
随机森林 原理介绍 实战https://zhuanlan.zhihu.com/p/161389525
https://zhuanlan.zhihu.com/p/161389525
ff
随机森林算法介绍
算法介绍:
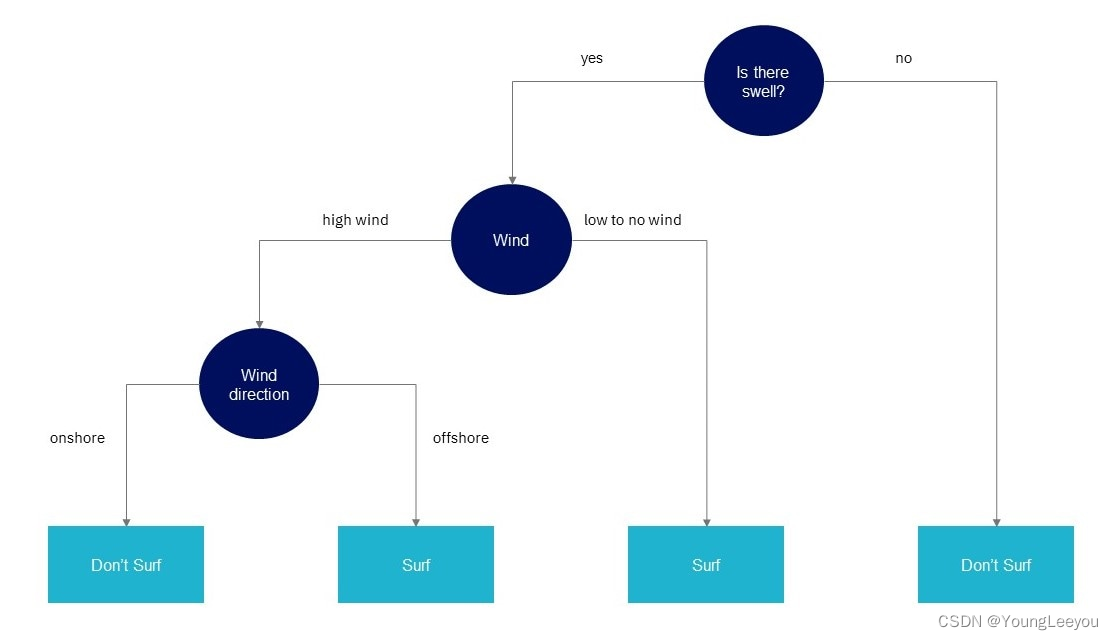
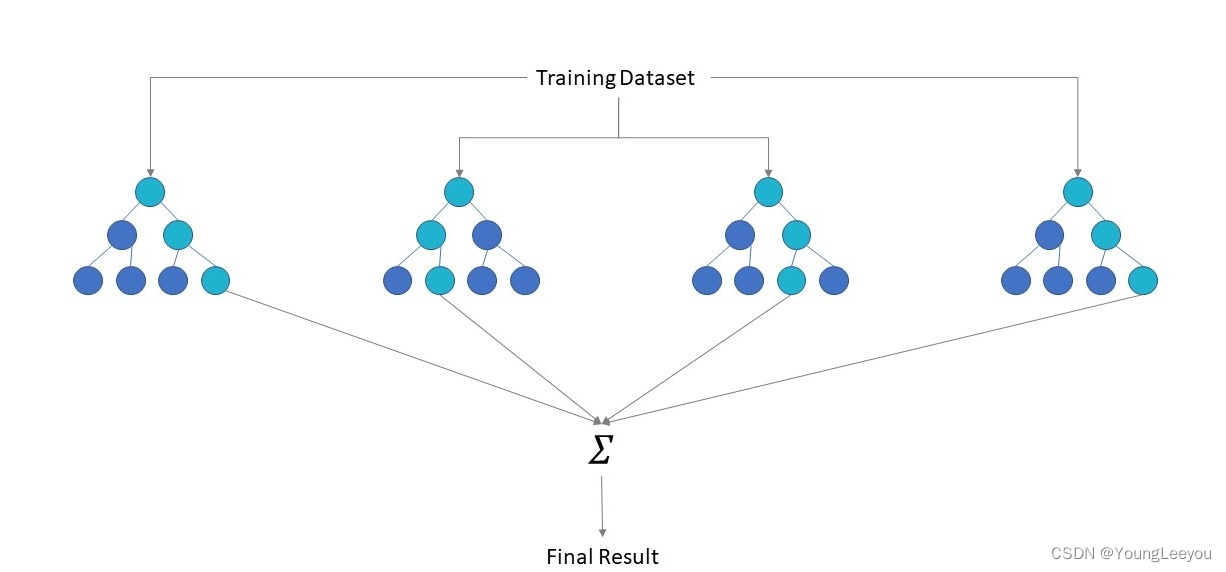
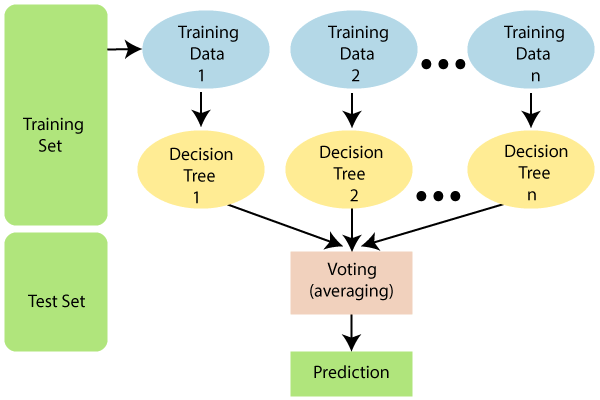
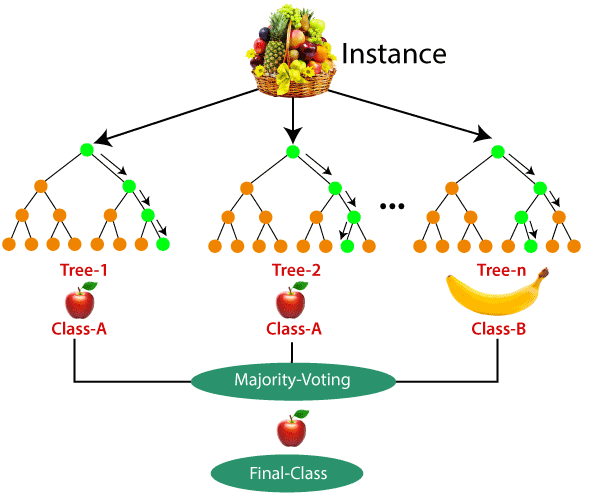
简单的说,随机森林就是用随机的方式建立一个森林,森林里面有很多的决策树,并且每棵树之间是没有关联的。得到一个森林后,当有一个新的样本输入,森林中的每一棵决策树会分别进行一下判断,进行类别归类(针对分类算法),最后比较一下被判定哪一类最多,就预测该样本为哪一类。
随机森林算法有两个主要环节:决策树的生长和投票过程。
决策树生长步骤:
从容量为N的原始训练样本数据中采取放回抽样方式(即bootstrap取样)随机抽取自助样本集,重复k(树的数目为k)次形成一个新的训练集N,以此生成一棵分类树;
每个自助样本集生长为单棵分类树,该自助样本集是单棵分类树的全部训练数据。设有M个输入特征,则在树的每个节点处从M个特征中随机挑选m(m <
M)个特征,按照节点不纯度最小的原则从这m个特征中选出一个特征进行分枝生长,然后再分别递归调用上述过程构造各个分枝,直到这棵树能准确地分类训练集或所有属性都已被使用过。在整个森林的生长过程中m将保持恒定;
分类树为了达到低偏差和高差异而要充分生长,使每个节点的不纯度达到最小,不进行通常的剪枝操作。 投票过程:
随机森林采用Bagging方法生成多个决策树分类器。
基本思想:
给定一个弱学习算法和一个训练集,单个弱学习算法准确率不高,可以视为一个窄领域专家;
将该学习算法使用多次,得出预测函数序列,进行投票,将多个窄领域专家评估结果汇总,最后结果准确率将大幅提升。
随机森林的优点:
可以处理大量的输入变量;
对于很多种资料,可以产生高准确度的分类器;
可以在决定类别时,评估变量的重要性;
在建造森林时,可以在内部对于一般化后的误差产生不偏差的估计;
包含一个好方法可以估计遗失的资料,并且,如果有很大一部分的资料遗失,仍可以维持准确度;
