
简单Python爬虫编写——requests包使用初体验
2023-09-14 09:15:14 时间
今天继续给大家介绍Python相关知识,本文主要内容是简单Python爬虫编写——requests包使用初体验。
一、爬虫代码程序
接下来,我们就通过一个简单的程序,来实现简单的python爬虫编写——使用Python爬虫爬取百度主页。代码如下所示:
import requests
url="https://www.baidu.com/"
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}
reponse=requests.get(url=url,headers=header)
page_text=reponse.text
with open(r"C:\Users\Administrator\Desktop\baidu.html",'w',encoding="utf-8") as fp:
fp.write(page_text)
print("Mission completed!")
二、爬虫代码解析
在上述代码中,我们引用了requests库,requests库的安装需要在cmd下执行命令:
pip install requests
我由于已经安装过了,因此上述命令执行结果如下所示:

在上述代码中,我们定义了url变量,该变量指定了目标URL,同时还使用了headers变量指定了一个字典。这个字典的键是User-Agent,值是一个谷歌浏览器的User-Agent头。接下来,调用了requests.get()方法,并指定了url和headers参数,这两个参数分别表示requests发起请求的目标url以及添加的User-Agent头。该方法会返回一个响应对象,引用该对象的text属性可以返回响应数据包的数据。最后,程序把数据写到了一个html文件文件中。
三、爬虫代码执行结果
上述代码执行后,我们可以打开该HTML文件,发现执行结果如下所示:
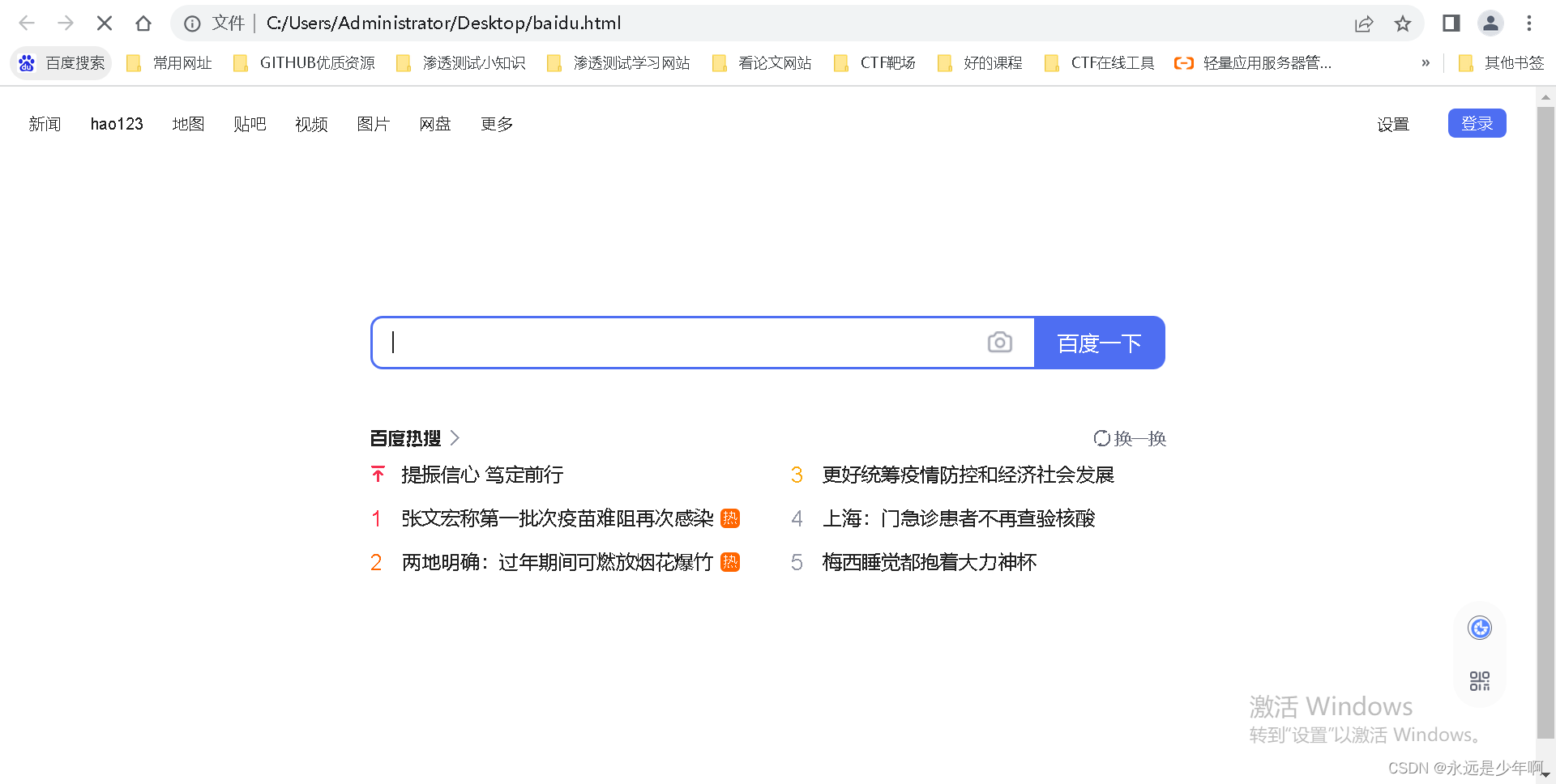
从上图可以看出,我们成功爬取到了百度的页面!(注意:由于一些文件我们没有下载,因此和百度主页面不完全相同)
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200
相关文章
- Python爬虫之urllib.parse详解
- python爬虫之分析Ajax请求抓取抓取今日头条街拍美图(七)
- 第三百四十五节,Python分布式爬虫打造搜索引擎Scrapy精讲—爬虫和反爬的对抗过程以及策略—scrapy架构源码分析图
- python之simplejson,Python版的简单、 快速、 可扩展 JSON 编码器/解码器
