
Kubernetes APIServer 限流策略

之前说过了,认证,鉴权,准入,这三个重要的环节。到此为止k8s apiserver就已经将请求继续往后传递了,作为rest服务器,它一定要有自我保护机制,这个自我保护的机制最核心的就是限流。
作为web服务器,处理能力是有上限的,不能无休止的接受用户的请求,所以要做一个约定说这边能够接受多少请求。
下面来看看限流有哪些传统的方法。
计数器固定窗口算法
原理就是对一段固定时间窗口内的请求进行计数,如果请求数超过了阈值,则舍弃该请求;如果没有达到设定的阈值,则接受该请求,且计数加1。当时间窗口结束时,重置计数器为0。

就是将时间切为一个一个的窗口,比如一分钟一个窗口,然后限制,在这个窗口期间最多能够接受多少请求,当然按照小时和天计算都是很有可能的。这样就能够限制单位时间的请求数。
这个实现简单,能够满足我最初始的需求。
我这个时间窗口可能非常大,限流在这个时间窗口之内,其实限流是可以达到目的的,但是还有极端情况,比如两个窗口交替时间窗口这一块,如果所有的请求都集中在前一个窗口结束,以及后一个窗口开始的这一块,是不是在那个单位周期内,我的整个系统其实在接受两倍的请求数量。
这个限流其实是有漏洞的,为了解决这个问题,如下。
计数器滑动窗口算法
在固定窗口的基础上,将一个计时窗口分成了若干个小窗口,然后每个小窗口维护一个独立的计数器。
当请求的时间大于当前窗口的最大时间时,则将计时窗口向前平移一个小窗口。
平移时,将第一个小窗口的数据丢弃,然后将第二个小窗口设置为第一个小窗口,同时在最后面新增一个小窗口,将新的请求放在新增的小窗口中。
同时要保证整个窗口中所有小窗口的请求数目之和不能超过设定的阈值。

既然你一个时间单位,比如1分钟,1个小时,我怕所有的请求都集中在窗口切换的时间,我能不能通过更加精细的,通过精细粒度的时间控制来使得限流更加平滑。
这就涉及到了一个滑动窗口。也就是将大周期切成小框,限流还是按照大周期去框的,比如说我是一分钟的限流,但是这一分钟我可以切位60个1s,然后60个1s就组成了一分钟的一个窗口期。
然后我每一秒让整个窗口向后滑动一格,也就是限流永远在框60秒的单位。所以这样就不会有大的这种窗口期切换过程当中产生了一个超额的请求将我系统压死。
这样其实就是将大周期切分为小周期,但是还有一些问题,在小窗口期间去做切换还可能有高峰,所以在一定程度上面以及解决了限流的不少问题,但是它依然不够精确。
所以一直在探索,有没有更加平滑的方式来解决限流的问题呢?如下:
漏斗算法
漏斗算法的原理也很容易理解。请求来了之后会首先进到漏斗里,然后漏斗以恒定的速率将请求流出进行处理,从而起到平滑流量的作用。
当请求的流量过大时,漏斗达到最大容量时会溢出,此时请求被丢弃。
在系统看来,请求永远是以平滑的传输速率过来,从而起到了保护系统的作用。
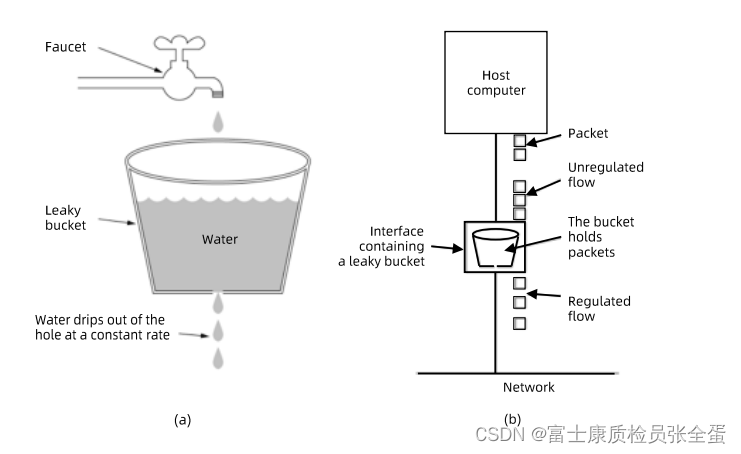
比较常用的算法就是漏斗算法,所有的请求在被系统接受之前,是要经过一个漏斗的,下面有个口子是要往外露数据的,或者漏请求的,我这个漏请求的速率是恒定的,比如每秒1次,每秒2次。
你request如果过来都无所谓,只要漏斗满了,你还要发请求就丢弃。server这端如果你请求很多,它永远按照固定的速率往外流出,所以server接受到的请求就是你设定好的固定速率。
令牌桶算法
令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。在令牌桶算法中,存在一个令牌桶,算法中存在一种机制以恒定的速率向令牌桶中放入令牌。令牌桶也有一定的容量,如果满了令牌就无法放进去了。
