
【Apache Spark 】第 8 章结构化流
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
从 Spark Streaming (DStreams) 中吸取的教训
使用自定义 StreamingQueryListeners 发布指标
使用 mapGroupsWithState() 对任意状态操作进行建模
在前面的章节中,您学习了如何使用结构化 API 来处理非常大但数量有限的数据。但是,通常数据是连续到达的,需要实时处理。在本章中,我们将讨论如何使用相同的结构化 API 来处理数据流。
Apache Spark 流处理引擎的演进
流处理被定义为对无穷无尽的数据流的连续处理。随着大数据的出现,流处理系统从单节点处理引擎转变为多节点分布式处理引擎。传统上,分布式流处理是通过一次记录处理模型实现的,如图 8-1 所示。

图 8-1。传统的一次记录处理模型
处理流水线由节点的有向图组成,如图8-1所示;每个节点一次连续接收一条记录,对其进行处理,然后将生成的记录转发到图中的下一个节点。这种处理模型可以实现非常低的延迟——也就是说,输入记录可以由管道处理,并且可以在几毫秒内生成结果输出。但是,该模型在从节点故障和散乱的节点(即比其他节点慢的节点)中恢复时效率不高;它可以通过大量额外的故障转移资源快速从故障中恢复,或者使用最少的额外资源但恢复缓慢。1
微批处理流处理的出现
这种传统方法在引入 Spark Streaming(也称为 DStreams)时受到 Apache Spark 的挑战。它引入了微批处理流处理的概念,其中流计算被建模为小块流数据上的一系列连续的小型 map/reduce 式批处理作业(因此,“微批处理”)。如图 8-2所示。
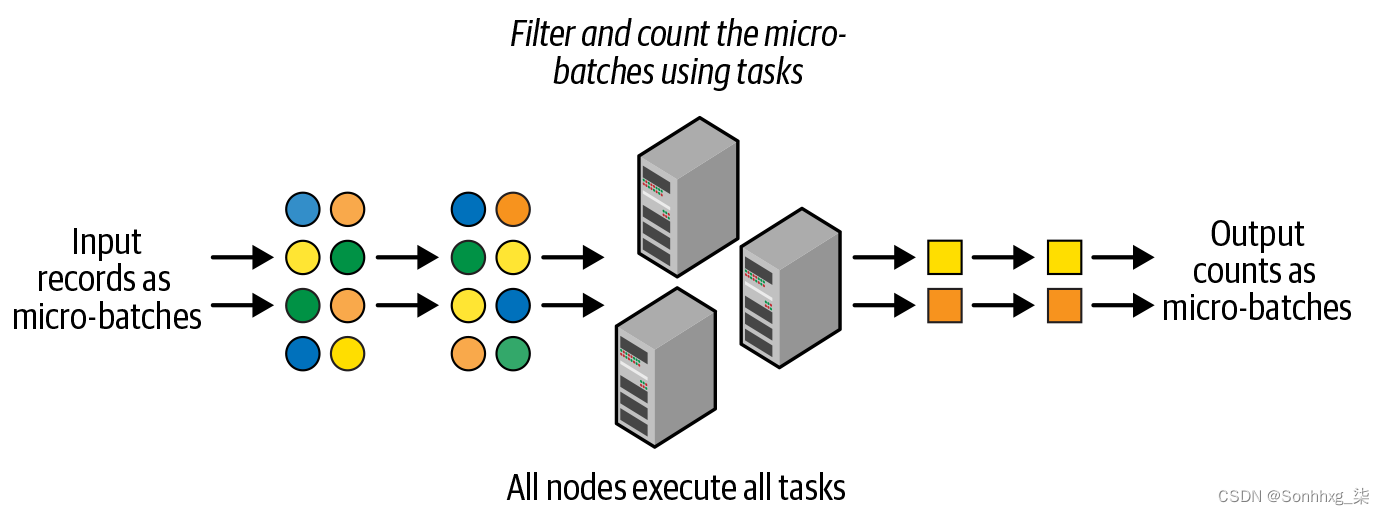
图 8-2。结构化流式处理使用微批处理模型
如此处所示,Spark Streaming 将输入流中的数据划分为 1 秒的微批次。每个批次在 Spark 集群中以分布式方式处理,具有小的确定性任务以微批次的形式生成输出。将流计算分解为这些小任务,与传统的连续算子模型相比,我们有两个优势:
-
Spark 的敏捷任务调度可以通过在任何其他执行器上重新调度任务的一个或多个副本来非常快速有效地从故障和落后的执行器中恢复。
-
任务的确定性确保无论任务被重新执行多少次,输出数据都是相同的。这一关键特性使 Spark Streaming 能够提供端到端的一次性处理保证,即生成的输出结果将使得每个输入记录都被处理一次。
这种高效的容错确实是以延迟为代价的——微批处理模型无法实现毫秒级的延迟;它通常会达到几秒的延迟(在某些情况下低至半秒)。然而,我们观察到,对于绝大多数流处理用例,微批处理的好处超过了秒级延迟的缺点。这是因为大多数流式传输管道至少具有以下特征之一:
-
管道不需要低于几秒的延迟。例如,当流输出仅由每小时作业读取时,生成具有亚秒级延迟的输出是没有用的。
-
管道的其他部分存在较大的延迟。例如,如果将传感器写入 Apache Kafka(用于摄取数据流的系统)进行批处理以实现更高的吞吐量,那么下游处理系统中的任何优化都无法使端到端延迟低于批处理延误。
此外,DStream API 是基于 Spark 的批处理 RDD API 构建的。因此,DStreams 具有与 RDDs 相同的功能语义和容错模型。因此,Spark Streaming 证明了单个统一的处理引擎可以为批处理、交互式和流式工作负载提供一致的 API 和语义。这种流处理的基本范式转变推动 Spark Streaming 成为使用最广泛的开源流处理引擎之一。
从 Spark Streaming (DStreams) 中吸取的教训
尽管有所有优点,但 DStream API 并非没有缺陷。以下是确定的一些需要改进的关键领域:
缺乏用于批处理和流处理的单一 API
尽管 DStreams 和 RDDs 具有一致的 API(即相同的操作和相同的语义),开发人员在将批处理作业转换为流式作业时仍然必须显式地重写他们的代码以使用不同的类。
逻辑计划和物理计划之间缺乏分离
Spark Streaming 以开发人员指定的相同顺序执行 DStream 操作。由于开发人员有效地指定了确切的物理计划,因此没有自动优化的余地,开发人员必须手动优化他们的代码以获得最佳性能。
缺乏对事件时间窗口的本机支持
DStreams 仅根据 Spark Streaming 接收每条记录的时间(称为处理时间)定义窗口操作。但是,许多用例需要根据生成记录的时间(称为事件时间)而不是接收或处理记录的时间来计算窗口聚合。由于缺乏对事件时间窗口的原生支持,开发人员很难使用 Spark Streaming 构建此类管道。
结构化流的哲学
基于 DStreams 的这些经验教训,Structured Streaming 是从零开始设计的,具有一个核心理念——对于开发人员来说,编写流处理管道应该像编写批处理管道一样简单。简而言之,结构化流的指导原则是:
用于批处理和流处理的单一、统一的编程模型和接口
这个统一模型为批处理和流式工作负载提供了一个简单的 API 接口。您可以像处理批处理一样在流上使用熟悉的 SQL 或类似批处理的 DataFrame 查询(就像您在前几章中了解的那样),而将处理容错、优化和延迟数据的底层复杂性留给引擎。在接下来的部分中,我们将检查您可能编写的一些查询。
流处理的更广泛定义
大数据处理应用程序已经变得足够复杂,以至于实时处理和批处理之间的界限已经变得非常模糊。结构化流式处理的目的是将其适用性从传统的流式处理扩展到更大的应用程序类别;任何定期(例如,每隔几个小时)到连续(如传统流应用)处理数据的应用程序都应该可以使用结构化流处理来表达。
结构化流的编程模型
“表格”是开发人员在构建批处理应用程序时熟悉的一个众所周知的概念。结构化流将这一概念扩展到流应用程序,将流视为无界的、连续附加的表,如图 8-3 所示。
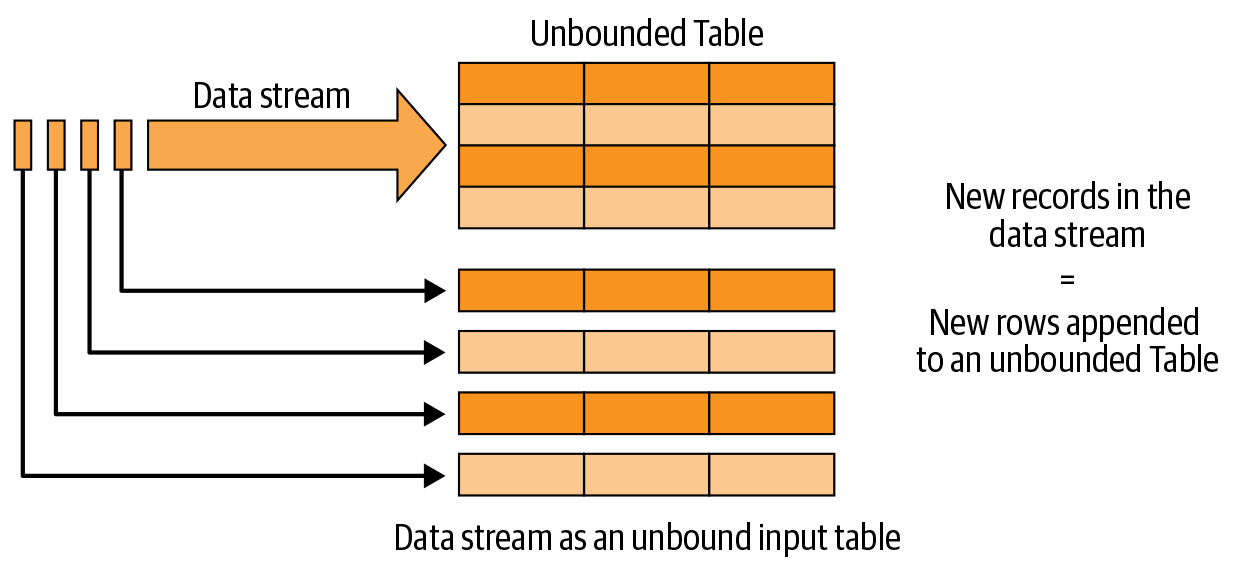
图 8-3。结构化流编程模型:作为无界表的数据流
数据流中接收到的每条新记录就像是附加到无界输入表中的新行。结构化流式处理实际上不会保留所有输入,但结构化流式处理在时间 T 之前产生的输出将等价于在静态、有界表中拥有直到 T 之前的所有输入并在该表上运行批处理作业。
如图 8-4所示,开发人员随后在这个概念输入表上定义一个查询,就好像它是一个静态表一样,以计算将写入输出接收器的结果表。结构化流式处理将自动将此类似批处理的查询转换为流式处理执行计划。这称为增量化:结构化流式处理确定每次记录到达时需要维护什么状态来更新结果。最后,开发人员指定触发策略来控制何时更新结果。每次触发触发器时,结构化流式处理都会检查新数据(即输入表中的新行)并增量更新结果。
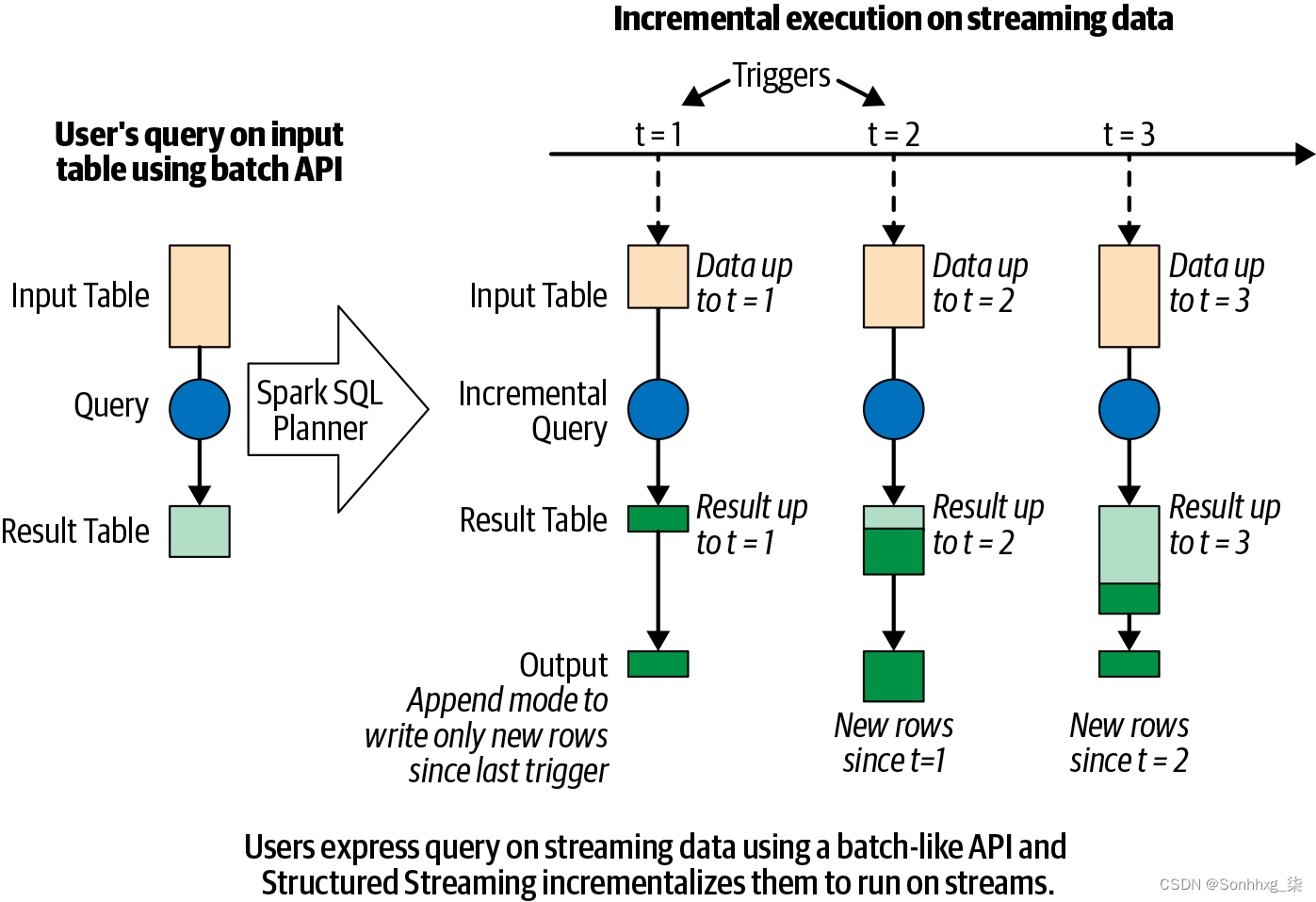
图 8-4。结构化流处理模型
模型的最后一部分是输出模式。每次更新结果表时,开发人员都希望将更新写入外部系统,例如文件系统(例如,HDFS、Amazon S3)或数据库(例如,MySQL、Cassandra)。我们通常希望增量写入输出。为此,Structured Streaming 提供了三种输出模式:
追加模式
只有自上次触发后附加到结果表的新行才会写入外部存储。这仅适用于结果表中现有行无法更改的查询(例如,输入流上的映射)。
更新模式
只有自上次触发后结果表中更新的行才会在外部存储中更改。此模式适用于可以就地更新的输出接收器,例如 MySQL 表。
完成模式
整个更新的结果表将被写入外部存储。
笔记
除非指定了完整模式,否则结构化流不会完全实现结果表。将维护足够的信息(称为“状态”)以确保可以计算结果表中的更改并可以输出更新。
将数据流视为表不仅可以更轻松地概念化数据的逻辑计算,而且还可以更轻松地在代码中表达它们。由于 Spark 的 DataFrame 是表的编程表示,因此您可以使用 DataFrame API 来表达对流数据的计算。您需要做的就是从流数据源中定义一个输入 DataFrame(即输入表),然后以与在批处理源上定义的 DataFrame 相同的方式对 DataFrame 应用操作。
在下一节中,您将看到使用 DataFrame 编写结构化流查询是多么容易。
结构化流式查询的基础知识
在本节中,我们将介绍一些高级概念,您需要了解这些概念才能开发结构化流查询。我们将首先介绍定义和启动流式查询的关键步骤,然后我们将讨论如何监控活动查询并管理其生命周期.