- Python正则表达式如何进行字符串替换实例
- python:ERROR: No matching distribution found for Pillow==9.1.0的处理(Python 3.6.8)
- 如何入门 Python 爬虫?
- 零基础自学python网络爬虫有没有学习路线。最好是详细的?
- Python语言学习:Python语言学习之python包/库package的简介(模块的封装/模块路径搜索/模块导入方法/自定义导入模块实现华氏-摄氏温度转换案例应用)、使用方法、管理工具之详细攻略
- Python语言学习:在python中,如何获取变量的本身字符串名字而非其值/内容及其应用(在代码中如何查找同值的所有变量名)
- Python语言学习之文件夹那些事:python和文件夹的使用方法之详细攻略
- Python之ffmpeg:利用python编程基于ffmpeg将m4a格式音频文件转为mp3格式文件
- Python之pandas:特征工程中数据类型(object/category/bool/int32/int64/float64)的简介、数据类型转换四大方法、案例应用之详细攻略
- 已解决2.Set PROTOCOL_BUFFERS_PYTHON_IMPLEMENTATION=python (but this will use pure-Python parsing and wi
- 已解决2. Set PROTOCOL_BUPFERS_PYTHON_iMPLEMENTATION=python (but this will use pure-Python parsing and w
- 〖Python自动化办公篇⑳〗 - python实现邮件自动化 - 发送html邮件和带附件的邮件
- Python精确指南——第三章 Selenium和爬虫
- 太好玩了!我用 Python 制作一款小游戏!
- 《Fluent Python》读书笔记-2.4
- python实战===2017年30个惊艳的Python开源项目 (转)
- python基础===八大排序算法的 Python 实现
- 【Python基础】python爬虫之异步网络爬虫ǃ
- 【python】Python实现网络爬虫demo实例
- Python爬虫入门并不难,甚至入门也很简单
- python工具方法27 训练时在线random resize的实现(支持图像分类与语义分割)
- 【Python实战】 ---- 爬虫 爬取LOL英雄皮肤图片
- Python 爬虫 NO.4 HTTP 响应状态码
- 《从零开始,学会Python爬虫不再难!!!》系列导航(持续更新中)