当请求来时,会首先到令牌桶中去拿令牌,如果拿到了令牌,则该请求会被处理,并消耗掉拿到的令牌;
如果令牌桶为空,则该请求会被丢弃。
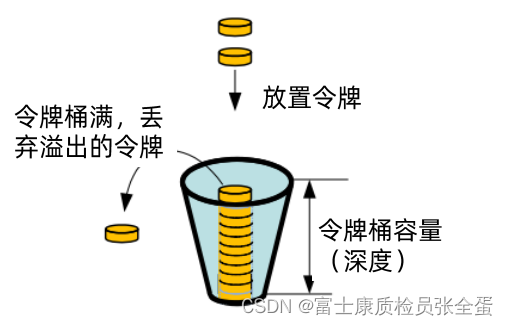
更加常见的是令牌桶的算法,这种算法其实在限流的时候是最常用的一种算法。
漏斗算法它的问题是什么?我的速率是恒定的,就很难去处理这种突然的有个burst,比如大部分时间恒定,比如每秒1个,然后突然有一会,是1秒钟来了两个,那么多的这个请求在漏斗算法里面就丢弃了。
你既然丢掉,那么客户端就失败了,那么系统的健壮性能不能更加强一些,这种突发的超量请求我也能够做一定的容忍,这就是令牌桶的算法。
令牌桶算法就在漏斗算法上面做了一定的改进,它除了可以以固定速率去处理请求,还能支持一定的突发流量。
怎么实现的呢?首先假设有一个桶,这个桶里面它有深度,深度就是可以放的令牌的数量。假设说是10,那么所有请求过来的时候,首先要去桶里面拿令牌,只有拿到了令牌这个请求才能处理,如果拿不到令牌,这个请求就是要被丢弃的。
限速怎么做?就是说,请求过来,先去桶里面拿令牌,拿到令牌以后这个请求就会被处理,桶里面的令牌就少了一个,在另外一个层面,会有一个后台的进程去按照固定的速率去补充这个桶子。
假设说request过来的频率是1s一个,补充桶的频率也是1s一个,那么现在达到的平衡,往桶里面放令牌的速度和从桶里面拿令牌的速度就达到了一个平衡,这个时候有突发流量了,突然多来了9个,这个时候桶里面还有富余的9个令牌,所以这9个都能拿到有效的令牌,这9个请求都被发送到后端了,它可以被正确处理,如果还有新的请求过来,桶里面已经空了,新的令牌补充进来之前,你这个请求没有办法被处理,就有可能被丢弃。
这个时候我请求没有那么多了,那么我后台固定填充令牌的频率还在,它会慢慢的再将桶装满。
所以通过这种方式我们就有一定的速率来控制请求,同时这个桶里面装着一些有效预备充好的有效令牌,使得我整个限速能够有一个应对突发请求的这样一个能力。
APIServer 中的限流
max-requests-inflight∶在给定时间内的最大non-mutating 请求数
max-mutating-requests-inflight∶在给定时间内的最大mutating请求数,调整apiserver 的流控 qos。
代码∶staging/src/k8s.io/apiserver/pkg/server/filters/maxinflight.go:WithMaxInFlightLimit()
apiserver要做自我保护,也有自己的限流机制。通过WithMaxInFlightLimit()函数来做整体的限流。
所以apiserver里面提供了两个参数,让你去控制它的限流策略。第一个参数max-requests-inflight,inflight就是apiserver从接受一个请求到一直将这个请求处理完,那所有apiserver已经接受但是但是没有处理完的请求都叫inflight,这个参数max-requests-inflight也就是说它能够处理的并发请求最大是多少。
max-mutating-requests-inflight:比上面来说就多了一个mutating,mutating就是对k8s对象做变更的时候,包括创建,删除,修改(update patch),所有这些操作就是mutating操作,max-requests-inflight其实就是限制了总的并发数,max-mutating-requests-inflight限制了写操作的变更数,因为写操作对etcd和对apiserver都有额外的压力,所以写操作会做额外的控制。