定义流式查询的五个步骤
如上一节所述,Structured Streaming 使用与批处理查询相同的 DataFrame API 来表达数据处理逻辑。但是,在定义结构化流查询时,您需要了解一些关键差异。在本节中,我们将通过构建一个简单的查询来探索定义流式查询所涉及的步骤,该查询通过套接字读取文本数据流并计算字数。
第 1 步:定义输入源
与批处理查询一样,第一步是从流式源定义 DataFrame。但是,在读取批处理数据源时,我们需要spark.read创建一个. 具有与 大部分相同的方法,因此您可以以类似的方式使用它。下面是从要通过套接字连接接收的文本数据流创建 DataFrame 的示例:DataFrameReaderspark.readStreamDataStreamReaderDataStreamReaderDataFrameReader
# In Python
spark = SparkSession...
lines = (spark
.readStream.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load())// In Scala
val spark = SparkSession...
val lines = spark
.readStream.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()此代码将linesDataFrame 生成为从 localhost:9999 读取的以换行符分隔的文本数据的无界表。请注意,与带有 的批处理源类似spark.read,这不会立即开始读取流数据;它仅设置显式启动流式查询后读取数据所需的配置。
除了套接字之外,Apache Spark 本身还支持从 Apache Kafka 读取数据流以及所有DataFrameReader支持的各种基于文件的格式(Parquet、ORC、JSON 等)。本章稍后将讨论这些来源及其支持的选项的详细信息。此外,流式查询可以定义多个输入源,包括流式和批处理,可以使用联合和连接等 DataFrame 操作进行组合(本章稍后也会讨论)。
第 2 步:转换数据
现在我们可以应用通常的 DataFrame 操作,例如将行拆分为单个单词,然后对它们进行计数,如下面的代码所示:
# In Python
from pyspark.sql.functions import *
words = lines.select(explode(split(col("value"), "\\s")).alias("word"))
counts = words.groupBy("word").count()// In Scala
import org.apache.spark.sql.functions._
val words = lines.select(explode(split(col("value"), "\\s")).as("word"))
val counts = words.groupBy("word").count()counts是一个流式 DataFrame(即,无界流式数据上的 DataFrame),它表示一旦启动流式查询并且正在连续处理流式输入数据时将计算的运行字数。
请注意,如果是批处理 DataFrame ,这些转换lines流式 DataFrame 的操作将以完全相同的方式工作。lines一般来说,大多数可以应用于批处理 DataFrame 的 DataFrame 操作也可以应用于流式 DataFrame。要了解结构化流式处理中支持哪些操作,您必须认识两大类数据转换:
无状态转换
select(), filter(),等操作map()不需要前行的任何信息来处理下一行;每一行都可以自己处理。这些操作中缺乏先前的“状态”使它们成为无状态的。无状态操作可以应用于批处理和流数据帧。
有状态的转换
相比之下,像这样的聚合操作count()需要维护状态以跨多行组合数据。更具体地说,任何涉及分组、加入或聚合的 DataFrame 操作都是有状态的转换。虽然结构化流中支持其中许多操作,但不支持它们的一些组合,因为以增量方式计算它们要么计算困难要么不可行。
结构化流支持的有状态操作以及如何在运行时管理它们的状态将在本章后面讨论。
第 3 步:定义输出接收器和输出模式
转换数据后,我们可以定义如何写入处理后的输出数据DataFrame.writeStream(而不是DataFrame.write,用于批处理数据)。这将创建一个DataStreamWriterwhich,类似于DataFrameWriter,具有指定以下内容的其他方法:
-
输出写入细节(在哪里以及如何写入输出)
-
处理细节(如何处理数据以及如何从故障中恢复)
让我们从输出写入细节开始(我们将在下一步中重点关注处理细节)。例如,以下代码段显示了如何将 final 写入counts控制台:
# In Python
writer = counts.writeStream.format("console").outputMode("complete")// In Scala
val writer = counts.writeStream.format("console").outputMode("complete")在这里,我们指定"console"了输出流接收器和"complete"输出模式。流式查询的输出模式指定在处理新输入数据后要写出更新输出的哪一部分。在这个例子中,当处理大量新输入数据并更新字数时,我们可以选择将迄今为止看到的所有单词的计数(即完整模式)或仅打印到控制台在最后一块输入数据中更新。这是由指定的输出模式决定的,可以是以下之一(正如我们在“结构化流的编程模型”中已经看到的那样:
追加模式
这是默认模式,只有自上次触发后添加到结果表/DataFrame(例如counts表)的新行才会输出到接收器。从语义上讲,这种模式保证输出的任何行在将来都不会被查询更改或更新。因此,仅那些永远不会修改先前输出数据的查询(例如,无状态查询)支持追加模式。相比之下,我们的字数查询可以更新之前生成的字数;因此,它不支持附加模式。
完成模式
在此模式下,结果表/DataFrame 的所有行将在每次触发结束时输出。这由结果表可能比输入数据小得多的查询支持,因此可以保留在内存中。例如,我们的字数查询支持完整模式,因为计数数据可能远小于输入数据。
更新模式
在这种模式下,只有自上次触发后更新的结果表/DataFrame 的行将在每次触发结束时输出。这与追加模式相反,因为输出行可能会被查询修改并在将来再次输出。大多数查询支持更新模式。
笔记
有关不同查询支持的输出模式的完整详细信息,请参阅最新的结构化流编程指南。
除了将输出写入控制台之外,Structured Streaming 本身还支持对文件和 Apache Kafka 的流式写入。此外,您可以使用foreachBatch()和foreach()API 方法写入任意位置。事实上,您可以使用foreachBatch()现有的批处理数据源来编写流输出(但您将失去完全一次的保证)。这些接收器的详细信息及其支持的选项将在本章后面讨论。
第 4 步:指定处理细节
开始查询之前的最后一步是指定如何处理数据的详细信息。继续我们的字数统计示例,我们将指定处理细节,如下所示:
# In Python
checkpointDir = "..."
writer2 = (writer
.trigger(processingTime="1 second")
.option("checkpointLocation", checkpointDir))// In Scala
import org.apache.spark.sql.streaming._
val checkpointDir = "..."
val writer2 = writer
.trigger(Trigger.ProcessingTime("1 second"))
.option("checkpointLocation", checkpointDir)DataStreamWriter在这里,我们使用我们创建的 指定了两种类型的详细信息DataFrame.writeStream:
触发细节
这指示何时触发新可用流数据的发现和处理。有四个选项:
默认
如果未明确指定触发器,则默认情况下,流式查询以微批次执行数据,其中下一个微批次在前一个微批次完成后立即触发。
带触发间隔的处理时间
您可以显式指定ProcessingTime带有间隔的触发器,查询将以该固定间隔触发微批处理。
一次
在这种模式下,流式查询将只执行一个微批次——它会在一个批次中处理所有可用的新数据,然后自行停止。当您想控制外部调度程序的触发和处理时,这很有用,外部调度程序将使用任何自定义调度重新启动查询(例如,通过每天仅执行一次查询来控制成本)。
连续的
这是一种实验模式(从 Spark 3.0 开始),流式查询将连续处理数据,而不是微批处理。虽然只有一小部分 DataFrame 操作允许使用此模式,但它可以提供比微批量触发模式低得多的延迟(低至毫秒)。有关最新信息,请参阅最新的结构化流编程指南。
检查点位置
这是任何与 HDFS 兼容的文件系统中的一个目录,流式查询在其中保存其进度信息,即已成功处理的数据。失败时,此元数据用于在失败的查询中重新启动失败的查询。因此,设置此选项对于具有完全一次保证的故障恢复是必要的。
第五步:开始查询
# In Python
streamingQuery = writer2.start()// In Scala
val streamingQuery = writer2.start()返回的 type 对象streamingQuery代表一个活动的查询,可以用来管理查询,我们将在本章后面介绍。
请注意,这start()是一种非阻塞方法,因此一旦在后台开始查询,它将立即返回。如果您希望主线程阻塞直到流式查询终止,您可以使用streamingQuery.awaitTermination(). 如果查询在后台因错误awaitTermination()而失败,也会因同样的异常而失败。
您可以使用 等待最多超时持续时间awaitTermination(timeoutMillis),并且可以使用 显式停止查询streamingQuery.stop()。
把它们放在一起
总而言之,这里是通过套接字读取文本数据流、计算单词并将计数打印到控制台的完整代码:
# In Python
from pyspark.sql.functions import *
spark = SparkSession...
lines = (spark
.readStream.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load())
words = lines.select(explode(split(col("value"), "\\s")).alias("word"))
counts = words.groupBy("word").count()
checkpointDir = "..."
streamingQuery = (counts
.writeStream
.format("console")
.outputMode("complete")
.trigger(processingTime="1 second")
.option("checkpointLocation", checkpointDir)
.start())
streamingQuery.awaitTermination()// In Scala
import org.apache.spark.sql.functions._
import org.apache.spark.sql.streaming._
val spark = SparkSession...
val lines = spark
.readStream.format("socket")
.option("host", "localhost")
.option("port", 9999)
.load()
val words = lines.select(explode(split(col("value"), "\\s")).as("word"))
val counts = words.groupBy("word").count()
val checkpointDir = "..."
val streamingQuery = counts.writeStream
.format("console")
.outputMode("complete")
.trigger(Trigger.ProcessingTime("1 second"))
.option("checkpointLocation", checkpointDir)
.start()
streamingQuery.awaitTermination()查询开始后,后台线程不断地从流式传输源读取新数据,对其进行处理,然后将其写入流式传输接收器。接下来,让我们快速了解一下它是如何执行的。
在主动流式查询的底层
一旦查询开始,引擎中就会出现以下步骤序列,如图 8-5 所示。DataFrame 操作被转换为逻辑计划,这是 Spark SQL 用于计划查询的计算的抽象表示:
-
Spark SQL 分析和优化这个逻辑计划,以确保它可以在流数据上增量和高效地执行。
-
Spark SQL 启动一个后台线程,不断执行以下循环:2
-
根据配置的触发间隔,线程检查流源是否有新数据。
-
如果可用,则通过运行微批处理来执行新数据。从优化后的逻辑计划生成优化的Spark执行计划,从Source读取新数据,增量计算更新结果,并按照配置的输出模式将输出写入Sink。
-
对于每个微批次,处理的数据的确切范围(例如,文件集或 Apache Kafka 偏移的范围)和任何关联的状态都保存在配置的检查点位置,以便查询可以在需要时确定性地重新处理确切的范围.
