
Hadoop_HDFS(二):Shell操作之文件的管理(上传下载删除等)
文章目录
基本语法
hadoop fs 具体命令 和hdfs dfs 具体命令,两个是完全相同的。
一、命令查看
查看所有命令,相当于help:
cd bin/
hadoop fs
如下:
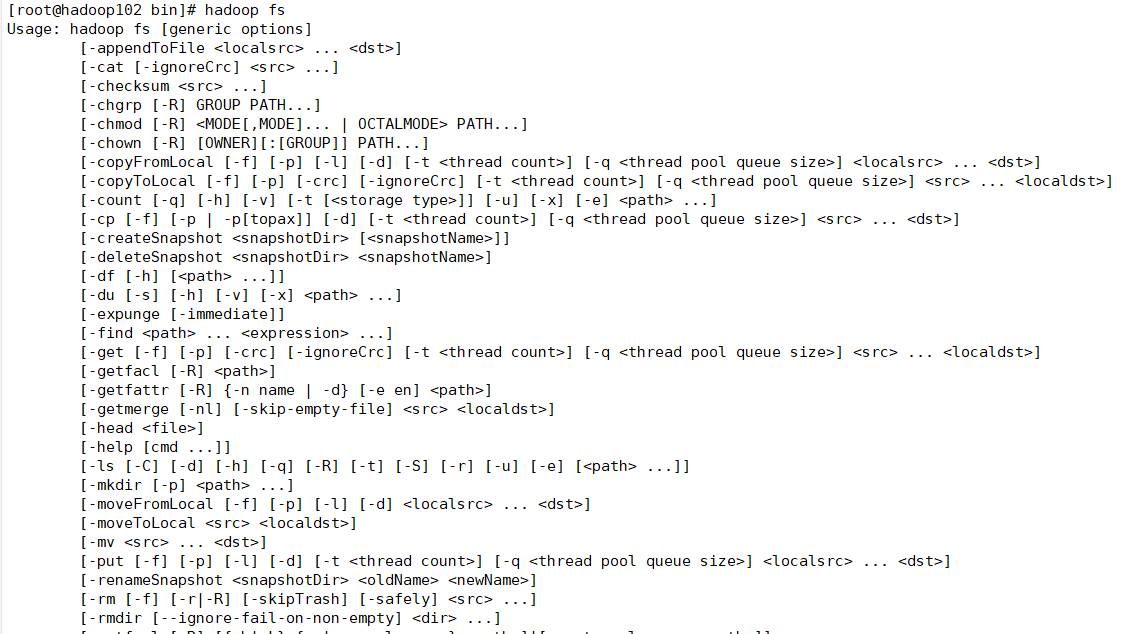
再看下这个命令
hdfs dfs
如下:
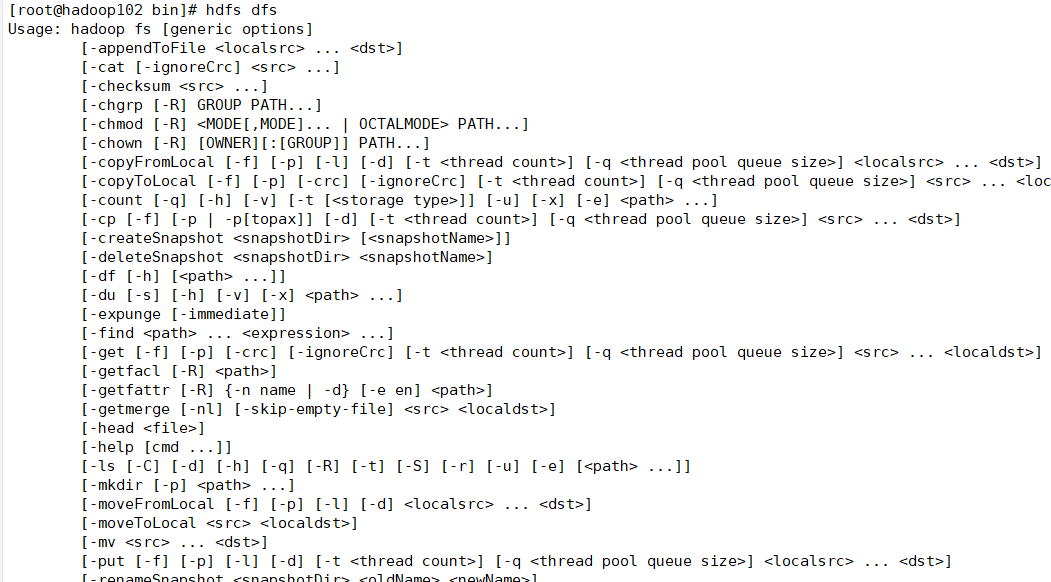
可见一样的。
二、实操
2.1 前提
前提是启动了集群,执行脚本即可:
myhadoop.sh start
也或者分别再102和104执行:
start-dfs.sh
start-yarn.sh
这里不多说,前面已经讲过。大部分命令其实和Linux差不多。
2.2 help查看
查看cat命令语法:
hadoop fs -help cat
如下:

2.3 创建文件夹
