
HTTP 无状态 持久化连接 流水线方式
万维网的工作过程
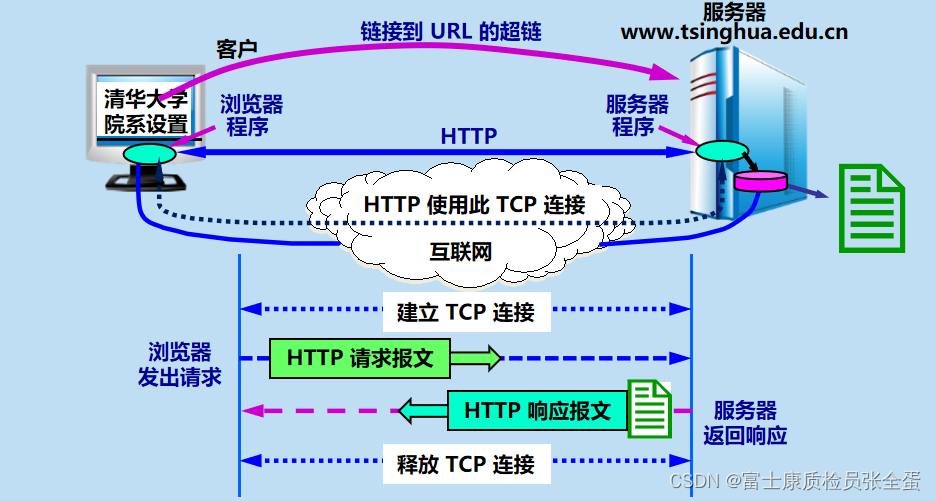
每个万维网网点都有一个服务器进程,它不断地监听 TCP 的端口 80,以便发现是否有浏览器向它发出连接建立请求。(如果是https协议,那么监听的是443端口)
一旦监听到连接建立请求并建立了 TCP 连接之后,浏览器就向万维网服务器发出浏览某个页面的请求,服务器接着就返回所请求的页面作为响应。最后,TCP 连接就被释放了。
通常将请求访问的一端称为客户端,提供资源响应的称为服务器端。通信的方式提供请求和响应的方式来完成的,请求从客户端发出,而后服务器端响应该请求,通信是从客户端开始建立的。
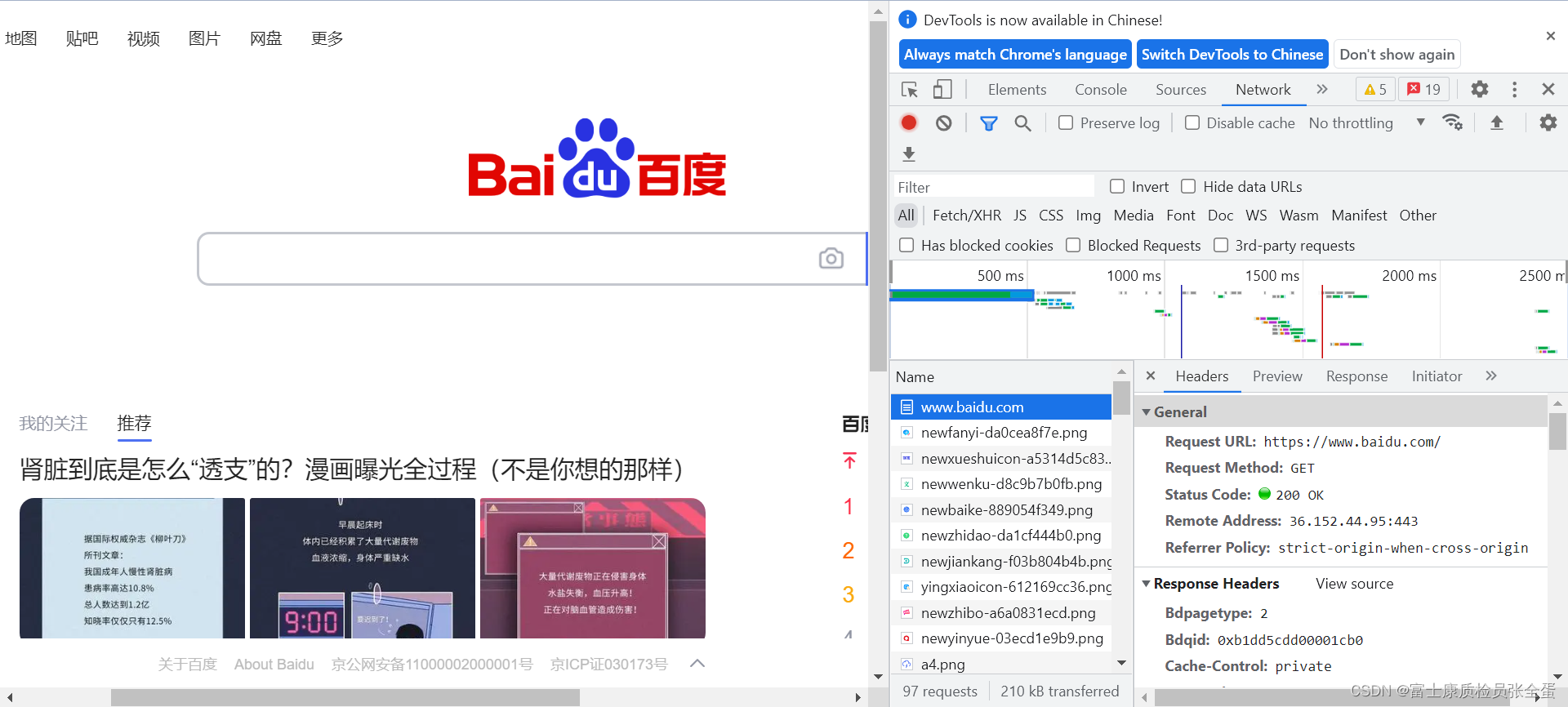
任何的网站,它的第一个请求方式都是get,上面可以看出http报文组成如下:
和请求内容无关的,都称为请求头。
- 请求方法
- 请求的url
- 请求的版本号
请求体
- 请求内容 页面 图片
请求处理结果的状态码 参数和参数之间都单独起一行。
HTTP 的主要特点
HTTP 使用了面向连接的 TCP 作为运输层协议,保证了数据的可靠传输。
HTTP 协议本身也是无连接的,虽然它使用了面向连接的 TCP 向上提供的服务。
HTTP 是面向事务的客户服务器协议。
HTTP 1.0 协议是无状态的 (stateless)。 (客户端访问完了,就忘了你了,再访问我就再建立TCP再传,并不是一直保持连接知道你是谁)
HTTP很有名的特点,无状态,老年痴呆和无状态非常的类似,http是一个不会保存状态的协议,它不对请求,响应的通信状态做保存。换句话来说就是协议对发送过的请求和响应不会做持久化的处理,每次的请求都是新的请求。
而这一特点是为了处理大量的请求,并且确保协议的可伸缩性,因为不保存就可以节省很多资源,同时没有状态就很容易扩展。
因为无状态,使得很多业务的处理变的复杂,比如用户登入到一家网站购物,在不同的页面进行跳转的时候,需要保持这种登入状态,因为只有这样网站才能知道是谁发起的请求,是谁购物,谁下单。
为了弥补http无状态,就诞生了另外一项技术,叫做cookie,cookie并没有从根本上改变HTTP的无状态,而是通过另外一种方式,变相的维护用户状态。
请求一个万维网文档所需的时间
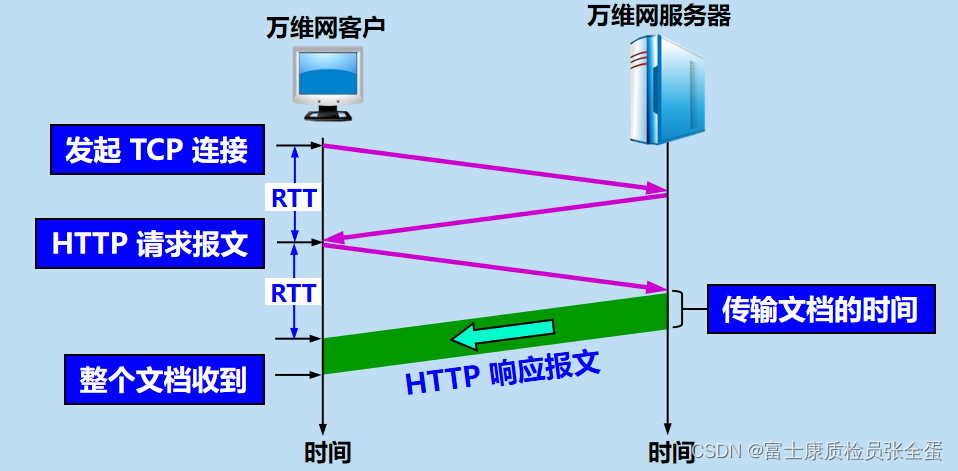
