
手把手调参 YOLOv8 模型之 训练|验证|推理配置-详解
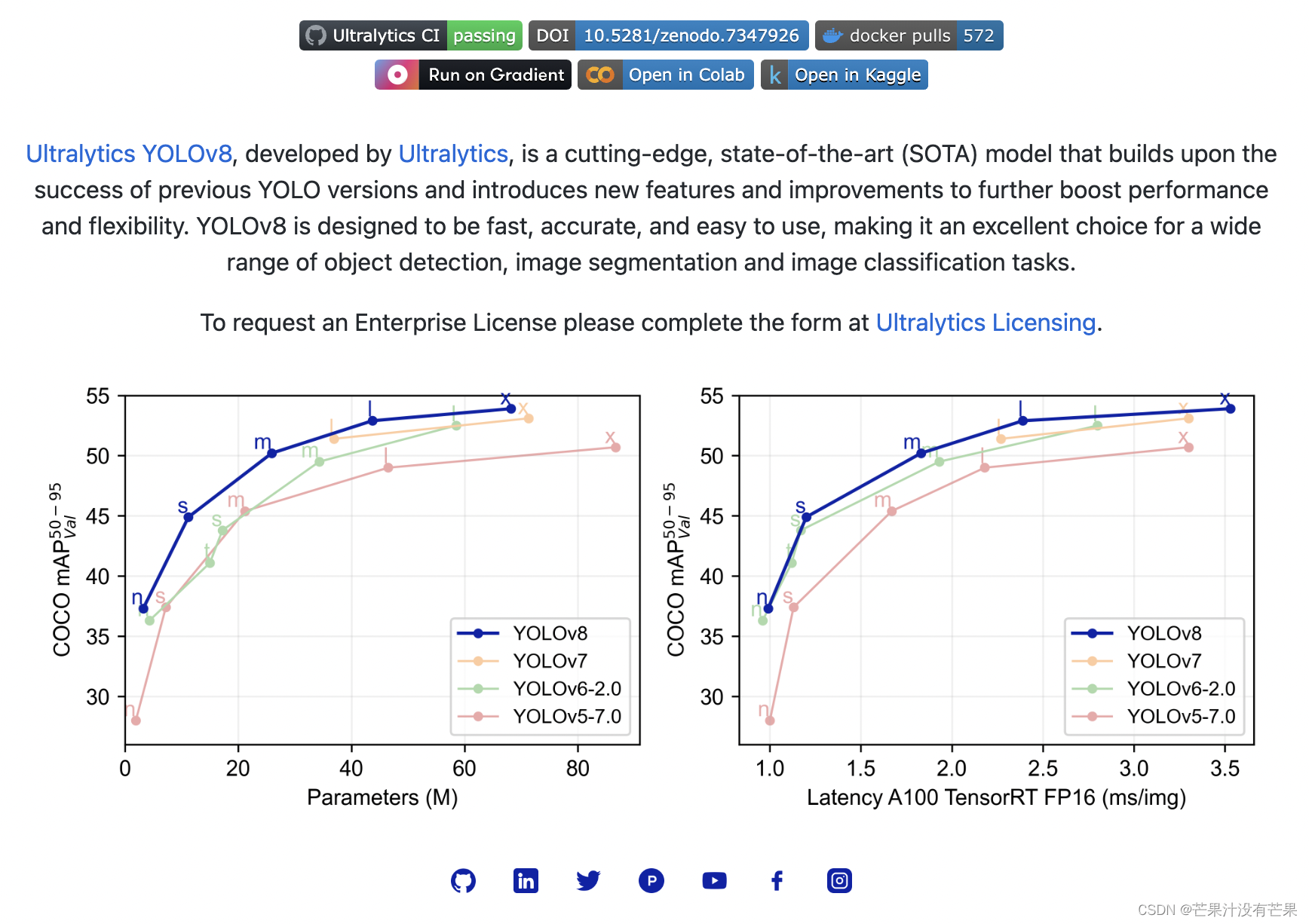
YOLO系列模型在目标检测领域有着十分重要的地位,随着版本不停的迭代,模型的性能在不断地提升,源码提供的功能也越来越多,那么如何使用源码就显得十分的重要,接下来通过文章带大家手把手去了解Yolov8(最新版本)的每一个参数的含义,并且通过具体的图片例子让大家明白每个参数改动将会给网络带来哪些影响。
这篇文章讲解的是 关于 YOLOv8最新版本 的配置解析🚀
包含 训练|验证|推理 部分汇总
YOLOv7 模型 手把手调参系列🚀
YOLOv8 模型 手把手调参系列🚀
文章目录
- 1. 代码获取方式🌟
- 2. 准备项目环境✨
- 3. YOLOv8 💡
- 4. default.yaml
- 4.1 YOLOv8 网络模型结构图
- 4.2 Predict参数详解🚀
- 4.2.1 “source”
- 4.2.2 “show: False”
- 4.2.3 “save_txt: False”
- 4.2.4 “save_conf: False”
- 4.2.5 “save_crop: False”
- 4.2.6 “hide_conf: False”
- 4.2.7 “vid_stride: 1”
- 4.2.8 “line_thickness: 3”
- 4.2.9 “visualize: False”
- 4.2.10 “augment: False”
- 4.2.11 “agnostic_nms: False”
- 4.2.12 “classes:”
- 4.2.13 “retina_masks: False”
- 4.2.14 “boxes: True”
- Predict参数配置一览
- train 参数配置
- val参数配置
- 5. COCO数据集训练配置
- 6. YOLOv8 网络配置
1. 代码获取方式🌟
官方YOLOv8 项目地址:https://github.com/ultralytics/ultralytics
进入仓库 可以查看项目目前提供的最新版本
选择的代码是main分支版本

2. 准备项目环境✨
在配置Conda环境后就可以进入项目了,在终端中键入如下指令:
pip install ultralytics
3. YOLOv8 💡
YOLOv8 可以直接在命令行界面(CLI)中使用 yolo 命令运行:
yolo predict model=yolov8n.pt source="https://ultralytics.com/images/bus.jpg"
4. default.yaml
default.yaml配置文件如下
# Ultralytics YOLO 🚀, GPL-3.0 license
# Default training settings and hyperparameters for medium-augmentation COCO training
task: detect # inference task, i.e. detect, segment, classify
mode: train # YOLO mode, i.e. train, val, predict, export
# Train settings -------------------------------------------------------------------------------------------------------
model: # path to model file, i.e. yolov8n.pt, yolov8n.yaml
data: # path to data file, i.e. i.e. coco128.yaml
epochs: 100 # number of epochs to train for
patience: 50 # epochs to wait for no observable improvement for early stopping of training
batch: 16 # number of images per batch (-1 for AutoBatch)
imgsz: 640 # size of input images as integer or w,h
save: True # save train checkpoints and predict results
cache: False # True/ram, disk or False. Use cache for data loading
device: # device to run on, i.e. cuda device=0 or device=0,1,2,3 or device=cpu
workers: 8 # number of worker threads for data loading (per RANK if DDP)
project: # project name
name: # experiment name
exist_ok: False # whether to overwrite existing experiment
pretrained: False # whether to use a pretrained model
optimizer: SGD # optimizer to use, choices=['SGD', 'Adam', 'AdamW', 'RMSProp']
verbose: True # whether to print verbose output
seed: 0 # random seed for reproducibility
deterministic: True # whether to enable deterministic mode
single_cls: False # train multi-class data as single-class
image_weights: False # use weighted image selection for training