这里创建sanguo文件夹:
hadoop fs -mkdir /sanguo
浏览器查看:
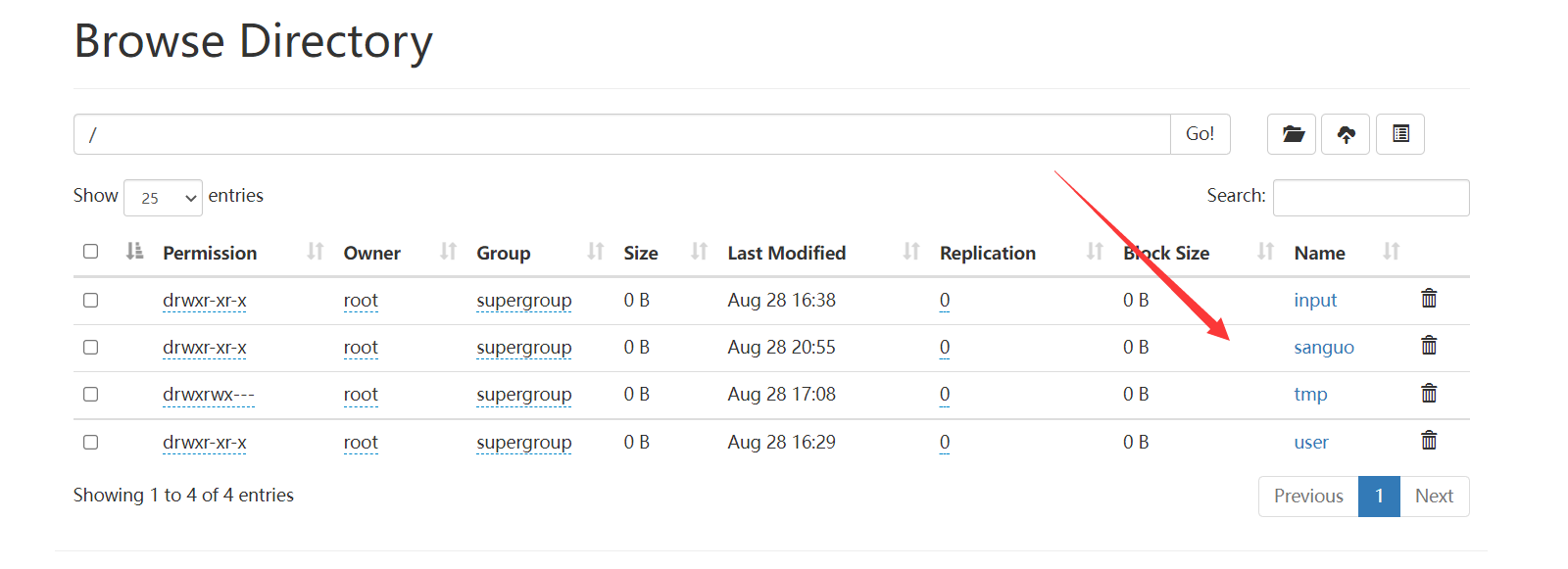
三、上传文件
3.1 moveFromLocal
创建一个文件:
vim shuguo.txt
如下:
演示:

上传(该命令相当于剪切再上传到文件夹):
hadoop fs -moveFromLocal ./shuguo.txt /sanguo
可以看到目录它不存在了(剪切掉了):
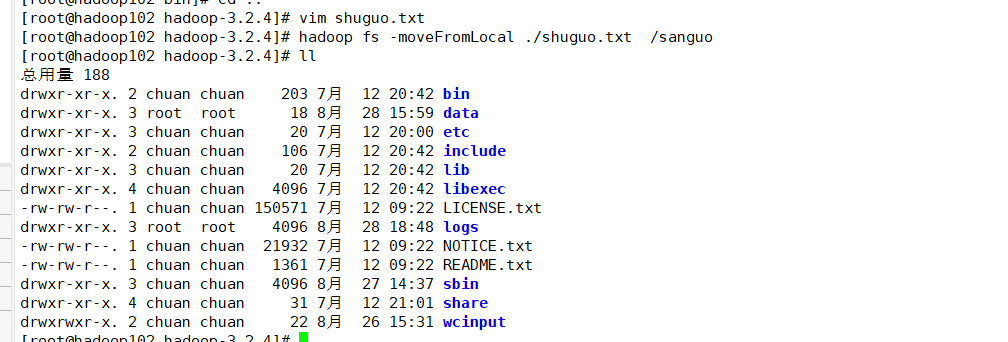
浏览器查看sanguo:
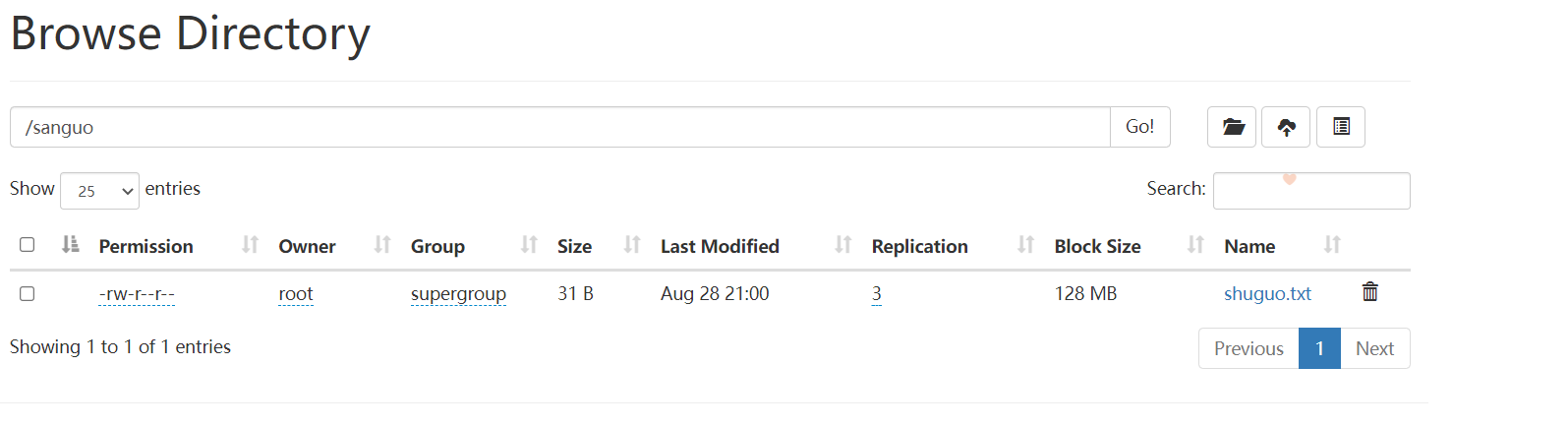
打开:
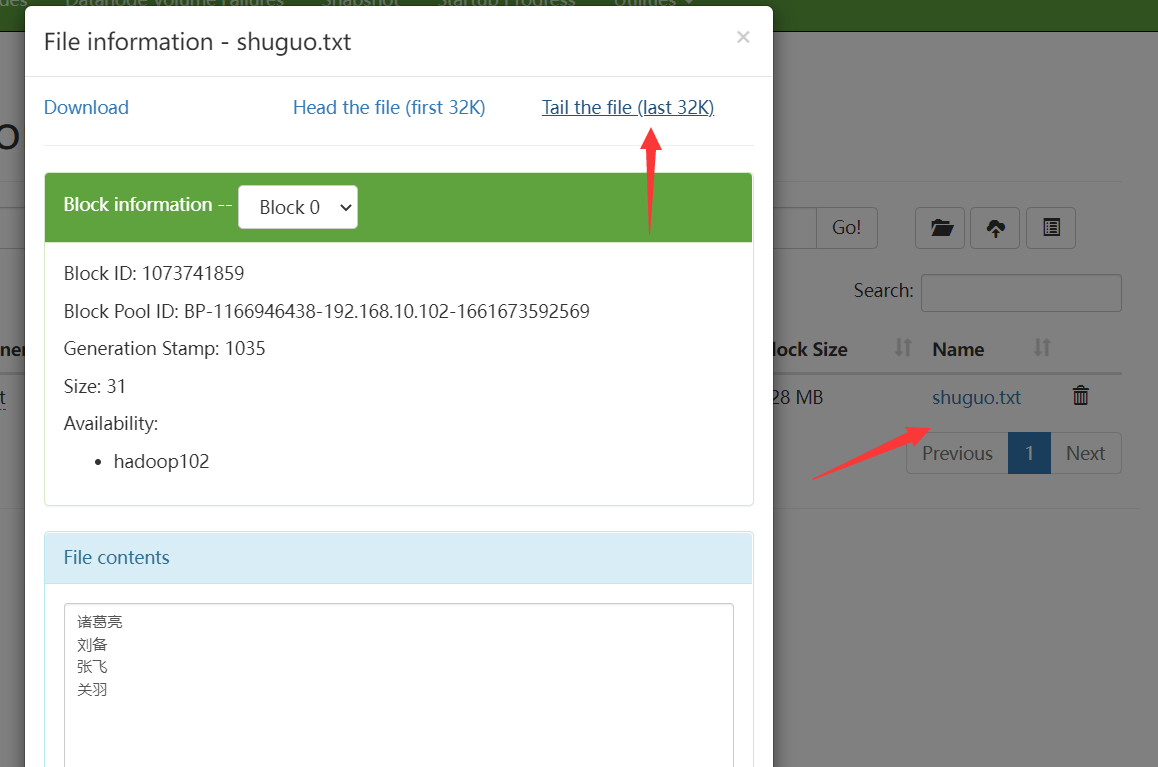
3.2 copyFromLocal
再来介绍另一个命令。先创建一个文件:
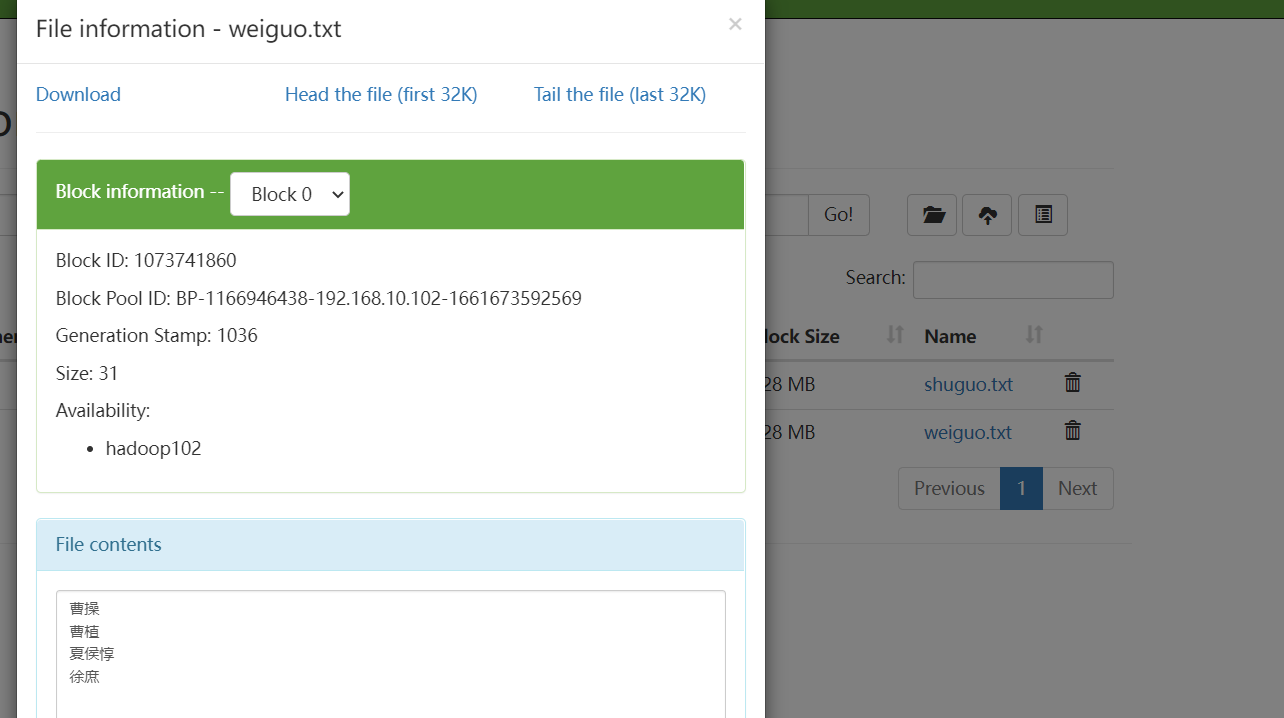
vim weiguo.txt
内容如下:
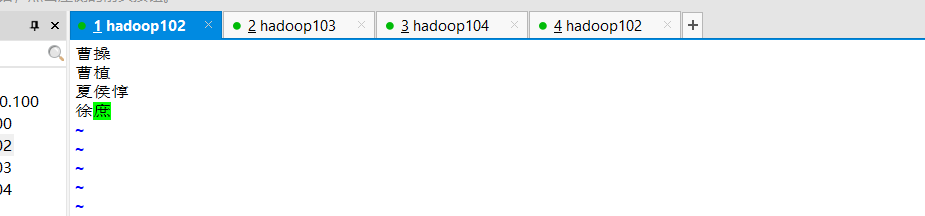
上传:
hadoop fs -copyFromLocal ./weiguo.txt /sanguo
演示如下:

内容打开:
两个命令区别:
- copyFromLocal命令,复制本地的上传到HDFS,不会删除本地
- moveFromLocal命令,剪切(删除)本地上传HDFS,会删除本地
3.3 put
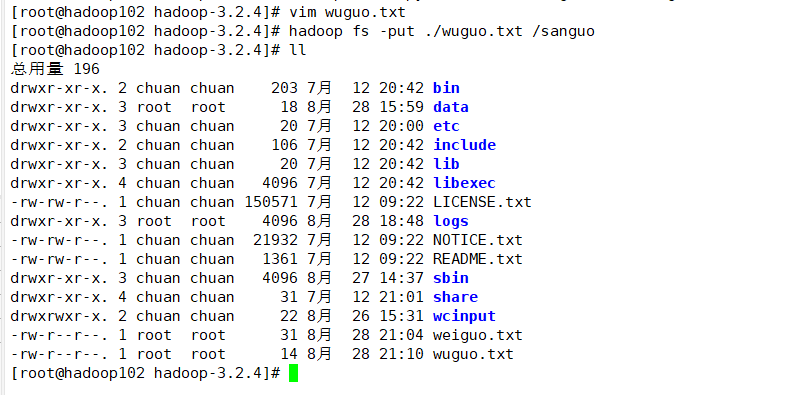
再来介绍put命令,它等同于 copyFromLocal命令,这个跟简约。创建文本:
vim wuguo.txt
内容如下:

上传:
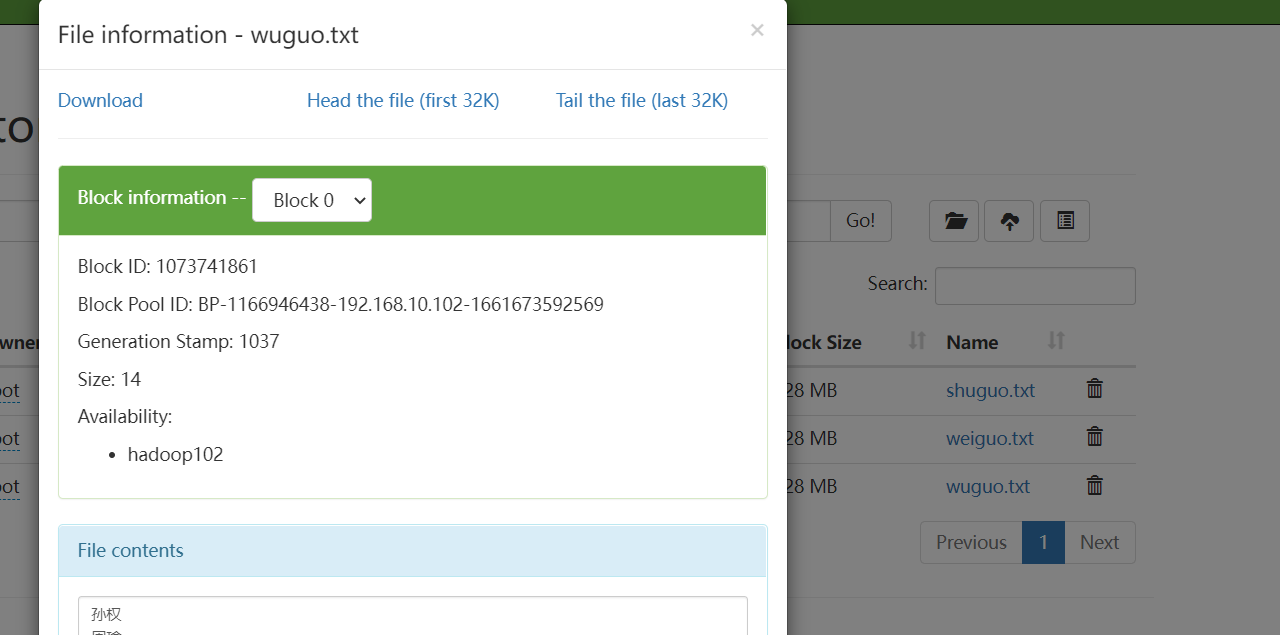
hadoop fs -put ./wuguo.txt /sanguo
