
Spark MLlib概述
Spark 概述
2023-09-14 09:14:49 时间
机器学习
机器学习的过程 :
- 基于历史数据,机器会根据一定的算法,尝试从历史数据中挖掘并捕捉出一般规律
- 再把找到的规律应用到新产生的数据中,从而实现在新数据上的预测与判断
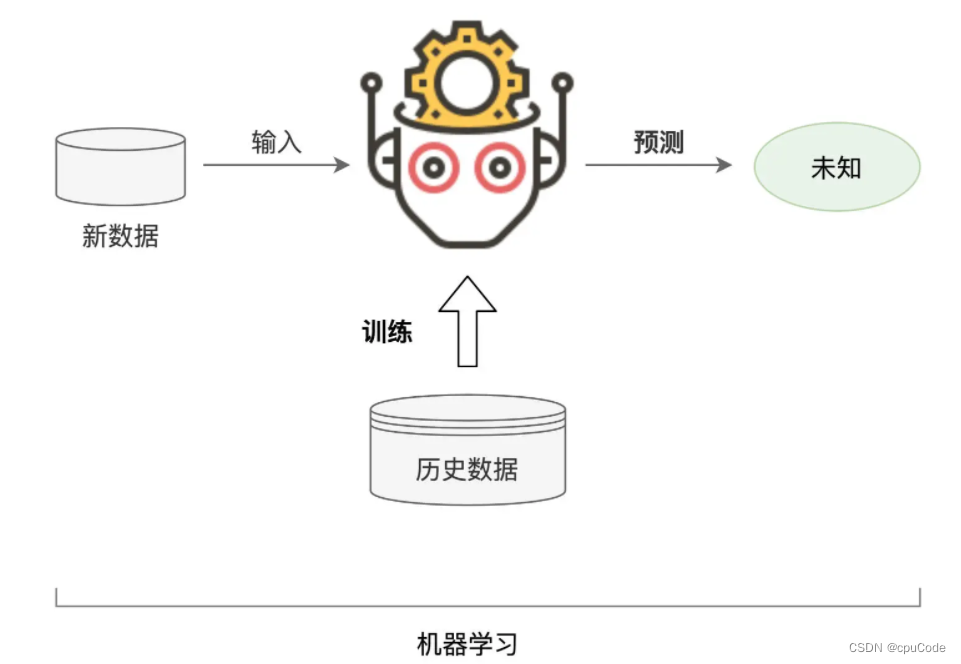
机器学习(Machine Learning): 一种计算过程:
- 对于给定的训练数据(Training samples),选择一种先验的数据分布模型(Models)
- 借助优化算法(Learning Algorithms)自动地持续调整模型参数(Model Weights / Parameters)
- 让模型不断逼近训练数据的原始分布
模型训练 (Model Training) : 调整模型参数的过程
- 根据优化算法,基于过往的计算误差 (Loss),优化算法以不断迭代的方式,自动地对模型参数进行调整
- 模型训练时 ,触发了收敛条件 (Convergence Conditions) ,就结束模型的训练过程
模型测试 (Model Testing) :
- 模型训练完成后,会用一份新的数据集 (Testing samples),来测试模型的预测能力,来验证模型的训练效果
机器学习开发步骤 :
- 数据加载 : SparkSession read API
- 数据提取 : DataFrame select 算子
- 数据类型转换 : DataFrame withColumn + cast 算子
- 生成特征向量 : VectorAssembler 对象及 transform 函数
- 数据集拆分 : DataFrame 的 randomSplit 算子
- 线性回归模型定义 : LinearRegression 对象及参数
- 模型训练 : 模型 fit 函数
- 训练集效果评估 : 模型 summaray 函数
房价预测
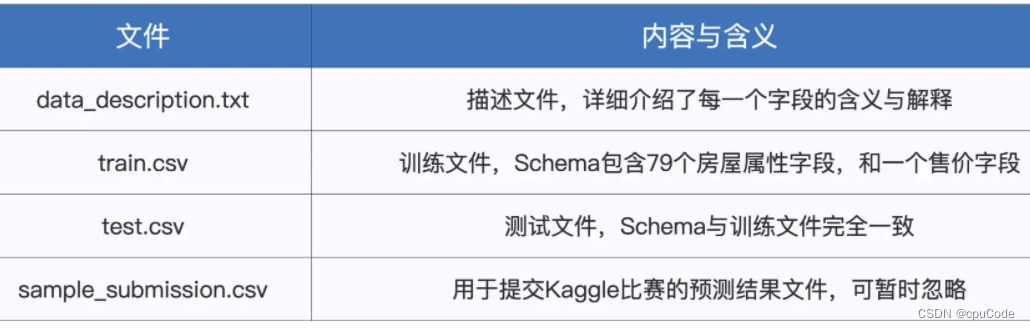
房屋数据中的不同文件 :
模型选型
机器学习分类 :
- 拟合能力 : 有线性模型 , 非线性模型
- 预测标 : 回归、分类、聚类、挖掘
- 模型复杂度 : 经典算法、深度学习
- 模型结构 : 广义线性模型、树模型、神经网络
房价预测的预测标的(Label)是房价,而房价是连续的数值型字段,所以用回归模型(Regression Model)来拟合数据
数据探索
要想准确预测房价,就要先确定那些属性对房价的影响最大
- 模型训练时,要选择那些影响大的因素,剔除那些影响小的干扰项
- 数据特征 (Features) : 预测标的相关的属性
- 特征选择 (Features Selection) : 选择有效特征的过程
特征选择时 , 先查看 Schema
import org.apache.spark.sql.DataFrame
val rootPath: String = _
val filePath: String = s"${rootPath}/train.csv"
// 从CSV文件创建DataFrame
val trainDF: DataFrame = spark.read.format("csv")
.option("header", true).load(filePath)
trainDF.show
trainDF.printSchema
数据提取
选择对房价影响大的特征,要计算每个特征与房价之间的相关性
从 CSV 创建 DataFrame,所有字段的类型默认都是 String
- 训练模型时,只计算数值型数据 , 所以要把所有字段都转为整型
import org.apache.spark.sql.types.IntegerType
