
Transfomer入门:Self-attention + Multi-head Self-attention
入门 multi head self ATTENTION
2023-09-14 09:14:43 时间
Q、K、V生动的例子:
举个简单例子说明:
- 假设世界上所有小吃都可以被标签化,例如微辣、特辣、变态辣、微甜、有嚼劲....,总共有1000个标签,现在我想要吃的小吃是[微辣、微甜、有嚼劲],这三个单词就是我的Query
- 来到东门老街一共100家小吃店,每个店铺卖的东西不一样,但是肯定可以被标签化,例如第一家小吃被标签化后是[微辣、微咸],第二家小吃被标签化后是[特辣、微臭、特咸],第三家小吃被标签化后是[特辣、微甜、特咸、有嚼劲],其余店铺都可以被标签化,每个店铺的标签就是Keys,但是每家店铺由于卖的东西不一样,单品种类也不一样,所以被标签化后每一家的标签List不一样长
- Values就是每家店铺对应的单品,例如第一家小吃的Values是[烤羊肉串、炒花生]
- 将Query和所有的Keys进行一一比对,相当于计算相似性,此时就可以知道我想买的小吃和每一家店铺的匹配情况,最后有了匹配列表,就可以去店铺里面买东西了(Values和相似性加权求和)。最终的情况可能是,我在第一家店铺买了烤羊肉串,然后在第10家店铺买了个玉米,最后在第15家店铺买了个烤面筋
以上就是完整的注意力机制,采用我心中的标准Query去和被标签化的所有店铺Keys一一比对,此时就可以得到我的Query在每个店铺中的匹配情况,最终去不同店铺买不同东西的过程就是权重和Values加权求和过程。