演示:
浏览器查看:
3.4 appendToFile
这个命令用于追加内容到文件。创建新的脚本:
vim chuan.txt
内容如下:

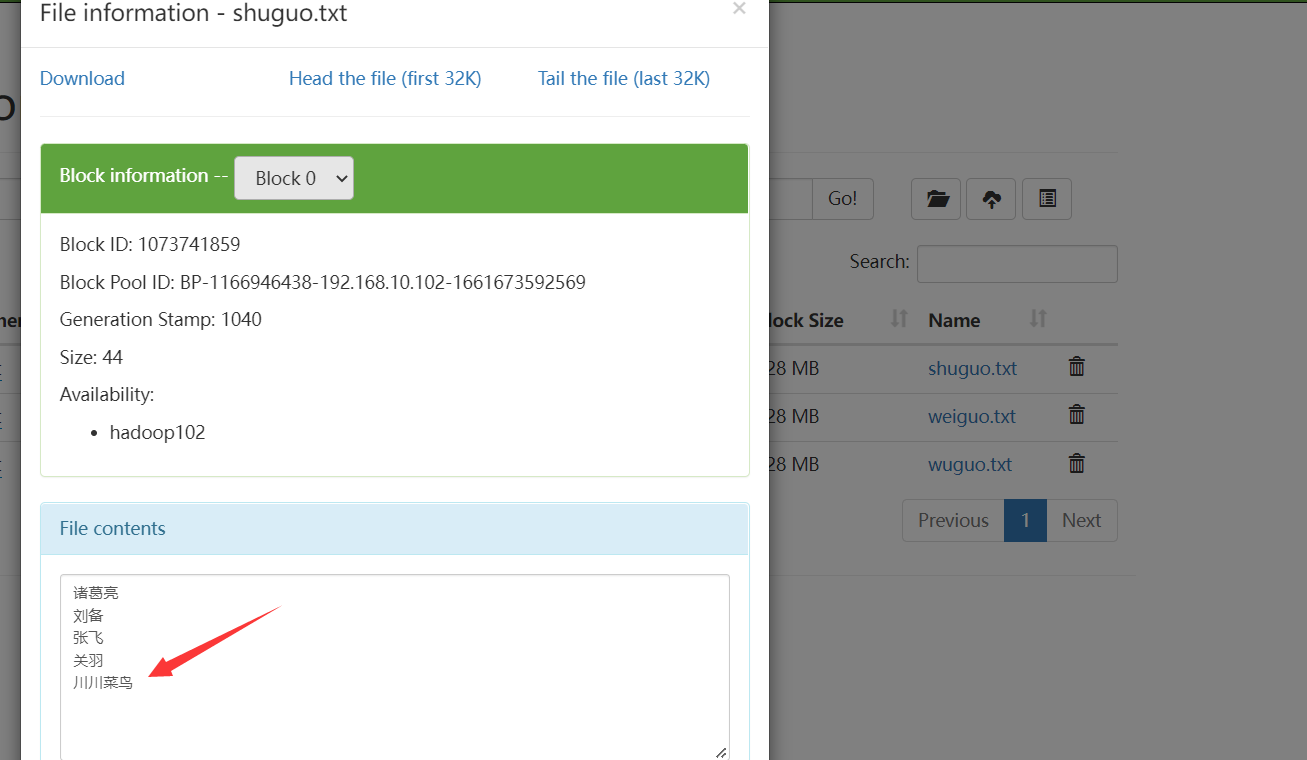
把该文件内容追加到shuguo.txt文件中:
hadoop fs -appendToFile ./chuan.txt /sanguo/shuguo.txt
如果你报错,请看这篇文章:Failed to replace a bad datanode on the existing pipeline due to no more good datanodes being avail
如下:

浏览器查看:
四、下载
4.1 copyToLocal
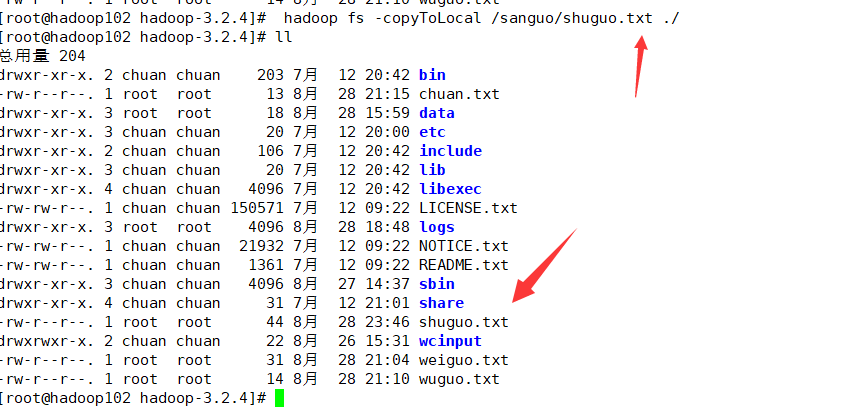
该命令从 HDFS 拷贝到本地。例如把shuguo.txt拷贝到当前文件夹:
