
使用einops简化数据维度操作
einops主要实现了三个函数:rearrange、reduce、repeat。rearrange用于重排数据,reduce用于对数据进行sum、mean、max等统计,repeat用于重复数据的维度。
通过使用einops的函数可以便捷的对数据的维度仅修改操作,此外einops的数据操作还可以在神经网络模型的forward中生效。
用法参考:http://einops.rocks/1-einops-basics/
官网地址:http://einops.rocks/
einops里面的表达式对应着ims.shape 的具体值,bhwcd等各种字母并无实际含义,只是说第0个字母对应着ims.shape[0],第i个字母对应着ims.shape[i]。例如img的shape为100,300,4,语句rearrange(ims, ‘a b c -> b a c’) ;则a表示100,b表示300,c表示4。同时表达式中用括号()包裹在一起的,表示一个数。就如rearrange(ims, ‘b h w c -> (b h) w c’)里面的(b h)其实表示b*h的值。
1、安装einops
pip install einops
导入einops库
from einops import rearrange,reduce,repeat
2、Rearrange
Rearrange操作本质是保证数据总量不变,调整顺序重新排列
2.1 维度顺序交换
交换不同维度的顺序,相当于torch.transpose()。可以安装个人需求任意交换数据的维度顺序。
rearrange(ims, 'h w c -> w h c')
rearrange(ims, 'h w c -> c w h')
2.2 维度间自由组合
实现维度的压缩与拉伸,可以实现torch.flatten(), torch.reshape等功能
rearrange(ims, 'b h w c -> (b h) w c')
rearrange(ims, 'b h w c -> h (b w) c')
2.3 维度填充或删除
实现1维度的添加与删除,可以实现类似torch.squeeze(),torch.unsqueeze()的功能
rearrange(ims, 'h w c -> 1 h w c')
rearrange(ims, '1 h w c -> h w c')
2.4 空间的自由组合
可以自由划定维度进行重排序,基于此可以实现图像的切片与切片还原。
基于变量实现数据的切片
pads = rearrange(pad, '(a1 h) (a2 w) c -> (a1 a2) h w c',a1=2,a2=2) #可以实现图像的切片
pads_megre = rearrange(pads, '(a1 a2) h w c -> (a1 h) (a2 w) c',a1=2,a2=2) #可以实现图像切片的还原
基于常量实现数据的切片
该操作在最新的eniops库中不可以用,也就是说目前不支持包含常量的写法
pads = rearrange(pad, '(2 h) (2 w) c -> (2 2) h w c')
pads_megre = rearrange(pads, '(2 2) h w c -> (2 h) (2 w) c')
2.5 维度内部的重排序
实现shufflenet的维度重排序。这里可以只写一个变量,因为c2的值可以根据c1推断出来
rearrange(ims, 'b (c1 c2) h w -> b (c2 c1) h w', c1=groups)
3、reduce
reduce函数中设置的是输入维度和输出维度,其中消失的维度则是被被reduce了
3.1 在维度上进行reduce
mean操作
reduce(ims, 'b h w c -> h w c', 'mean') #在b维度求均值
reduce(ims, 'b h w c -> b c', 'mean') #在h、w维度求均值(相当于全局平均池化)
reduce(ims, 'b h w c -> c', 'mean') #在b、h、w维度上求均值
sum操作
reduce(ims, 'b h w c -> h w c', 'sum') #在b维度求sum
reduce(ims, 'b h w c -> b c', 'sum') #在h、w维度求sum
reduce(ims, 'b h w c -> c', 'sum') #在b、h、w维度上求均值
max操作
reduce(ims, 'b h w c -> h w c', 'max') #在b维度求max
reduce(ims, 'b h w c -> b c', 'max') #在h、w维度求max(相当于全局最大池化)
reduce(ims, 'b h w c -> c', 'max') #在b、h、w维度求max
3.2 在空间上进行reduce
常量写法
reduce(ims, 'b (2 h) (2 w) c -> h w c', 'mean') #在hw维度上划分2x2的空间求均值
变量写法
reduce(ims, 'b (a1 h) (a2 w) c -> h w c', 'mean',a1=2,a2=2) #在hw维度上划分2x2的空间求均值
此外,sum、max都是这种写法
3.3 保留维度进行reduce
保留数据维度的长度进行reduce操作
reduce(ims, 'b h w c -> b () w c', 'max') #在h维度求均值,并保持括号的维度为1
reduce(ims, 'b h w c -> b () () c', 'max') #在hw维度求均值,并保持括号的维度为1
reduce(ims, 'b h w c -> () () () c', 'max') #在bhw维度求均值,并保持括号的维度为1
4、repeat
可以将特定维度的数据进行重复,可以基于此实现图像的上采样
repeat(ims, 'h w c -> h (a w) c', a=3) #将w维度重复三次
repeat(ims, 'h w c -> (a1 h) (a2 w) c', a1=2,a2=3) #将h维度重复两次,将w维度重复三次。类似于实现图像的放大