使用self-attention layer取代RNN所做的事情
而CNN的一个好处是:它是可以并行化的 (can parallel),不需要等待红色的filter算完,再算黄色的filter。但是必须要叠很多层filter,才可以看到长时的资讯。所以今天有一个想法:self-attention,如下图3所示,目的是使用self-attention layer取代RNN所做的事情。
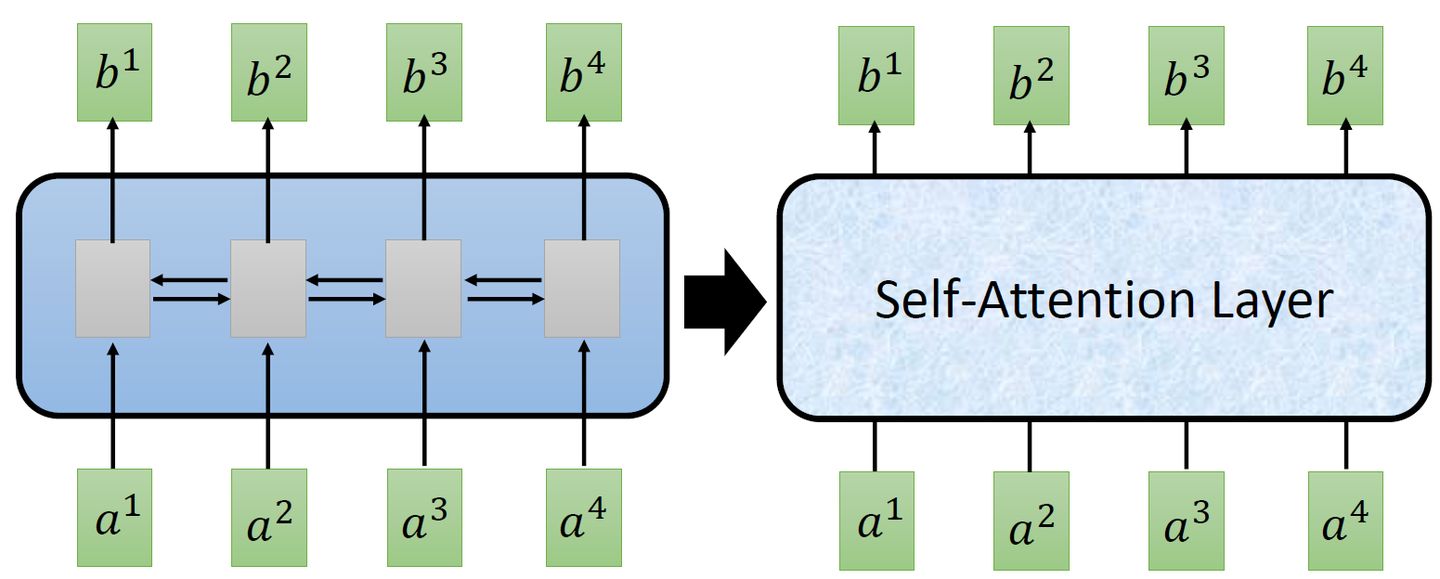
图3:You can try to replace any thing that has been done by RNN with self-attention
所以重点是:我们有一种新的layer,叫self-attention,它的输入和输出和RNN是一模一样的,输入一个sequence,输出一个sequence,它的每一个输出 b1-b4 都看过了整个的输入sequence,这一点与bi-directional RNN(双向循环神经网络)相同。但是神奇的地方是:它的每一个输出 b1-b4可以并行化计算。
Self-attention整体过程:

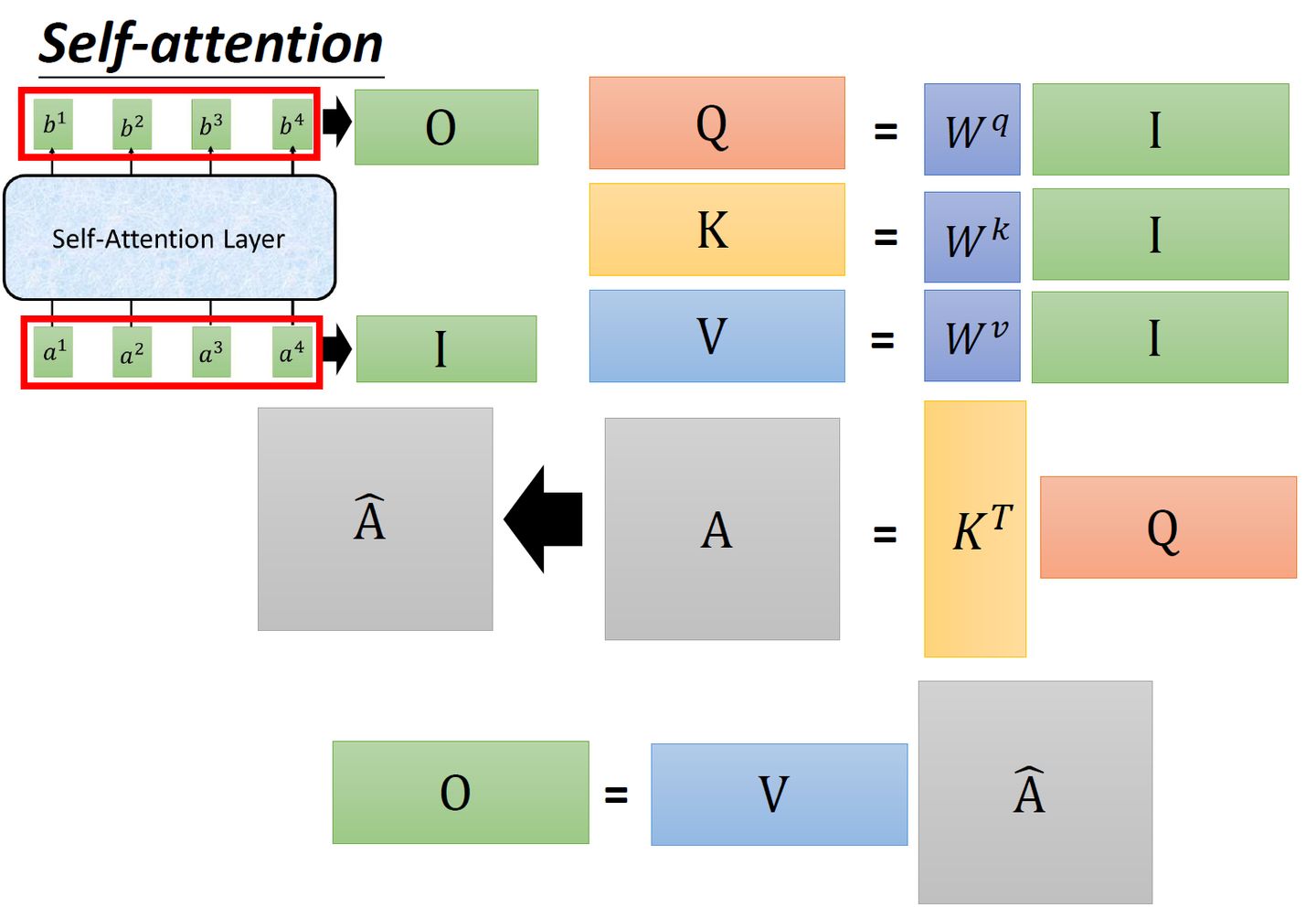
图4:self-attention就是一堆矩阵乘法,可以实现GPU加速
详细的过程:Vision Transformer 超详细解读 (原理分析+代码解读) (一) - 知乎