hadoop fs -copyToLocal /sanguo/shuguo.txt ./
如下:
4.2 get
该命令与上一个一样,生产环境更常用 get。
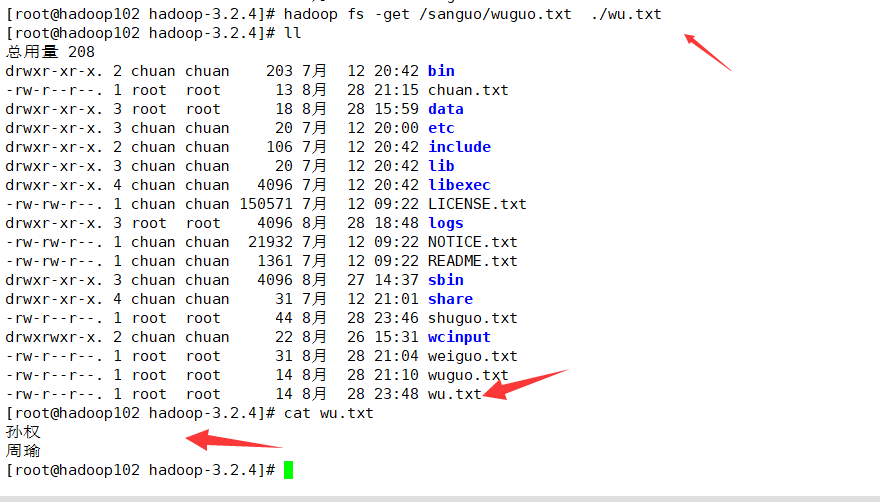
例如下载wuguo.txt到本地并更名为wu.txt:
hadoop fs -get /sanguo/wuguo.txt ./wu.txt
如下:
五、HDFS直接操作
5.1 查看目录
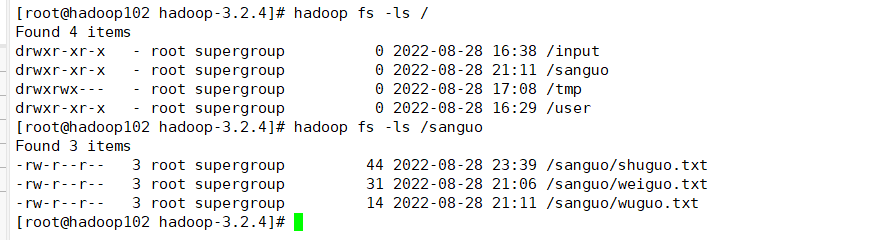
查看根目录:
hadoop fs -ls /
查看目录某个文件夹内容:
hadoop fs -ls /sanguo
如下:
5.2 查看文件内容
用cat:
hadoop fs -cat /sanguo/wuguo.txt
如下:

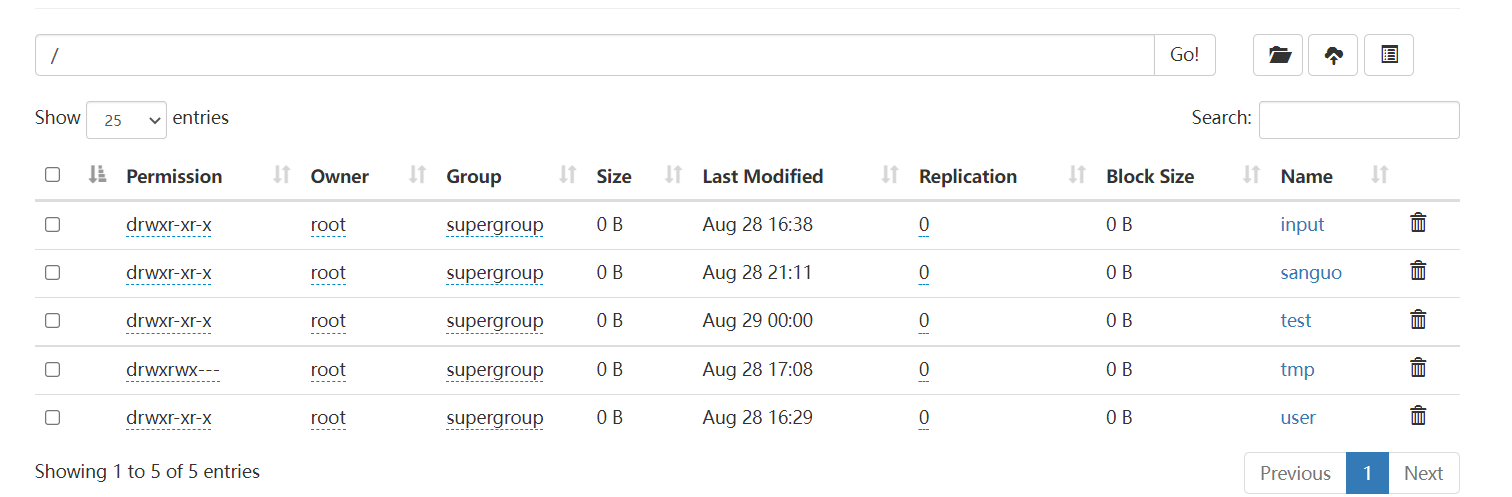