// 提取用于训练的特征字段与预测标的(房价SalePrice)
val selectedFields: DataFrame =
trainDF.select("LotArea", "GrLivArea", "TotalBsmtSF", "GarageArea", "SalePrice");
// 将所有字段都转换为整 型Int
val typedFields = selectedFields
.withColumn("LotAreaInt",col("LotArea").cast(IntegerType)).drop("LotArea")
.withColumn("GrLivAreaInt",col("GrLivArea").cast(IntegerType)).drop("GrLivArea")
.withColumn("TotalBsmtSFInt",col("TotalBsmtSF").cast(IntegerType)).drop("TotalBsmtSF")
.withColumn("GarageAreaInt",col("GarageArea").cast(IntegerType)).drop("GarageArea")
.withColumn("SalePriceInt",col("SalePrice").cast(IntegerType)).drop("SalePrice")
typedFields.printSchema
/** 结果打印
root
|-- LotAreaInt: integer (nullable = true)
|-- GrLivAreaInt: integer (nullable = true)
|-- TotalBsmtSFInt: integer (nullable = true)
|-- GarageAreaInt: integer (nullable = true)
|-- SalePriceInt: integer (nullable = true)
*/
准备训练样本
把要训练的多个特征字段,捏合成一个特征向量(Feature Vectors)
import org.apache.spark.ml.feature.VectorAssembler
// 待捏合的特征字段集合
val features: Array[String] = Array("LotAreaInt", "GrLivAreaInt", "TotalBsmtSFInt", "GarageAreaInt", "SalePriceInt")
// 准备“捏合器”,指定输入特征字段集合,与捏合后的特征向量字段名
val assembler = new VectorAssembler().setInputCols(features).setOutputCol("featuresAdded")
// 调用捏合器的transform函数,完成特征向量的捏合
val featuresAdded: DataFrame = assembler.transform(typedFields)
.drop("LotAreaInt")
.drop("GrLivAreaInt")
.drop("TotalBsmtSFInt")
.drop("GarageAreaInt")
featuresAdded.printSchema
/** 结果打印
root
|-- SalePriceInt: integer (nullable = true)
|-- features: vector (nullable = true) // 注意,features的字段类型是Vector
*/
把训练样本按比例分成两份 : 一份用于模型训练,一份用于初步验证模型效果
- 将训练样本拆分为训练集和验证集