rect: False # support rectangular training if mode='train', support rectangular evaluation if mode='val'
cos_lr: False # use cosine learning rate scheduler
close_mosaic: 10 # disable mosaic augmentation for final 10 epochs
resume: False # resume training from last checkpoint
min_memory: False # minimize memory footprint loss function, choices=[False, True, <roll_out_thr>]
# Segmentation
overlap_mask: True # masks should overlap during training (segment train only)
mask_ratio: 4 # mask downsample ratio (segment train only)
# Classification
dropout: 0.0 # use dropout regularization (classify train only)
# Val/Test settings ----------------------------------------------------------------------------------------------------
val: True # validate/test during training
save_json: False # save results to JSON file
save_hybrid: False # save hybrid version of labels (labels + additional predictions)
conf: # object confidence threshold for detection (default 0.25 predict, 0.001 val)
iou: 0.7 # intersection over union (IoU) threshold for NMS
max_det: 300 # maximum number of detections per image
half: False # use half precision (FP16)
dnn: False # use OpenCV DNN for ONNX inference
plots: True # save plots during train/val
# Prediction settings --------------------------------------------------------------------------------------------------
source: # source directory for images or videos
show: False # show results if possible
save_txt: False # save results as .txt file
save_conf: False # save results with confidence scores
save_crop: False # save cropped images with results
hide_labels: False # hide labels
hide_conf: False # hide confidence scores
vid_stride: 1 # video frame-rate stride
line_thickness: 3 # bounding box thickness (pixels)
visualize: False # visualize model features
augment: False # apply image augmentation to prediction sources
agnostic_nms: False # class-agnostic NMS
classes: # filter results by class, i.e. class=0, or class=[0,2,3]
retina_masks: False # use high-resolution segmentation masks
boxes: True # Show boxes in segmentation predictions
# Export settings ------------------------------------------------------------------------------------------------------
format: torchscript # format to export to
keras: False # use Keras
optimize: False # TorchScript: optimize for mobile
int8: False # CoreML/TF INT8 quantization
dynamic: False # ONNX/TF/TensorRT: dynamic axes
simplify: False # ONNX: simplify model
opset: # ONNX: opset version (optional)
workspace: 4 # TensorRT: workspace size (GB)
nms: False # CoreML: add NMS
# Hyperparameters ------------------------------------------------------------------------------------------------------
lr0: 0.01 # initial learning rate (i.e. SGD=1E-2, Adam=1E-3)
