
论文阅读:Self-Attention Generative Adversarial Networks
论文地址:https://arxiv.org/abs/1805.08318
发表时间:2019
项目地址:https://github.com/heykeetae/Self-Attention-GAN
在本文中,我们提出了自注意生成对抗网络(SAGAN),它允许对图像生成任务进行注意驱动的长期依赖建模。传统的卷积GANs只在低分辨率特征图中生成高分辨率的细节。在SAGAN中,细节可以使用来自所有特征位置的线索来生成。此外,鉴别器还可以检查图像远处部分的高级的特征是否相互一致。此外,最近的研究表明,generator反射会影响GAN的性能。利用这一见解,我们将谱归一化应用于GAN生成器,并发现这动态的改善了训练。提出的SAGAN比之前的工作1表现更好,在具有挑战性的ImageNet数据集上,将最佳发布的Inception分数从36.8提高到52.52,并将 Fr´echet Inception距离从27.62降低到18.65。注意层的可视化显示,生成器利用了与物体形状相对应的邻域,而不是固定形状的局部区域。
1. Introduction
图像合成是计算机视觉中的一个重要问题。随着生成对抗网络(GANs)的出现,在这一方向上取得了显著进展(Goodfelletal.,2014),尽管仍有许多悬而未决的问题(Odena,2019)。基于深度卷积网络的GANs(Radford et al.,2016;Karras et al.,2018;Zhang et al.)尤其成功。仔细的检查这些来自模型生成的样本,我们可以观察到,卷积GANs(Odena et al.,2017;Miyato et al.,2018;在多类数据集上训练时,很难建模一些图像类(Russakovsky et al., 2015)。例如,虽然最先进的ImageNet干模型(Miyato & Koyama,2018)擅长合成图像类与一些结构约束(例如,海洋、天空和景观类,区分纹理而不是几何),它未能捕捉几何或结构模式一致发生在一些类(例如,狗通常与现实的毛皮纹理但没有明确定义单独的脚)。一种可能的解释是,以前的模型在很大程度上依赖于卷积来建模不同图像区域之间的依赖关系。由于卷积算子有一个局部的接受域,因此远程依赖关系只能在经过几个卷积层后才能进行处理。这可能会阻碍学习长期依赖的各种原因:一个小模型可能无法代表它们,优化算法可能难以发现参数值,仔细协调多层捕获这些依赖,这些参数化可能在统计上脆弱和容易失败时应用于以前未见的输入。增加卷积核的大小可以增加网络的表示能力,但这样做也会失去通过使用局部卷积结构所获得的计算和统计效率。Self-attention (Cheng et al., 2016; Parikh et al.,2016; Vaswani et al., 2017), 在模拟长期依赖的能力与计算和的统计效率之间表现出更好的平衡。自我注意模块将一个位置的响应作为所有位置特征的加权和计算,其中权重或注意向量只计算很小的计算成本。
在这项工作中,我们提出了自注意生成对抗网络(SAGANs),它在卷积的自注意生成对抗网络中引入了一种自注意机制。自我注意模块是对卷积的互补模块,并帮助建模跨图像区域的长期、多层次的依赖关系。通过自我注意,生成器可以绘制图像,其中每个位置的细节与图像的遥远部分的细节仔细协调。此外,辨别器可以精准的强迫约束全局图像结构的复杂几何结构。
除了自我注意,我们还结合了网络调节与GAN表现的见解。(Odenaetal.,2018)的工作表明,条件良好的生成器往往表现得更好。我们建议使用以前只应用于鉴别器的谱归一化技术,加强GAN生成器的良好调节(Miyatoetal.,2018)。
我们在ImageNet数据集上进行了广泛的实验,以验证所提出的自注意机制和稳定技术的有效性。SAGAN在图像合成方面的表现从36.8提高到52.52,Fr´echet Inception从27.62提高到18.62.5。注意层的可视化显示,生成器利用了与物体形状相对应的邻域,而不是固定形状的局部区域。我们的代码在https://github.com/brain-research/self-attention-gan .