通常与reduce组合使用,形成一种给图像添加马赛克的效果(本质就是先缩小图片,再重排序后放大图片)
averaged = reduce(ims, 'b (h h2) (w w2) c -> b h w c', 'mean', h2=10, w2=8)
repeat(averaged, 'b h w c -> (h h2) (b w w2) c', h2=10, w2=8)
5、实现图片的切片与还原
基于rearrange的操作可以实现对图片的切片与切片的还原,这里需要注意的是,图像的尺寸不能整除patch size时,需要进行填充。
import math
import numpy as np
img=np.random.random((2340,3402))
b_h=500
b_w=500
h=math.ceil(img.shape[0]/b_h)*b_h
w=math.ceil(img.shape[1]/b_w)*b_w
print(img.shape,h,w)
#对原图像进行填充
pad=np.zeros((h,w,3),dtype=img.dtype)
pad[:img.shape[0],:img.shape[1]]=img
print(pad.shape)#(4000, 3000, 3)
pads = rearrange(pad, '(a1 h) (a2 w) c -> (a1 a2) h w c',a1=int(pad.shape[0]/b_h),a2=int(pad.shape[1]/b_w))
print(pads.shape)#(48, 500, 500, 3)
pads_megre = rearrange(pads, '(a1 a2) h w c -> (a1 h) (a2 w) c',a1=int(pad.shape[0]/b_h),a2=int(pad.shape[1]/b_w))
print(pads_megre.shape)#(4000, 3000, 3)
diff=np.abs(pads_megre-pad)
print(diff.sum())#0
6、在深度学习中的用法
可以使用Rearrange, Reduce等来构建layer,支持chainer、gluon、keras、tensorflow、torch
from einops.layers.chainer import Rearrange, Reduce,WeightedEinsum
from einops.layers.gluon import Rearrange, Reduce,WeightedEinsum
from einops.layers.keras import Rearrange, Reduce,WeightedEinsum
from einops.layers.tensorflow import Rearrange, Reduce,WeightedEinsum
from einops.layers.torch import Rearrange, Reduce,WeightedEinsum
通过以上方式导入的Rearrange, Reduce,WeightedEinsum相当于深度学习框架中的layer对象,相关用法可见下图

在pytorch中的一些用法http://einops.rocks/pytorch-examples.html
恒等变化,通常用于深度学习中
Rearrange('...->...') # identity
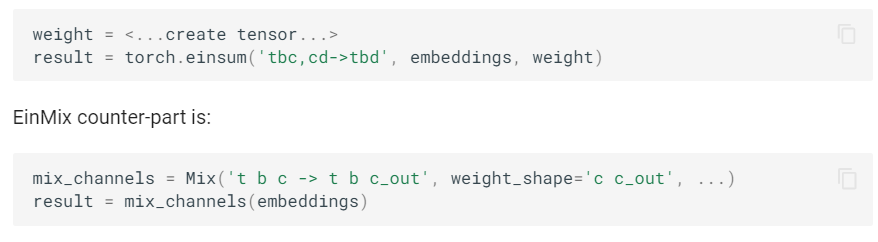
此外,einops还支持einsum操作,具体可以参考http://einops.rocks/3-einmix-layer/
相关文章
- 开源大数据平台HBase对接OBS操作指南
- CANopen笔记2 -- PDO过程数据对象
- 追踪记录每笔业务操作数据改变的利器——SQLCDC
- 利用bootstraptable展示数据,对数据进行排序分页等操作
- 数据科学初学者九种常见错误
- Go标准库Context包:单个请求多个goroutine 之间与请求域的数据、取消信号、截止时间等相关操作
- python3操作MySQL:insert插入数据
- 数据建模工具:GeneXproTools 5.0 Crack
- VB.net:VB.net编程语言学习之基于VS软件连接SQL Server(利用ADO.NET操作数据库/添加新数据源/DataGridView数据表格控件)的简介、案例应用之详细攻略
- Python编程语言学习:for循环实现对多个不同的DataFrame数据执行相同操作(可用于对分开的测试集、训练集实现执行相同逻辑任务)
- Keras之ML~P:基于Keras中建立的回归预测的神经网络模型(根据200个数据样本预测新的5+1个样本)——回归预测
- 〖Python 数据库开发实战 - MySQL篇㉖〗- 数据删除操作 - DELETE语句
- 【状态估计】电力系统状态估计的虚假数据注入攻击建模与对策(Matlab代码实现)
- Java中double类型精度丢失的问题_double类型数据加减操作精度丢失解决方法_BigDecimal取整
- Mysql之binlog日志说明及利用binlog日志恢复数据操作记录
- 【SQL开发实战技巧】系列(二十一):数据仓库中时间类型操作(进阶)识别重叠的日期范围,按指定10分钟时间间隔汇总数据
- 利用fiddler实现简单的数据重放
- tflearn 数据集太大无法加载进内存问题?——使用image_preloader 或者是 hdf5 dataset to deal with that issue
- 大数据Hadoop之——Apache Hudi 数据湖实战操作(Spark,Flink与Hudi整合)
- 大数据Hadoop之——HDFS小文件问题与处理实战操作
- 大数据Hadoop之——Hadoop HDFS多目录磁盘扩展与数据平衡实战操作
- 302_弹性分布式数据集RDD基本操作
- 数据工程师日记:10年职场老鸟,我居然被新人给上了一课
- 企业数据中台选型前必读!透过Gartner看清面向未来的下一代数据中台