默认情况下它们值分别为400 200,随着集群的量不断的增加,有一些基于压力测试所测出来的一些推荐的值。
如果集群范围是1000-3000,那么全部的并发设置为1500,然后写并发设置为500,如果节点数大于3000,值调整为上图。
当然根据业务场景而定,因为虽然集群一样大,里面建立了多少pod,pod变更频率不一样,怎么做这个事情还得通过压力测试来看如何调节这个参数来优化集群。
| --max-mutating-requests-inflight int Default: 200 | |
| This and --max-requests-inflight are summed to determine the server's total concurrency limit (which must be positive) if --enable-priority-and-fairness is true. Otherwise, this flag limits the maximum number of mutating requests in flight, or a zero value disables the limit completely. | |
| --max-requests-inflight int Default: 400 | |
| This and --max-mutating-requests-inflight are summed to determine the server's total concurrency limit (which must be positive) if --enable-priority-and-fairness is true. Otherwise, this flag limits the maximum number of non-mutating requests in flight, or a zero value disables the limit completely. | |
传统限流方法的局限性粒度粗
刚才所说的这些限流算法都是全局限流,只能给web server限制一个限流数字,这种限流的粒度就很粗,然后它又是单队列的,它会带来一些问题。
比如突然有一个人发起无数请求,这些请求一个人就可以将apiserver打死,然后它阻塞了其他的所有的请求。因为是一个共享集群,这个共享集群里面有无数的用户,然后无数的组件,如果有一个组件出现了问题,比如他发了1w个请求到apiserver,这些请求就将apiserver堵死了,请求请求只能在后面排队。
所以如何对apiserver限流做优化呢?那么就需要考虑细粒度的限流,我们不能通过单队列,单限流去处理这种请求。我们要避免一个用户将整个集群拖死这种情况。
粒度粗
- 无法为不同用户,不同场景设置不通的限流.
单队列
- 共享限流窗口/桶,一个坏用户可能会将整个系统堵塞,其他正常用户的请求无法被及时处理。
不公平
- 正常用户的请求会被排到队尾,无法及时处理而饿死。
无优先级
- 重要的系统指令一并被限流,系统故障难以恢复。
API Priority and Fairness
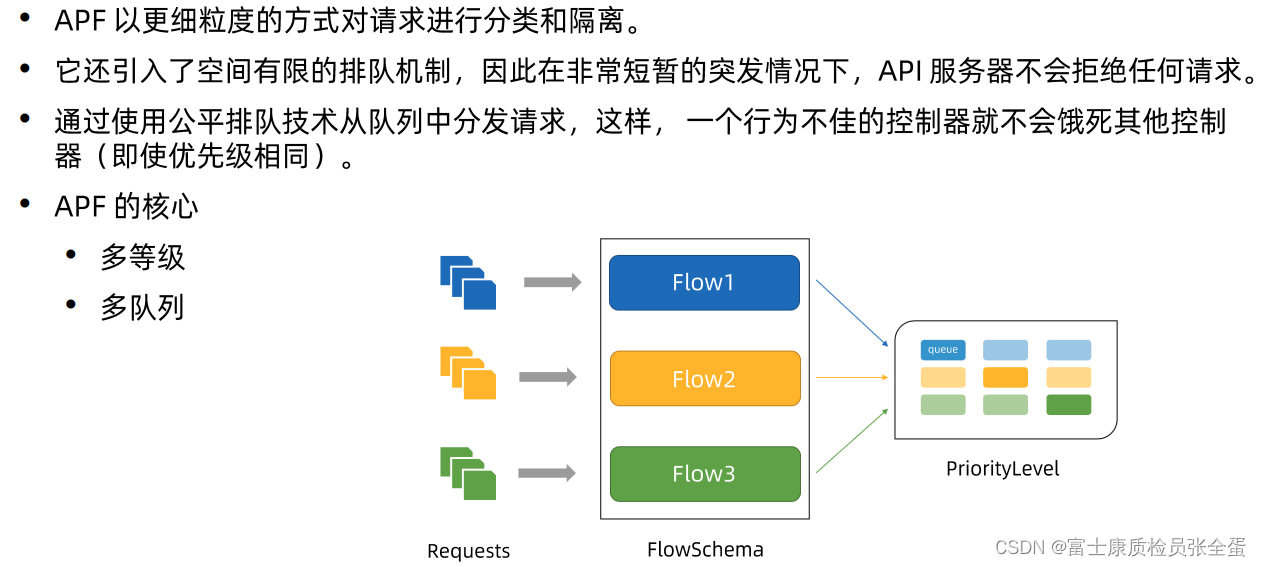