2. Related Work
Generative Adversarial Networks. GANs在各种图像生成任务中取得了巨大成功,包括图像到图像的翻译、图像超分辨率和文本到图像的合成。尽管取得了这些成功,但已知GANs的训练不稳定,并且对超参数的选择敏感。有几项工作试图通过设计新的网络结构、修改学习目标和动态、添加正则化方法和引入启发式技巧来稳定GAN训练动态并改善样本多样性。最近,Miyato et al.提出限制鉴别器中权重矩阵的谱范数,以约束鉴别器函数的Lipschitz常数。结合基于投影的鉴别器,谱归一化模型极大地改进了ImageNet上的类条件图像生成。
Attention Models. 最近,注意力机制已经成为必须捕捉全局相关性的模型的一个组成部分(Bahdanau et al., 2014; Xu et al., 2015; Yang et al., 2016; Gregor et al., 2015; Chen et al., 2018)。特别是,self-attention (Cheng et al., 2016; Parikh et al.,2016),也称为 intra-attention,通过关注同一序列中的所有位置,计算序列中某个位置的响应。Vaswani et al.(2017年)证明,机器翻译模型可以通过单独使用自我注意模型实现最先进的结果。Parmar et al.(2018)提出了一种图像翻译方法,将自我注意添加到用于图像生成的自回归模型中。Wang et al.将自我注意形式化为非局部操作,以模拟视频序列中的时空相关性。尽管取得了这一进展,但尚未在GANs的背景下探索自我关注。AttnGAN(Xu et al.,2018年)在输入序列中使用了对单词嵌入的注意,但在内部模型状态中没有使用自我注意。SAGAN学会了在图像的内部表示中高效地找到全局的、长期的依赖关系。
3. Self-Attention Generative Adversarial Networks
大多数基于GAN的模型((Radford et al., 2016; Salimans et al., 2016; Karras et al., 2018)都是使用卷积层构建的。卷积处理局部邻域的信息,因此单独使用卷积层对图像中的长期依赖建模是低效的。在本节中,我们采用(Wangetal.,2018)的非局部模型,引入GAN框架的自我关注,使生成器和鉴别器能够有效地建模广泛分离的空间区域之间的关系。我们将所提出的方法称为自注意生成对抗网络(SAGAN),因为它包含自注意模块(见图2)。
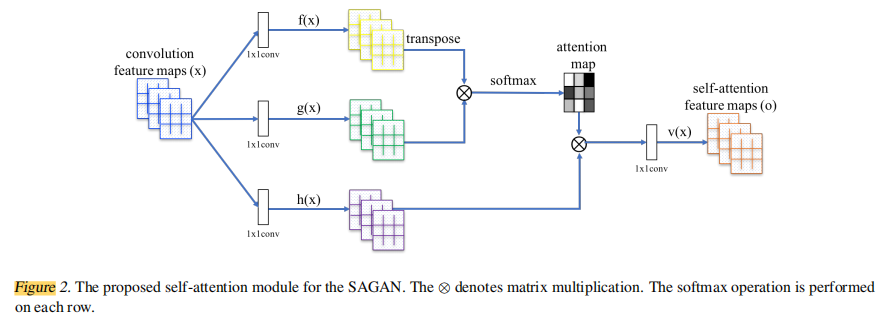
来自上一个隐藏层的图像特征
x
∈
R
C
x
N
x∈R_{CxN}
x∈RCxN首先被传入到两个特征空间f和g,用于计算attention,其中
f
(
x
)
=
W
f
x
,
g
(
x
)
=
W
g
x
f(x)=W_fx, \ g(x)=W_gx
f(x)=Wfx, g(x)=Wgx
β
j
,
i
=
exp
(
s
i
j
)
∑
i
=
1
N
exp
(
s
i
j
)
,
where
s
i
j
=
f
(
x
i
)
T
g
(
x
j
)
(1)
\beta_{j, i}=\frac{\exp \left(s_{i j}\right)}{\sum_{i=1}^{N} \exp \left(s_{i j}\right)}, \text { where } s_{i j}=\boldsymbol{f}\left(\boldsymbol{x}_{i}\right)^{T} \boldsymbol{g}\left(\boldsymbol{x}_{j}\right) \tag{1}
βj,i=∑i=1Nexp(sij)exp(sij), where sij=f(xi)Tg(xj)(1)
β
j
,
i
\beta_{j, i}
βj,i指模型在生成第j个区域时对第i个区域的关注程度。这里,C表示数据的通道数,N是前一个隐藏层特征的特征编号数。attention层的输出
o
=
(
o
1
,
o
2
,
.
