
【Ensemble Learning】第 6 章 : 技巧和最佳实践
为了充分发挥集成的力量,您需要学习将其有效应用于现实世界的艺术。
如果您听说过机器学习中数据整理的 80/20 规则,那么您就会知道在搜索和优化模型之外还花费了大量时间。到本章结束时,您将拥有一组很好的可重用解决方案,可将集成集成到您的真实世界 ML 工作流中。
以下是本章的学习目标。
使用随机森林模型进行特征选择。特征选择和特征相关性受益于机器学习算法的性能和解释也就不足为奇了。
树集合的特征转换。
为随机森林回归器构建预处理管道。
隔离森林,一种用于异常值检测的有效算法,尤其是在高维数据集中。
使用 Dask 缩放集成。
使用随机森林进行特征选择
为您的 ML 任务提供数百个功能是很常见的,但它们可能并非都发挥同等作用,有些可能根本没有作用。可以从功能列表中安全地删除重要性非常低或不重要的功能。这种特征修剪(或重要特征的选择)提供了三个好处。
它减少了训练模型的计算成本和时间。
它使经过训练的模型解释更容易。
它通过减少方差来减少过度拟合。
随机森林(决策树的集合)在特征选择方面很受欢迎。您可以通过查看使用该特征的树节点平均提高纯度的程度(在森林中的所有树中)来直观地衡量特征的重要性。因此,通过修剪特定节点下的树,您可以创建最重要特征的子集。
幸运的是,scikit-learn 会在训练后自动计算每个特征的重要性分数,然后对结果进行缩放,使所有特征重要性的总和等于 1。您可以使用feature_importances_变量访问结果。让我们看一下清单6-1中的代码。为简洁起见,我们跳过了导入。
iris = datasets.load_iris() # -1
feature_list = iris.feature_names # -2
print(feature_list)
['sepal length (cm)',
'sepal width (cm)',
'petal length (cm)',
'petal width (cm)']
X = iris.data # -3
y = iris.target # -4
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.33, random_state=42) # -5
rf_clf = RandomForestClassifier(n_estimators=10000, random_state=42, n_jobs=-1) # -6
rf_clf.fit(X_train, y_train) # -7
for name, score in zip(iris["feature_names"], rf_clf.feature_importances_):
print(name, score) # -8
# sepal length (cm) 0.09906957842524829
# sepal width (cm) 0.03880497890715764
# petal length (cm) 0.4152569088750478
# petal width (cm) 0.4468685337925464
y_pred = clf.predict(X_test) # -9
accuracy_score(y_test, y_pred) # -10
# 0.9333333333333333
sfm = SelectFromModel(clf, threshold=0.15) # - 11
sfm.fit(X_train, y_train) # -12
X_important_train = sfm.transform(X_train) # -13
X_important_test = sfm.transform(X_test)
rf_clf_important = RandomForestClassifier(n_estimators=500, random_state=0, n_jobs=-1) # -14
rf_clf_important.fit(X_important_train, y_train)
y_important_pred = rf_clf_important.predict(X_important_test) # - 15
accuracy_score(y_test, y_important_pred)
# 0.9166666666666666清单 6-1 在 scikit-learn 中计算特征重要性
让我们解压缩代码以更好地理解它。
使用鸢尾花数据集。它与 sklearn 库一起提供,因此您不需要单独下载数据。
使用数据集检索要素列表。feature_names属性。
从数据集中提取特征。
从数据集中提取目标。
使用 sklearn 中提供的train_test_split方法将数据拆分为训练和测试。
使用 10K 估计器初始化RandomForestClassifier 。
调用拟合方法。
训练完成后,使用feature_importances_变量检查重要性分数。似乎在鸢尾花数据集中,花瓣的长度和宽度更为重要。
预测测试集。
计算准确度分数。我们在特征选择后重新计算精度。
创建一个选择器对象,它将使用随机森林分类器来识别重要性超过 0.15 的特征。
训练选择器
通过转换仅包含重要特征的数据来创建新数据集。
使用 500 个估计器初始化一个新的RandomForestClassifier 。
适合分类器并预测新创建的X_important_test。
尽管仅使用重要特征进行训练时准确率有所下降,但数据集大小却减少了 50%。准确率下降了 2%,特征数量下降了 50%——这还不错!
即使您使用其他技术进行特征选择,随机森林也可以非常方便地快速了解哪些特征在初始实验中真正重要。
树集合的特征转换
决策树森林因其鲁棒性和高维度支持而在分类和回归任务中非常受欢迎,并且易于解释。它们也可用于提取嵌入。
嵌入是将输入投影到另一个更方便的表示空间。嵌入可以更轻松地对大输入进行机器学习,例如表示单词的稀疏向量。理想情况下,嵌入通过将语义相似的输入紧密放置在嵌入空间中来捕获输入的一些语义。可以跨模型学习和重用嵌入。如果它让你想起 word2Vec 和 gloVec,那么你对嵌入有很好的直觉!