5.3 创建文件夹
hadoop fs -mkdir /test
如下:
5.4 权限管理
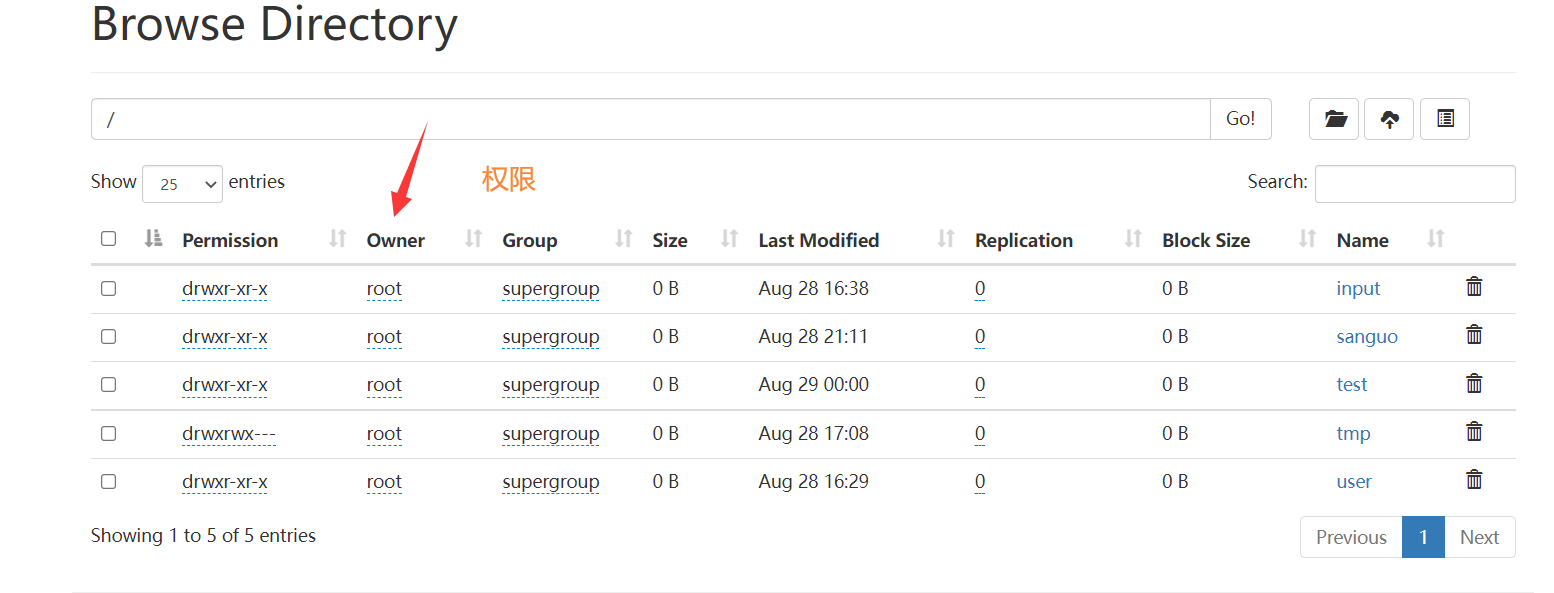
目标:修改sanguo里面文件的权限
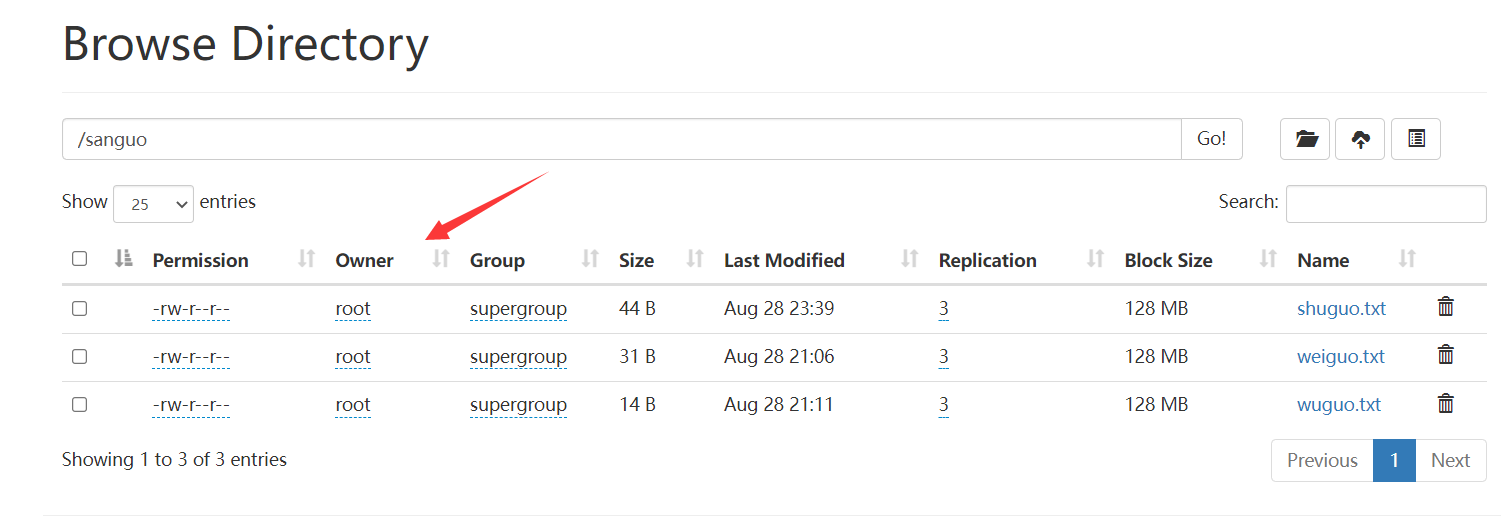
使用chmod方法:修改为只能读
hadoop fs -chmod 444 /sanguo/wuguo.txt
如下:
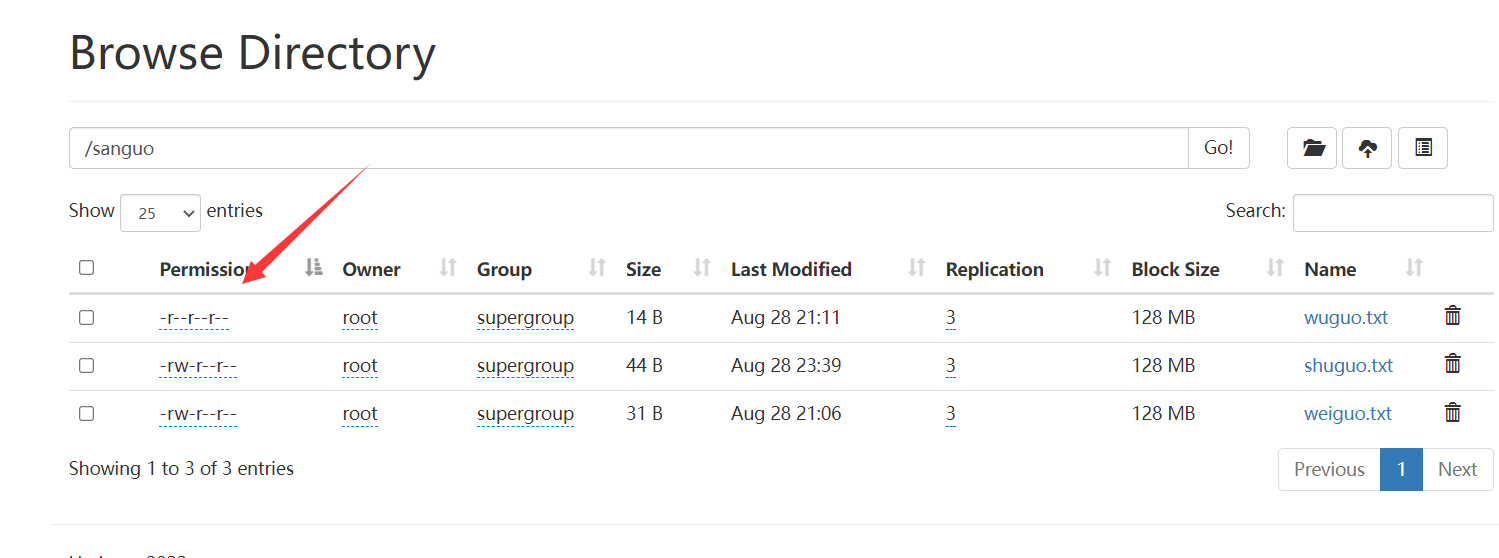
chmod语法:

5.5 移动文件
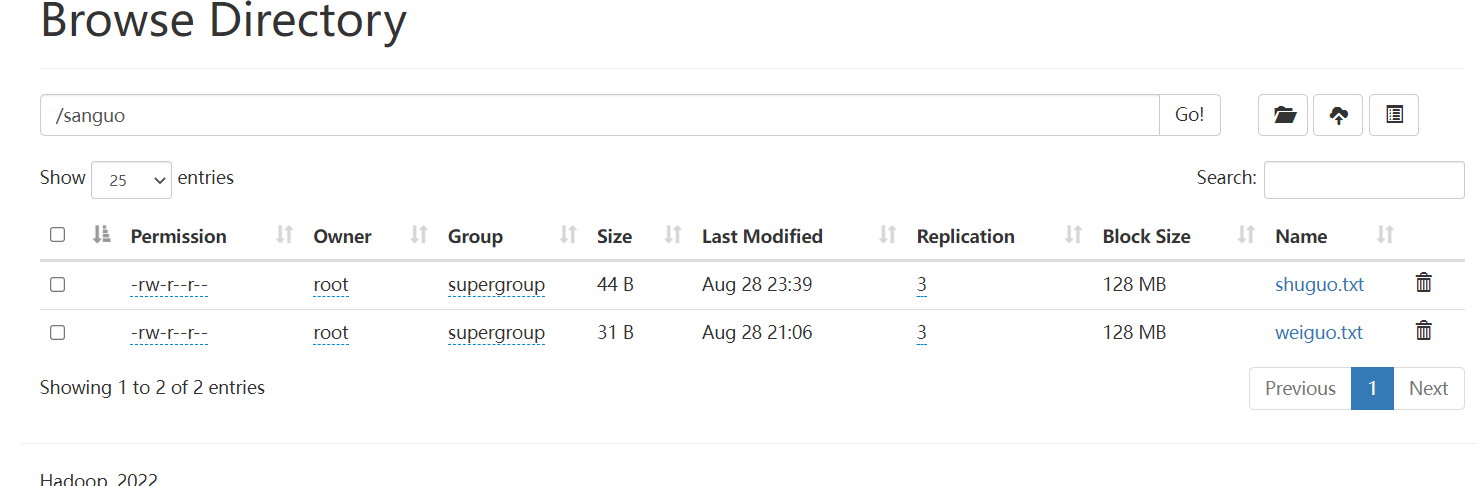
例如:把wuguo.txt移动到test文件夹
hadoop fs -mv /sanguo/wuguo.txt /test
如下:
5.6 删除文件
用rm删除文件或者文件夹。
例如:删除test文件夹下面的wuguo.txt