.
.
,
o
N
)
∈
R
C
×
N
o=(o_1,o_2,...,o_N) ∈ R^{C \times N}
o=(o1,o2,...,oN)∈RC×N
o
j
=
v
(
∑
i
=
1
N
β
j
,
i
h
(
x
i
)
)
,
h
(
x
i
)
=
W
h
x
i
,
v
(
x
i
)
=
W
v
x
i
(2)
o_{j}=v\left(\sum_{i=1}^{N} \beta_{j, i} h\left(x_{i}\right)\right), h\left(x_{i}\right)=W_{h} x_{i}, v\left(x_{i}\right)=W_{v} x_{i} \tag{2}
oj=v(i=1∑Nβj,ih(xi)),h(xi)=Whxi,v(xi)=Wvxi(2)
在上面的公式中,
W
∈
R
C
ˉ
×
C
W \in \mathbb{R}^{\bar{C} \times C}
W∈RCˉ×C 是一个可学习的权重矩阵,都是基于权重矩阵实现的。自从我们注意到将¯C的通道数减少为¯C/k时,有任何显著的性能下降,其中在ImageNet上经过少量训练后,k=为1,2,4,8。为了提高内存效率,我们在所有的实验中都选择了k=8(即¯C=C/8)。
此外,我们还进一步将注意层的输出乘以一个比例参数,并将其添加回输入特征图。因此,最终的输出为:
y
i
=
γ
o
i
+
x
i
(3)
\boldsymbol{y}_{i}=\gamma \boldsymbol{o}_{i}+\boldsymbol{x}_{i} \tag{3}
yi=γoi+xi(3)
其中,γ是一个可学习的标量,它被初始化为0。引入可学习的γ可以让网络首先依赖于局部邻域中的线索,因为这更容易。然后逐渐学习为非局部证据分配更多的权重。我们为什么这样做的直觉很简单:我们想首先学习简单的任务,然后逐步增加任务的复杂性。在SAGAN算法中,所提出的注意模块已同时应用于发生器和鉴别器,它们通过交替的方式进行训练,最小化对抗性损失。
L D = − E ( x , y ) ∼ p data [ min ( 0 , − 1 + D ( x , y ) ) ] − E z ∼ p z , y ∼ p data [ min ( 0 , − 1 − D ( G ( z ) , y ) ) ] L G = − E z ∼ p z , y ∼ p data D ( G ( z ) , y ) (4) \begin{aligned} L_{D}=&-\mathbb{E}_{(x, y) \sim p_{\text {data }}}[\min (0,-1+D(x, y))] \\ &-\mathbb{E}_{z \sim p_{z}, y \sim p_{\text {data }}}[\min (0,-1-D(G(z), y))] \tag{4} \\ L_{G}=&-\mathbb{E}_{z \sim p_{z}, y \sim p_{\text {data }}} D(G(z), y) \end{aligned} LD=LG=−E(x,y)∼pdata [min(0,−1+D(x,y))]−Ez∼pz,y∼pdata [min(0,−1−D(G(z),y))]−Ez∼pz,y∼pdata D(G(z),y)(4)
4. Techniques to Stabilize the Training of GANs
我们还研究了两种技术来稳定在具有挑战性的数据集上训练的差距。首先,我们在生成器和鉴别器中使用谱归一化(Miyatoetal.,2018)。其次,我们确认了双时间尺度更新规则(TTUR)(Heuseletal.,2017)是有效的,并且我们提倡专门使用它来解决正则化鉴别器中的学习速度慢问题。
4.1. Spectral normalization for both generator and discriminator
Miyato et al.(2018)最初提出通过对鉴别器网络应用谱归一化来稳定GANs的训练。这样做通过限制每一层的谱范数来限制鉴别器的利普希茨常数。与其他归一化技术相比,谱归一化不需要额外的超参数调优(将所有权重层的谱范数设置为1,在实践中始终表现良好)。此外,计算成本也相对较小。