-
-
此循环一直持续到查询终止,这可能由于以下原因之一发生:
-
查询发生故障(处理错误或集群故障)。
-
使用 明确停止查询
streamingQuery.stop()。 -
如果触发器设置为
Once,则查询将在执行包含所有可用数据的单个微批处理后自行停止。
-

图 8-5。流式查询的增量执行
笔记
关于结构化流,您应该记住的一个关键点是,在它下面使用 Spark SQL 来执行数据。因此,Spark SQL 的超优化执行引擎的全部功能被用来最大化流处理吞吐量,提供关键的性能优势。
接下来,我们将讨论终止后如何重新启动流式查询以及流式查询的生命周期。
通过 Exactly-Once 保证从故障中恢复
要在一个全新的进程中重新启动已终止的查询,您必须创建一个新的SparkSession,重新定义所有 DataFrame,并使用与第一次启动查询时使用的检查点位置相同的检查点位置对最终结果启动流式查询。对于我们的字数统计示例,您可以简单地重新执行前面显示的整个代码片段,从spark第一行的定义到start()最后一行的最终。
检查点位置在重新启动时必须相同,因为此目录包含流式查询的唯一标识并确定查询的生命周期。如果检查点目录被删除或者同一个查询使用不同的检查点目录启动,这就像从头开始一个新的查询。具体来说,检查点具有记录级信息(例如,Apache Kafka 偏移量)来跟踪最后一个不完整的微批处理正在处理的数据范围。重新启动的查询将使用此信息在最后一次成功完成微批处理之后开始处理记录。如果之前的查询计划了一个微批处理但在完成之前已经终止,那么重新启动的查询将在处理新数据之前重新处理相同范围的数据。再加上 Spark 的确定性任务执行,
当满足以下条件时, Structured Streaming 可以确保端到端的Exactly-once 保证(即,输出就像每个输入记录被处理一次一样):
可重放的流媒体源
最后一个不完整的微批次的数据范围可以从源头重新读取。
确定性计算
当给定相同的输入数据时,所有数据转换都会确定性地产生相同的结果。
幂等流接收器
接收器可以识别重新执行的微批处理并忽略可能由重新启动引起的重复写入。
请注意,我们的字数统计示例不提供完全一次保证,因为套接字源不可重放且控制台接收器不是幂等的。
作为关于重新启动查询的最后一点说明,可以在重新启动之间对查询进行少量修改。您可以通过以下几种方式修改查询:
数据帧转换
您可以对重新启动之间的转换进行少量修改。例如,在我们的流式字数统计示例中,如果您想忽略可能导致查询崩溃的字节序列损坏的行,您可以在转换中添加一个过滤器:
# In Python
# isCorruptedUdf = udf to detect corruption in string
filteredLines = lines.filter("isCorruptedUdf(value) = false")
words = lines.select(explode(split(col("value"), "\\s").alias("word"))// In Scala
// val isCorruptedUdf = udf to detect corruption in string
val filteredLines = lines.filter("isCorruptedUdf(value) = false")
val words = lines.select(explode(split(col("value"), "\\s").as("word"))使用此修改后words的 DataFrame 重新启动后,重新启动的查询将对自重新启动以来处理的所有数据(包括最后一个不完整的微批处理)应用过滤器,以防止查询再次失败。
源和汇选项
是否可以在重新启动之间更改readStream或writeStream选项取决于特定源或接收器的语义。例如,如果要将数据发送到该主机和端口,则不应更改套接字源的hostandport选项。但是您可以向控制台接收器添加一个选项,以在每次触发后打印多达一百个更改的计数:
writeStream.format("console").option("numRows", "100")...处理细节
如前所述,检查点位置不得在重新启动之间更改。但是,可以在不破坏容错保证的情况下更改触发间隔等其他细节。
有关重新启动之间允许的有限更改集的更多信息,请参阅最新的Structured Streaming Programming Guide。
监控活动查询
在生产中运行流式管道的一个重要部分是跟踪其运行状况。结构化流式处理提供了多种方法来跟踪活动查询的状态和处理指标。
使用 StreamingQuery 查询当前状态
StreamingQuery您可以使用实例查询活动查询的当前运行状况。这里有两种方法:
使用 StreamingQuery 获取当前指标
当一个查询以微批处理的方式处理一些数据时,我们认为它已经取得了一些进展。lastProgress()返回有关最后完成的微批次的信息。例如,打印返回的对象(StreamingQueryProgress在 Scala/Java 或 Python 中的字典)将产生如下内容:
// In Scala/Python
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2// In Scala/Python
{
"id" : "ce011fdc-8762-4dcb-84eb-a77333e28109",
"runId" : "88e2ff94-ede0-45a8-b687-6316fbef529a",
"name" : "MyQuery",
"timestamp" : "2016-12-14T18:45:24.873Z",
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0,
"durationMs" : {
"triggerExecution" : 3,
"getOffset" : 2
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"1" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"1" : 134,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}
},
"stateOperators" : [ ],
"sources" : [ {
"description" : "KafkaSource[Subscribe[topic-0]]",
"startOffset" : {
"topic-0" : {
"2" : 0,
"1" : 1,
"0" : 1
}
},
"endOffset" : {
"topic-0" : {
"2" : 0,
"1" : 134,
"0" : 534
}
},
"numInputRows" : 10,
"inputRowsPerSecond" : 120.0,
"processedRowsPerSecond" : 200.0
} ],
"sink" : {
"description" : "MemorySink"
}
}id
与检查点位置相关的唯一标识符。这在查询的整个生命周期(即重新启动)中保持不变。
runId
当前(重新)启动的查询实例的唯一标识符。这会随着每次重新启动而改变。
numInputRows
在最后一个微批处理中处理的输入行数。
inputRowsPerSecond
在源处生成输入行的当前速率(上一个微批处理持续时间的平均值)。
processedRowsPerSecond
接收器处理和写出行的当前速率(上一个微批处理持续时间的平均值)。如果此速率始终低于输入速率,则查询无法像源生成数据一样快地处理数据。这是查询运行状况的关键指标。
sources和sink
提供上一批中处理的数据的源/接收器特定详细信息。
使用 StreamingQuery.status() 获取当前状态
这提供了有关后台查询线程此时正在做什么的信息。例如,打印返回的对象将产生如下内容:
// In Scala/Python
{
"message" : "Waiting for data to arrive",
"isDataAvailable" : false,
"isTriggerActive" : false
}
使用 Dropwizard Metrics 发布指标
Spark 通过一个名为Dropwizard Metrics的流行库支持报告指标。该库允许将指标发布到许多流行的监控框架(Ganglia、Graphite 等)。由于报告的数据量很大,因此默认情况下不会为结构化流查询启用这些指标。要启用它们,除了为 Spark 配置 Dropwizard Metrics之外,您还必须在开始查询之前将SparkSession配置显式设置spark.sql.streaming.metricsEnabled为。true
请注意,只有一部分可用信息StreamingQuery.lastProgress()通过 Dropwizard Metrics 发布。如果您想不断地向任意位置发布更多进度信息,则必须编写自定义侦听器,如下所述。
使用自定义 StreamingQueryListeners 发布指标
StreamingQueryListener是一个事件侦听器接口,您可以使用它注入任意逻辑来持续发布指标。此开发人员 API 仅在 Scala/Java 中可用。使用自定义侦听器有两个步骤:
-
定义您的自定义侦听器。该
StreamingQueryListener接口提供了三种方法,您的实现可以定义这些方法来获取与流式查询相关的三种类型的事件:开始、进度(即执行了触发器)和终止。这是一个例子:// In Scala import org.apache.spark.sql.streaming._ val myListener = new StreamingQueryListener() { override def onQueryStarted(event: QueryStartedEvent): Unit = { println("Query started: " + event.id) } override def onQueryTerminated(event: QueryTerminatedEvent): Unit = { println("Query terminated: " + event.id) } override def onQueryProgress(event: QueryProgressEvent): Unit = { println("Query made progress: " + event.progress) } } -
SparkSession在开始查询之前将您的侦听器添加到:// In Scala spark.streams.addListener(myListener)
流式数据源和接收器
现在我们已经介绍了表达端到端结构化流查询所需的基本步骤,让我们来看看如何使用内置的流数据源和接收器。提醒一下,您可以使用从流式源创建 DataFrame,SparkSession.readStream()并使用DataFrame.writeStream(). 在每种情况下,您都可以使用方法指定源类型format()。稍后我们将看到一些具体的例子。
文件
Structured Streaming 支持从与批处理支持的格式相同的文件读取和写入数据流:纯文本、CSV、JSON、Parquet、ORC 等。这里我们将讨论如何对文件操作 Structured Streaming。
从文件中读取
# In Python
from pyspark.sql.types import *
inputDirectoryOfJsonFiles = ...
fileSchema = (StructType()
.add(StructField("key", IntegerType()))
.add(StructField("value", IntegerType())))
inputDF = (spark
.readStream
.format("json")
.schema(fileSchema)
.load(inputDirectoryOfJsonFiles))// In Scala
import org.apache.spark.sql.types._
val inputDirectoryOfJsonFiles = ...
val fileSchema = new StructType()
.add("key", IntegerType)
.add("value", IntegerType)
val inputDF = spark.readStream
.format("json")
.schema(fileSchema)
.load(inputDirectoryOfJsonFiles)返回的流数据帧将具有指定的模式。以下是使用文件时要记住的几个关键点:
-
所有文件必须具有相同的格式,并且应该具有相同的架构。例如,如果格式为
"json",则所有文件必须为 JSON 格式,每行一条 JSON 记录。每条 JSON 记录的架构必须与用 指定的架构相匹配readStream()。违反这些假设可能导致不正确的解析(例如,意外null值)或查询失败。 -
每个文件都必须以原子方式出现在目录列表中——也就是说,整个文件必须立即可供读取,并且一旦可用,就无法更新或修改文件。这是因为结构化流式处理将在引擎找到文件时(使用目录列表)处理该文件,并在内部将其标记为已处理。不会处理对该文件的任何更改。
-
当有多个新文件要处理但它只能在下一个微批处理中选择其中一些时(例如,由于速率限制),它将选择具有最早时间戳的文件。然而,在微批处理中,没有预定义的选定文件的读取顺序;所有这些都将被并行读取。
笔记
这个流文件源支持许多常用选项,包括支持的文件格式特定选项
spark.read()(参见第 4 章中的“DataFrames 和 SQL 表的数据源” )和几个特定于流的选项(例如,限制文件处理速率)。有关详细信息,请参阅编程指南。maxFilesPerTrigger
写入文件
结构化流式处理支持将流式查询输出写入与读取格式相同的文件。然而,它只支持追加模式,因为虽然在输出目录中写入新文件很容易(即,将数据追加到目录中),但很难修改现有数据文件(正如更新和完成模式所期望的那样) . 它还支持分区。这是一个例子:
# In Python
outputDir = ...
checkpointDir = ...
resultDF = ...
streamingQuery = (resultDF.writeStream
.format("parquet")
.option("path", outputDir)
.option("checkpointLocation", checkpointDir)
.start())// In Scala
val outputDir = ...
val checkpointDir = ...
val resultDF = ...
val streamingQuery = resultDF
.writeStream
.format("parquet")
.option("path", outputDir)
.option("checkpointLocation", checkpointDir)
.start()您"path"可以直接将输出目录指定为start(outputDir).
要记住的几个关键点:
-
结构化流式处理通过维护已写入目录的数据文件的日志,在写入文件时实现端到端的一次性保证。此日志保存在子目录_spark_metadata中。对目录(而不是其子目录)的任何 Spark 查询都将自动使用日志来读取正确的数据文件集,从而保持完全一次保证(即,不会读取重复数据或部分文件)。请注意,其他处理引擎可能不知道此日志,因此可能无法提供相同的保证。
-
如果您在重新启动之间更改结果 DataFrame 的架构,则输出目录将包含多个架构中的数据。查询目录时必须协调这些模式。
Apache Kafka
Apache Kafka是一种流行的发布/订阅系统,广泛用于存储数据流。Structured Streaming 内置了对 Apache Kafka 读取和写入的支持。
Reading from Kafka
要从 Kafka 执行分布式读取,您必须使用选项来指定如何连接到源。假设您要订阅来自主题的数据"events"。以下是创建流式 DataFrame 的方法:
# In Python
inputDF = (spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "events")
.load())// In Scala
val inputDF = spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "events")
.load()返回的 DataFrame 将具有表 8-1中描述的模式。
| 列名 | 立柱类型 | 描述 |
|---|---|---|
key | binary | 记录的关键数据,以字节为单位。 |
value | binary | 记录的值数据,以字节为单位。 |
topic | string | 记录所在的 Kafka 主题。这在订阅多个主题时很有用。 |
partition | int | 记录所在的 Kafka 主题的分区。 |
offset | long | 记录的偏移值。 |
timestamp | long | 与记录关联的时间戳。 |
timestampType | int | 与记录关联的时间戳类型的枚举。 |
您还可以选择订阅多个主题、主题模式,甚至是主题的特定分区。此外,您可以选择是只读取订阅主题中的新数据还是处理这些主题中的所有可用数据。您甚至可以从批量查询中读取 Kafka 数据——也就是说,将 Kafka 主题视为表。有关更多详细信息,请参阅Kafka 集成指南。
写给 Kafka
为了写入 Kafka,Structured Streaming 期望结果 DataFrame 有一些特定名称和类型的列,如表 8-2中所述。
| 列名 | 立柱类型 | 描述 |
|---|---|---|
key(可选的) | string或者binary | 如果存在,这些字节将作为 Kafka 记录键写入;否则,密钥将为空。 |
value(必需的) | string或者binary | 字节将作为 Kafka 记录值写入。 |
topic(仅当"topic"未指定为选项时才需要) | string | 如果"topic"未指定为选项,则这将确定要写入键/值的主题。这对于将写入分散到多个主题很有用。如果"topic"已指定选项,则忽略此值。 |
您可以在所有三种输出模式下写入 Kafka,但不建议使用完整模式,因为它会重复输出相同的记录。以下是将我们之前的字数查询的输出以更新模式写入 Kafka 的具体示例:
# In Python
counts = ... # DataFrame[word: string, count: long]
streamingQuery = (counts
.selectExpr(
"cast(word as string) as key",
"cast(count as string) as value")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "wordCounts")
.outputMode("update")
.option("checkpointLocation", checkpointDir)
.start())// In Scala
val counts = ... // DataFrame[word: string, count: long]
val streamingQuery = counts
.selectExpr(
"cast(word as string) as key",
"cast(count as string) as value")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "wordCounts")
.outputMode("update")
.option("checkpointLocation", checkpointDir)
.start()有关更多详细信息,请参阅Kafka 集成指南.