在树集成的上下文中,森林嵌入表示使用随机森林的特征空间。
可以以有监督或无监督的方式学习编码。
在受监督的情况下,您使用针对分类或回归问题训练的森林树结构来提取嵌入。
在无监督情况下,没有目标变量;森林中的每棵树都随机生成分裂。
那么嵌入是如何产生的呢?它非常简单。
为您的分类或回归问题训练随机森林。
将样本通过每棵树并记下它最终到达的叶节点。
将叶子节点标记为1,决策树放置样本;否则,将其标记为 0。
将向量连接在一起。
形象地,可以想象该过程如图6-1所示。
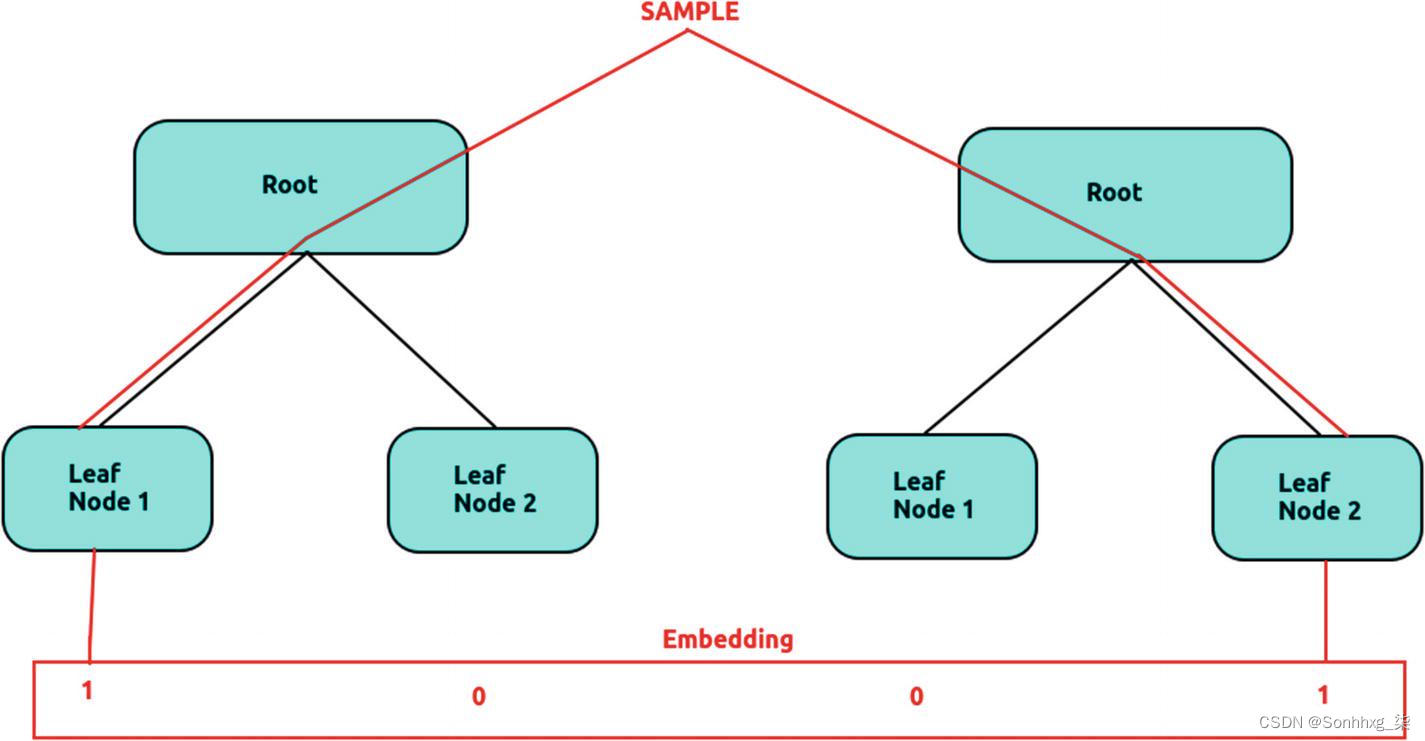
图 6-1 嵌入过程。资料来源:David Vassallo,2020 年 2 月 26 日。
让我们通过一个例子来更好地理解这一点。在图6-2所示的树中,有三个特征:收入、年龄和信用等级 (CR)。有 10 个终端节点(是/否)。最终的嵌入看起来像 [0, 0, 0, 0, 0, 0, 0, 0, 0, 1]。考虑到森林可以有数百棵相似的树,您最终会得到一个具有大量维度的嵌入。请记住,我们仅从三维特征构建了此高维数据。
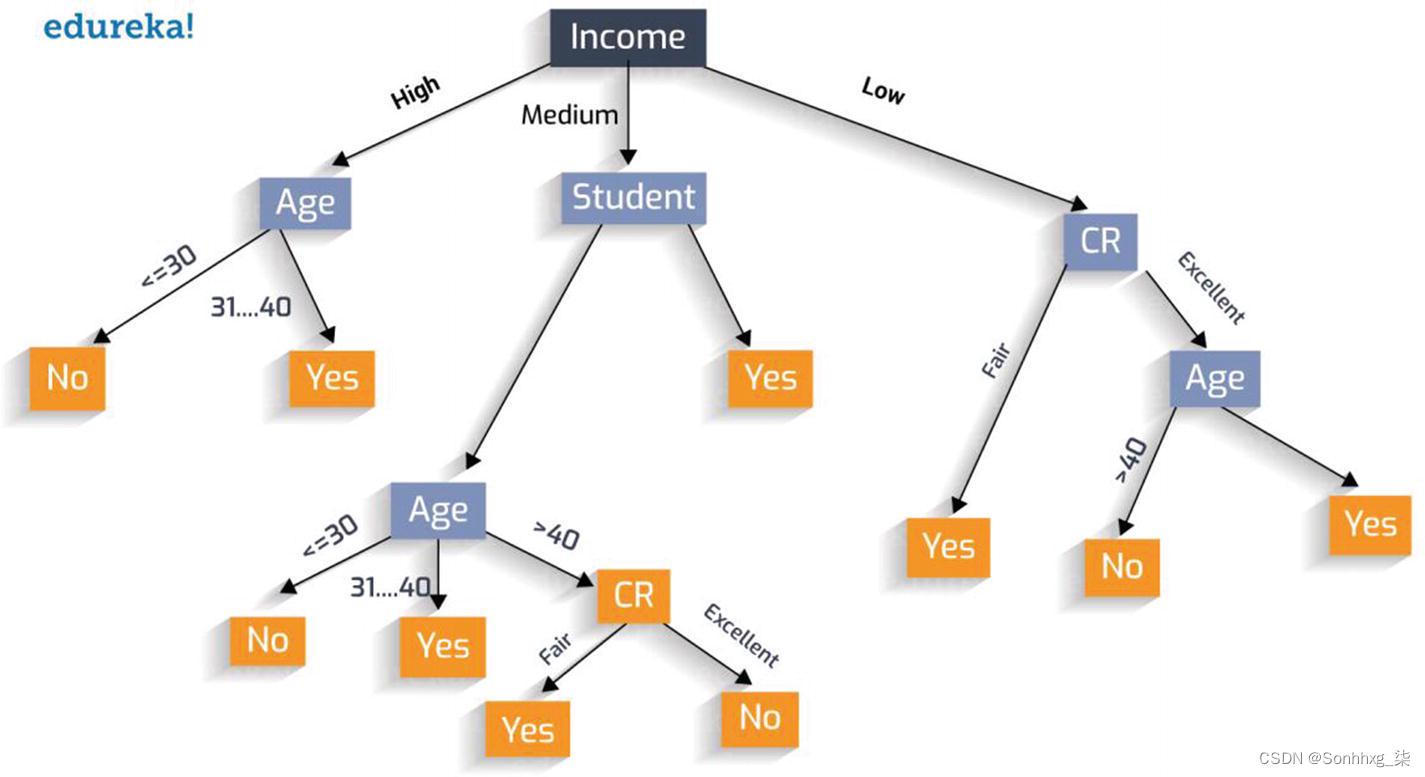
图 6-2 资料来源:Upasana Priyadarshiny,https ://dzone.com/articles/how-to-create-a-perfect-decision-tree
您可能想知道高维度的好处。在高维空间中,线性分类器通常可以实现出色的准确性。
幸运的是,我们不需要编写逻辑;sklearn 已经通过sklearn.ensemble.RandomTreesEmbedding 提供了它。 RandomTreesEmbedding是数据集到高维稀疏表示的无监督转换。数据点根据它被分类到每棵树上的哪个叶子上进行编码。使用树叶的单热编码会导致二进制编码,其数量与森林中的树木一样多。让我们检查代码中的概念。
我们将使用 sklearn 中可用的虚拟分类数据集。
X,y = make_classification(n_samples=80000)让我们检查一下数据的形状。第二个维度是这里的特征数量。
print(X.shape)(80000, 20)
让我们初始化我们的完全随机树的集合。
model = RandomTreesEmbedding(n_estimators=100, min_samples_leaf=10)在数据上拟合模型。
model.fit(X, y)将森林中的树木应用于 X 以返回叶索引。
leaves = model.apply(X)如果您现在检查叶子的形状,您会发现特征维度增加到 100。您能猜出为什么是 100 吗?