我们认为,生成器也可以从谱归一化中获益,基于最近的证据表明,生成器的条件作用是GANs性能的一个重要的因果因素(Odenaetal.,2018)。发电机中的谱归一化可以防止参数大小的升级,避免不寻常的梯度。根据经验,我们发现,生成器和鉴别器的谱归一化使得每次生成器更新都可以使用更少的鉴别器更新,从而显著降低了训练的计算成本。该方法还表现出更稳定的训练行为。
4.2. Imbalanced learning rate for generator and discriminator updates
在之前的工作中,鉴别器的正则化(Miyato et al.,2018;Gullrajani et al.,2017)通常会减慢GANs的学习过程。在实践中,使用正则化鉴别器的方法通常需要在训练过程中每个生成器更新步骤有多个(例如,5)鉴别器更新步骤。Heusel et al.(2017)主张对生成器和鉴别器使用单独的学习率(TTUR)。我们建议特别使用TTUR来补偿正则化鉴别器中学习较慢的问题,使每个生成器步骤使用更少的鉴别器步长成为可能。使用这种方法,我们能够在相同的挂钟时间下产生更好的结果。
5. Experiments
为了评估所提出的方法,我们在LSVRC2012(ImageNet)数据集上进行了广泛的实验(russkokovsky et al.,2015)。首先,在第5.1节中,我们提出了旨在评估这两种被提出的稳定GANs训练的技术的有效性的实验。接下来,在第5.2节中研究了所提出的自我注意机制。最后,将我们的SAGAN与最先进的方法( (Odena et al., 2017; Miyato & Koyama,2018)对5.3节的图像生成任务进行了比较。模型在4个gpu上进行了大约2周的训练,使用同步SGD(众所周知异步SGD的困难——例如(Odena,2016))。
Evaluation metrics. 我们选择起始分数(IS)(Salimans et al.,2016)和Fr的起始距离(FID)(Heusel et al.,2017)进行定量评估。尽管存在替代方案(Zhou et al.,2019年;Khrulkov & Oseledets, 2018;Olsson et al.,2018年),但它们并未得到广泛应用。 Inception score(Salimansetal.,2016)计算条件类分布和边际类分布之间的KL散度。 Inception score越高,说明图像质量越好。我们引入 Inception score是因为它被广泛使用,因此可以将我们的结果与以前的工作进行比较。然而,重要的是要理解 Inception score有严重的限制(它的主要目的是确保模型生成的样本可以被自信地识别为属于一个特定的类,并且模型从多个类中生成样本,而不一定是为了评估细节的真实性或类内的多样性)。FID是一个更有原则和全面的度量标准,在评估生成样本的真实性和变化时,已被证明与人类评估更一致(Heuseletal.,2017)。FID计算了在Inception-v3网络的特征空间中,生成的图像与真实图像之间的Wasserstein-2距离。除了计算整个数据分布的FID(即ImageNet中所有1000类图像),我们还计算生成的图像和数据集图像之间的FID(称为内部FID(Miyato&Koyama,2018))。较低的FID值和内部FID值意味着合成数据分布和真实数据分布之间的距离更近。在我们所有的实验中,每个模型随机生成50k个样本,以计算初始得分、FID和内部FID。
Network structures and implementation details. 我们训练的所有SAGAN模型都被设计成生成128×128的图像。默认情况下,谱归一化(Miyatoetal.,2018)同时用于生成器和鉴别器中的层。类似于(Miyato&Koyama,2018),SAGAN在生成器中使用条件批处理归一化,在鉴别器中使用投影。对于所有的模型,我们使用Adam优化器(Kingma&Ba,2015)和β1=0和β2=0.9进行训练。默认情况下,鉴别器的学习速率为0.0004,生成器的学习速率为0.0001。
5.1. Evaluating the proposed stabilization techniques
