
requests爬虫实战:某基金信息爬取
爬虫 实战 信息 requests 爬取 基金
2023-09-14 09:14:35 时间
一、请求探索
网页分析:
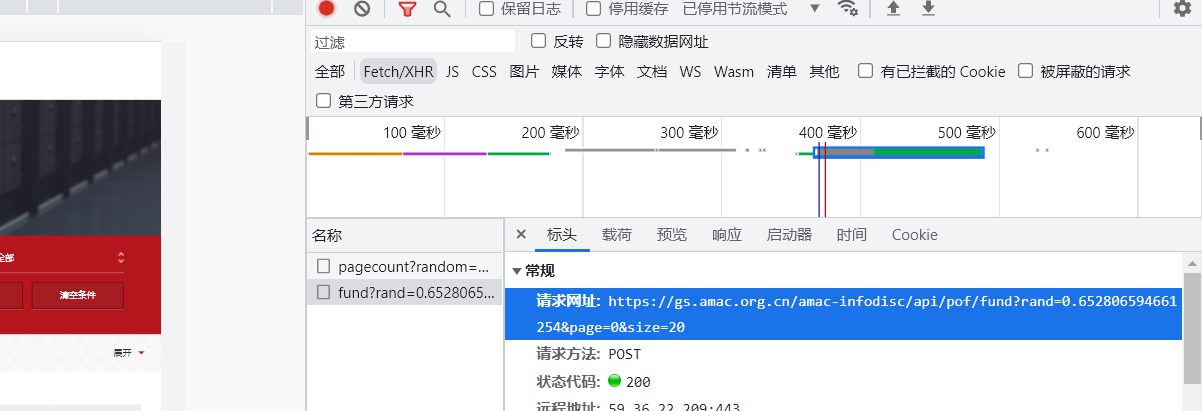
页码分析:
1.第一页:https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.652806594661254&page=0&size=20
2. 第二页: https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.652806594661254&page=1&size=20
3. https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.652806594661254&page=2&size=20
单数刷新一下rand发生变化:似乎就是是一个随机数
https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand=0.16767992415199218&page=0&size=20
规律变化:页码部分需要调整,rand部分随机的。
https://gs.amac.org.cn/amac-infodisc/api/pof/fund?rand={}&page={}&size=20
也可以通过JS查看确定一下就是用的一个随机函数:
相关文章
- SpringBoot 入门爬虫项目实战
- 【python】秀人集-写真集-爬虫-1.0「建议收藏」
- 爬虫课第一次报错总结
- python 基于aiohttp的异步爬虫实战
- python爬虫爬图片教程_爬虫爬取图片的代码
- 小站独家PDF | 2015年肿瘤口中标青年项目摘要~~站长开启R爬虫技能
- 编写一个爬虫的思路,当遇到反爬时如何处理
- 爬虫实战-豆瓣电影Top250
- Python爬虫如何设置静态IP代理定时自动更换IP代理?
- Python无框架分布式爬虫,爬取范例:拼多多商品详情数据,拼多多商品列表数据
- Python3.X 爬虫实战缓存与持久化详解程序员
- 爬虫采集舆情数据的方案
- 原来爬虫是用Redis才行(爬虫为什么用redis)
- 爬虫以Redis创建队列保存爬取结果(爬虫redis构建队列)
- 使用BeautifulSoup爬虫程序获取百度搜索结果的标题和url示例
- 零基础写Java知乎爬虫之准备工作