APIServer提供了新的一种精细化限流的方式叫 API Priority and Fairness,或者叫APF,这个就解决了上面阐述的现象。
多等级
APF它的核心就是多等级,它将整个集群分为了不同的限流等级,会把相近用户的请求分到不同等级里面,比如和系统相关,那么优先级可能比较高,普通用户的优先级可能比较低。
我不同用户,不同场景,不同的组件我用不同的等级队列 Flow1,Flow2.........,每一个等级队列它限流完全不是一个,就是我有多个通道,不同通道它的限流机制是一样的,但是它限流不是共享单一队列的,它们完全是独立的限流队列,这样一个队列阻塞了,那么其他的队列还是通的。
这样就可以有效的防止一些初级的用户突然发起大量的请求,把系统给搞死了。
上面是多等级的概念。
多队列
其次还有多队列的概念,在每个等级,如果也是一个单队列,假设flow1对应了一个队列,那么一样会有问题,万一flow1里面有坏用户发了很多的请求,那么整个flow流里面,所有的请求都在后面排了,它的破坏力就很大的,那么APF里面就引入了多队列的概念,就是在这个flow里面提供多个队列,即使是同一个flow,即使我是系统组件发的请求,不同的组件发送到的队列也可能是不一样的。
你有一个坏的用户造成了大量的请求堆积,那么它也只塞一个队列,如果你的请求是在别的队列里面,那也是不影响的。
也就是通过多等级,多队列的方式,来实现精细化的限流。
FlowSchema,PriorityLevelConfiguration
- APF的实现依赖两个非常重要的资源 FlowSchema,PriorityLevelConfiguration。
- APF对请求进行更细粒度的分类,每一个请求分类对应一个FlowSchema(FS)。
- FS 内的请求又会根据 distinguisher进一步划分为不同的Flow。
- FS会设置一个优先级(Priority Level,PL),不同优先级的并发资源是隔离的。所以不同优先级的资源不会相互排挤。特定优先级的请求可以被高优处理。
它具体的实现,k8s主要提供了两个对象FlowSchema,PriorityLevelConfiguration,FlowSchema主要定义不同的流的,针对这些流的定义做一些约束。包含不同的请求应该怎么样去确定它属于一个流还是多个流,包含一个流对应它队列的优先级队列是什么。
PriorityLevelConfiguration里面确定了具体的Priority应该如何限流的这样一些细节。
PriorityLevelConfiguration QueueSet
- 一个PL可以对应多个FS,PL中维护了一个QueueSet,用于缓存不能及时处理的请求,请求不会因为超出PL的并发限制而被丢弃。
priority是一个一对多的关系,prioritylevel是可以复用的,一个flowschema可以指定一个prioritylevel,但是prioritylevel可以服务多个flowschema。
prioritylevel主要做什么呢?它维护了一个queueset,所谓的queueset就是队列的集合。
生产者消费者模型,生产者和消费者之间可以有queue,一边往里面塞,一边往里面取,那么你的queue被某些坏的或者不太好的程序占满了,那么整个队列都是非常忙的,那么真正处理请求就没有办法得到处理。