自定义流源和接收器
在本节中,我们将讨论如何读取和写入在结构化流中没有内置支持的存储系统。特别是,您将看到如何使用foreachBatch()和foreach()方法来实现自定义逻辑以写入您的存储。
写入任何存储系统
有两种操作允许您将流式查询的输出写入任意存储系统:foreachBatch()和foreach(). 它们的用例略有不同:虽然foreach()允许在每一行上自定义写入逻辑,但foreachBatch()允许在每个微批次的输出上进行任意操作和自定义逻辑。让我们更详细地探讨它们的用法。
使用 foreachBatch()
foreachBatch() 允许您指定在流式查询的每个微批次的输出上执行的函数。它有两个参数:具有微批次输出的 DataFrame 或 Dataset,以及微批次的唯一标识符。例如,假设我们要将之前的字数查询的输出写入Apache Cassandra。从Spark Cassandra 连接器 2.4.2开始,不支持编写流式 DataFame。但是您可以使用连接器的批处理 DataFrame 支持将每个批处理的输出(即更新的字数)写入 Cassandra,如下所示:
# In Python
hostAddr = "<ip address>"
keyspaceName = "<keyspace>"
tableName = "<tableName>"
spark.conf.set("spark.cassandra.connection.host", hostAddr)
def writeCountsToCassandra(updatedCountsDF, batchId):
# Use Cassandra batch data source to write the updated counts
(updatedCountsDF
.write
.format("org.apache.spark.sql.cassandra")
.mode("append")
.options(table=tableName, keyspace=keyspaceName)
.save())
streamingQuery = (counts
.writeStream
.foreachBatch(writeCountsToCassandra)
.outputMode("update")
.option("checkpointLocation", checkpointDir)
.start())// In Scala
import org.apache.spark.sql.DataFrame
val hostAddr = "<ip address>"
val keyspaceName = "<keyspace>"
val tableName = "<tableName>"
spark.conf.set("spark.cassandra.connection.host", hostAddr)
def writeCountsToCassandra(updatedCountsDF: DataFrame, batchId: Long) {
// Use Cassandra batch data source to write the updated counts
updatedCountsDF
.write
.format("org.apache.spark.sql.cassandra")
.options(Map("table" -> tableName, "keyspace" -> keyspaceName))
.mode("append")
.save()
}
val streamingQuery = counts
.writeStream
.foreachBatch(writeCountsToCassandra _)
.outputMode("update")
.option("checkpointLocation", checkpointDir)
.start()使用foreachBatch(),您可以执行以下操作:
重用现有的批处理数据源
如上例所示,foreachBatch()您可以使用现有的批处理数据源(即支持写入批处理 DataFrames 的源)来编写流式查询的输出。
写入多个位置
如果您想将流式查询的输出写入多个位置(例如,OLAP 数据仓库和 OLTP 数据库),那么您可以简单地多次写入输出 DataFrame/Dataset。但是,每次写入尝试都可能导致重新计算输出数据(包括可能重新读取输入数据)。为避免重新计算,您应该缓存batchOutputDataFrame,将其写入多个位置,然后取消缓存:
# In Python
def writeCountsToMultipleLocations(updatedCountsDF, batchId):
updatedCountsDF.persist()
updatedCountsDF.write.format(...).save() # Location 1
updatedCountsDF.write.format(...).save() # Location 2
updatedCountsDF.unpersist()// In Scala
def writeCountsToMultipleLocations(
updatedCountsDF: DataFrame,
batchId: Long) {
updatedCountsDF.persist()
updatedCountsDF.write.format(...).save() // Location 1
updatedCountsDF.write.format(...).save() // Location 2
updatedCountsDF.unpersist()
}应用额外的 DataFrame 操作
流数据帧不支持许多 DataFrame API 操作3因为结构化流不支持在这些情况下生成增量计划。使用foreachBatch(),您可以在每个微批量输出上应用其中一些操作。但是,您将不得不对自己进行操作的端到端语义进行推理。
笔记
foreachBatch()仅提供至少一次写入保证。batchId您可以通过使用 对重新执行的微批处理中的多次写入进行重复数据删除来获得一次性保证。
使用 foreach()
如果foreachBatch()不是一个选项(例如,如果相应的批处理数据写入器不存在),那么您可以使用foreach(). 具体来说,可以将数据写入逻辑分为三个方法:open()、process()、close()。Structured Streaming 将使用这些方法来写入输出记录的每个分区。这是一个抽象的例子:
# In Python
# Variation 1: Using function
def process_row(row):
# Write row to storage
pass
query = streamingDF.writeStream.foreach(process_row).start()
# Variation 2: Using the ForeachWriter class
class ForeachWriter:
def open(self, partitionId, epochId):
# Open connection to data store
# Return True if write should continue
# This method is optional in Python
# If not specified, the write will continue automatically
return True
def process(self, row):
# Write string to data store using opened connection
# This method is NOT optional in Python
pass
def close(self, error):
# Close the connection. This method is optional in Python
pass
resultDF.writeStream.foreach(ForeachWriter()).start()// In Scala
import org.apache.spark.sql.ForeachWriter
val foreachWriter = new ForeachWriter[String] { // typed with Strings
def open(partitionId: Long, epochId: Long): Boolean = {
// Open connection to data store
// Return true if write should continue
}
def process(record: String): Unit = {
// Write string to data store using opened connection
}
def close(errorOrNull: Throwable): Unit = {
// Close the connection
}
}
resultDSofStrings.writeStream.foreach(foreachWriter).start()结构化流编程指南中讨论了这些方法执行时的详细语义。
数据转换
在本节中,我们将深入研究结构化流中支持的数据转换。如前所述,Structured Streaming 仅支持可以增量执行的 DataFrame 操作。这些操作大致分为无状态操作和有状态操作。我们将定义每种类型的操作并解释如何识别哪些操作是有状态的。
增量执行和流状态
正如我们在“Active Streaming Query 的幕后”中所讨论的,Spark SQL 中的 Catalyst 优化器将所有 DataFrame 操作转换为优化的逻辑计划。决定如何执行逻辑计划的 Spark SQL 计划器认识到这是一个需要对连续数据流进行操作的流式逻辑计划。因此,计划器不是将逻辑计划转换为一次性物理执行计划,而是生成执行计划的连续序列。每个执行计划都会以增量方式更新最终结果 DataFrame——也就是说,该计划只处理来自输入流的一大块新数据,并且可能会处理一些由先前执行计划计算的中间、部分结果。
每次执行都被视为一个微批处理,执行之间通信的部分中间结果称为流式“状态”。根据增量执行操作是否需要维护状态,DataFrame 操作可以大致分为无状态和有状态操作。在本节的其余部分,我们将探讨无状态操作和有状态操作之间的区别,以及它们在流式查询中的存在如何需要不同的运行时配置和资源管理。
无状态转换
所有投影操作(例如 , select(), explode(), map())flatMap()和选择操作(例如 , filter())where()单独处理每个输入记录,而不需要来自先前行的任何信息。这种对先前输入数据的不依赖使它们成为无状态操作。
只有无状态操作的流式查询支持追加和更新输出模式,但不支持完整模式。这是有道理的:由于此类查询的任何已处理输出行都不能被任何未来数据修改,因此可以以附加模式(包括仅附加的流接收器,如任何格式的文件)将其写入所有流接收器。另一方面,此类查询自然不会跨输入记录组合信息,因此可能不会减少结果中的数据量。不支持完整模式,因为存储不断增长的结果数据通常成本很高。这与有状态转换形成鲜明对比,我们将在下面讨论。