在本节中,我们进行了实验来评估所提出的稳定技术的有效性,即对生成器应用谱归一化(TTUR)(SN),并利用不平衡学习率(TTUR)。在图3中,我们的模型“G/DSN”和“G/DSN+TTUR”与基线模型进行了比较,基线模型基于最先进的图像生成方法(Miyatoetal.,2018)。在这个基线模型中,SN仅在鉴别器中使用。当我们对鉴别器(D)和生成器(G)进行1:1的平衡更新训练时,训练变得非常不稳定,如图3最左边的子图所示。它在训练的早期就表现出模式崩溃。例如,图4中左上角的子图说明了基线模型在第10k次迭代时随机生成的一些图像。虽然在原始论文(Miyatoetal.,2018)中,通过对D和G使用5:1的不平衡更新,大大缓解了这种不稳定的训练行为,但通过1:1的平衡更新进行稳定训练的能力可以提高模型的收敛速度。因此,使用我们提出的技术意味着该模型可以在相同的训练时间下产生更好的结果。鉴于此,没有必要为生成器和鉴别器寻找合适的更新比率。如图3的中间子图所示,在生成器和鉴别器中都添加SN,极大地稳定了我们的模型“SNonG/D”,即使是使用1:1的平衡更新进行训练。然而,在训练过程中,样本的质量并没有单调地提高。例如,由FID和IS测量的图像质量在第260k次迭代时开始下降。该模型在不同迭代条件下随机生成的示例图像如图4所示。当我们也应用不平衡学习率来训练鉴别器和生成器时,我们的模型“SNonG/D+TTUR”生成的图像质量在整个训练过程中单调地提高。如图3和图4所示,在100万次训练迭代中,我们没有观察到样本质量、FID或初始阶段得分的任何显著下降。因此,定量结果和定性结果都证明了所提出的稳定技术对GANs训练的有效性。他们还证明了这两种技术的效果至少部分是相加的。在其余的实验中,所有的模型都对生成器和鉴别器使用频谱归一化,并使用不平衡的学习率对生成器和鉴别器进行1:1的更新。


5.2. Self-attention mechanism
为了探讨所提出的自我注意机制的影响,我们通过将自我注意机制添加到生成器和鉴别器的不同阶段,建立了多个SAGAN模型。如表1所示,SAGAN模型的自我注意机制在中到高级别特征图(例如,
f
e
a
t
32
和
f
e
a
t
64
feat_{32}和feat_{64}
feat32和feat64)在低级别特征图(例如,
f
e
a
t
8
和
f
e
a
t
16
feat_{8}和feat_{16}
feat8和feat16)上具有自我注意机制的模型获得更好的性能。例如,模型“SAGAN,
f
e
a
t
8
feat_8
feat8”的FID被“SAGAN,
f
e
a
t
32
feat_{32}
feat32”从22.98提高到18.28。原因是自我注意接收到更多的证据,并享有更多的自由来选择具有较大特征映射的条件(即,它是对大特征映射的卷积的补充),然而,当建模小(如8×8)特征映射的依赖关系时,它发挥着与局部卷积相似的作用。结果表明,注意机制使生成器和鉴别器都更能直接建模特征图中的长期依赖关系。此外,将我们的SAGAN模型与无注意的基线模型(表1第2列)进行比较,进一步显示了所提出的自我注意机制的有效性。

与参数数相同的残差块相比,自注意块也取得了更好的效果。例如,当我们用8×8特征图中的残差块替换自注意块时,训练并不稳定,这将导致性能的显著下降(例如,FID从22.98增加到42.13)。即使在训练顺利的情况下,用残差块替换自我注意块仍然会导致FID和Inception score的结果。(例如,特征图32×32中的FID18.28vs27.33)。这一比较表明,使用SAGAN所得到的性能改进并不仅仅是由于模型深度和容量的增加。
为了更好地理解在生成过程中学到了什么,我们将SAGAN中不同图像的注意力权重可视化。在图5和图1中显示了一些值得注意的示例图像。有关学习到的注意力地图的一些属性的描述,请参见图5的标题。


5.3. Comparison with the state-of-the-art
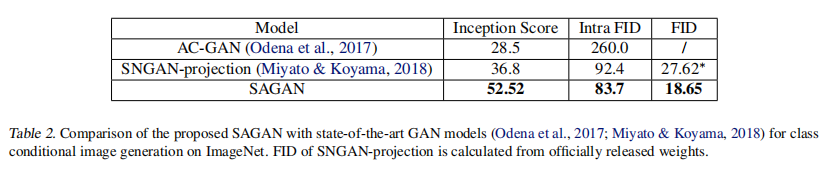
