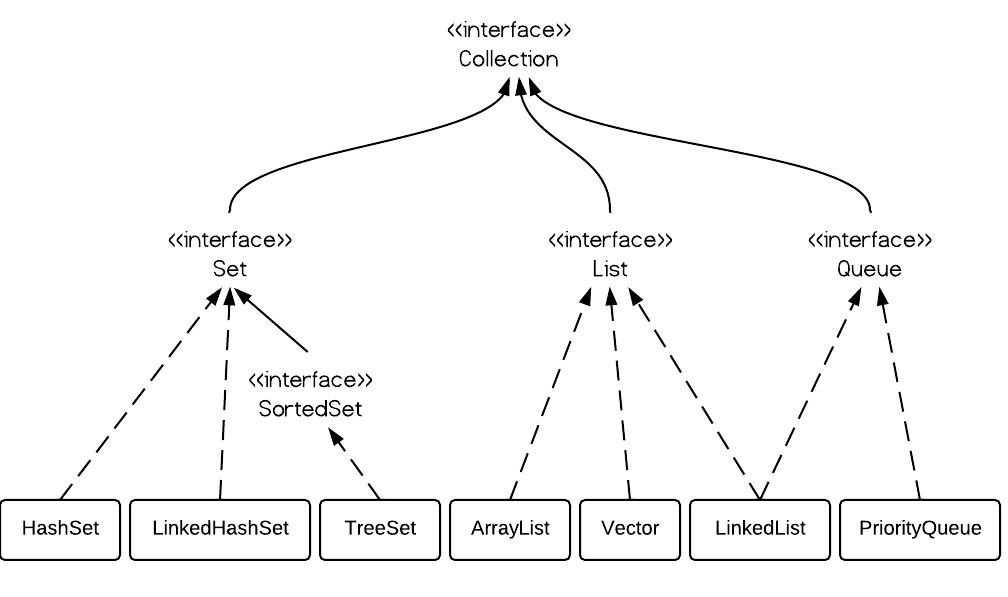
2. HashSet vs. TreeSet vs. LinkedHashSet
HashSet is Implemented using a hash table. Elements are not ordered. The add, remove, and contains methods have constant time complexity O(1).
TreeSet is implemented using a tree structure(red-black tree in algorithm book). The elements in a set are sorted, but the add, remove, and contains methods has time complexity of O(log (n)). It offers several methods to deal with the ordered set like first(), last(), headSet(), tailSet(), etc.
LinkedHashSet is between HashSet and TreeSet. It is implemented as a hash table with a linked list running through it, so it provides the order of insertion. The time complexity of basic methods is O(1).
3. TreeSet Example
TreeSet<Integer> tree = new TreeSet<Integer>();
tree.add(12);
tree.add(63);
tree.add(34);
tree.add(45);
Iterator<Integer> iterator = tree.iterator();
System.out.print("Tree set data: ");
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
|
Output is sorted as follows:
Tree set data: 12 34 45 63
4. HashSet Example
HashSet<Dog> dset = new HashSet<Dog>();
dset.add(new Dog(2));
dset.add(new Dog(1));
dset.add(new Dog(3));
dset.add(new Dog(5));
dset.add(new Dog(4));
Iterator<Dog> iterator = dset.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
|
Output:
5 3 2 1 4
Note the order is not certain.
5. LinkedHashSet Example
LinkedHashSet<Dog> dset = new LinkedHashSet<Dog>();
dset.add(new Dog(2));
dset.add(new Dog(1));
dset.add(new Dog(3));
dset.add(new Dog(5));
dset.add(new Dog(4));
Iterator<Dog> iterator = dset.iterator();
while (iterator.hasNext()) {
System.out.print(iterator.next() + " ");
}
|
The order of the output is certain and it is the insertion order:
2 1 3 5 4
相关文章
- 并发数据结构- 1.8 优先队列&1.9 总结
- [LeetCode] Palindrome Number & Valid Palindrome - 回文系列问题
- 【数组&双指针】leetcode 283. 移动零【简单】
- 【数组&双指针】leetcode 234. 回文链表【简单】
- [Redux-Observable && Unit testing] Testing the output of epics
- 【数组&双指针】LeetCode 1. 两数之和【简单】
- 报错"ORA-01861: 文字与格式字符串不匹配"
- 华为OD机试 - 英文输入法(Java & JS & Python)
- 线程异常:undefined reference to 'pthread_create' 处理
- 【华为云技术分享】敏捷&DevOps知识卡大全(内附下载资料)
- <LeetCode OJ> 328. Odd Even Linked List
- uva 11178 Morley's Theorem(计算几何-点和直线)
- .NET Framework 4.0&4.5安装包下载
- LeetCode刷题训练 && LeetCode算法和数据结构学习(一)