hadoop fs -rm /test/wuguo.txt
如下:


相关文章
- Java基础入门笔记08——文件流,IO流,FileIputStream类,FileOutputStream类,缓冲流,转换流,标准输入输出流,打印流,数据流,对象流,随机存储流
- Linux文件的特殊权限[SUID&SGID&SBIT]
- 跟着Nature ecology and evolution学python:vcf文件转换成fasta文件
- 如何使用Python对嵌套结构的JSON进行遍历获取链接并下载文件
- Linux文件基本属性与文件查找
- Hadoop综合练习第三节–HDFS读写文件操作详解大数据
- 【Hadoop基础】hadoop fs 命令详解大数据
- reduce hadoop利用MySQL、MapReduce、Hadoop轻松解决大数据问题(mysqlmap)
- Linux快速批量删除文件的方法(linux下批量删除文件)
- split命令_Linux split命令:切割(拆分)文件
- Linux环境下如何导入Jar文件(linux导入jar文件)
- Linux文件管理:修改文件所有者(linux修改文件所有者)
- 快速搭建Hadoop集群:基于Linux的简易配置(linux配置hadoop)
- Linux下创建Hadoop用户指南(linux创建hadoop用户)
- linux下修改文件权限的chmod指令研究(linux 下chmod)
- 删除Linux中只读文件的方法(删除只读文件linux)
- 本地文件无缝传入Redis(本地文件传入redis)
- MySQL下载教程如何获取ZIP文件版本(mysql下载是zip)
- asp下将数据库中的信息存储至XML文件中
- 异步动态加载js与css文件的js代码
- apache中使用.htaccess文件缓存图片的配置方法
- DB2数据库创建、表的ixf文件导出导入示例