print(leaves.shape)(80000, 100)
现在,我们对叶子应用稀疏的单热编码。
M = OneHotEncoder().fit_transform(leaves)该编码已准备好进行分类或供其他机器学习算法使用。
让我们通过另一个代码示例(参见清单6-2)来比较无监督嵌入和有监督嵌入。为了进行比较,我们将特征转换为更高维的稀疏空间,然后在这些特征上训练线性模型。
n_estimator = 100
X, y = make_classification(n_samples=80000) # - 1
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.5) # - 2
X_train, X_train_lr, y_train, y_train_lr = train_test_split(X_train, y_train, test_size=0.5) # -3
rt = RandomTreesEmbedding(max_depth=3, n_estimators=n_estimator,random_state=0) # -4
rt_lm = LogisticRegression(max_iter=1000) # -5
pipeline = make_pipeline(rt, rt_lm) #-6
pipeline.fit(X_train, y_train)
y_pred_rt = pipeline.predict_proba(X_test)[:, 1]
fpr_rt_lm, tpr_rt_lm, _ = roc_curve(y_test, y_pred_rt) #-7清单 6-2 灵感来自scikit-learn 文档
让我们解压代码。
1.使用 sklearn 中可用的虚拟分类数据集。
2.在训练和测试中拆分数据。我们仅使用sklearn中的 train_test_split。
3.在与线性回归模型不同的训练数据子集上训练树的集合,以避免过度拟合。
4.初始化树集合。
5.初始化逻辑回归。
6.创建一个将随机树集合连接到逻辑回归的管道。
7.训练管道,计算测试集上的概率估计,然后计算 roc_curve 值。
重申一下,前面的代码用于使用完全随机树的无监督转换。接下来,我们将使用随机森林进行监督转换。
rf = RandomForestClassifier(max_depth=3, n_estimators=n_estimator)
rf_enc = OneHotEncoder()
rf_lm = LogisticRegression(max_iter=1000)
rf.fit(X_train, y_train) # -8
rf_enc.fit(rf.apply(X_train)) # -9
rf_lm.fit(rf_enc.transform(rf.apply(X_train_lr)), y_train_lr) # -10