val Array(trainSet, testSet) = featuresAdded.randomSplit(Array(0.7, 0.3))
模型训练
用训练样本来构建线性回归模型
import org.apache.spark.ml.regression.LinearRegression
// 构建线性回归模型,指定特征向量、预测标的与迭代次数
val lr = new LinearRegression()
.setLabelCol("SalePriceInt")
.setFeaturesCol("features")
.setMaxIter(10)
// 使用训练集trainSet训练线性回归模型
val lrModel = lr.fit(trainSet)
迭代次数 :
- 模型训练是一个持续不断的过程,训练过程会反复扫描同一份数据
- 以迭代的方式,一次次地更新模型中的参数(Parameters, 权重, Weights),直到模型的预测效果达到一定的标准,才能结束训练
标准的制定 :
- 对于预测误差的要求 : 当模型的预测误差 < 预先设定的阈值时,模型迭代就收敛、结束训练
- 对于迭代次数的要求 : 不论预测误差是多少,只要达到设定的迭代次数,模型训练就结束
烘焙/模型训练的对比 :

完成模型的训练过程
import org.apache.spark.ml.regression.LinearRegression
// 构建线性回归模型,指定特征向量、预测标的与迭代次数
val lr = new LinearRegression()
.setLabelCol("SalePriceInt")
.setFeaturesCol("features")
.setMaxIter(10)
// 使用训练集trainSet训练线性回归模型
val lrModel = lr fit(trainSet)
模型效果评估
在线性回归模型的评估中,有很多的指标,用来量化模型的预测误差
- 最具代表性 : 均方根误差 RMSE(Root Mean Squared Error),用 summary 能获取模型在训练集上的评估指标
val trainingSummary = lrModel.summary
println(s"RMSE: ${trainingSummary.rootMeanSquaredError}")
/** 结果打印
RMSE: 45798.86
*/
房价的值域在(34,900,755,000)之间,而预测是 45,798.86 。这说明该模型是欠拟合的状态
相关文章
- 关于用户路径分析模型_spark用户行为路径
- Spark3.12+Kyuubi1.5.2+kyuubi-spark-authz源码编译打包+部署配置HA
- spark RDD
- 跨内外网远程操作Spark
- Hadoop/Spark 太重,esProc SPL 很轻
- Spark SQL增量查询Hudi表
- Spark内核源码深度分析
- 借助IBCS虚拟专线优化Apache Spark集群性能
- Spark入门实战系列–6.SparkSQL(中)–深入了解SparkSQL运行计划及调优详解大数据
- Spark入门实战系列–10.分布式内存文件系统Tachyon介绍及安装部署详解大数据
- Spark MLlib回归算法——线性回归、逻辑回归、SVM和ALS详解大数据
- Spark 更新 MySQL 数据库:实现快速、高效转移(spark更新mysql)
- 作为缓存Spark利用Redis缓冲数据的应用(spark需要redis)
- 基于Spark实现Redis数据库查询(spark查询redis)
- Spark与Redis的联合探索(spark加redis)
- Spark开发之利用Redis提升性能(spark使用redis)
- 大疆Spark无人机正式发布!手势操控让遥控器成为历史