发起TCP的时间,http请求报文的时间,传文件的时间。
持续连接
HTTP/1.1 协议使用持续连接 (persistent connection)。
万维网服务器在发送响应后仍然在一段时间内保持这条连接,使同一个客户(浏览器)和该服务器可以继续在这条连接上传送后续的 HTTP 请求报文和响应报文。(只要建立了一个连接,后面传输多个文件都使用这个连接)
这并不局限于传送同一个页面上链接的文档,而是只要这些文档都在同一个服务器上就行。
目前一些流行的浏览器(例如,IE 6.0)的默认设置就是使用 HTTP/1.1。
一个页面里面包含了n多个文件资源,也就是想获取页面的内容就需要不停的三次握手,这样就会有很多重复性的工作,为了解决多次三次握手,http就提出了持久化连接,它的参数表示为keep-alive,它的特点是只要一端没有明确的提出断开连接,那么就会一直保持连接状态。
这样的好处就是减少了连接的重复建立和断开所造成的开销,这样大大的减少了服务端的负载,给我们直观的感受就是web页面显示的速度也提高了。在http 1.1当中,所有的连接都是持久化连接,需要知道的是持久化连接需要客户端和服务器端都支持才能实现。
HTTP1.1持续连接的两种工作方式
非流水线方式:客户在收到前一个响应后才能发出下一个请求。这比非持续连接的两倍 RTT 的开销节省了建立 TCP 连接所需的一个 RTT 时间。但服务器在发送完一个对象后,其 TCP 连接就处于空闲状态,浪费了服务器资源。
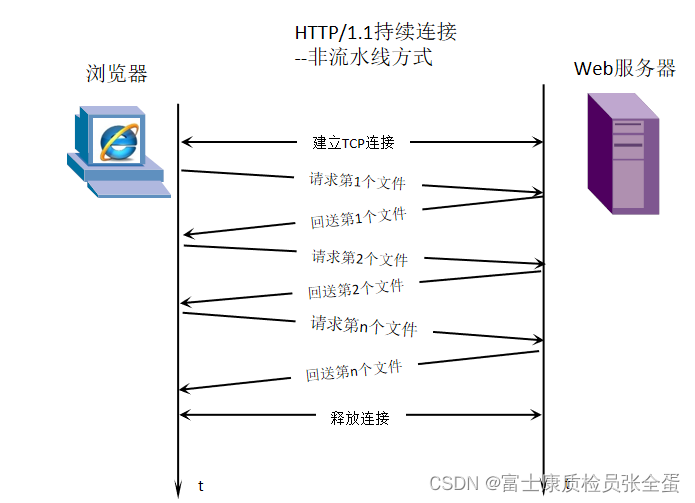
浏览器访问这个网站,先建立TCP连接,3次握手,请求第一个文件,然后收到,再请求第二个文件,收到。
流水线方式:客户在收到 HTTP 的响应报文之前就能够接着发送新的请求报文。一个接一个的请求报文到达服务器后,服务器就可连续发回响应报文。使用流水线方式时,客户访问所有的对象只需花费一个 RTT时间,使 TCP 连接中的空闲时间减少,提高了下载文档效率。

更快一点的就是流水线方式,一次性发多个请求,一块发,然后一个一个的往回返。(不用等待响应也可以发送下一个请求)
相关文章
- [apue] sysconf 的四种返回状态
- cBridge 2.0测试网升级:全新的状态守卫者网络UI/UX[通俗易懂]
- 通过select 和状态EINPROGRESS 实现socket 连接超时判断
- 【混沌工程】2022 混沌工程状态