有状态的转换
有状态转换的最简单示例是DataFrame.groupBy().count(),它生成自查询开始以来接收到的记录数的运行计数。在每个微批次中,增量计划将新记录的计数添加到先前微批次生成的先前计数中。计划之间传达的这个部分计数就是状态。该状态保存在 Spark 执行器的内存中,并被检查点到配置的位置以容忍故障。虽然 Spark SQL 自动管理此状态的生命周期以确保正确的结果,但您通常必须调整一些旋钮来控制资源使用以维护状态。在本节中,我们将探讨不同的有状态操作员如何在后台管理其状态。
分布式和容错状态管理
回想第1章和第2章,在集群中运行的 Spark 应用程序有一个驱动程序和一个或多个执行程序。在驱动程序中运行的 Spark 调度程序将您的高级操作分解为更小的任务并将它们放入任务队列中,当资源可用时,执行程序从队列中拉出任务以执行它们。流式查询中的每个微批处理本质上执行一组这样的任务,这些任务从流式源读取新数据并将更新的输出写入流式传输下沉。对于有状态的流处理查询,除了写入接收器之外,每个微批处理任务都会生成中间状态数据,这些数据将被下一个微批处理使用。这种状态数据的生成是完全分区和分布式的(因为所有的读取、写入和处理都在 Spark 中),并且缓存在执行器内存中以供高效使用。这在图 8-6中进行了说明,它显示了在我们的原始流式字数查询中如何管理状态。
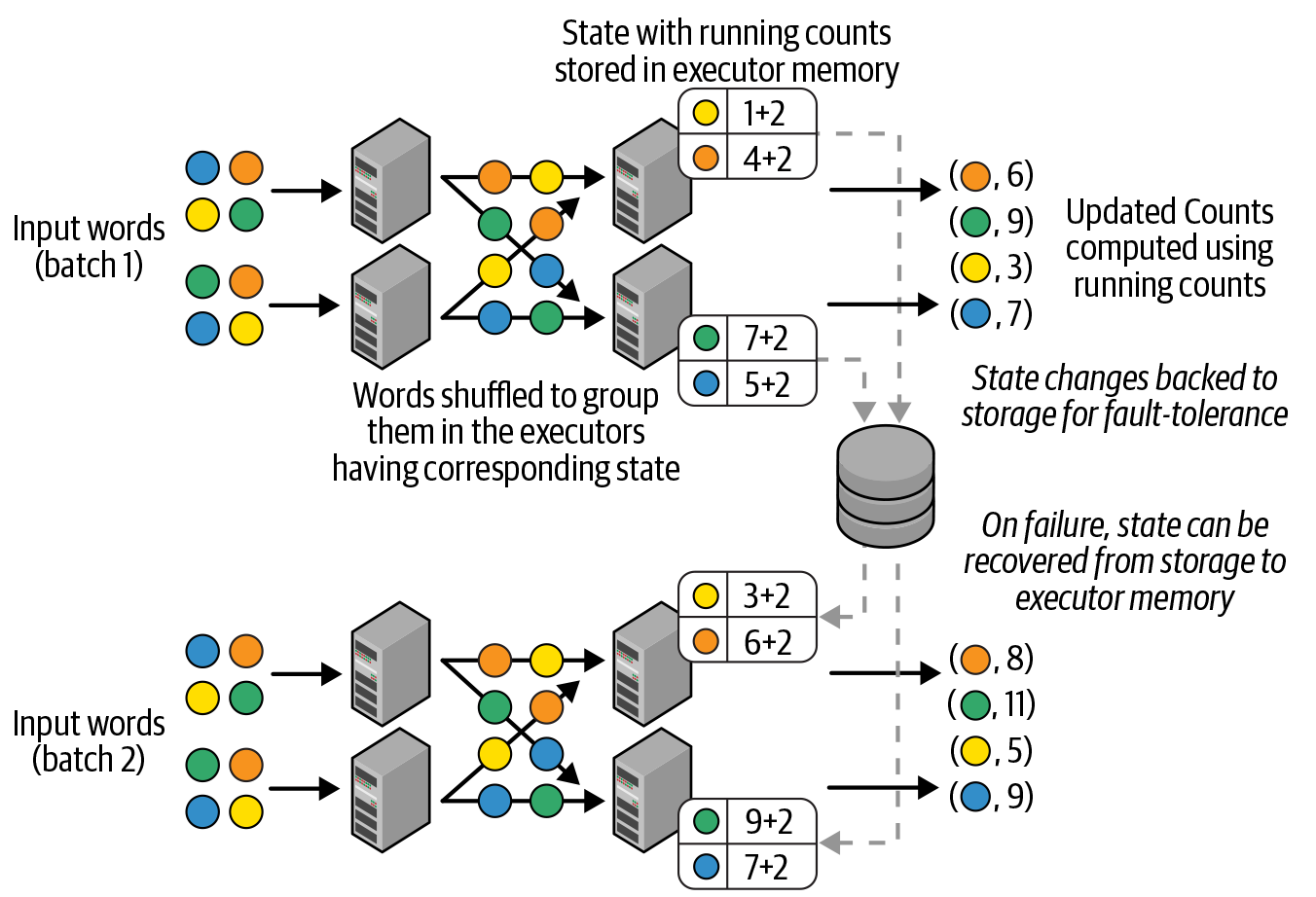
图 8-6。结构化流中的分布式状态管理
每个微批次读取一组新单词,在执行程序中将它们打乱以对它们进行分组,计算微批次中的计数,最后将它们添加到运行计数中以产生新计数。这些新计数既是下一个微批次的输出又是状态,因此它们被缓存在执行器的内存中。下一个微批量数据在 executor 之间按照与之前完全相同的方式进行分组,这样每个单词总是由同一个 executor 处理,因此可以在本地读取和更新其运行计数。
但是,仅将此状态保留在内存中是不够的,因为任何故障(执行程序或整个应用程序)都会导致内存中状态丢失。为了避免丢失,我们将键/值状态更新作为更改日志同步保存在用户提供的检查点位置。这些更改与每个批次中处理的偏移范围共同进行版本化,并且可以通过读取检查点日志来自动重建所需的状态版本。如果发生任何故障,结构化流能够通过重新处理相同的输入数据以及它在该微批次之前的相同状态来重新执行失败的微批次,从而产生与如果没有失败。这对于确保端到端的一次性保证至关重要。
总而言之,对于所有有状态的操作,Structured Streaming 通过以分布式方式自动保存和恢复状态来确保操作的正确性。根据有状态操作,您可能需要做的就是调整状态清理策略,以便可以自动从缓存状态中删除旧键和值。这就是我们接下来要讨论的。
有状态操作的类型
流状态的本质是保留过去数据的摘要。有时需要从状态中清理旧摘要,以便为新摘要腾出空间。根据这是如何完成的,我们可以区分两种类型的有状态操作:
托管状态操作
它们根据特定于操作的“旧”定义自动识别和清理旧状态。您可以调整定义为旧的内容以控制资源使用(例如,用于存储状态的执行程序内存)。属于这一类的操作是那些:
-
流式聚合
-
流-流连接
-
流式重复数据删除
非托管有状态操作
这些操作让您可以定义自己的自定义状态清理逻辑。此类别中的操作是:
-
MapGroupsWithState -
FlatMapGroupsWithState
这些操作允许您定义任意有状态操作(会话化等)。
以下各节将详细讨论这些操作中的每一个。
有状态的流聚合
结构化流可以增量执行大多数 DataFrame 聚合操作。您可以按键(例如,流式字数)和/或按时间(例如,每小时接收的记录计数)聚合数据。在本节中,我们将讨论调整这些不同类型的流聚合的语义和操作细节。我们还将简要讨论流中不支持的几种聚合类型。让我们从不涉及时间的聚合开始。
不基于时间的聚合
全局聚合
流中所有数据的聚合。例如,假设您有一个传感器读数流作为名为sensorReadings. 您可以使用以下查询计算接收到的读数总数的运行计数:
# In Python
runningCount = sensorReadings.groupBy().count()// In Scala
val runningCount = sensorReadings.groupBy().count()笔记
您不能在流式 DataFrames 上使用直接聚合操作,例如
DataFrame.count()和。Dataset.reduce()这是因为,对于静态 DataFrame,这些操作会立即返回最终计算的聚合,而对于流式 DataFrame,聚合必须不断更新。因此,您必须始终在流式 DataFrame 上使用DataFrame.groupBy()or进行聚合。Dataset.groupByKey()
分组聚合
数据流中存在的每个组或键中的聚合。例如,如果sensorReadings包含来自多个传感器的数据,您可以使用以下方法计算每个传感器的运行平均读数(例如,为每个传感器设置基线值):
# In Python
baselineValues = sensorReadings.groupBy("sensorId").mean("value")// In Scala
val baselineValues = sensorReadings.groupBy("sensorId").mean("value")除了计数和平均值之外,流式 DataFrames 还支持以下类型的聚合(类似于批处理 DataFrames):
所有内置聚合函数
sum(), mean(), stddev(), countDistinct(), collect_set(),approx_count_distinct()等。有关详细信息,请参阅 API 文档(Python和Scala)。
多个聚合一起计算
您可以通过以下方式应用多个聚合函数一起计算:
# In Python
from pyspark.sql.functions import *
multipleAggs = (sensorReadings
.groupBy("sensorId")
.agg(count("*"), mean("value").alias("baselineValue"),
collect_set("errorCode").alias("allErrorCodes")))// In Scala
import org.apache.spark.sql.functions.*
val multipleAggs = sensorReadings
.groupBy("sensorId")
.agg(count("*"), mean("value").alias("baselineValue"),
collect_set("errorCode").alias("allErrorCodes"))用户定义的聚合函数
支持所有用户定义的聚合函数。有关无类型和有类型的用户定义聚合函数的更多详细信息,请参阅Spark SQL 编程指南。
关于此类流式聚合的执行,我们已经在前面的章节中说明了运行中的聚合如何维护为分布式状态。除此之外,对于不基于时间的聚合,还有两点需要记住:用于此类查询的输出模式和按状态规划资源使用情况。这些将在本节末尾讨论。接下来,我们将讨论在时间窗口内组合数据的聚合。
具有事件时间窗口的聚合
在许多情况下,您希望对按时间窗口分桶的数据进行聚合,而不是在整个流上运行聚合。继续我们的传感器示例,假设每个传感器每分钟最多发送一个读数,我们想要检测是否有任何传感器报告异常高的次数。为了发现此类异常,我们可以每隔五分钟计算从每个传感器接收到的读数数量。此外,为了稳健性,我们应该根据传感器生成数据的时间而不是根据接收数据的时间计算时间间隔,因为任何传输延迟都会扭曲结果。换句话说,我们要使用事件时间——即记录中表示读取生成时间的时间戳。说sensorReadingsDataFrame 将生成时间戳记为名为 的列eventTime。我们可以将这个五分钟的计数表示如下:
# In Python
from pyspark.sql.functions import *
(sensorReadings
.groupBy("sensorId", window("eventTime", "5 minute"))
.count())// In Scala
import org.apache.spark.sql.functions.*
sensorReadings
.groupBy("sensorId", window("eventTime", "5 minute"))
.count()这里要注意的关键是window()函数,它允许我们将五分钟窗口表示为动态计算的分组列。启动时,此查询将对每个传感器读数有效地执行以下操作:
-
使用该
eventTime值计算传感器读数落入的五分钟时间窗口。 -
根据复合组对阅读进行分组。
(<computed window>, SensorId) -
更新复合组的计数。
让我们用一个说明性的例子来理解这一点。图 8-7显示了一些传感器读数如何根据其事件时间映射到五分钟滚动(即非重叠)窗口组。两条时间线显示每个接收到的事件何时将由结构化流处理,以及事件数据中的时间戳(通常是在传感器处生成事件的时间)。
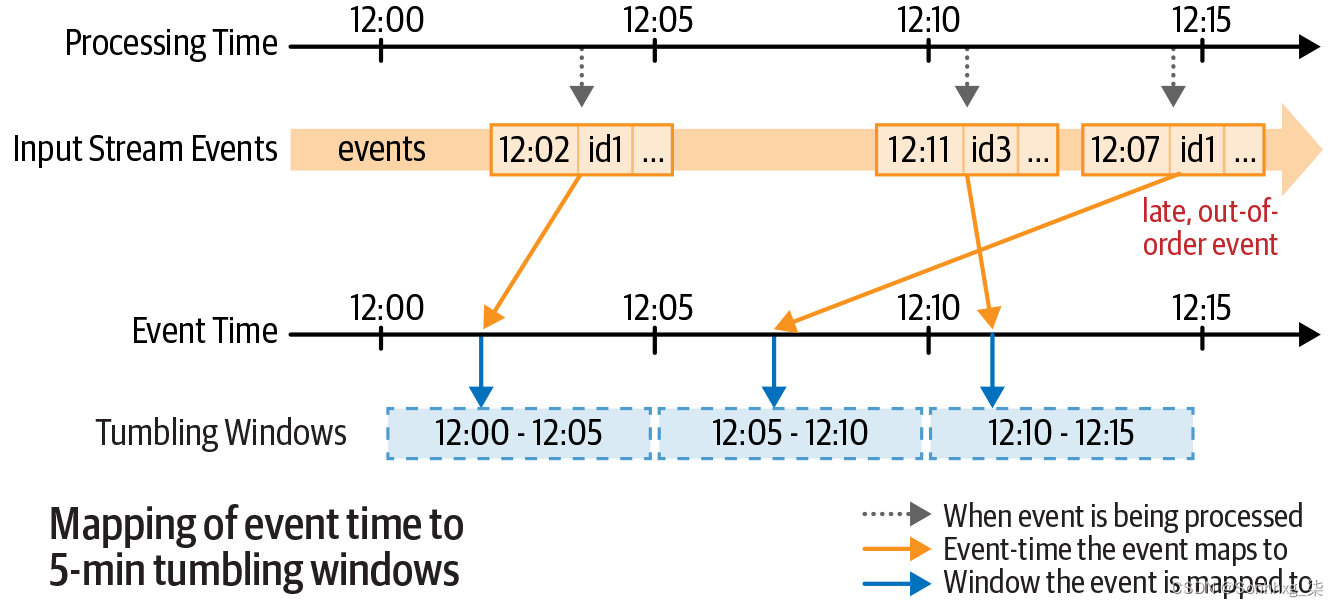
图 8-7。将事件时间映射到翻滚窗口
事件时间的每个 5 分钟窗口都被考虑用于分组,将根据该分组计算计数。请注意,就事件时间而言,事件可能会迟到并且出现混乱。如图所示,事件时间为12:07的事件在时间为12:11的事件之后被接收并处理。但是,无论它们何时到达,每个事件都会根据其事件时间分配到适当的组。事实上,根据窗口规范,每个事件都可以分配给多个组。例如,如果要计算每 5 分钟滑动 10 分钟的窗口对应的计数,则可以执行以下操作:
# In Python
(sensorReadings
.groupBy("sensorId", window("eventTime", "10 minute", "5 minute"))
.count())// In Scala
sensorReadings
.groupBy("sensorId", window("eventTime", "10 minute", "5 minute"))
.count()在这个查询中,每个事件都将分配给两个重叠的窗口,如图 8-8 所示。
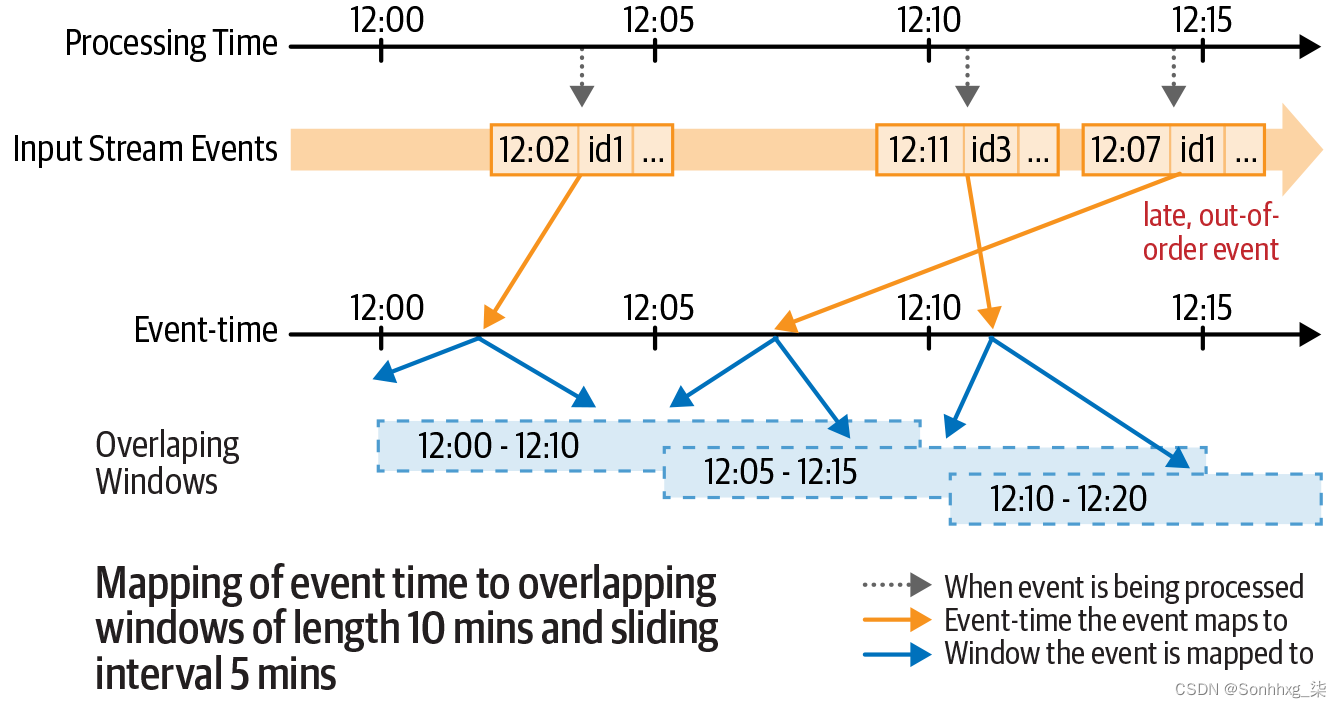
图 8-8。将事件时间映射到多个重叠窗口
每个唯一的元组都被认为是一个动态生成的组,将为其计算计数。例如,事件被映射到两个时间窗口,因此被映射到两个组,并且。这两个窗口的计数均以 1 递增。图 8-9对前面显示的事件进行了说明。(<assigned time window>, sensorId)[eventTime = 12:07, sensorId = id1](12:00-12:10, id1)(12:05-12:15, id1)
假设以五分钟的触发间隔处理输入记录,图 8-9底部的表格显示了每个微批次的结果表的状态(即计数)。随着事件时间的推移,新组会自动创建,并且它们的聚合会自动更新。迟到和无序的事件会被自动处理,因为它们只是更新旧的组。
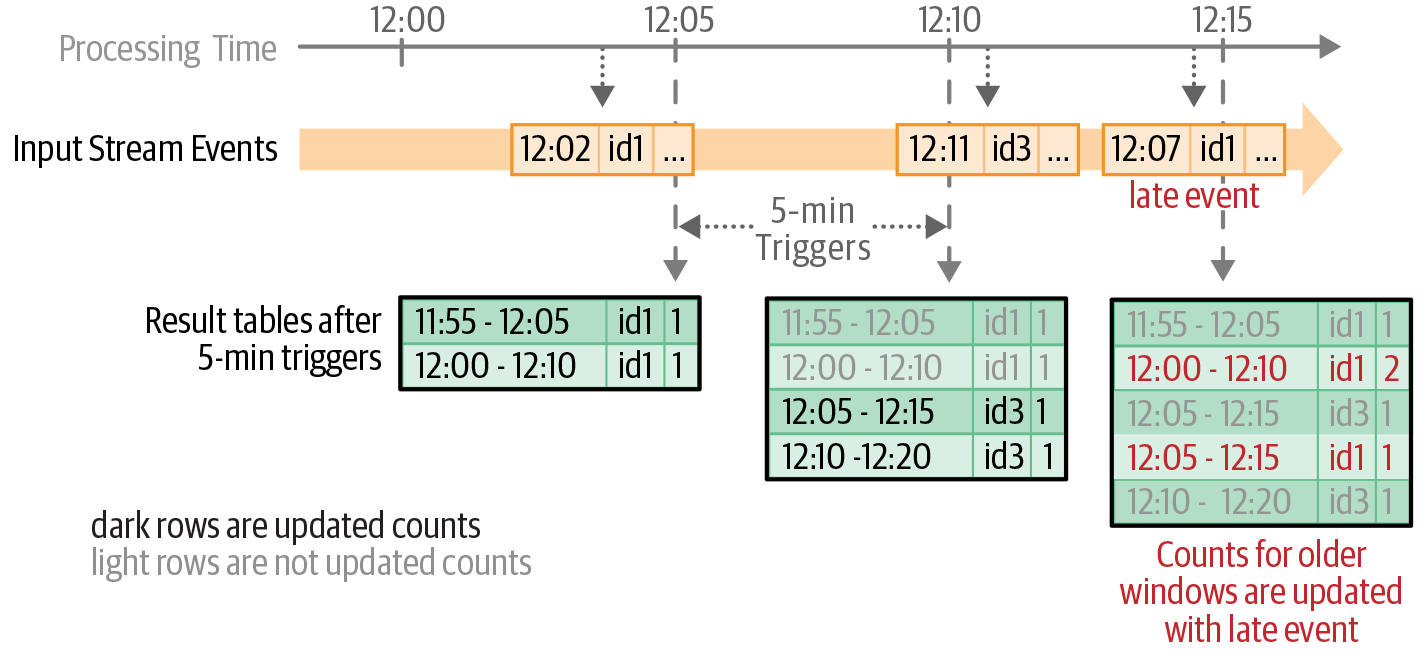
图 8-9。每五分钟触发后更新结果表中的计数