y_pred_rf_lm = rf_lm.predict_proba(rf_enc.transform(rf.apply(X_test)))[:, 1] #-11
fpr_rf_lm, tpr_rf_lm, _ = roc_curve(y_test, y_pred_rf_lm) # -12让我们解压代码。
1.在数据上训练随机森林分类器。
2.将森林中的树应用于数据 (X_train),然后将 one-hot 编码器拟合到返回的叶索引上。
3.将森林中的树应用于逻辑回归数据子集,使用较早训练的单热编码器对其进行转换,并在其上拟合逻辑回归模型。
4.计算测试集上的概率估计,然后计算 roc_curve 值。
重申一下,前面的代码用于使用随机森林进行监督转换。接下来,我们将使用梯度提升树进行监督转换。
该代码几乎与我们为随机森林所做的相同。
grd = GradientBoostingClassifier(n_estimators=n_estimator)
grd_enc = OneHotEncoder()
grd_lm = LogisticRegression(max_iter=1000)
grd.fit(X_train, y_train)
grd_enc.fit(grd.apply(X_train)[:, :, 0])
grd_lm.fit(grd_enc.transform(grd.apply(X_train_lr)[:, :, 0]), y_train_lr)
y_pred_grd_lm = grd_lm.predict_proba(grd_enc.transform(grd.apply(X_test)[:, :, 0]))[:, 1]
fpr_grd_lm, tpr_grd_lm, _ = roc_curve(y_test, y_pred_grd_lm)为了进行比较,让我们计算梯度提升和随机森林模型的 roc_curve。
y_pred_grd = grd.predict_proba(X_test)[:, 1]
fpr_grd, tpr_grd, _ = roc_curve(y_test, y_pred_grd)
y_pred_rf = rf.predict_proba(X_test)[:, 1]
fpr_rf, tpr_rf, _ = roc_curve(y_test, y_pred_rf)让我们绘制所有选项的 roc_curve。
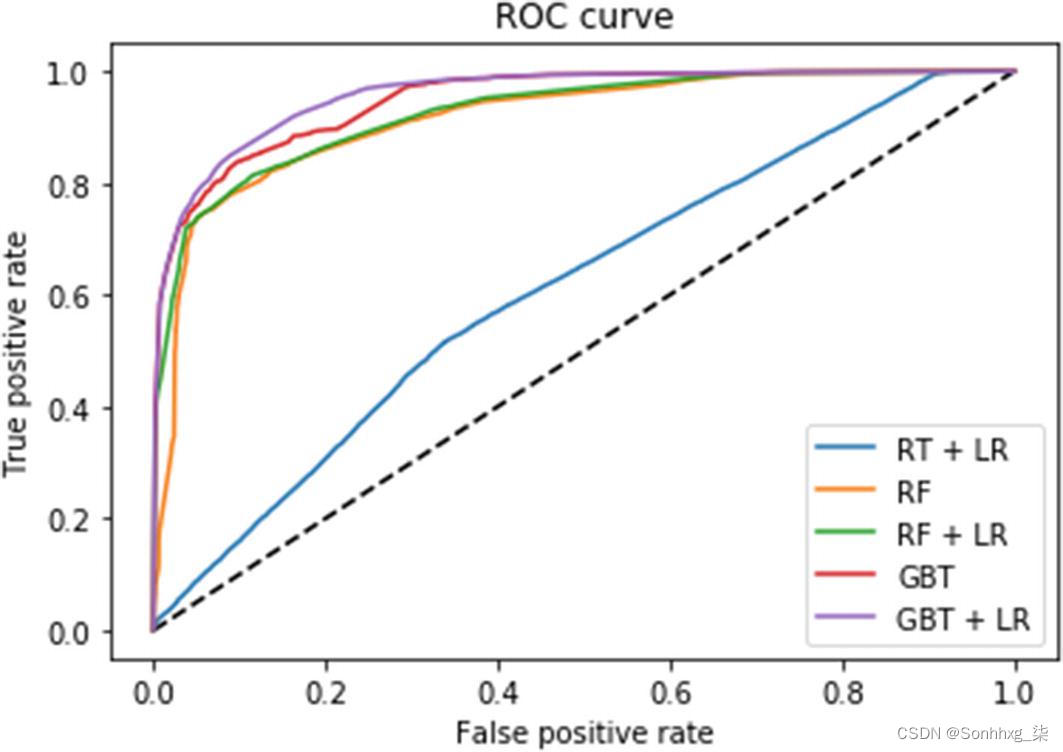
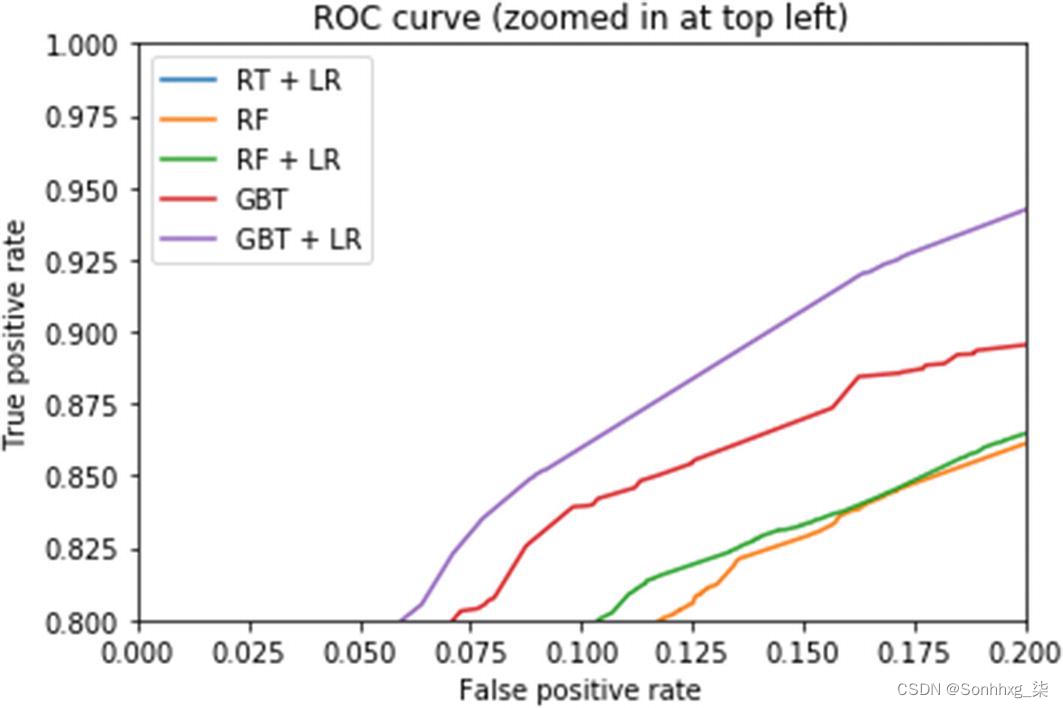
很明显,基于集成的嵌入 是线性分类任务的一个很好的预处理步骤。
为随机森林分类器构建预处理管道
在理想世界中,数据是完美的。不幸的是,我们并不是生活在一个完美的世界中。在集成模型之前,数据需要进行预处理。感谢 sklearn,有强大的构建块可以有效地设置预处理管道。
我们将使用sklearn.pipeline.Pipeline 和随机森林分类模型构建一个结合预测的预处理管道。我们将使用泰坦尼克号数据集为幸存者构建一个二元分类器。