- PID为0的系统空闲进程连接状态为TIME_WAIT
- linux系统查看网卡是否开启,查看Linux下网卡状态或 是否连接
- 【PPT】国内外网络靶场发展状态演进与分析
- .NET MAUI Preview5 状态预览(6月)
- Linux||后台运行及查看状态命令
- (十)使用 Actions 异步修改状态
- halo服务状态查看
- Pinia入门-实现简单的用户状态管理
- MySQL Status Mysqlx_notice_other_sent 数据库状态作用意思及如何正确
- MySQL Status Ndb_api_bytes_received_count 数据库状态作用意思及如何正确
- MySQL Status Sort_scan 数据库状态作用意思及如何正确
- 成功MySQL数据库连接状态确认(mysql判断是否连接)
- 获取WBS状态函数详解编程语言
- 状态探索Linux下查看网络连接状态的方法(linux查看连接)
- Linux Ping测试失败:连接状态异常(linuxping不通)
- 中的netstat工具使用Netstat连接Linux系统的网络状态(连接linux系统)
- 利用Redis查看客户端的连接状态(redis查看客户端连接)
- 监控Oracle索引状态监控:提升性能的最佳实践(oracle索引状态)
- 使用Linux监视系统:掌握实时状态(linux监视工具)
- MySQL状态查看:掌握系统运行状态(mysql查看状态)
- Linux网络查询:全面了解网络配置与状态(linux查询网络)
- Linux实时监控网络流量,精准把握网络状态(linux实时网络流量)
- 掉电后MSSQL连接状态解决方案(掉电后mssql连接不上)
- 如何在MSSQL中查看连接状态?(mssql查看连接)
- 服务器升级后redis状态异常排查连接问题(服务器升级后redis连不上)
- 数据库使用HTTP连接Oracle数据库的简单操作(http连接oracle)
- Redis如何保持可靠的连接状态(如何让redis保持连接)
- 查明redis连接状态的方法测试连接redis(如何测试连接redis)
- Redis队列状态精准监测,保障数据流畅传输(redis队列检测)
- 监控获取Redis连接状态实时监控(redis 连接情况)
- 七、HTTP应答状态
- PHP判断表单复选框选中状态完整例子