
Hw1机器学习的作业
五月又是学习的好季节,准备重拾起算法搞本砖业的东西,数据挖掘----》机器学习
这次有很有幸的看到了一位讲得很好的老师李宏毅老师的ml,真的适合入门。当然也会涉及到一些求导或者现代以及其他数学类的东西。
这里有梯度下降法不懂的可以看看https://www.youtube.com/watch?v=yKKNr-QKz2Q 这个是youtube的也有b站的https://www.bilibili.com/video/av9770190/?p=3感兴趣却又不是很懂的可以去看看。
最后附上自己做的作业的代码,这个是自己写的,没有配图和解释,将就着看吧,只有注释,顺便给出作业的地址https://ntumlta.github.io/2017fall-ml-hw1/。
# -*- coding: utf-8 -*-
"""
Created on Sun May 13 20:59:45 2018
@author: 被遗弃的庸才
"""
import numpy as np
import matplotlib.pyplot as plt
xandy=[]
i=1
with open('train.txt') as files:
while True:
line=files.readline()
if line.strip():
if i%18 == 10:
for j in range(2,12):
xandy.append(float(line.split(',')[j]))
#print(line.split(',')[j],end=' ')#这里只输出pm2.5的值
#pass
#print()#换行
else:
break
i+=1
xandy=np.array(xandy)
xandy=xandy.reshape(240,10)#改变一下形状
#print(xandy.shape)
#定义方程y=wx-------------+b
w=np.random.randn(9,1)#随机给出w
b=1#直接给出b
#print(w)
cost=[]
x=[]
lr=0.000001#手动调学习率,我也不知道多少合适,看着来嘛,
literator=1000000#迭代次数为10000次
sum_gradient_w=[0,0,0,0,0,0,0,0,0]
sum_gradient_b=0
for j in range(literator):
y_=np.dot(xandy[:,0:9],w)+b
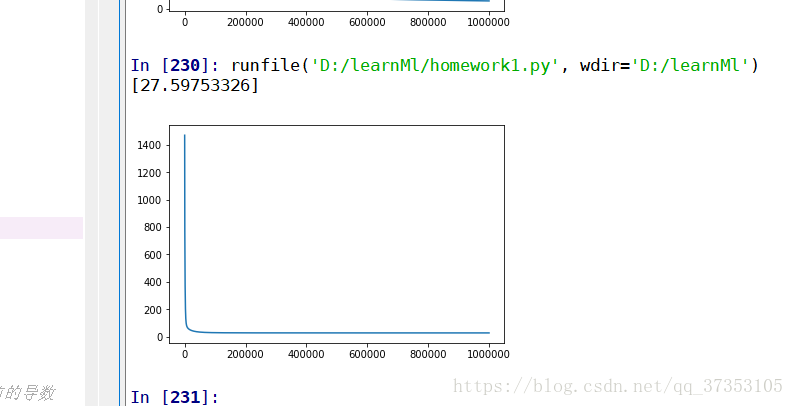
cost.append(sum((y_-xandy[:,9].reshape(240,1))**2)/y_.size)#损失函数
gradient_w=np.dot((y_-xandy[:,9].reshape(240,1)).transpose(),xandy[:,:9])*(2)/y_.size#当前的导数
gradient_b=sum((y_-xandy[:,9].reshape(240,1))*(2))/y_.size#这些都是向量,也看一看成240行1列的矩阵
'''
#这个是adagrad的实现
sum_gradient_w+=gradient_w**2
ada_w=np.sqrt(sum_gradient_w.transpose())
w=w-lr*gradient_w.transpose()/ada_w
sum_gradient_b+=gradient_b**2
ada_b=np.sqrt(sum_gradient_b)
b=b-lr*gradient_b/ada_b
'''
#这个是最简单的
w=w-gradient_w.transpose()*lr
b=b-gradient_b*lr
x.append(j)
#print(cost,x)
plt.figure()
plt.plot(x,cost)
#对比,最后测试一下与测试值的差距
xandy2=[]
i2=1
with open('train.txt') as files:
while True:
line=files.readline()
if line.strip():
if i%18 == 10:
for j in range(2,12):
xandy2.append(float(line.split(',')[j]))
#print(line.split(',')[j],end=' ')#这里只输出pm2.5的值
#pass
#print()#换行
else:
break
i2+=1
xandy2=np.array(xandy)
xandy2=xandy2.reshape(240,10)#改变一下形状
y_=np.dot(xandy2[:,0:9],w)+b
print(sum((y_-xandy2[:,9].reshape(240,1))**2)/y_.size)
(加油,不只是你一个人在学习,)
相关文章
- tcpdump 和 wireshark组合拳,揪出有问题的机器
- 机器学习、数据挖掘、人工智能、统计模型这么多概念有何差异
- 机器学习--详解人脸对齐算法SDM-LBF
- 机器学习入门02 - 深入了解 (Descending into ML)
- 《百面机器学习》拾贝----第五章:非监督学习
- 【NLP】基于机器学习角度谈谈CRF(三)
- 机器学习入门08 - 表示法 (Representation)
- 机器学习笔记 - 什么是联合概率分布?
- 机器学习笔记 - 特殊类型的矩阵和向量
- 机器学习笔记 - Pascal VOC数据集使用FCN语义分割
- 机器学习笔记 - 构建推荐系统(6) 用于协同过滤的 6 种自动编码器
- 机器学习笔记 - keras和预训练词嵌入
- 机器学习——支持向量机SVM在R中的实现
- AI之FL:联邦学习(Federated Learning,分布式机器学习技术)的简介(背景/思想/特点/优势/未来展望/发展史)、系统及其架构、场景应用之详细攻略
- 已解决(机器学习填补数值型缺失值时报错)TypeError: init() got an unexpected keyword argument ‘axis’
- 【千呼万唤】李宏毅《机器学习》国语课程(2022)终于来了
- 机器学习必知必会10大算法
- 机器学习中常用的分类算法总结
- 机器学习: k-means聚类对数据进行预分类
- 【Meetup预告】OpenMLDB+OneFlow:链接特征工程到模型训练,加速机器学习模型开发
- python 机器学习
- 加州理工大学公开课:机器学习与数据挖掘_线性模型(第三个教训)
- RSAC 2022热点议题——勒索软件、AI安全、威胁分析和狩猎,基于机器学习实现内存取证的技术,使用 Volatility 3 + pslist、psscan、pstree、malfind、netscan 等
- InterpretML 微软可解释性机器学习包
- darktrace 亮点是使用的无监督学习(贝叶斯网络、聚类、递归贝叶斯估计)发现未知威胁——使用无人监督 机器学习反而允许系统发现罕见的和以前看不见的威胁,这些威胁本身并不依赖 不完善的训练数据集。 学习正常数据,发现异常!
- Apache Flink vs Apache Spark——感觉二者是互相抄袭啊 看谁的好就抄过来 Flink支持在runtime中的有环数据流,这样表示机器学习算法更有效而且更有效率
- Python3《机器学习实战》学习笔记(一):k-近邻算法(史诗级干货长文)
- 机器学习:特征选择之ChiSqSelector(SparkMLlib中的ChiSqSelector)
- 机器学习之【蒙特卡罗法】
- 机器学习能解决什么问题?
- 机器学习入门(六)神经网络初识
- 机器学习使用记录(A-1):