lrf: 0.01 # final learning rate (lr0 * lrf)
momentum: 0.937 # SGD momentum/Adam beta1
weight_decay: 0.0005 # optimizer weight decay 5e-4
warmup_epochs: 3.0 # warmup epochs (fractions ok)
warmup_momentum: 0.8 # warmup initial momentum
warmup_bias_lr: 0.1 # warmup initial bias lr
box: 7.5 # box loss gain
cls: 0.5 # cls loss gain (scale with pixels)
dfl: 1.5 # dfl loss gain
fl_gamma: 0.0 # focal loss gamma (efficientDet default gamma=1.5)
label_smoothing: 0.0 # label smoothing (fraction)
nbs: 64 # nominal batch size
hsv_h: 0.015 # image HSV-Hue augmentation (fraction)
hsv_s: 0.7 # image HSV-Saturation augmentation (fraction)
hsv_v: 0.4 # image HSV-Value augmentation (fraction)
degrees: 0.0 # image rotation (+/- deg)
translate: 0.1 # image translation (+/- fraction)
scale: 0.5 # image scale (+/- gain)
shear: 0.0 # image shear (+/- deg)
perspective: 0.0 # image perspective (+/- fraction), range 0-0.001
flipud: 0.0 # image flip up-down (probability)
fliplr: 0.5 # image flip left-right (probability)
mosaic: 1.0 # image mosaic (probability)
mixup: 0.0 # image mixup (probability)
copy_paste: 0.0 # segment copy-paste (probability)
# Custom config.yaml ---------------------------------------------------------------------------------------------------
cfg: # for overriding defaults.yaml
# Debug, do not modify -------------------------------------------------------------------------------------------------
v5loader: False # use legacy YOLOv5 dataloader
4.1 YOLOv8 网络模型结构图
 图 1:YOLOv8-P5 模型结构
图 1:YOLOv8-P5 模型结构
4.2 Predict参数详解🚀
在default.yaml文件中,就是参数配置,其中
4.2.1 “source”
source:
这个就是 图片或视频的源目录
4.2.2 “show: False”
show: False
是否显示结果
4.2.3 “save_txt: False”
save_txt: False
这个意思就是将结果保存为 .txt 文件
4.2.4 “save_conf: False”
save_conf: False
这个就是保存带有置信度分数的结果
4.2.5 “save_crop: False”
save_crop: False
这个参数就是保存裁剪后的图像和结果
4.2.6 “hide_conf: False”
hide_conf: False
这个参数意思就是隐藏标签。
4.2.7 “vid_stride: 1”
vid_stride: 1
表示视频帧率步幅。
4.2.8 “line_thickness: 3”
line_thickness: 3
这个参数意思就是检测的时候边界框粗细(像素)
4.2.9 “visualize: False”
visualize: False
这个参数的意思就是:是否使用可视化模型特征
4.2.10 “augment: False”
augment: False
这个参数的意思就是将图像增强应用于预测
4.2.11 “agnostic_nms: False”
agnostic_nms: False
类别不可知的 NMS
4.2.12 “classes:”
classes:
按类别过滤结果,即 class=0 或 class=[0,2,3]
这个的意思就是我们可以给变量指定多个赋值,也就是说我们可以把“0”赋值给“classes”,也可以把“0”“2”“4”“6”都赋值给“classes”
接下来说classes参数,这里看一下coco128.yaml的配置文件就明白了,比如说我这里给classes指定“0”,那么意思就是只检测人这个类别。
4.2.13 “retina_masks: False”
retina_masks: False
这个参数表示使用高分辨率分割掩码
4.2.14 “boxes: True”
boxes: True
在分割预测中显示框
Predict参数配置一览
model.predict接受控制预测操作的多个参数。这些参数可以直接传递给model.predict:
model.predict(source, save=True, imgsz=320, conf=0.5)
All supported arguments:
| Key | Value | Description |
|---|---|---|
source | 'ultralytics/assets' | 图片或视频的源目录 |
conf | 0.25 | 用于检测的对象置信度阈值 |
iou | 0.7 | NMS 的联合交集 (IoU) 阈值 |
half | False | 使用半精度 (FP16) |
device | None | 要运行的设备,即 cuda device=0/1/2/3 或 device=cpu |
show | False | 尽可能显示结果 |
save | False | 保存图像和结果 |
save_txt | False | 将结果保存为 .txt 文件 |
save_conf | False | 保存带有置信度分数的结果 |
save_crop | False | 保存裁剪后的图像和结果 |
hide_labels | False | 隐藏标签 |
hide_conf | False | 隐藏置信度分数 |
max_det | 300 | 每张图像的最大检测数 |
vid_stride | False | 视频帧率步幅 |
line_thickness | 3 | 边界框大小(像素) |
visualize | False | 可视化模型特征 |
augment | False | 将图像增强应用于预测源 |
agnostic_nms | False | 类别不可知的 NMS |
retina_masks | False | 使用高分辨率分割蒙版 |
classes | None | 按类过滤结果,即class=0,或class=[0,2,3] |
boxes | True | 在分割预测中显示框 |
train 参数配置
YOLO 模型的训练设置是指用于在数据集上训练模型的各种超参数和配置。
| Key | Value | Description |
|---|---|---|
model | None | 模型文件路径,即yolov8n.pt、yolov8n.yaml |
data | None | 数据文件的路径,即 coco128.yaml |
epochs | 100 | 要训练的时期数 |
patience | 50 | 等待早期停止训练没有明显改善的时代 |
batch | 16 | 每批次的图像数量(AutoBatch 为 -1) |
imgsz | 640 | 输入图像的大小为整数或 w,h |
save | True | 保存火车检查站并预测结果 |
save_period | -1 | 每 x 个时期保存检查点(如果 < 1 则禁用) |
cache | False | True/ram、disk 或 False。使用缓存进行数据加载 |
device | None | 要运行的设备,即 cuda device=0 或 device=0,1,2,3 或 device=cpu |
workers | 8 | 用于数据加载的工作线程数(如果是 DDP,则为每个 RANK) |
project | None | 项目名(eg:mg) |
name | None | 实验名称 |
exist_ok | False | 是否覆盖现有实验 |
pretrained | False | 是否使用预训练模型 |
optimizer | 'SGD' | 要使用的优化器,choices=[‘SGD’, ‘Adam’, ‘AdamW’, ‘RMSProp’] |
verbose | False | 是否打印详细输出 |
seed | 0 | 可重复性的随机种子 |