然而,从资源使用的角度来看,这带来了一个不同的问题——无限增长的状态大小。随着与最新时间窗口对应的新组的创建,旧组继续占用状态内存,等待任何迟到的数据更新它们。即使在实践中对输入数据的延迟有限制(例如,数据不能延迟超过 7 天),查询也不知道该信息。因此,它不知道何时将窗口视为“太旧而无法接收更新”并将其从状态中删除。为了提供绑定到查询的延迟(并防止无界状态),您可以指定watermarks,正如我们接下来讨论的那样。
处理带有水印的延迟数据
水印被定义为事件时间的移动阈值,该阈值落后于处理数据中查询看到的最大事件时间。尾随间隙(称为水印延迟)定义了引擎将等待延迟数据到达的时间。通过知道给定组不再有数据到达的点,引擎可以自动完成某些组的聚合并将它们从状态中删除。这限制了引擎为计算查询结果而必须维护的状态总量。
例如,假设您知道您的传感器数据延迟不会超过 10 分钟。然后可以如下设置水印:
# In Python
(sensorReadings
.withWatermark("eventTime", "10 minutes")
.groupBy("sensorId", window("eventTime", "10 minutes", "5 minutes"))
.mean("value"))// In Scala
sensorReadings
.withWatermark("eventTime", "10 minutes")
.groupBy("sensorId", window("eventTime", "10 minutes", "5 minute"))
.mean("value")请注意,您必须在用于定义窗口的时间戳列withWatermark()之前和之前调用。groupBy()执行该查询时,Structured Streaming 将持续跟踪该eventTime列的最大观察值,并相应地更新水印,过滤“太迟”的数据,并清除旧状态。也就是说,任何迟到 10 分钟以上的数据都将被忽略,所有比最新(按事件时间)输入数据早 10 分钟以上的时间窗口都将从状态中清除。为了阐明这个查询将如何执行,请考虑图 8-10中的时间线,该时间线显示了如何处理选择的输入记录。
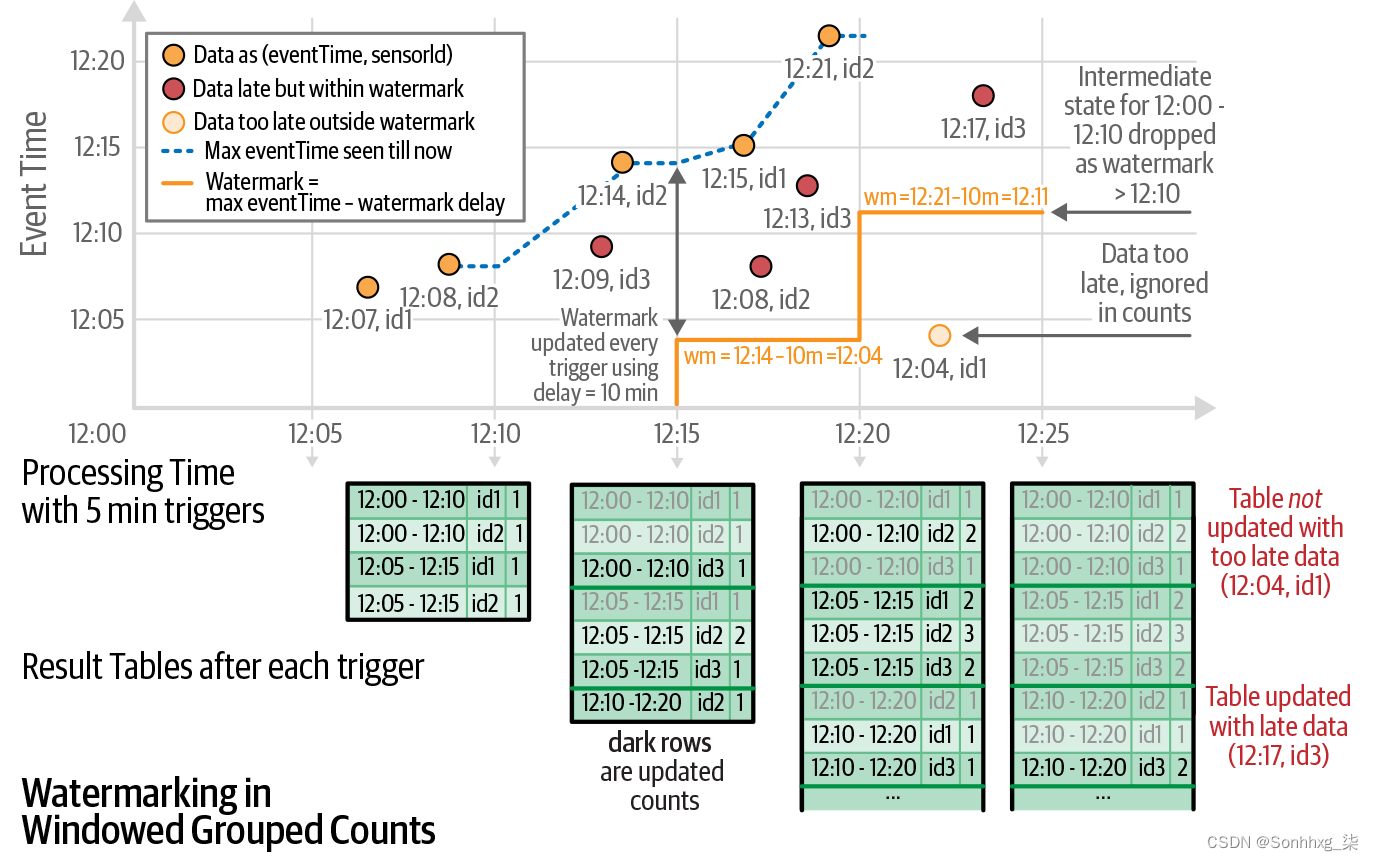
图 8-10。说明引擎如何跨事件跟踪最大事件时间、更新水印并相应地处理延迟数据
此图显示了根据处理时间(x 轴)和事件时间(y 轴)处理的记录的二维图。记录以五分钟的微批次进行处理,并用圆圈标记。底部的表格显示了每个微批次完成后结果表的状态。
每条记录在其左侧的所有记录之后被接收和处理。考虑两条记录[12:15, id1](在 12:17 左右处理)和[12:13, id3](在 12:18 左右处理)。记录id3被认为是迟到的(因此标记为纯红色),因为它是在记录之前由传感器生成的,id1但在后者之后处理。但是,在处理时间范围12:15–12:20的微批处理中,使用的水印是 12:04,它是根据直到前一个微批处理看到的最大事件时间(即 12:14减去 10 分钟的水印延迟)。因此,迟到的记录[12:13, id3]不算太晚,算成功了。相比之下,在下一个微批次中,记录[12:04, id1]与12:11的新水印相比,被认为为时已晚,被丢弃。
您可以根据应用程序的要求设置水印延迟 - 此参数的较大值允许数据稍后到达,但以增加状态大小(即内存使用)为代价,反之亦然。
支持的输出模式
与不涉及时间的流式聚合不同,具有时间窗口的聚合可以使用所有三种输出模式。但是,您需要注意关于状态清理的其他含义,具体取决于模式:
更新模式
在这种模式下,每个微批次将只输出聚合更新的行。此模式可用于所有类型的聚合。特别是对于时间窗口聚合,水印将确保定期清理状态。这是使用流式聚合运行查询的最有用和最有效的模式。但是,您不能使用此模式将聚合写入仅附加的流接收器,例如任何基于文件的格式,如 Parquet 和 ORC(除非您使用 Delta Lake,我们将在下一章讨论)。
完成模式
在这种模式下,每个微批次都将输出所有更新的聚合,无论它们的年龄或是否包含更改。虽然此模式可用于所有类型的聚合,但对于时间窗口聚合,使用完整模式意味着即使指定了水印也不会清除状态。输出所有聚合需要所有过去的状态,因此即使定义了水印,也必须保留聚合数据。谨慎地在时间窗口聚合上使用此模式,因为这可能会导致状态大小和内存使用量的无限增加。
追加模式
此模式只能用于事件时间窗口上的聚合并启用水印. 回想一下,附加模式不允许更改以前的输出结果。对于任何没有水印的聚合,每个聚合都可以用任何未来的数据进行更新,因此这些不能以附加模式输出。只有在事件时间窗口上的聚合上启用水印时,查询才会知道聚合何时不会进一步更新。因此,仅当水印确保聚合不会再次更新时,追加模式才输出每个键及其最终聚合值,而不是输出更新的行。这种模式的优点是它允许您将聚合写入仅附加的流接收器(例如,文件)。.
流式连接
结构化流式处理支持将流式传输数据集与另一个静态或流式传输数据集连接起来。在本节中,我们将探讨支持哪些类型的连接(内部、外部等),以及如何使用水印来限制为有状态连接存储的状态。我们将从连接数据流和静态数据集的简单案例开始。
流 - 静态连接
许多用例需要将数据流与静态数据集连接起来。例如,让我们考虑广告货币化的案例。假设您是一家在网站上展示广告的广告公司,并且当用户点击它们时您会赚钱。假设您有一个包含所有要展示的广告(称为展示次数)的静态数据集,以及每次用户点击展示的广告时的另一个事件流。要计算点击收入,您必须将事件流中的每次点击与表格中相应的广告展示进行匹配。让我们首先将数据表示为两个 DataFrame,一个静态的和一个流式的,如下所示:
# In Python
# Static DataFrame [adId: String, impressionTime: Timestamp, ...]
# reading from your static data source
impressionsStatic = spark.read. ...
# Streaming DataFrame [adId: String, clickTime: Timestamp, ...]
# reading from your streaming source
clicksStream = spark.readStream. ...// In Scala
// Static DataFrame [adId: String, impressionTime: Timestamp, ...]
// reading from your static data source
val impressionsStatic = spark.read. ...
// Streaming DataFrame [adId: String, clickTime: Timestamp, ...]
// reading from your streaming source
val clicksStream = spark.readStream. ...要将点击与展示相匹配,您只需使用公共adId列在它们之间应用内部等值连接:
# In Python
matched = clicksStream.join(impressionsStatic, "adId")// In Scala
val matched = clicksStream.join(impressionsStatic, "adId")如果展示和点击都是静态 DataFrame,这与您编写的代码相同 - 唯一的区别是您spark.read()用于批处理和spark.readStream()流。执行此代码时,每个微批次的点击都会与静态印象表进行内连接,以生成匹配事件的输出流。
除了内连接,结构化流还支持两种类型的流静态外连接:
-
左侧是流式 DataFrame 时的左外连接
-
右侧是流式 DataFrame 时的右外连接
不支持其他类型的外连接(例如,完全外连接和左外连接,右侧有流式 DataFrame),因为它们不容易以增量方式运行。在这两种受支持的情况下,代码与两个静态 DataFrame 之间的左/右外连接完全相同:
# In Python
matched = clicksStream.join(impressionsStatic, "adId", "leftOuter")// In Scala
val matched = clicksStream.join(impressionsStatic, Seq("adId"), "leftOuter")关于流静态连接有几个要点需要注意:
-
流静态连接是无状态操作,因此不需要任何类型的水印。
-
静态DataFrame在加入每个微批量的流数据的同时被重复读取,因此您可以缓存静态DataFrame以加快读取速度。
-
如果定义了静态 DataFrame 的数据源中的底层数据发生了变化,流式查询是否能看到这些变化取决于数据源的具体行为。例如,如果静态 DataFrame 是在文件上定义的,那么在重新启动流式查询之前,不会获取对这些文件的更改(例如,追加)。
在这个流静态示例中,我们做了一个重要的假设:印象表是静态表。实际上,随着新广告的展示,将会产生一连串的新印象。虽然流-静态连接有利于通过附加静态(或缓慢变化)信息丰富一个流中的数据,但当两个数据源都快速变化时,这种方法是不够的。为此,您需要流-流连接,我们将在下面讨论。
Stream–Stream Joins
在两个数据流之间生成连接的挑战在于,在任何时间点,任一数据集的视图都是不完整的,这使得在输入之间找到匹配变得更加困难。来自两个流的匹配事件可能以任何顺序到达并且可能被任意延迟。例如,在我们的广告用例中,展示事件及其相应的点击事件可能会乱序到达,它们之间存在任意延迟。结构化流式处理通过缓冲来自双方的输入数据作为流式处理状态来解决这种延迟,并在接收到新数据时不断检查匹配。图 8-11勾勒出这个概念。
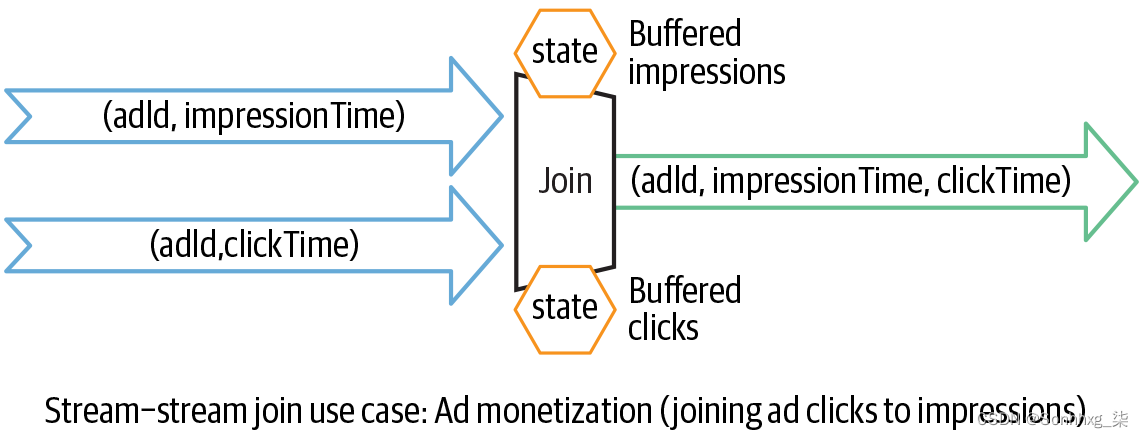
图 8-11。使用流-流连接的广告获利
让我们更详细地考虑这一点,首先是内连接,然后是外连接。
带有可选水印的内部连接
假设我们已将impressionsDataFrame 重新定义为流式 DataFrame。要获得匹配的展示流及其相应的点击,我们可以使用之前用于静态连接和流静态连接的相同代码:
# In Python
# Streaming DataFrame [adId: String, impressionTime: Timestamp, ...]
impressions = spark.readStream. ...
# Streaming DataFrame[adId: String, clickTime: Timestamp, ...]
clicks = spark.readStream. ...
matched = impressions.join(clicks, "adId")// In Scala
// Streaming DataFrame [adId: String, impressionTime: Timestamp, ...]
val impressions = spark.readStream. ...
// Streaming DataFrame[adId: String, clickTime: Timestamp, ...]
val clicks = spark.readStream. ...