分类器将使用以下数字特征进行训练。
# - age: float.
# - fare: float.
它将使用以下分类特征进行训练。
# - embarked: categories encoded as strings {'C', 'S', 'Q'}.
# - sex: categories encoded as strings {'female', 'male'}.
# - pclass: ordinal integers {1, 2, 3}.
让我们使用fetch_openML获取数据集,它从openml. org存储库下载数据。openml.org是机器学习数据和实验的公共存储库;它允许任何人上传开放数据集。从 sklearn 0.22.2 开始,您可以指定as_frame参数以将数据作为dataframe返回。这对于探索和实验非常有用。
np.random.seed(0)
X, y = fetch_openml("titanic", version=1, as_frame=True, return_X_y=True)让我们探索数据集。info() 方法对于获取数据的快速描述很有用;特别是总行数、每个属性的类型和非空值的数量。
X.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 1309 entries, 0 to 1308
Data columns (total 13 columns):
pclass 1309 non-null float64
name 1309 non-null object
sex 1309 non-null category
age 1046 non-null float64
sibsp 1309 non-null float64
parch 1309 non-null float64
ticket 1309 non-null object
fare 1308 non-null float64
cabin 295 non-null object
embarked 1307 non-null category
boat 486 non-null object
body 121 non-null float64
home.dest 745 non-null object
请注意,虽然有 1309 个实例,但年龄列只有 1046 个值表示缺失值。我们需要处理管道中的缺失值。
让我们探索分类字段。您可以为它使用value_counts 方法 。此方法告诉您类别总数和每个类别的条目数。
X['pclass'].value_counts()3.0 709
1.0 323
2.0 277
X['sex'].value_counts()male 843
female 466
X['embarked'].value_counts()S 914
C 270
Q 123
让我们为数字和分类数据创建预处理管道。
所有缺失的年龄值将被替换为中值策略(即年龄列的中值)。您可以轻松猜出其他潜在策略。
如果是 mean,则使用每列的平均值替换缺失值。这只能用于数字数据。
如果是median,则使用每列的中位数替换缺失值。这只能用于数字数据。
如果most_frequent,则使用每列中出现频率最高的值替换缺失值。这可以与字符串或数字数据一起使用。
如果是常量,则用 fill_value 替换缺失值。这可以与字符串或数字数据一起使用。
StandardScaler通过移除均值并缩放到单位方差来标准化特征。
样本的标准分数x的计算公式为
z = ( x - u ) / s
其中u是训练样本的平均值,如果with_mean=False则为零,s是训练样本的标准差,如果with_std=False 则为 1。
数据集的标准化是许多机器学习估计器的共同要求。如果个别特征不类似于标准正态分布数据(例如,具有 0 均值和单位方差的高斯分布),它们可能表现不佳。请注意,随机森林和梯度提升对变量的大小不敏感。因此,在拟合这些模型之前不需要标准化。为了完整起见,将它们添加到此处。
numeric_features = ['age', 'fare']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])OneHotEncoder 将分类特征编码为单热数值数组。这个转换器的输入应该是类似数组的整数或字符串,表示分类(离散)特征所采用的值。
categorical_features = ['embarked', 'sex', 'pclass']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value="missing")),
('onehot', OneHotEncoder(handle_unknown='ignore'))])到目前为止,我们已经分别创建了分类和数字列转换器。但是,拥有一个可以处理所有列并自动将适当的转换应用于每一列的转换器会更方便。在 0.20 版本中,scikit-learn 引入了ColumnTransformer,它提供了这个特性。它也适用于 Pandas 数据框。
rom sklearn.compose import ColumnTransformer
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])首先,您需要导入ColumnTransformer类 。接下来,您使用数字和分类列名称列表初始化 ColumnTransformer。构造函数需要一个元组列表,其中每个元组包含一个名称、一个转换器和一个转换器应应用于的列的名称(或索引)列表。
在我们的例子中,numeric_features 应该使用numeric_transformer进行转换,而categorical_features应该使用categorical_transformer进行转换。
我们的管道几乎准备就绪。我们最后需要添加分类器,在我们的例子中是随机森林。
rnd_clf = RandomForestClassifier(n_estimators=255,n_jobs=-1)
pipeline = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', rnd_clf)])如果我们在将数据输入管道之前将其拆分为训练和测试,会不会令人感到意外?
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)最后,是时候让管道适应数据了。
pipeline.fit(X_train, y_train)
print("model score: %.3f" % clf.score(X_test, y_test))你有没有注意到我们的随机森林是用 255 个估计器初始化的?这个数字是从哪里来的?好吧,我们使用网格搜索来找到最佳参数。事实上,对于现实世界的问题,通过搜索(网格搜索、随机搜索等)优化的流水线是常态。让我们将网格搜索添加到我们的管道中。
首先,我们需要导入GridSearchCV 。接下来,我们需要定义我们感兴趣的所有参数的搜索空间。