deterministic | True | 是否启用确定性模式 |
single_cls | False | 将多类数据训练为单类 |
image_weights | False | 使用加权图像选择进行训练 |
rect | False | 为最小填充整理每批次的矩形训练 |
cos_lr | False | 使用余弦学习率调度器 |
close_mosaic | 0 | (int) 禁用最后时期的马赛克增强 |
resume | False | 从上一个检查点恢复训练 |
amp | True | 自动混合精度 (AMP) 训练,选择=[True, False] |
lr0 | 0.01 | 初始学习率(即SGD=1E-2,Adam=1E-3) |
lrf | 0.01 | 最终学习率 (lr0 * lrf) |
momentum | 0.937 | SGD momentum/亚当 beta1 |
weight_decay | 0.0005 | 优化器权重衰减 5e-4 |
warmup_epochs | 3.0 | 热身时期(分数确定) |
warmup_momentum | 0.8 | 热身初始动量 |
warmup_bias_lr | 0.1 | 预热初始偏置 lr |
box | 7.5 | 框丢失增益 |
cls | 0.5 | cls 损失增益(按像素缩放) |
dfl | 1.5 | dfl 损失增益 |
pose | 12.0 | 姿势损失增益(仅限姿pose) |
kobj | 2.0 | 关键点对象损失增益(仅限关键点) |
label_smoothing | 0.0 | 标签平滑(分数) |
nbs | 64 | 标称批量 |
overlap_mask | True | 训练期间掩码应该重叠(仅限分段训练) |
mask_ratio | 4 | 掩码下采样率(仅分段训练) |
dropout | 0.0 | 使用 dropout 正则化(仅分类训练) |
val | True | 在培训期间验证/测试 |
val参数配置
YOLO 模型的验证设置是指用于验证的各种超参数和配置
评估模型在验证数据集上的性能。
| Key | Value | Description |
|---|---|---|
data | None | 数据文件的路径,即coco128.yaml |
imgsz | 640 | 图像大作为标量或 (h, w) 列表,即 (640, 480) |
batch | 16 | 每次批次的图像数量(AutoBatch为-1) |
save_json | False | 将结果保存到 JSON 文件 |
save_hybrid | False | 保存标签的混合版本(标签+附加预测) |
conf | 0.001 | 用于检测的对象设置信度值 |
iou | 0.6 | NMS 的联合交易集 (IoU) 阈值 |
max_det | 300 | 每个张图的最大检测数 |
half | True | 使用半精度 (FP16) |
device | None | 要运行的设备,即cuda device=0/1/2/3 或者device=cpu |
dnn | False | 使用 OpenCV DNN 进行 ONNX 推理 |
plots | False | 在训练期间显示图 |
rect | False | 为最小填充整顿每次批次的形状值 |
split | val | 数据集拆分用于验证,即“val”、“test”或“train” |
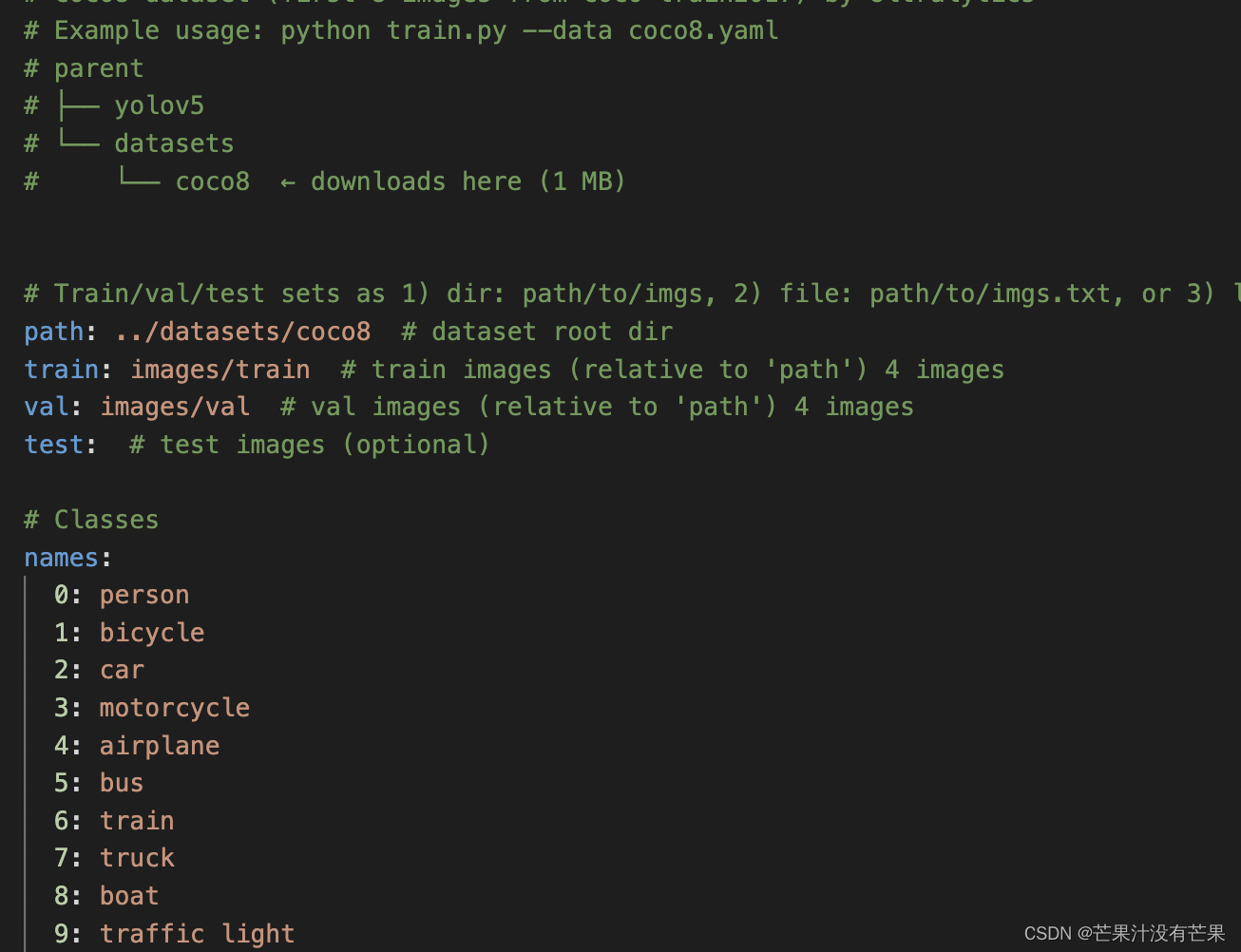
5. COCO数据集训练配置