val matched = impressions.join(clicks, "adId")即使代码相同,执行方式也完全不同。当这个查询被执行时,处理引擎将把它识别为流-流连接而不是流-静态连接。引擎会将所有点击和展示作为状态进行缓冲,并在收到的点击与缓冲的展示匹配时立即生成匹配的展示和点击(反之亦然,具体取决于哪个先收到)。让我们使用图 8-12中的事件时间线示例来可视化这个内部连接是如何工作的。
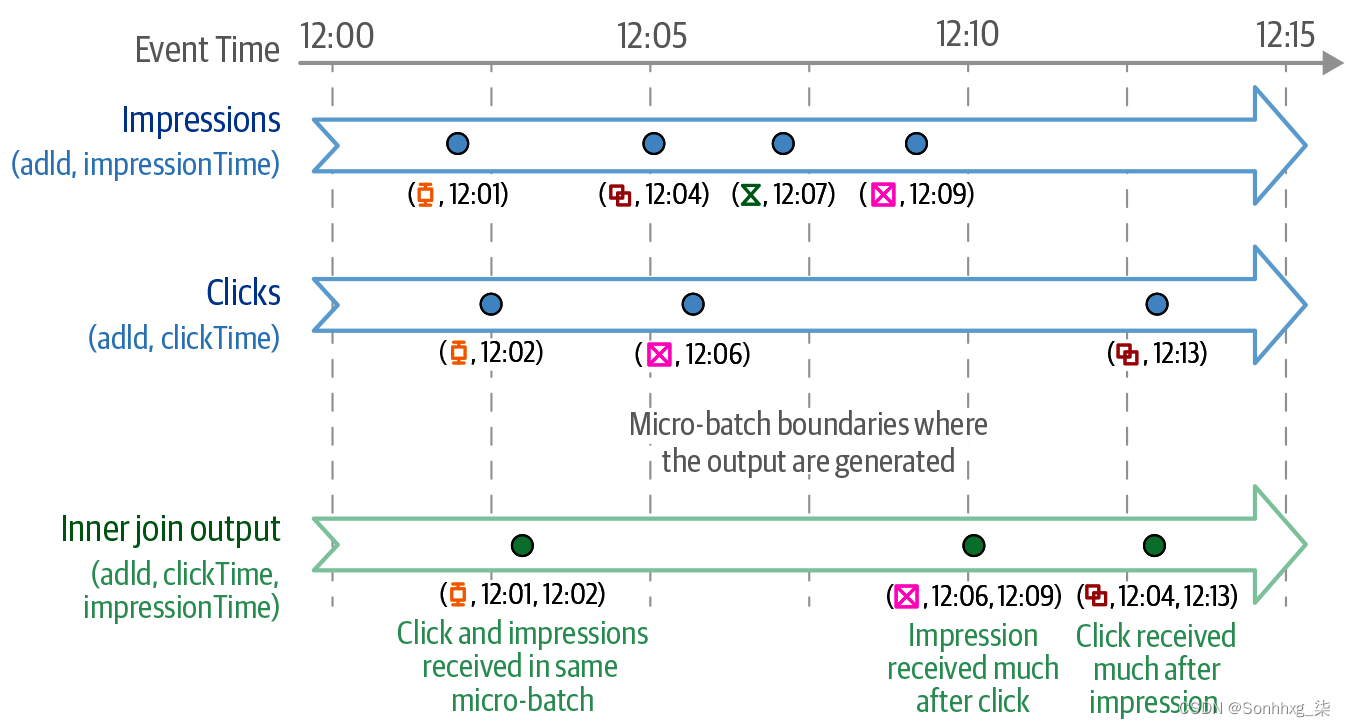
图 8-12。点击次数、展示次数及其联合输出的说明性时间表
在图 8-12中,蓝点表示在不同微批次中接收到的印象和点击事件的事件时间(由灰色虚线分隔)。出于此说明的目的,假设每个事件实际上是在与事件时间相同的挂钟时间收到的。请注意加入相关事件的不同场景。adId带有= ⧮的两个事件都在同一个微批次中接收,因此它们的联合输出是由该微批次生成的。然而,对于adId= ⧉印象是在 12:04 收到的,比相应的点击在 12:13 早得多。结构化流式传输将首先在 12:04 接收展示,并将其缓冲在状态中。对于每次收到的点击,引擎都会尝试将其与所有缓冲的展示一起加入(反之亦然)。最终,在 12:13 左右运行的后续微批处理中,引擎接收到adId= ⧉的点击并生成连接输出。
然而,在这个查询中,我们没有给出引擎应该缓冲多长时间来找到匹配的事件。因此,引擎可能会永远缓冲一个事件并累积无限量的流状态。要限制由流-流连接维护的流状态,您需要了解有关您的用例的以下信息:
-
两个事件在各自来源产生之间的最大时间范围是多少?在我们的用例的上下文中,我们假设点击可以在相应的展示之后的 0 秒到 1 小时内发生。
-
事件在源和处理引擎之间的传输过程中可以延迟的最大持续时间是多少?例如,来自浏览器的广告点击可能会由于间歇性连接而延迟,并且比预期晚得多,并且出现故障。假设展示次数和点击次数最多可以分别延迟两个小时和三个小时。
这些延迟限制和事件时间约束可以使用水印和时间范围条件在 DataFrame 操作中进行编码。换句话说,您必须在连接中执行以下附加步骤以确保状态清理:
-
在两个输入上定义水印延迟,以便引擎知道输入可以延迟多长时间(类似于流式聚合)。
-
定义跨两个输入的事件时间约束,以便引擎可以确定何时不需要一个输入的旧行(即不满足时间约束)与另一个输入匹配。可以通过以下方式之一定义此约束:
-
时间范围连接条件(例如,连接条件 = )
"leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR" -
加入事件时间窗口(例如,加入条件 = )
"leftTimeWindow = rightTimeWindow"
-
在我们的广告用例中,我们的内部连接代码会变得有点复杂:
# In Python
# Define watermarks
impressionsWithWatermark = (impressions
.selectExpr("adId AS impressionAdId", "impressionTime")
.withWatermark("impressionTime", "2 hours"))
clicksWithWatermark = (clicks
.selectExpr("adId AS clickAdId", "clickTime")
.withWatermark("clickTime", "3 hours"))
# Inner join with time range conditions
(impressionsWithWatermark.join(clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime BETWEEN impressionTime AND impressionTime + interval 1 hour""")))// In Scala
// Define watermarks
val impressionsWithWatermark = impressions
.selectExpr("adId AS impressionAdId", "impressionTime")
.withWatermark("impressionTime", "2 hours ")
val clicksWithWatermark = clicks
.selectExpr("adId AS clickAdId", "clickTime")
.withWatermark("clickTime", "3 hours")
// Inner join with time range conditions
impressionsWithWatermark.join(clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime BETWEEN impressionTime AND impressionTime + interval 1 hour"""))使用每个事件的这些时间限制,处理引擎可以自动计算需要缓冲多长时间才能生成正确的结果,以及何时可以从状态中删除事件。例如,它将评估以下内容(如图 8-13 所示):
-
展示最多需要缓冲四个小时(在事件时间中),因为延迟三个小时的点击可能与四个小时前的展示相匹配(即延迟三个小时 + 展示之间最多延迟一小时)点击)。
-
相反,点击最多需要缓冲两个小时(在事件时间),因为延迟两个小时的展示可能与两个小时前收到的点击相匹配。
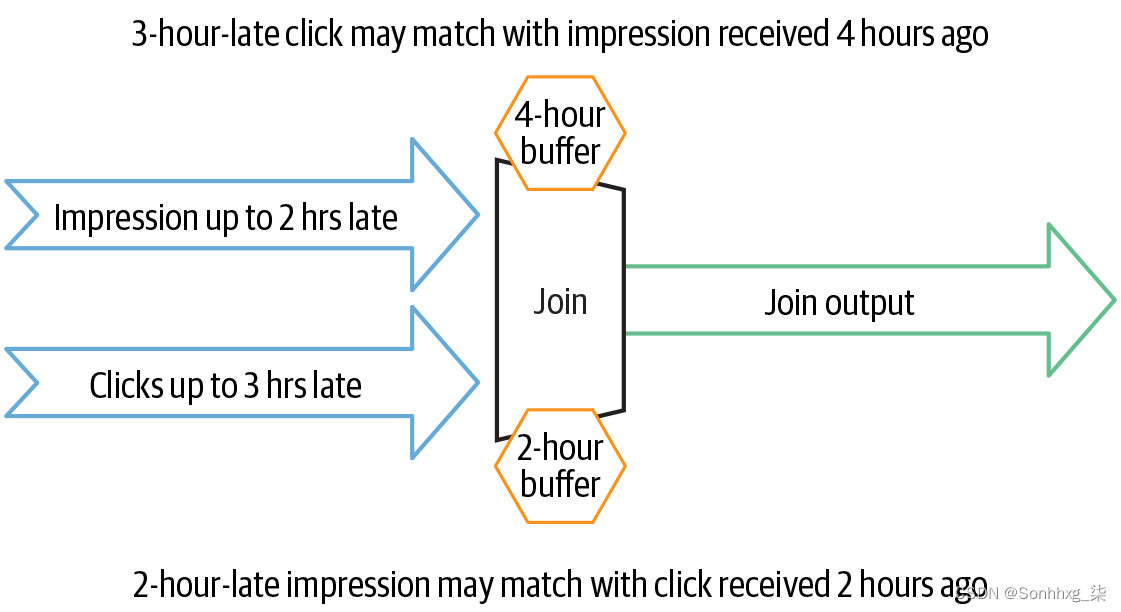
图 8-13。结构化流式处理使用水印延迟和时间范围条件自动计算状态清理的阈值
关于内部连接,需要记住几个关键点:
带水印的外部连接
先前的内部连接将仅输出已收到两个事件的广告。换句话说,根本不会报告未获得点击的广告。相反,您可能希望报告所有广告展示,无论是否包含相关的点击数据,以便稍后进行其他分析(例如,点击率)。这给我们带来了流-流外连接。您需要做的就是指定外部连接类型:
# In Python
# Left outer join with time range conditions
(impressionsWithWatermark.join(clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime BETWEEN impressionTime AND impressionTime + interval 1 hour"""),
"leftOuter")) # only change: set the outer join type// In Scala
// Left outer join with time range conditions
impressionsWithWatermark.join(clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime BETWEEN impressionTime AND impressionTime + interval 1 hour"""),
"leftOuter") // Only change: set the outer join type正如外连接所期望的那样,这个查询将开始为每次展示生成输出,无论有没有(即使用NULL)点击数据。但是,关于外连接还有几点需要注意:
-
与内连接不同,水印延迟和事件时间约束对于外连接不是可选的。这是因为为了生成
NULL结果,引擎必须知道将来什么时候事件不会与其他任何事件匹配。为了正确的外部连接结果和状态清理,必须指定水印和事件时间约束。 -
因此,外部
NULL结果将延迟生成,因为引擎必须等待一段时间以确保既没有也不会有任何匹配。该延迟是引擎为每个事件计算的最大缓冲时间(相对于事件时间),如上一节所述(即,展示时间为 4 小时,点击时间为 2 小时)。
任意状态计算
许多用例需要比我们目前讨论的 SQL 操作更复杂的逻辑。例如,假设您想通过实时跟踪用户的活动(例如,点击)来跟踪用户的状态(例如,登录、忙碌、空闲)。要构建此流处理管道,您必须将每个用户的活动历史记录为具有任意数据结构的状态,并根据用户的操作不断对数据结构应用任意复杂的更改。该操作mapGroupsWithState()及其更灵活的对应flatMapGroupsWithState()物专为此类复杂的分析用例而设计。
笔记
从 Spark 3.0 开始,这两个操作仅在 Scala 和 Java 中可用。
在本节中,我们将从一个简单的示例开始,mapGroupsWithState()以说明对自定义状态数据进行建模和在其上定义自定义操作的四个关键步骤。然后我们将讨论超时的概念以及如何使用它们来使一段时间没有更新的状态过期。我们将以 结束flatMapGroupsWithState(),这为您提供更大的灵活性。
使用 mapGroupsWithState() 对任意状态操作进行建模
具有任意模式和任意转换的状态被建模为用户定义的函数,该函数将先前版本的状态值和新数据作为输入,并生成更新后的状态和计算结果作为输出。在 Scala 中以编程方式,您必须定义一个具有以下签名的函数(K, V, S, 和U是数据类型,如后所述):
// In Scala
def arbitraryStateUpdateFunction(
key: K,
newDataForKey: Iterator[V],
previousStateForKey: GroupState[S]
): UgroupByKey()使用操作和将此函数提供给流式查询mapGroupsWithState(),如下所示:
// In Scala
val inputDataset: Dataset[V] = // input streaming Dataset
inputDataset
.groupByKey(keyFunction) // keyFunction() generates key from input
.mapGroupsWithState(arbitraryStateUpdateFunction)当这个流式查询开始时,在每个微批次中,Spark 将为arbitraryStateUpdateFunction()微批次数据中的每个唯一键调用它。让我们仔细看看参数是什么以及 Spark 将调用函数的参数值是什么:
key: K
K是在状态和输入中定义的公共键的数据类型。Spark 将为数据中的每个唯一键调用此函数。
newDataForKey: Iterator[V]
V是输入数据集的数据类型。当 Spark 为某个键调用此函数时,此参数将包含与该键对应的所有新输入数据。请注意,输入数据对象在迭代器中出现的顺序没有定义。
previousStateForKey: GroupState[S]
S是您将要维护的任意状态的数据类型,并且GroupState[S]是一个类型化的包装对象,它提供了访问和管理状态值的方法。当 Spark 为键调用此函数时,此对象将提供上次 Spark 为该键调用此函数时设置的状态值(即,为先前的微批次之一)。
U
U是函数输出的数据类型。
笔记
您必须提供几个附加参数。所有类型 (
K,V,S,U) 都必须可由 Spark SQL 的编码器编码。因此,在 中mapGroupsWithState(),您必须在 Scala 中隐式或在 Java 中显式提供类型化编码S器U。有关详细信息,请参阅第 6 章中的“数据集编码器”。
让我们通过一个示例来研究如何以这种格式表达所需的状态更新函数。假设我们想根据用户的行为了解用户行为。从概念上讲,这很简单:在每个微批次中,对于每个活跃用户,我们将使用用户采取的新操作并更新用户的“状态”。以编程方式,我们可以通过以下步骤定义状态更新函数:
-
定义数据类型。我们需要定义
K、V、S和的确切类型U。在这种情况下,我们将使用以下内容:-
Input data(
V) =case class UserAction(userId: String, action: String) -
Keys (
K) =String(即userId) -
State(
S) =case class UserStatus(userId: String, active: Boolean) -
Output (
U) =UserStatus, 因为我们要输出最新的用户状态请注意,编码器支持所有这些数据类型。
-
-
定义函数。根据选择的类型,让我们将概念转换为代码。当使用新用户操作调用此函数时,我们需要处理两种主要情况:该键(即,
userId)是否存在先前状态(即先前用户状态)。因此,我们将初始化用户的状态,或者用新的动作更新现有的状态。我们将使用新的运行计数显式更新状态,最后返回更新后的userId-userStatus对:// In Scala import org.apache.spark.sql.streaming._ def updateUserStatus( userId: String, newActions: Iterator[UserAction], state: GroupState[UserStatus]): UserStatus = { val userStatus = state.getOption.getOrElse { new UserStatus(userId, false) } newActions.foreach { action => userStatus.updateWith(action) } state.update(userStatus) return userStatus } -
将功能应用于动作。我们将使用
groupByKey()数据集对输入操作进行分组,然后使用以下函数应用该updateUserStatus函数mapGroupsWithState():// In Scala val userActions: Dataset[UserAction] = ... val latestStatuses = userActions .groupByKey(userAction => userAction.userId) .mapGroupsWithState(updateUserStatus _)
一旦我们使用控制台输出启动此流式查询,我们将看到更新的用户状态正在打印。
在我们继续讨论更高级的主题之前,需要记住一些值得注意的点:
-
调用该函数时,新数据迭代器中的输入记录没有明确定义的顺序(例如,
newActions)。如果您需要以特定顺序(例如,按照操作执行的顺序)使用输入记录更新状态,那么您必须显式地重新排序它们(例如,基于事件时间戳或其他排序 ID)。实际上,如果有可能从源中读取动作乱序,那么您必须考虑将来的微批处理可能会在当前批处理中的数据之前收到应该处理的数据。在这种情况下,您必须将记录作为状态的一部分进行缓冲。 -
在微批处理中,仅当微批处理具有该键的数据时,才对该键调用该函数一次。例如,如果一个用户变得不活跃并且很长时间没有提供新的操作,那么默认情况下,该函数将不会被长时间调用。如果你想根据用户长时间的不活动来更新或删除状态,你必须使用超时,我们将在下一节中讨论。
-
增量处理引擎的输出
mapGroupsWithState()假定为不断更新的键/值记录,类似于聚合的输出。这限制了 after 查询中支持哪些操作mapGroupsWithState(),以及支持哪些接收器。例如,不支持将输出附加到文件中。如果您想以更大的灵活性应用任意有状态操作,那么您必须使用flatMapGroupsWithState(). 我们将在超时后讨论这个问题。
使用超时来管理非活动组
在前面跟踪活跃用户会话的例子中,随着越来越多的用户变得活跃,状态中的键数将不断增加,状态使用的内存也会增加。现在,在现实世界的场景中,用户可能不会一直保持活跃。将非活动用户的状态保持在状态中可能不是很有用,因为在这些用户再次变为活动状态之前它不会再次更改。因此,我们可能希望明确删除非活动用户的所有信息。然而,用户可能不会明确地采取任何行动来变得不活跃(例如,明确地注销),并且我们可能必须将不活跃定义为在阈值持续时间内没有任何行动。这在函数中编码变得很棘手,因为在该用户有新操作之前不会为用户调用该函数。
要编码基于时间的不活动,mapGroupsWithState()支持定义如下的超时:
-
每次在键上调用函数时,都可以根据持续时间或阈值时间戳在键上设置超时。
-
如果该密钥没有接收到任何数据,从而满足超时条件,则将该密钥标记为“超时”。下一个微批次将调用此超时键上的函数,即使该微批次中没有该键的数据。在这个特殊的函数调用中,新的输入数据迭代器将为空(因为没有新数据)
GroupState.hasTimedOut()并将返回true。这是在函数内部识别调用是由于新数据还是超时的最佳方法。
基于我们的两种时间概念,有两种类型的超时:处理时间和事件时间。处理时间超时是两者中更简单的一个,所以我们将从它开始。
处理时间超时
处理时间超时基于运行流式查询的机器的系统时间(也称为挂钟时间),定义如下:如果密钥最后在系统时间戳 接收数据T,并且当前时间戳大于,然后将使用新的空数据迭代器再次调用该函数。(T + <timeout duration>)