from sklearn.model_selection import GridSearchCV
# 随机森林中的树数
n_estimators = [int(x) for x in np.linspace(start = 100, stop = 300, num = 10)]
# 每次分割要考虑的特征数量
max_features = ['auto', 'sqrt']
# 树的最大层数
max_depth = [int(x) for x in np.linspace(10, 110, num = 11)]
max_depth.append(None)
# 分裂节点所需的最小样本数
min_samples_split = [2, 5, 10]
# 每个叶节点所需的最小样本数
min_samples_leaf = [1, 2, 4]
# 选取样本训练每棵树的方法
bootstrap = [True, False]接下来,我们准备参数网格。请注意,我们是否使用转换器名称和双下划线将参数映射到特定转换器。
grid = {'classifier__n_estimators': n_estimators,
'classifier__max_features': max_features,
'classifier__max_depth': max_depth,
'classifier__min_samples_split': min_samples_split,
'classifier__min_samples_leaf': min_samples_leaf,
'classifier__bootstrap': bootstrap}以下是我们的参数搜索空间的样子。
pprint(grid)pprint(grid)
{'classifier__bootstrap': [True, False],
'classifier__max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 110, None],
'classifier__max_features': ['auto', 'sqrt'],
'classifier__min_samples_leaf': [1, 2, 4],
'classifier__min_samples_split': [2, 5, 10],
'classifier__n_estimators': [100, 122, 144, 166, 188, 211, 233, 255, 277, 300]}
让我们初始化GridSearchCV。
search = GridSearchCV(estimator = pipeline,param_grid = grid, cv = 3, verbose=2, n_jobs = -1)是时候拟合网格搜索模型了。
search.fit(X_train, y_train)您可以通过best_params_ 属性检查最佳参数值。
print(search.best_params_){'classifier__bootstrap': True, 'classifier__max_depth': 10, 'classifier__max_features': 'auto', 'classifier__min_samples_leaf': 2, 'classifier__min_samples_split': 10, 'classifier__n_estimators': 255 }
管道和网格搜索不是特定于集成的,但知道如何将它们有效地与集成一起使用会导致非常准确的集成。
用于离群值检测的隔离林
隔离森林是异常 值检测的有效算法,尤其是在高维数据集中。该算法通过选择随机特征和随机阈值(在最小值和最大值之间)来分割数据集来构建随机森林。数据集拆分一直持续到所有实例最终与其他实例隔离为止。离群值的出现频率低于常规观察值,并且通常具有不同的值。平均而言(在所有决策树中),与正常实例相比,它们倾向于以更少的步骤被隔离。让我们从视觉上看一下。
在图6-3中,红色点表示异常点。
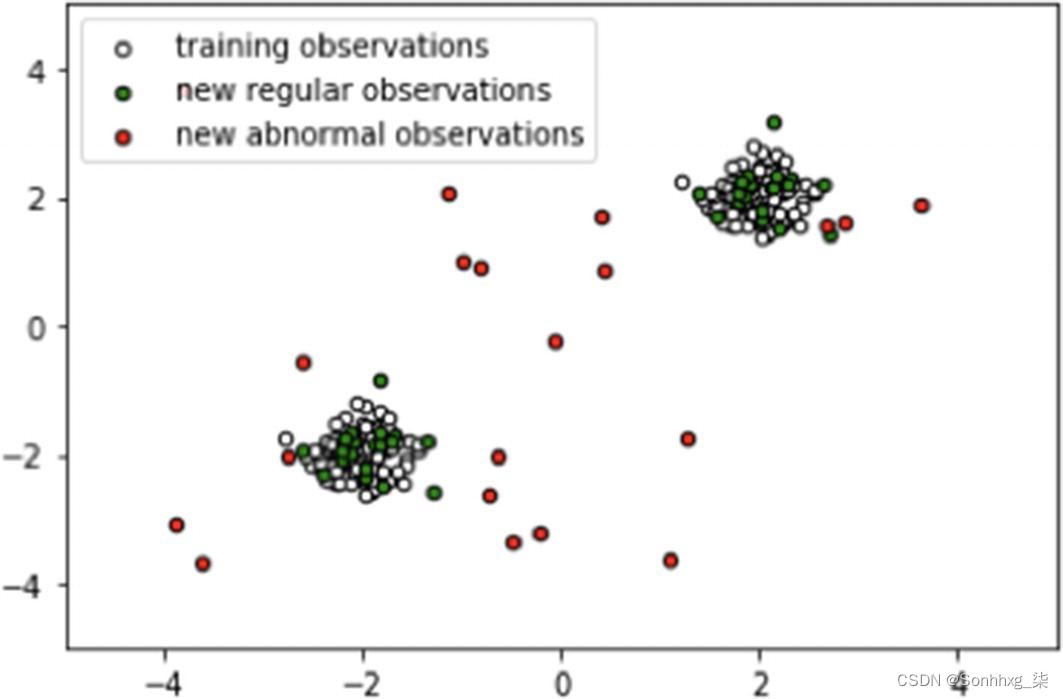
图 6-3 包含常规和异常观察的虚拟数据集
如您所见,正常点聚集在一起,而异常点则离其他点更远。因此,在随机划分域空间的同时,在比正常点更少的分区中检测到异常。分区数越少表示距根节点的距离越短(即从根节点到达终端节点所经过的边数越少)。隔离样本所需的分裂(或分区)数等于从根节点到终止节点的路径长度。
随机分区会为异常产生明显更短的路径。因此,当随机树的森林共同为特定样本产生较短的路径长度时,它们很可能是异常的。图6-4和6-5说明了这一点。

图 6-4 隔离法线点
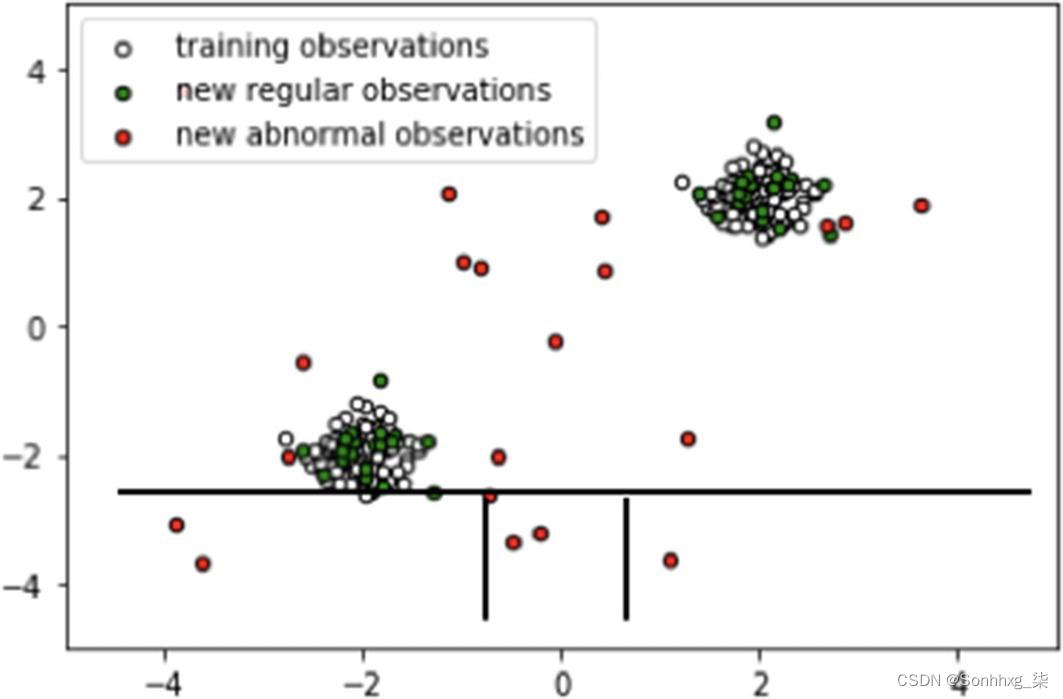
图 6-5 隔离异常点
一个点是正常点还是异常点由路径长度指示。隔离森林算法返回每个样本的异常分数。
将分数解释为概率,有助于表示 0 到 1 之间的分数。例如,如果我们得到 0.7 的异常分数,那么我们解释该点有 70% 的概率是异常点。
现在您已经了解隔离林的工作原理,让我们在代码中使用实现。
让我们首先导入必要的模块。为简洁起见,我们删除了一些导入。
from sklearn.ensemble import IsolationForest
rng = np.random.RandomState(42)让我们生成数据。训练和测试的常规新观察值是从标准正态分布生成的,而异常值是从均匀分布生成的。
# 训练数据
X = 0.3 ∗ rng.randn(100, 2)
X_train = np.r_[X + 2, X - 2]
# 正常的小说观察
X = 0.3 ∗ rng.randn(20, 2)
X_test = np.r_[X + 2, X - 2]
# 异常的小说观察
X_outliers = rng.uniform(low=-4, high=4, size=(20, 2))现在是初始化和适应隔离林的时候了。
clf = IsolationForest(max_samples=100, random_state=rng)
clf.fit(X_train)训练好模型后,就可以生成预测了。
y_pred_train = clf.predict(X_train)
y_pred_test = clf.predict(X_test)
y_pred_outliers = clf.predict(X_outliers)让我们绘制和可视化(见图6-6)隔离森林的预测。
xx, yy = np.meshgrid(np.linspace(-5, 5, 50), np.linspace(-5, 5, 50))
Z = clf.decision_function(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.title("IsolationForest")
plt.contourf(xx, yy, Z, cmap=plt.cm.Blues_r)
b1 = plt.scatter(X_train[:, 0], X_train[:, 1], c="white",