那么限流其实是一样的,那么怎么解决这个问题,它提供了一个多队列的概念,就是如果我有一个queueset,queueset针对每一个级别限流的话,我不是一个队列,我是多个队列,如果有一个坏的请求过来,它所有请求最终对应的是这个队列里面一个局部的队列组合,就是queueset里面局部的q对吧,只会将那些queue占满,然后其他的同一个flow里面其他的queue是不受影响的。同一个priority里面其他队列是不受影响的。
所以这样就有效的隔离了坏用户产生的破坏性。
- FS中的每个Flow通过shuffle sharding算法从QueueSet选取特定的queues缓存请求。
- 每次从QueueSet中取请求执行时,会先应用fair queuing算法从QueueSet中选中一个queue,然后从这个queue 中取出oldest 请求执行。所以即使是同一个PL内的请求,也不会出现一个Flow内的请求一直占用资源的不公平现象。
概念
- 传入的请求通过FlowSchema按照其属性分类,并分配优先级。
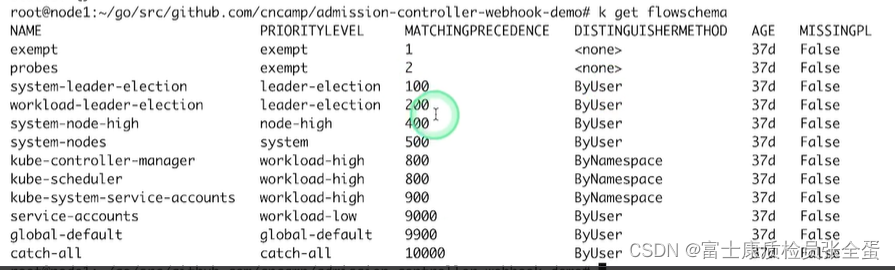
这个是kubernetes1.22版本自带的,也就是你安装好集群之后,这些flowschema就已经定义好了。可以看到每个flowschema都有其对应的优先级,所以任何请求过来之后它都会从上到下去匹配,优先级数字越小的越优先匹配(第三列),它就通过优先级来决定它的限流策略是什么。
每一个优先级维护自己的并发限制,这样不同的优先级它的限流是隔离的,不同的优先级不会相互饿死,我高优出现问题不会饿死低优的,低优出现问题不会饿死高优的,因为大家是不同的限流队列,这样的话我限制了问题的影响。
-
每个优先级维护自定义的并发限制,加强了隔离度,这样不同优先级的请求,就不会相互饿死。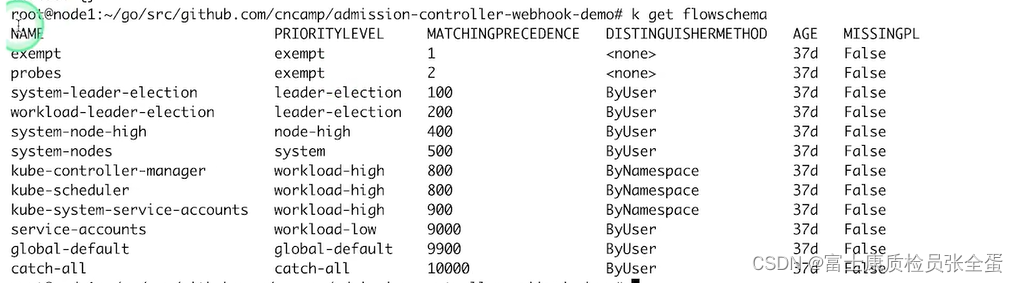
- 在同一个优先级内,公平排队算法可以防止来自不同flow的请求相互饿死。
- 该算法将请求排队,通过排队机制,防止在平均负载较低时,通信量突增而导致请求失败。
优先级

总体的并发依然受到这两个参数的影响,过了最顶层的这种整体并发限制之后,再去看这些细的策略,也就是精细化限流策略是和总的限流策略是并行的,它们是一起去做限流的。
排队

这里面就涉及到排队的问题了,就是在同一个优先级内也会存在大量不同源的flowschema,就会出现一种情况,对于同一个优先级,同一个限流队列里面,如果有一个请求,也就是坏用户产生了大量的请求,如果我们不做一些处理的话,它会将这个队列占满,饿死其他的请求,怎么去解决这样一个问题呢?
就是prioritylevelconfiguration去实现的。

每个请求都会被分到某个流里面去,第一按照你的请求过来,我先按照优先级来匹配,这个请求落到了哪个flowschema。

前面两个flowschema,它们的prioritylevel是exempt,也就是这两类是不限流的,然后接下来就是有各种各样的限流策略,所以最上面优先级最高,所以它会先去看你的请求属于不属于上两类,属于就不限流。
然后就是系统级别的leaderelection,它会按照user去分,也就是一个请求它按照流量特征来具体的和哪个flowschema去匹配。
和flowschema匹配完了之后,去看请求和namespace相关的还是和user相关的。
如果是按照namspace,那么不同的namespace过来的请求就是不同的flow。
这样的话就是每个请求都和一个flow产生的绑定关系,分到了流之后呢,这个请求就会被分配到对应的队列里面,这个队列如何分配呢?
