
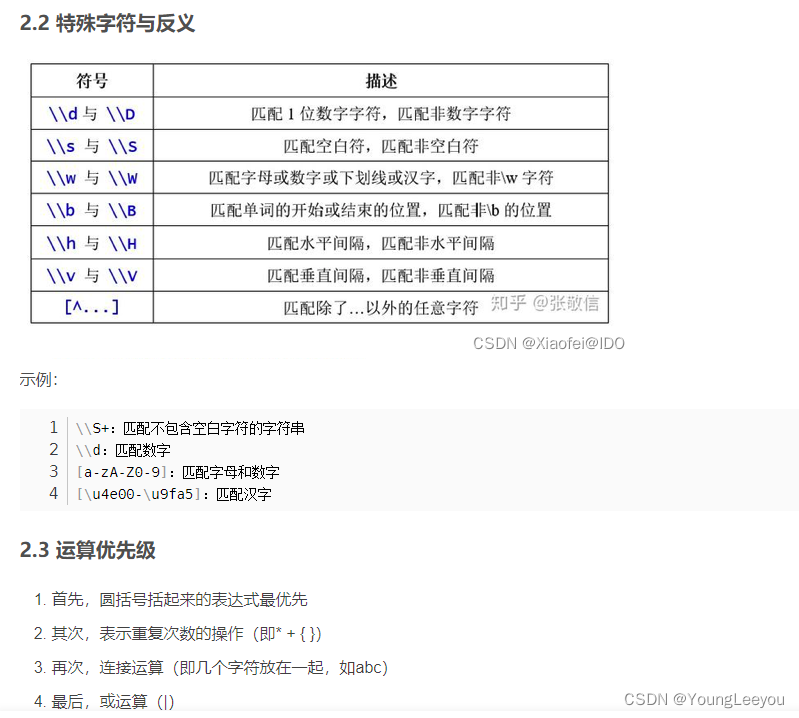
lapply与自定义函数 apply sapply 字符串变成list list变成vector 向量 调用开方括号函数“[”和参数1来获取每个基因的第一个 id r匹配双反斜杠 双斜杠匹配正则。
https://zhuanlan.zhihu.com/p/370586866
https://www.jianshu.com/p/59fb24ca2ea7
Adding gene names Our result table only uses Ensembl gene IDs, but
gene names may be more informative. Bioconductor’s biomaRt package can
help with mapping various ID schemes to each other. First, we split up
the rownames of the results object, which contain ENSEMBL gene ids,
separated by the plus sign, +. The following code then takes the fi rst id for each gene by invoking the open square bracket function “[” and the argument, 1. 然后,下面的代码通过调用开方括号函数“[”和参数1来获取每个基因的第一个 id。
提取每行的行名第一个| 竖线之前的字符串
res$ensembl <- sapply( strsplit( rownames(res),split="\\+" ), "[", 1 )
The following chunk of code uses the ENSEMBL
mart, querying with the ENSEMBL gene id and requesting the Entrez gene
id and HGNC gene symbol.
library( "biomaRt" )
ensembl = useMart( "ensembl", dataset = "hsapiens_gene_ensembl" )
genemap <- getBM( attributes = c("ensembl_gene_id", "entrezgene", "hgnc_symbol"),
filters = "ensembl_gene_id",
values = res$ensembl,
mart = ensembl )
idx <- match( res$ensembl, genemap$ensembl_gene_id )
res$entrez <- genemap$entrezgene[ idx ]
res$hgnc_symbol <- genemap$hgnc_symbol[ idx ]
Now the results have the desired external gene ids:
head(res,4)
## log2 fold change (MAP): treatment DPN vs Control
## Wald test p-value: treatment DPN vs Control
## DataFrame with 4 rows and 9 columns
## baseMean log2FoldChange lfcSE stat pvalue
## <numeric> <numeric> <numeric> <numeric> <numeric>
## ENSG00000000003 616.390 -0.01579 0.0856 -0.1844 0.854
## ENSG00000000005 0.553 -0.00836 0.1703 -0.0491 0.961
## ENSG00000000419 305.400 -0.01647 0.0935 -0.1762 0.860
## ENSG00000000457 184.341 -0.09290 0.1180 -0.7874 0.431
## padj ensembl entrez hgnc_symbol
## <numeric> <character> <integer> <character>
## ENSG00000000003 0.971 ENSG00000000003 7105 TSPAN6
## ENSG00000000005 NA ENSG00000000005 64102 TNMD
## ENSG00000000419 0.973 ENSG00000000419 8813 DPM1
## ENSG00000000457 0.879 ENSG00000000457 57147 SCYL3
在使用apply函数应用自己写的函数提高运算速度的时候,我遇到了问题(其实还是自己apply函数运用的不够熟练)。
使用apply处理一个数据框,我想对每一行进行处理,每一行上使用自己编写的函数进行计算。自己编写的函数如下:
reprocess <- function(x,vars_event,str1){
str3 <- paste("(", vars_event, "=='",
sapply(x[vars_event], as.character), "')",
sep = "", collapse = " & ")
set.seed(1)
xxx <- eval(parse(text=paste("cpquery(fit,event =(",str3,"), evidence = (",str1,"),n=1000000)")))
return(xxx)
}
具体的代码不需要看,它的意思就是我输入一个向量或数组x,还有后面两个参数vars_event和str1,最后会得出一个数值结果。