我们的SAGAN还与最先进的GAN模型进行了比较(Odena et al.,2017;Miyato&Koyama,2018),在ImageNet上进行类条件图像生成。如表2所示,我们提出的SAGAN获得了最好的Inception score,intra FID和FID。提出的SAGAN将最佳公布的Inception score从36.8显著提高到52.52。SAGAN获得的较低的FID(18.65)和内FID(83.7)也表明,SAGAN利用自注意模块建模图像区域之间的长期依赖关系,可以更好地近似原始图像分布。
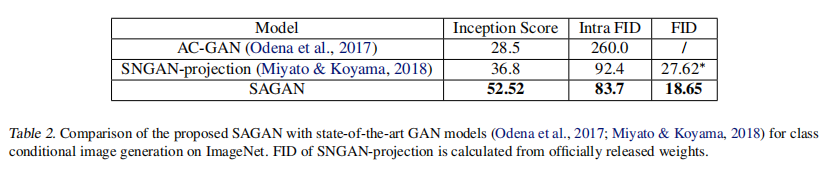
图6显示了ImageNet代表性类别的一些比较结果和结果。我们观察到,我们的SAGAN与最先进的GAN模型(Mayan)相比,SAGAN取得了更好的性能(即更低的内部FID),如金鱼和圣伯纳德。对于结构约束很少的类别(例如,山谷、石墙和珊瑚真菌,它们更多的是通过纹理而不是几何形状),我们的SAGAN与基线模型相比的优势较小(Miyato&Koyama,2018)。同样,原因是SAGAN中的自我注意是对卷积的补充,以捕获在几何或结构模式中持续发生的长期、全局级依赖,但在建模简单纹理的依赖时发挥了与局部卷积相似的作用。
6. Conclusion
在本文中,我们提出了自注意生成对抗网络(SAGANs),它将自注意机制纳入到GAN框架中。自注意模块在建模远程依赖关系方面是有效的。此外,我们还证明了应用于生成器的谱归一化方法稳定了GAN的训练,并且TTUR加快了正则化鉴别器的训练速度。SAGNAs在ImageNet上实现了类条件图像生成方面取得了最先进的性能。
相关文章
- 生活娱乐 毕业生论文查重技巧
- 2018年4月24日论文阅读
- 2018年4月2日论文阅读
- 2018年3月15日论文阅读
- 2018年4月24日论文阅读
- 2018年3月12日论文阅读
- Paper之ICASSP&IEEEAUDIOSPE:2018~2019年ICASSP国际声学、语音和信号处理会议&IEEE-ACM T AUDIO SPE音频、语音和语言处理期刊最佳论文简介及其解读
- Paper之DL:深度学习高质量论文分类推荐(建议收藏,持续更新)
- DL之Yolo:Yolo算法的简介(论文介绍)、架构详解、案例应用等配图集合之详细攻略
- 顶会VLDB‘22论文解读:CAE-ENSEMBLE算法
- 【大数据&人工智能AI】每个现代数据科学家都必须阅读的 6 篇论文:该领域的每个人都熟悉深度学习的一些最重要的现代基础知识的列表
- 毕业设计 Spring Boot的运动健身管理系统(含源码+论文)
- 论文投稿指南——中文核心期刊推荐(计算机技术)
- 论文投稿指南——中文核心期刊推荐(矿业工程)
- 论文笔记系列:轻量级网络(一)-- RepVGG
- 《论文阅读》Autoregressive Entity Generation for End-to-End Task-Oriented Dialog
- 《论文阅读》 ProphetChat: Enhancing Dialogue Generation with Simulation of Future Conversation
- 《论文阅读》EmoBERTa: Speaker-Aware Emotion Recognition in Conversation with RoBERTa
- 《论文阅读》Towards Expressive Communication with Internet Memes: A New Multimodal Conversation Dataset an
- 2022年第十一届认证杯数学中国数学建模国际赛小美赛:D题野生动物贸易是否应该长期禁止建模 38页一等奖论文及代码
- 【2022 年“SPSSPRO 杯”数学中国数学建模网络挑战赛】A题 人员的紧急疏散-第二阶段23页论文
- 论文阅读《Alexa Conversations》
- 论文阅读《SPANNER: Named Entity Re-/Recognition as Span Prediction》
- 论文阅读:Rethinking Atrous Convolution for Semantic Image Segmentation
- 目标检测论文解读复现【NO.21】基于改进YOLOv7的小目标检测
- 论文阅读-Fast Algorithms for Convolutional Neural Networks
- 论文阅读笔记2:Eyeriss