# Ultralytics YOLO 🚀, GPL-3.0 license
# COCO8 dataset (first 8 images from COCO train2017) by Ultralytics
# Example usage: python train.py --data coco8.yaml
# parent
# ├── yolov5
# └── datasets
# └── coco8 ← downloads here (1 MB)
# Train/val/test sets as 1) dir: path/to/imgs, 2) file: path/to/imgs.txt, or 3) list: [path/to/imgs1, path/to/imgs2, ..]
path: ../datasets/coco8 # dataset root dir
train: images/train # train images (relative to 'path') 4 images
val: images/val # val images (relative to 'path') 4 images
test: # test images (optional)
# Classes
names:
0: person
1: bicycle
2: car
3: motorcycle
4: airplane
5: bus
6: train
7: truck
8: boat
9: traffic light
10: fire hydrant
11: stop sign
12: parking meter
13: bench
14: bird
15: cat
16: dog
17: horse
18: sheep
19: cow
20: elephant
21: bear
22: zebra
23: giraffe
24: backpack
25: umbrella
26: handbag
27: tie
28: suitcase
29: frisbee
30: skis
31: snowboard
32: sports ball
33: kite
34: baseball bat
35: baseball glove
36: skateboard
37: surfboard
38: tennis racket
39: bottle
40: wine glass
41: cup
42: fork
43: knife
44: spoon
45: bowl
46: banana
47: apple
48: sandwich
49: orange
50: broccoli
51: carrot
52: hot dog
53: pizza
54: donut
55: cake
56: chair
57: couch
58: potted plant
59: bed
60: dining table
61: toilet
62: tv
63: laptop
64: mouse
65: remote
66: keyboard
67: cell phone
68: microwave
69: oven
70: toaster
71: sink
72: refrigerator
73: book
74: clock
75: vase
76: scissors
77: teddy bear
78: hair drier
79: toothbrush
# Download script/URL (optional)
download: https://ultralytics.com/assets/coco8.zip
6. YOLOv8 网络配置