可以看到,我的reprocess函数,有个参数x,代表我想处理的数据框的每一行,最开始的时候遇到的麻烦就是下面的代码的样子,我不知道x该如何指定了,因为具体到了数据框里的某一行我根本不知道名称,后来参考了一些资料发现,其实这个x可以不需要写的,也就是说,不用在函数中写出来这个参数。
#错误的示范
aabb <- apply(data_event_1,MARGIN = 1,reprocess(x,vars_event,str1))
不写x的话,根据帮助文档,整个函数只写名称就可以,参数逐个放在函数名称的后面,正确的写法如下:
aabb <- apply(data_event_1,MARGIN = 1,reprocess,vars_event,str1)
实战:
#自建函数,只要输入一个长的类似于"ENST00000641515.1|OR4F5-202|OR4F5|2618|protein_coding|"的字符串,
#就可以返回第一个 | 之前的名字
return_desired_position_value<-function(x,myposition){
strsplit(x,split = "|",fixed = T)[[1]][myposition]
}
return_desired_position_value("ENST00000641515.1|OR4F5-202|OR4F5|2618|protein_coding|",4)

dat$name=unlist( lapply(rownames(expr.df),return_desired_position_value,1))
dat$genesymbol=unlist(lapply(rownames(expr.df),return_desired_position_value,6))

https://blog.csdn.net/nixiang_888/article/details/124058558
https://bbs.pinggu.org/thread-3085029-1-1.html 双反斜杠
试了一下,匹配两个反斜杠是没问题的,如下
> str_detect(tmp,"\\\\")
library(stringr)
str_split("NM_001141945 // ACTA2 /// NM_001613 // ACTA2 /// ENST00000458208 // ACTA2 /// ENST00000224784 // ACTA2 /// AY692464 // ACTA2 /// BC093052 // ACTA2 /// BC017554 // ACTA2 /// CR536518 // ACTA2 /// J05192 // ACTA2 /// AK300664 // ACTA2 /// ENST00000415557 // ACTA2 /// ENST00000458159 // ACTA2 /// uc001kfp.1 // ACTA2 /// uc001kfq.1 // ACTA2",
pattern = "//")
str_split( "",pattern = "//")
sapply(str_split( "",pattern = "//"), "[",2)
sapply(str_split(ids_for10739$gene_assignment,pattern = "//"),"[",2)
apply()函数
apply()将数据框或矩阵作为输入,并以矢量,列表或数组形式输出。apply()函数主要用于避免重复使用循环结构。它是所有可以在矩阵上使用的最基本的集合。
此函数接受3个参数:
apply(X, MARGIN, FUN)
-x:数组或矩阵
-MARGIN:取一个介于1到2之间的值或范围,以定义该函数的应用位置:
-MARGIN = 1:对行执行操作 -MARGIN = 2:对列执行操作
-MARGIN = c(1,2)`该操作在行和列上执行
-FUN:告诉应用哪个功能。可以应用平均值,中位数,和,最小值,最大值甚至用户定义的函数等内置函数
最简单的示例是对所有列求和。代码apply(m1,2,sum)将sum函数应用于矩阵5x6,并返回数据集中可访问的每一列的总和。
m1 <- matrix(C<-(1:10),nrow=5, ncol=6)
m1
a_m1 <- apply(m1, 2, sum)
a_m1

链接:https://www.jianshu.com/p/59fb24ca2ea7
lapply()函数
lapply()函数可用于对列表对象执行操作,并返回与原始集合长度相同的列表对象。lappy()返回一个长度与输入列表对象相似的列表,其每个元素都是将FUN应用于列表的相应元素的结果。lapply()将列表,向量或数据框作为输入,并在列表中给出输出。
lapply(X, FUN)
Arguments:
-X: A vector or an object
-FUN: Function applied to each element of x
lapply()中的l代表列表。lapply()和apply()之间的区别在于输出返回之间。
lapply()的输出是一个列表。lapply()可以用于其他对象,例如数据框和列表。
lapply()函数不需要MARGIN。
一个非常简单的示例是使用tolower函数将矩阵的字符串值更改为小写。我们用著名电影的名称构造一个矩阵。名称为大写形式。
movies <- c("SPYDERMAN","BATMAN","VERTIGO","CHINATOWN")
movies_lower <-lapply(movies, tolower)
str(movies_lower)
输出:
## List of 4
## $:chr"spyderman"
## $:chr"batman"
## $:chr"vertigo"
## $:chr"chinatown"
我们可以使用unlist()将列表转换为向量。
films_lower <- unlist(lapply(movies,tolower))
str(movies_lower)
输出:
## chr [1:4] "spyderman" "batman" "vertigo" "chinatown"
sapply()函数
sapply()函数将列表,向量或数据帧作为输入,并以向量或矩阵形式输出。它对列表对象的操作很有用,并返回与原始集合长度相同的列表对象。sapply()函数执行的功能与lapply()函数相同,但返回一个向量。
sapply(X, FUN)
Arguments:
-X: A vector or an object
-FUN: Function applied to each element of x
我们可以从汽车数据集中测量汽车的最小速度和停车距离。
dt <- cars
lmn_cars <- lapply(dt, min)
smn_cars <- sapply(dt, min)
lmn_cars
smn_cars
输出:
## $speed
## [1] 4
## $ dist
## [1] 2
## speed dist
## 4 2
我们可以在lapply()或sapply()中使用用户内置函数。我们创建一个名为avg的函数来计算向量最小值和最大值的平均值。
avg <- function(x) {
( min(x) + max(x) ) / 2}
fcars <- sapply(dt, avg)
fcars
输出量
## speed dist
## 14.5 61.0
**sapply()函数在返回的输出中比lapply()更有效,因为sapply()将值直接存储到向量中。**在下一个示例中,我们将看到情况并非总是如此。
下表总结了apply(),sapply()和lapply()之间的区别:
Function Arguments Objective Input Output
apply apply(x, MARGIN, FUN) Apply a function to the rows or columns or both Data frame or matrix vector, list, array
lapply lapply(X, FUN) Apply a function to all the elements of the input List, vector or data frame list
sapply sappy(X FUN) Apply a function to all the elements of the input List, vector or data frame vector or matrix
切片矢量
我们可以使用lapply()或sapply()互换来切片数据框。我们创建一个函数below_average(),该函数接受数值的向量,并返回仅包含严格高于平均值的值的向量。我们将两个结果与 identical() 函数进行比较。
below_ave <- function(x) {
ave <- mean(x)
return(x[x > ave])
}
dt_s <- sapply(dt, below_ave)
dt_l <- lapply(dt, below_ave)
identical(dt_s, dt_l)
输出:
## [1] TRUE
stringr包里专用于处理字符串向量的函数,这些函数有一个共同特点,str开头。
1.1 检测字符串长度:str_length(x)
1.2 字符串拆分:str_split()
1.3 按位置提取字符串:str_sub()
1.4 字符检测:str_detect(x,"h"):重点掌握用法
1.5 字符串替换:str_replace()/str_replace_all()
1.6 字符删除:str_remove()/str_remove_all()
相关文章
- python中列表(list)函数及使用
- List集合
- java8 list.sort 排序
- java中map转string_字符串转list集合
- list,tensor,numpy相互转化
- java中两个list对象取交集、差集
- 故障分析 | Cassandra 用户信息 list Error
- List<类型1>转成List<类型2>的LIst类型转换工具类
- 【Flutter】Dart 数据类型 List 集合类型 ( 定义集合 | 初始化 | 泛型用法 | 初始化后添加元素 | 集合生成函数 | 集合遍历 )
- 【Linux 内核 内存管理】RCU 机制 ③ ( RCU 模式下添加链表项 list_add_rcu 函数 | RCU 模式下删除链表项 list_del_rcu 函数 )
- ORA-32038: number of WITH clause column names does not match number of elements in select list ORACLE 报错 故障修复 远程处理
- ORA-01470: In-list iteration does not support mixed operators ORACLE 报错 故障修复 远程处理
- Python list列表详解
- 深入浅出 Redis List 查询(redislist查询)
- java8 list和map的forEach详解编程语言
- Python list列表的相关函数
- Java List.get()方法:获取列表指定位置的元素
- 利用Redis构建新的List存储方式(redis存储list)
- 类型探索Redis中List数据结构的优势(redis中的list)
- 性能优化提升Redis List性能的简单方法(redis的list)
- 的优势玩转Redis:List缓存的有点优势(redis 缓存list)
- 监测redis List动态稳定性突破极限(监听redis list)
- 警惕Redis List被空出(redis里list为空)
- ajax+json+Struts2实现list传递实例讲解
- Python列表list数组array用法实例解析