提供一个实验方法,可以去侦测 variable interactions;
对于不平衡的分类资料集来说,可以平衡误差;
计算各例中的亲近度,对于数据挖掘、侦测偏离者(outlier)和将资料视觉化非常有用;
使用上述。可被延伸应用在未标记的资料上,这类资料通常是使用非监督式聚类。也可侦测偏离者和观看资料;
学习过程很快速。
缺点
随机森林已经被证明在某些噪音较大的分类或回归问题上会过拟合;
对于有不同级别的属性的数据,级别划分较多的属性会对随机森林产生更大的影响,所以随机森林在这种数据上产出的属性权值是不可信的。
————————————————
版权声明:本文为CSDN博主「data大柳」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/yawei_liu1688/article/details/78891050
使用randomForest包中的randomForest函数
数据简介
本文数据选择了红酒质量分类数据集,这是一个很经典的数据集,原数据集中“质量”这一变量取值有{3,4,5,6,7,8}。为了实现二分类问题,我们添加一个变量“等级”,并将“质量”为{3,4,5}的观测划分在等级0中,“质量”为{6,7,8}的观测划分在等级1中。
数据下载戳我
因变量:等级
自变量:非挥发性酸性、挥发性酸性、柠檬酸、剩余糖分、氯化物、游离二氧化硫、二氧化硫总量、浓度、pH、硫酸盐、酒精
library(openxlsx)
wine = read.xlsx("C:/Users/Mr.Reliable/Desktop/classification/winequality-red.xlsx")
#将数据集分为训练集和测试集,比例为7:3
train_sub = sample(nrow(wine),7/10*nrow(wine))
train_data = wine[train_sub,]
test_data = wine[-train_sub,]
随机森林的实现
R包下载
install.packages('randomForest')
1
实现随机森林
randomForest函数的重要参数:
参数 意义
formula y yy~x 1 + 1 2 + . . . + x n x_1+1_2+...+x_nx
,确定自变量和因变量
data 使用的数据集