kube-apiserver这里提供了混洗分片技术,就是我这个对应的flow里面可能会有很多的队列,可能有50个队列,flowschema它对应的是queueset,它是多个队列。
比如创建了50个队列,但是针对任何一条flow,我最多允许你进几个队列,它就是要洗牌,你的请求不能进所有的队列,否则有一个坏的场景,那么50个队列都被被你撑爆,所以就会去限制说flow最多只能去4个队列,那么它就会去做一个混洗分片,从50个队列里选出4个队列让你放。
所以如果你的flow有问题最多4个有问题,还有46个是活的。所以整个flow大的影响是没有的,只不过和你共享同一个对列的往往都是你自己,要不来自同一个namespace,要么来自于同一个用户,这样就将影响限制到局部了,其他人不受影响。
豁免请求
某些特别重要的请求不受制于此特性施加的任何限制。这些豁免可防止不当的流控配置完全禁用
API服务器。
豁免请求就是不受到任何的限制,最上面两个是豁免的,不需要限流,因为它是最重要的请求。

默认配置


安装完k8s,它就会为我们创建默认的flowschema,不同的版本,它的flowschema可能不一样。
在1.22可以看到,最上面可能和probe相关,探活要最高优先级,不限流。然后是leaderelection,节点相关的,控制平面相关的,然后serviceaccount相关的,然后不同的用户,最后一个兜底的。
上面就是它默认为我们创建的一些flowschema。
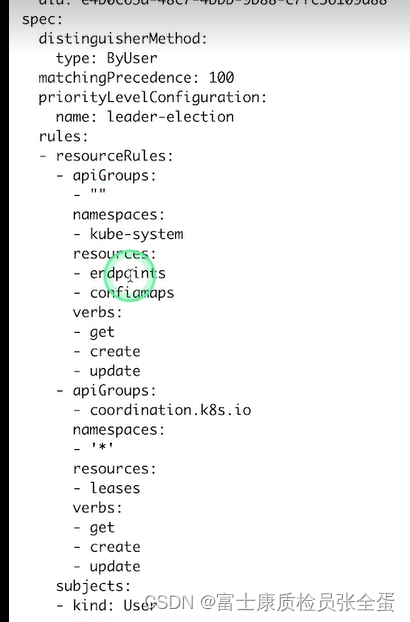
我是按照用户去分不同的流的,其次我的优先级是什么,之后对应的PriorityLevelConfiguration是什么?最后rule定义了限流的策略是什么。
针对哪些对象什么样的方法去做限流。
flowschema的意思是当apiserver接收到请求之后,它要去判断是不是这些对象的这些请求。如果是这些请求,你们你就落到了这个flowschema上面,然后按照不同的用户,或者不同的namespace,将其分到不同的流里面去,每个流会有对应的PriorityLevelConfiguration,这个PriorityLevelConfiguration就是下面要说的。
PriorityLevelConfiguration
一个PriorityLevelConfiguration表示单个隔离类型。
每个PriorityLevelConfigurations对未完成的请求数有各自的限制,对排队中的请求数也有限制。

20就是这个flow里面允许的并发请求,最多可以支持20个。
下面就是和多队列相关了,我这个PriorityLevelConfiguration,就是这个优先级里面我有128个队列,每个队列里面最多50个对象,然后针对每个flow,它最多可以放到6个队列里面,这样我就可以限制住你产生的破坏最多一个PriorityLevelConfiguration里面6/128个队列,这样再怎么坏的用户也不会将整个apiserver拖死。
flowschema
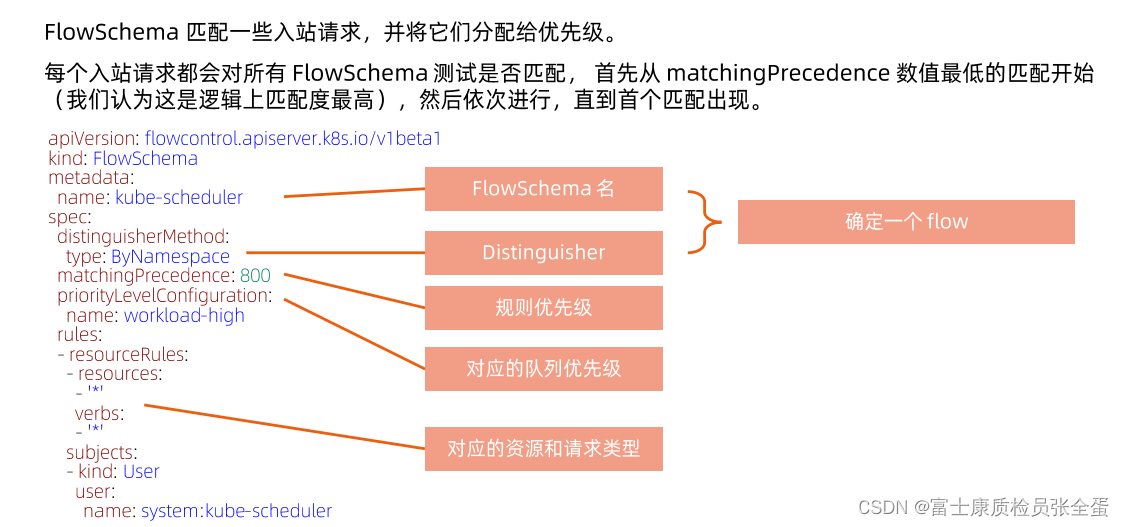
第一个名字是什么,其次distinguish就是怎么去区分不同的流,flowschema+distinguish确定唯一的flow,然后接下来优先级规则,之后对应的优先级队列,以及后面对应的资源和请求类型。