# Ultralytics YOLO 🚀, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # scales module repeats
width_multiple: 0.50 # scales convolution channels
# YOLOv8.0s backbone
backbone:
# [from, repeats, module, args]
- [-1, 1, Conv, [64, 3, 2]] # 0-P1/2
- [-1, 1, Conv, [128, 3, 2]] # 1-P2/4
- [-1, 3, C2f, [128, True]]
- [-1, 1, Conv, [256, 3, 2]] # 3-P3/8
- [-1, 6, C2f, [256, True]]
- [-1, 1, Conv, [512, 3, 2]] # 5-P4/16
- [-1, 6, C2f, [512, True]]
- [-1, 1, Conv, [1024, 3, 2]] # 7-P5/32
- [-1, 3, C2f, [1024, True]]
- [-1, 1, SPPF, [1024, 5]] # 9
# YOLOv8.0s head
head:
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]] # cat backbone P4
- [-1, 3, C2f, [512]] # 13
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 4], 1, Concat, [1]] # cat backbone P3
- [-1, 3, C2f, [256]] # 17 (P3/8-small)
- [-1, 1, Conv, [256, 3, 2]]
- [[-1, 12], 1, Concat, [1]] # cat head P4
- [-1, 3, C2f, [512]] # 20 (P4/16-medium)
- [-1, 1, Conv, [512, 3, 2]]
- [[-1, 9], 1, Concat, [1]] # cat head P5
- [-1, 3, C2f, [1024]] # 23 (P5/32-large)
- [[15, 18, 21], 1, Detect, [nc]] # Detect(P3, P4, P5)
其他的后续补充
参考链接: YOLOv8官方仓库 https://github.com/ultralytics/ultralytics
相关文章
- yolov2在CUDA8.0+cudnn8.0下安装、训练、检测经历
- faster r-cnn 在CPU配置下训练自己的数据
- Java实现 蓝桥杯 算法训练 数字游戏
- Java实现 蓝桥杯VIP 算法训练 连续正整数的和
- Java实现 蓝桥杯VIP 算法训练 链表数据求和操作
- Java 蓝桥杯 算法训练 字符串的展开 (JAVA语言实现)
- keras系列︱图像多分类训练与利用bottleneck features进行微调(三)
- NLP:自然语言处理技术领域的代表性算法概述(技术迭代路线图/发展时间路线)、四大技术范式变迁概述(统计时代→大模型时代)、四个时代的技术方法论探究(少数公司可承担的训练成本原因)之详细攻略
- TF之CNN:基于CIFAR-10数据集训练、检测CNN(2+2)模型(TensorBoard可视化)
- BN融合的量化感知训练及其uint8推理的模拟