s=20, edgecolor="k")
b2 = plt.scatter(X_test[:, 0], X_test[:, 1], c="green",
s=20, edgecolor="k")
c = plt.scatter(X_outliers[:, 0], X_outliers[:, 1], c="red",
s=20, edgecolor="k")
plt.axis('tight')
plt.xlim((-5, 5))
plt.ylim((-5, 5))
plt.legend([b1, b2, c],
["training observations",
"new regular observations", "new abnormal observations"],
loc="upper left")
plt.show()
图 6-6 孤立森林预测
与其他异常值检测算法相比,隔离森林非常独特。它介绍了使用隔离作为一种比常用的基本距离和密度测量更有效和高效的异常检测方法。无论数据集的大小如何,它都使用固定大小的小子样本来构建具有少量树的性能良好的模型。
使用 Dask 扩展集成
在集成时,您可能会遇到两个截然不同的缩放问题。扩展策略取决于您面临的问题。
大型模型:尽管数据适合 RAM,但您可能拥有许多模型的大型集合。
大型数据集:数据大于 RAM,采样不是一种选择。
Dask 可以帮助扩展集成。
对于大型模型,请使用dask_ml.joblib和您最喜欢的 scikit-learn 估算器。
对于大型数据集,请使用dask_ml估计器。
要扩展集成管道,您需要超越大型模型和数据集。回忆管道和网格搜索。Dask 具有用于预处理和参数空间搜索的模块。
预处理
dask_ml.preprocessing 包含一些 scikit-learn 风格的转换器,可用于管道中以执行各种数据转换,作为模型拟合过程的一部分。这些转换器在 Dask 集合(dask.array、dask.dataframe)、 NumPy arrays或Pandas dataframes 上运行良好。再次重申,为什么要使用 Dask 进行预处理?嗯,它适合并并行转换。
表6-1列出了一些转换 器(大部分)是它们的 scikit-learn 对应物的直接替代品。
表 6-1。 Dasks 替换 scikit-learn 对应的Transformer
Transformer | 描述 |
MinMaxScaler([feature_range, copy]) | 通过将每个特征缩放到给定范围来转换特征。 |
QuantileTransformer([n_quantiles, …]) | 使用分位数信息转换特征。 |
RobustScaler([with_centering, with_scaling, …]) | 使用对异常值具有鲁棒性的统计数据来缩放特征。 |
StandardScaler([copy,with_mean,with_std]) | 通过移除均值并缩放到单位方差来标准化特征。 |
LabelEncoder([use_categorical]) | 使用 0 到 n_classes-1 之间的值对标签进行编码。 |
使用dask_ml.preprocessing 时要记住两件重要的事情 。
它们并行操作 Dask 集合。
. 当输入是 Dask 集合时,transform返回dask.array或dask.dataframe 。
表6-2列出了一些其他有助于将非数字数据转换为数字数据的Dask转换器。
表 6-2。 将数字数据转换为数字数据的 Dask 转换器
Transformer | 描述 |
Categorizer([categories, columns]) | 将 DataFrame 列转换为分类数据类型。 |
DummyEncoder([columns,drop_first]) | 虚拟(单热)编码分类列。 |
OrdinalEncoder([columns]) | 序数(整数)编码分类列。 |
这些转换器可用作管道中的预处理步骤,您从异构数据(数字和非数字的混合)开始,但估算器需要所有数字数据。
让我们通过一个玩具管道来检查代码中的转换 器。我们的管道将
对文本数据进行分类
虚拟编码分类数据
适合 RandomForestClassifier
让我们导入必要的库。
from dask_ml.preprocessing import Categorizer, DummyEncoder
from sklearn.linear_model import RandomForestClassifier
from sklearn.pipeline import make_pipeline
import pandas as pd
import dask.dataframe as dd从 Pandas 数据帧初始化 Dask 数据帧。
df = pd.DataFrame({"A": [1, 2, 1, 2], "B": ["a", "b", "c", "c"]})
X = dd.from_pandas(df, npartitions=2)
y = dd.from_pandas(pd.Series([0, 1, 1, 0]), npartitions=2)构建并安装管道。
pipe = make_pipeline(Categorizer(),DummyEncoder(),RandomForestClassifier())
pipe.fit(X, y)如果您对管道有一般的了解,那么代码是不言自明 的,但为了完整起见,以下是一个快速解释。
分类器将 X 中的列子集转换为分类数据类型。默认情况下,它转换所有对象 dtype 列。
DummyEncoder 虚拟(或单热)编码数据集。这会将分类列替换为多个列,其中值为 0 或 1。
我们鼓励您阅读 sklearn.preprocessing 文档 ( https://scikit-learn.org/stable/modules/preprocessing.html ) 以了解有关可用转换 器的更多信息。
超参数搜索
Dask-ML 中有两种超参数优化估计器。使用哪种合适取决于数据集的大小以及底层估计器是否实现了partial_fit方法。
如果数据集相对较小或底层估计器未实现 partial_fit,则可以使用dask_ml.model_selection.GridSearchCV或dask_ml.model_selection.RandomizedSearchCV 。这些是 scikit-learn 对应物的直接替代品;他们应该提供更好的性能和处理 Dask 数组和数据帧。
scikit-learn 的直接替换
dask_ml.model_selection.GridSearchCV | 对估计器的指定参数值进行详尽搜索。 |
dask_ml.model_selection.RandomizedSearchCV | 对超参数进行随机搜索。 |
增量超参数优化
第二类超参数优化使用增量超参数优化。当您的完整数据集不适合单台机器的内存时,应该使用这些。