上面就是定义什么样的对象来触发这个限流策略。
调试

一般发现限流出问题了,比如很多队列堆积了,这个时候我们可以dump_request,来看当前集群里面有哪些request在堆积,因为现在的集群比较小,dump看不到什么信息。
这就是要做精细化限流要使用到的调试工具。
在生产化落地的时候要按照自己的实际情况,比如集群的规模多大,用户行为怎么样,在集群上部署的pod特征是怎么样,你可能要去调一下PriorityLevel和APF。
其实没有捷径,通过模拟的作业,模拟集群规模来做一些测试,然后去寻找apiserver会被影响的哪些点,并且去做一些参数的调整。
总结
apiserver有总的流控策略,就是max-inflight,max-mutating-inflight,通过这两个来配置总共可以接受的并发请求以及总共的变更请求。
然后通过APF来控制精细化的限流,这样将可能出现的,潜在的对APIserver影响控制到局部。
通过多优先级多队列的机制来达到这个目标的。
相关文章
- Kubernetes详解(四十二)——Secret应用
- 【云原生 | Kubernetes 系列】--Gitops持续交付 CD Push Pipeline实现
- 【云原生 | Kubernetes 系列】--Gitops持续交付 ArgoCD自动同步策略
- 【云原生 | Kubernetes 系列】---Ceph集群安装部署
- 没有Kubernetes怎么玩Dapr?
- 三小时学会Kubernetes:容器编排详细指南
- Kubeadm 部署kubernetes
- y39.第三章 Kubernetes从入门到精通 -- k8s 资源对象(十二)
- y30.第三章 Kubernetes从入门到精通 -- kubernets介绍(三)
- y64.第三章 Kubernetes从入门到精通 -- k8s资源限制(三七)
- kubernetes搭建jenkins
- Kubernetes集群Pod资源node主机定向调度策略(十五)
- Kubernetes集群Pod资源调度策略概念(十四)
- Kubernetes集群Pod资源重启策略配置(十三)
- Kubernetes web界面kubernetes-dashboard安装【h】
- 【云原生 • Kubernetes】kubernetes 核心技术 - RC、Replica Set 和 Deployment
- 【云原生 • Kubernetes】kubernetes 核心技术 - Pod
- Kubernetes 深入理解kubernetes(一)
- Kubernetes 默认调度器简介
- 这些用来审计 Kubernetes RBAC 策略的方法你都见过吗?
- Kubernetes ingress 证书更新
- 【云原生 | Kubernetes 系列】--Gitops持续交付 ArgoCD自动同步策略
- Kubernetes中的网络策略
- Kubernetes几种常用的存储卷类型
- a37.ansible 生产实战案例 -- 基于二进制包安装kubernetes v1.23 -- 集群部署(一)
- Kubernetes部署_使用kubernetes部署Mysql主从结构(Kubernetes工作实践类)