ntree 在森林中树的个数,默认是500
mtry 每棵树使用的特征个数
importance 是否计算变量的特征重要性,默认为False
proximity 是否计算各个观测之间的相似性
randomForest函数的参数非常多,这里只列举了几个常用以及会对模型结果造成影响的参数。其全部参数请参考:随机森林参数
library(pROC) #绘制ROC曲线
library(randomForest)
#数据预处理
train_data$等级 = as.factor(train_data$等级)
test_data$等级 = as.factor(test_data$等级)
wine_randomforest <- randomForest(等级 ~ 非挥发性酸性+挥发性酸性+柠檬酸+
剩余糖分+氯化物+游离二氧化硫+
二氧化硫总量+浓度+pH+硫酸盐+酒精,
data = train_data,
ntree =500,
mtry=3,
importance=TRUE ,
proximity=TRUE)
1
2
3
4
5
6
7
8
9
10
11
12
13
这样我们就实现了随机森林算法
查看变量的重要性
————————————————
版权声明:本文为CSDN博主「weixin_43216017」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43216017/article/details/87887334
相关文章
- mysql mycat读写分离_mycat读写分离原理
- 深入理解推荐系统:阿里DIN原理与实践
- 二维码的秘密(生成原理)
- 用 Charles 断点调试 HTTPS 请求,原理揭秘
- 干货|超详细的常见漏洞原理笔记总结
- 图解 LeakyBucket限流器的实现原理
- MySQL MVCC实现原理
- 装饰器原理剖析详解编程语言
- MySQL主主复制:原理及实现(mysql主主复制原理)
- 主从复制实现Redis高可用的神奇原理(主从复制原理redis)
- 浅析Oracle体系结构的运行原理(oracle体系结构原理)
- 探究Redis集群的底层实现原理(redis集群的底层原理)
- 深入理解Redis集群协议原理(redis 集群原理协议)
- php分页原理详解
- mysql数据库中索引原理分析说明