在 Dask 中,dask_ml.model_selection.IncrementalSearchCV是处理这个的类。此类在支持partial_fit的模型上增量搜索超参数。
从广义上讲,增量优化从一批模型(底层估计器和超参数组合)开始,并用批次数据重复调用底层估计器的 partial_fit 方法。
阅读文档以了解更多信息。
分布式集成拟合
其余部分 是集成拟合和预测。重申一下,我们正在探索如何将 Dask 用于集成训练和预测。
让我们考虑一种情况,我们使用 scikit-learn 估计器,但数据集大于内存。Dask 确保不会一次加载所有数据。
让我们导入必要的库。
from sklearn import datasets
from sklearn.ensemble import GradientBoostingClassifier
import dask_ml.datasets
from dask_ml.wrappers import ParallelPostFit唯一新导入的是dask_ml数据集和ParallelPostFit。
dask_m.datasets相当于 sklearn.datasets 。我们用它来创建一个大型玩具数据集。
ParallelPostFit是用于并行预测和转换的元估计器。将其视为分布式评分函数(在 sklearn 中)。需要注意的是,此类不适用于大型数据集的并行或分布式训练。为此,请使用 Dask Incremental;它提供分布式(但顺序)培训。
让我们制作一个 1000 个样本的小型训练数据集并正常拟合。
X, y = datasets.make_classification(n_samples=1000, random_state=0)
clf = ParallelPostFit(estimator=GradientBoostingClassifier(),
scoring='accuracy')
clf.fit(X, y)让我们构建一个更大的玩具数据集。
X_big, y_big = dask_ml.datasets.make_classification(n_samples=100000,
random_state=0)对新 Dask 输入的预测与您在sklearn 中所做的没有什么不同。这里的亮点是分类器适用于大于内存的预测数据集。
clf.predict(X_big)
现在让我们构建一个投票分类器。回想一下,投票分类器模型将多个模型(即子估计器)组合成一个模型,该模型(理想情况下)比单独 的任何单个模型都要强。
但是为什么要使用 Dask?Dask 提供了在集群中的不同机器上训练单个子估计器的软件。这使用户能够并行训练比在单台机器上训练更多的模型。让我们在代码中使用 Dask 探索投票分类器。
让我们导入必要的模块。
from sklearn.ensemble import VotingClassifier
from sklearn.linear_model import SGDClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.svm import SVC
import sklearn.datasets
X, y = sklearn.datasets.make_classification(n_samples=1_000, n_features=20)
classifiers = [
('sgd', SGDClassifier(max_iter=1000)),
('rf', RandomForestClassifier()),
('svc', SVC(gamma='auto')),
]
clf = VotingClassifier(classifiers, n_jobs=-1)您在前面的章节 中看到了所有这些代码。
让我们初始化dask 分布式集群。同样,我们在第5章中讨论了这一点。
import joblib
from distributed import Client
client = Client()
with joblib.parallel_backend("dask"):
clf.fit(X, y)这个熟悉的代码是使用 Dask 扩展集成的好处和优点。关键要点是记住可用于集成管道的预处理、训练和预测任务的可扩展选项。
概括
让我们快速回顾一下本章所涵盖的内容。
随机森林在学习哪些特征重要方面非常方便。您可以使用估算器的feature_importances_变量。
森林嵌入表示使用随机森林的特征空间。嵌入为特征提供了更高的维度,这有助于线性分类器实现出色的准确性。
sklearn 为构建集成预处理管道提供了一个很好的工具集。sklearn.pipeline可以构建一个转换器管道。
sklearn ColumnTransformer提供了一种一致的方式来连接管道。
隔离森林是异常值检测的有效算法,尤其是在高维数据集中。它通过随机选择一个特征然后随机选择所选特征的最大值和最小值之间的分割值来隔离观察。
dask_ml.preprocessing包含一些 scikit-learn 风格的转换器,可用于管道中以执行各种数据转换,作为模型拟合过程的一部分。
Dask-ML 中有两种超参数优化估计器。使用哪种合适取决于数据集的大小以及底层估计器是否实现了partial_fit方法。
Dask ParallelPostFit是一个用于并行预测和转换的元估计器。
Dask 提供了在集群中的不同机器上训练单个子估计器的软件。这使用户能够并行训练更多的模型,而不是在单台机器上。
相关文章
- Docker 实用的使用技巧
- 使用Unity3D的50个技巧:Unity3D最佳实践
- GDB的两个技巧
- mac的使用小技巧
- Shell 四剑客sed 之生产环境上,最常用的一套“Sed“技巧
- 一个快速找到Spring框架是在哪里找到XML配置文件并解析Beans定义的小技巧
- Database之SQL:SQL在线编程、工作中常用SQL代码实践之查询-SQL问题分析解决思路、高级案例SQL语法拆解(单技巧各自用法详细分类/多技巧组合用法)、经典组合案例实战之详细攻略
- 技术分享丨数据仓库的建模与ETL实践技巧
- 9个 value_counts() 的技巧,提高 Python 数据分析效率
- 深度盘点:Python 7种提效增速的技巧
- 10 个让你惊叹的 Python 技巧,第 9 款是我的最爱!
- python数据存储技巧
- c语言编程小技巧-if空语句用法
- 【编程实践】帮助您节省时间和编写更简单查询的 SQL 技巧
- C语言使用技巧(二十):万能模板【拿走不谢】:VS CODE配置C/C++编译环境
- 【SQL开发实战技巧】系列(二十九):数仓报表场景☞简单的树形(分层)查询以及如何确定根节点、分支节点和叶子节点
- 手机数据抓包以及wireshark技巧
- OJ常用技巧
- X86逆向15:OD脚本的编写技巧
- 【Kubernetes】高级技巧:秘密、ConfigMaps详细解析解析
- 【编程技巧】Stream流之list转map、分组取每组第一条
- C++使用技巧(十五):类构造函数 与 析构函数