让我们通过更新我们的用户示例来研究如何使用超时,以删除基于一小时不活动的用户状态。我们将进行三个更改:
-
在
mapGroupsWithState()中,我们将超时指定为GroupStateTimeout.ProcessingTimeTimeout。 -
在状态更新函数中,在用新数据更新状态之前,我们必须检查状态是否超时。因此,我们将更新或删除状态。
-
此外,每次我们用新数据更新状态时,我们都会设置超时时间。
这是更新的代码:
// In Scala
def updateUserStatus(
userId: String,
newActions: Iterator[UserAction],
state: GroupState[UserStatus]): UserStatus = {
if (!state.hasTimedOut) { // Was not called due to timeout
val userStatus = state.getOption.getOrElse {
new UserStatus(userId, false)
}
newActions.foreach { action => userStatus.updateWith(action) }
state.update(userStatus)
state.setTimeoutDuration("1 hour") // Set timeout duration
return userStatus
} else {
val userStatus = state.get()
state.remove() // Remove state when timed out
return userStatus.asInactive() // Return inactive user's status
}
}
val latestStatuses = userActions
.groupByKey(userAction => userAction.userId)
.mapGroupsWithState(
GroupStateTimeout.ProcessingTimeTimeout)(
updateUserStatus _)此查询将自动清理查询超过一个小时未处理任何数据的用户的状态。但是,关于超时,有几点需要注意:
-
上次调用该函数设置的超时时间会在再次调用该函数时自动取消,无论是新接收到的数据还是超时。因此,无论何时调用该函数,都需要显式设置超时持续时间或时间戳以启用超时。
-
由于超时是在微批处理期间处理的,因此它们的执行时间是不精确的,并且在很大程度上取决于触发间隔和微批处理时间。因此,不建议使用超时来进行精确的时序控制。
-
虽然处理时间超时很容易推理,但它们对减速和停机时间并不稳健。如果流式查询的宕机时间超过一小时,那么重启后,所有处于该状态的键都会超时,因为每个键接收到数据后已经过去了一个多小时。如果查询处理数据的速度比到达源的速度慢(例如,如果数据到达并在 Kafka 中缓冲),也会发生类似的大规模超时。例如,如果超时为 5 分钟,则处理速率的突然下降(或数据到达率的峰值)导致 5 分钟的延迟可能会产生虚假超时。为了避免此类问题,我们可以使用事件时间超时,我们将在下面讨论。
事件时间超时
事件时间超时不是基于系统时钟时间,而是基于数据中的事件时间(类似于基于时间的聚合)和在事件时间上定义的水印。如果一个键配置了特定的超时时间戳T(即,不是持续时间),那么T如果自上次调用函数以来没有接收到该键的新数据,则该键将在水印超过时超时。回想一下,水印是一个移动阈值,它滞后于处理数据时看到的最大事件时间。因此,与系统时间不同,水印在时间上以与处理数据相同的速率向前移动。这意味着(与处理时间超时不同)查询处理中的任何减速或停机时间都不会导致虚假超时。
让我们修改我们的示例以使用事件时间超时。除了我们已经为使用处理时间超时所做的更改之外,我们还将进行以下更改:
-
在输入数据集上定义水印(假设类
UserAction有一个eventTimestamp字段)。回想一下,水印阈值表示输入数据可能延迟和乱序的可接受时间量。 -
更新
mapGroupsWithState()使用EventTimeTimeout。 -
更新函数以设置将发生超时的阈值时间戳。请注意,事件时间超时不允许设置超时持续时间,例如处理时间超时。我们稍后会讨论这个原因。在这个例子中,我们将这个超时时间计算为当前水印加上一小时。
这是更新的示例:
// In Scala
def updateUserStatus(
userId: String,
newActions: Iterator[UserAction],
state: GroupState[UserStatus]):UserStatus = {
if (!state.hasTimedOut) { // Was not called due to timeout
val userStatus = if (state.getOption.getOrElse {
new UserStatus()
}
newActions.foreach { action => userStatus.updateWith(action) }
state.update(userStatus)
// Set the timeout timestamp to the current watermark + 1 hour
state.setTimeoutTimestamp(state.getCurrentWatermarkMs, "1 hour")
return userStatus
} else {
val userStatus = state.get()
state.remove()
return userStatus.asInactive() }
}
val latestStatuses = userActions
.withWatermark("eventTimestamp", "10 minutes")
.groupByKey(userAction => userAction.userId)
.mapGroupsWithState(
GroupStateTimeout.EventTimeTimeout)(
updateUserStatus _)此查询对于由重启和处理延迟引起的虚假超时将更加健壮。
以下是有关事件时间超时的几点注意事项:
-
与前面的处理时间超时示例不同,我们使用
GroupState.setTimeoutTimestamp()了GroupState.setTimeoutDuration(). 这是因为对于处理时间超时,持续时间足以计算发生超时的确切未来时间戳(即当前系统时间 + 指定持续时间),但对于事件时间超时,情况并非如此。不同的应用程序可能希望使用不同的策略来计算阈值时间戳。在这个例子中,我们只是根据当前的 watermark 来计算它,但不同的应用程序可能会选择根据为该键看到的最大事件时间时间戳(作为状态的一部分被跟踪并保存)来计算该键的超时时间戳。 -
超时时间戳必须设置为大于当前水印的值。这是因为当时间戳越过水印时预计会发生超时,因此将时间戳设置为已经大于当前水印的值是不合逻辑的。
在我们从超时开始之前,要记住的最后一件事是,您可以使用这些超时机制进行比固定持续时间超时更具创造性的处理。例如,您可以通过将最后一个任务执行时间戳保存在状态中并使用它来设置处理时间超时持续时间来在状态上实现一个近似周期性的任务(例如,每个小时),如此代码片段所示:
// In Scala
timeoutDurationMs = lastTaskTimstampMs + periodIntervalMs -
groupState.getCurrentProcessingTimeMs()使用 flatMapGroupsWithState() 进行泛化
有两个关键限制mapGroupsWithState()可能会限制我们想要实现更复杂用例(例如,链式会话)的灵活性:
-
每次
mapGroupsWithState()调用时,您必须返回一条且仅一条记录。对于某些应用程序,在某些触发器中,您可能根本不想输出任何内容。 -
对于
mapGroupsWithState(),由于缺乏关于不透明状态更新函数的更多信息,引擎假设生成的记录是更新的键/值数据对。因此,它对下游操作进行推理并允许或禁止其中一些操作。例如,使用生成的 DataFramemapGroupsWithState()不能以追加模式写入文件。但是,某些应用程序可能希望生成可被视为追加的记录。
flatMapGroupsWithState()以稍微复杂的语法为代价克服了这些限制。它与 有两个不同mapGroupsWithState():
-
返回类型是一个迭代器,而不是单个对象。这允许函数返回任意数量的记录,或者,如果需要,根本不返回任何记录。
-
它接受另一个参数,称为运算符输出模式(不要与我们在本章前面讨论的查询输出模式混淆),它定义输出记录是可以附加的新记录(
OutputMode.Append)还是更新的键/值记录(OutputMode.Update)。
为了说明这个函数的使用,让我们扩展我们的用户跟踪示例(我们删除了超时以保持代码简单)。例如,如果我们只想为某些用户更改生成警报,并且我们想将输出警报写入文件,我们可以执行以下操作:
// In Scala
def getUserAlerts(
userId: String,
newActions: Iterator[UserAction],
state: GroupState[UserStatus]): Iterator[UserAlert] = {
val userStatus = state.getOption.getOrElse {
new UserStatus(userId, false)
}
newActions.foreach { action =>
userStatus.updateWith(action)
}
state.update(userStatus)
// Generate any number of alerts
return userStatus.generateAlerts().toIterator
}
val userAlerts = userActions
.groupByKey(userAction => userAction.userId)
.flatMapGroupsWithState(
OutputMode.Append,
GroupStateTimeout.NoTimeout)(
getUserAlerts)
性能调优
结构化流使用 Spark SQL 引擎,因此可以使用与第5章和第7章中讨论的 Spark SQL 相同的参数进行调整。但是,与可能处理 GB 到 TB 数据的批处理作业不同,微批处理作业通常处理的数据量要小得多。因此,运行流式查询的 Spark 集群通常需要稍微不同地进行调整。以下是一些需要牢记的注意事项:
集群资源供应
由于运行流式查询的 Spark 集群将 24/7 全天候运行,因此适当地配置资源非常重要。资源配置不足可能导致流式查询落后(微批处理花费的时间越来越长),而过度配置(例如,已分配但未使用的核心)可能会导致不必要的成本。此外,应根据流式查询的性质进行分配:无状态查询通常需要更多内核,而有状态查询通常需要更多内存。
洗牌的分区数
对于结构化流查询,shuffle 分区的数量通常需要设置得比大多数批处理查询低得多——过多地划分计算会增加开销并降低吞吐量。此外,由于有状态操作的洗牌由于检查点而具有显着更高的任务开销。因此,对于有状态操作和触发间隔为几秒到几分钟的流式查询,建议将 shuffle分区的数量从默认值 200 调整到最多分配核心数的两到三倍。
为稳定性设置源速率限制
在针对查询的预期输入数据速率优化分配的资源和配置后,数据速率的突然激增可能会产生意外的大型作业和随后的不稳定。除了代价高昂的过度配置方法外,您还可以使用源速率限制来防止不稳定。在支持的源(例如,Kafka 和文件)中设置限制可以防止查询在单个微批处理中消耗过多的数据。激增的数据将在源中保持缓冲,并且查询最终会赶上。但是,请注意以下几点:
-
将限制设置得太低会导致查询未充分利用分配的资源并落后于输入速率。
-
限制不能有效地防止输入速率的持续增加。在保持稳定性的同时,缓冲的、未处理的数据量将在源端无限增长,端到端延迟也会如此。
同一 Spark 应用程序中的多个流式查询
在同一个中运行多个流式查询,SparkContext或者SparkSession可以导致细粒度的资源共享。然而:
-
执行每个查询会持续使用 Spark 驱动程序(即运行它的 JVM)中的资源。这限制了驱动程序可以同时执行的查询数量。达到这些限制可能会成为任务调度的瓶颈(即,未充分利用执行程序)或超出内存限制。
-
您可以通过将它们设置为在单独的调度程序池中运行来确保在相同上下文中的查询之间更公平地分配资源。将
SparkContext的线程局部属性spark.scheduler.pool设置为每个流的不同字符串值:// In Scala // Run streaming query1 in scheduler pool1 spark.sparkContext.setLocalProperty("spark.scheduler.pool", "pool1") df.writeStream.queryName("query1").format("parquet").start(path1) // Run streaming query2 in scheduler pool2 spark.sparkContext.setLocalProperty("spark.scheduler.pool", "pool2") df.writeStream.queryName("query2").format("parquet").start(path2)
# In Python
# Run streaming query1 in scheduler pool1
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "pool1")
df.writeStream.queryName("query1").format("parquet").start(path1)
# Run streaming query2 in scheduler pool2
spark.sparkContext.setLocalProperty("spark.scheduler.pool", "pool2")
df.writeStream.queryName("query2").format("parquet").start(path2)概括
本章探讨了使用 DataFrame API 编写结构化流查询。具体来说,我们讨论了:
-
结构化流的核心理念和将输入数据流视为无界表的处理模型
-
定义、启动、重启和监控流式查询的关键步骤
-
如何使用各种内置的流源和接收器以及编写自定义流接收器
-
如何使用和调整托管的有状态操作,如流聚合和流-流连接
-
表达自定义有状态计算的技术
相关文章
- Apache站点优化-数据压缩
- apache 负载均衡 超时设置_apache负载均衡配置
- apache 里的 ProxyPassReverse 指令
- Windows Server配置Apache(WAMPServer)
- 详解 Apache Pulsar 消息生命周期
- 实时化浪潮下,Apache Flink还将在大数据领域掀起怎样的变革?
- 借助IBCS虚拟专线优化Apache Spark集群性能
- 一个封装的使用Apache HttpClient进行Http请求(GET、POST、PUT等)的类。详解编程语言
- apache用Linux服务器架设QQ五笔输入法服务:基于Apache技术(qq五笔linux)
- Linux 下 Apache 服务器安装指南(linux安装apache)
- 的结合Apache和MySQL的完美结合(apache与mysql)
- 如何在CentOS 8上安装Apache Maven
- 用Spark轻松写入Redis(spark写入redis)
- 阿里巴巴向 Apache 软件基金会捐赠消息中间件 RocketMQ
- Spark 更新 MySQL 数据库:实现快速、高效转移(spark更新mysql)
- 如何正确卸载Linux服务器上的Apache Web服务器?(linux卸载apache)
- windows配置Apache+PHP+MySQL动态网站环境
- 以Apache、MySQL和PHP组成的最强技术栈(apache mysql php)
- Spark构建Redis数据按照高效实时处理(spark连接redis)
- 基于Spark实现Redis数据库查询(spark查询redis)
- 以Spark精准洞悉Redis潜力(spark分析redis)
- 学习Apache的modrewrite、access写法
- WINDOWS系统+Apache+PHP5+Zend+MySQL+phpMyAdmin安装配置方法
- apache+codeigniter通过.htcaccess做动态二级域名解析
- Linux下APACHE&PHP&MYSQL&CGI修改版
- Apache服务器无法使用的解决方法