
【偷偷卷死小伙伴Pytorch20天】-【day1】-【结构化数据建模流程范例】
系统教程20天拿下Pytorch
最近和中哥、会哥进行一个小打卡活动,20天pytorch,这是第一天。欢迎一键三连。
import os
import datetime
#打印时间
def printbar():
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
#mac系统上pytorch和matplotlib在jupyter中同时跑需要更改环境变量
os.environ["KMP_DUPLICATE_LIB_OK"]="TRUE"
tips:datetime模块显示当前时间并格式化

一、准备数据
泰坦尼克号数据集的目标是根据乘客信息预测他们在泰坦尼克号撞击冰山沉没后能否生存。(需要数据集关注后加博客置顶粉丝群)
结构化数据一般会使用Pandas中的DataFrame进行预处理。
tips:结构化数据说白了就是数据库表,当然csv excel这种都是
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
from torch import nn
from torch.utils.data import Dataset,DataLoader,TensorDataset
dftrain_raw = pd.read_csv('/home/mw/input/data6936/eat_pytorch_data/data/titanic/train.csv')
dftest_raw = pd.read_csv('/home/mw/input/data6936/eat_pytorch_data/data/titanic/test.csv')
dftrain_raw.head(10)

字段说明:
Survived:0代表死亡,1代表存活【y标签】
Pclass:乘客所持票类,有三种值(1,2,3) 【转换成onehot编码】
Name:乘客姓名 【舍去】
Sex:乘客性别 【转换成bool特征】
Age:乘客年龄(有缺失) 【数值特征,添加“年龄是否缺失”作为辅助特征】
SibSp:乘客兄弟姐妹/配偶的个数(整数值) 【数值特征】
Parch:乘客父母/孩子的个数(整数值)【数值特征】
Ticket:票号(字符串)【舍去】
Fare:乘客所持票的价格(浮点数,0-500不等) 【数值特征】
Cabin:乘客所在船舱(有缺失) 【添加“所在船舱是否缺失”作为辅助特征】
Embarked:乘客登船港口:S、C、Q(有缺失)【转换成onehot编码,四维度 S,C,Q,nan】
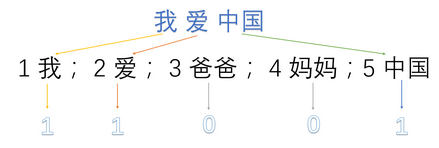
one-hot编码(独热编码):说白了就是将数据映射成相应的二进制
1->001
2->010
3->100
再举个例子
1:我 2:爱 3:爸爸 4:妈妈 5:中国
利用Pandas的数据可视化功能我们可以简单地进行探索性数据分析EDA(Exploratory Data Analysis)。
label分布情况
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Survived'].value_counts().plot(kind = 'bar',
figsize = (12,8),fontsize=15,rot = 0)
ax.set_ylabel('Counts',fontsize = 15)
ax.set_xlabel('Survived',fontsize = 15)
plt.show()

tips:dftrain_raw[‘Survived’].value_counts() 返回的是series数据结构,可以理解为一维字典,不了解这个数据结构的同学可以看Python进阶—Pandas,这里也有一个注意点就是series可以直接通过plot方法画图

年龄分布情况
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw['Age'].plot(kind='hist', bins=20, color='purple',
figsize=(12, 8), fontsize=15)
ax.set_ylabel('Frequency', fontsize=15)
ax.set_xlabel('Age', fontsize=15)
plt.show()

年龄和label的相关性
%matplotlib inline
%config InlineBackend.figure_format = 'png'
ax = dftrain_raw.query('Survived == 0')['Age'].plot(kind = 'density',
figsize = (12,8),fontsize=15)
dftrain_raw.query('Survived == 1')['Age'].plot(kind = 'density',
figsize = (12,8),fontsize=15)
ax.legend(['Survived==0','Survived==1'],fontsize = 12)
ax.set_ylabel('Density',fontsize = 15)
ax.set_xlabel('Age',fontsize = 15)
plt.show()

tips:这里的两条曲线用的是一个figure,所以图例和x标签、y标签给bx和ax设置都一样
dftrain_raw.query(‘Survived == 1’)这里的query相当于过滤条件
下面为正式的数据预处理
def preprocessing(dfdata):
dfresult= pd.DataFrame()
#Pclass
dfPclass = pd.get_dummies(dfdata['Pclass'])
dfPclass.columns = ['Pclass_' +str(x) for x in dfPclass.columns ]
dfresult = pd.concat([dfresult,dfPclass],axis = 1)
#Sex
dfSex = pd.get_dummies(dfdata['Sex'])
dfresult = pd.concat([dfresult,dfSex],axis = 1)
#Age
dfresult['Age'] = dfdata['Age'].fillna(0)
dfresult['Age_null'] = pd.isna(dfdata['Age']).astype('int32')
#SibSp,Parch,Fare
dfresult['SibSp'] = dfdata['SibSp']
dfresult['Parch'] = dfdata['Parch']
dfresult['Fare'] = dfdata['Fare']
#Carbin
dfresult['Cabin_null'] = pd.isna(dfdata['Cabin']).astype('int32')
#Embarked
dfEmbarked = pd.get_dummies(dfdata['Embarked'],dummy_na=True)
dfEmbarked.columns = ['Embarked_' + str(x) for x in dfEmbarked.columns]
dfresult = pd.concat([dfresult,dfEmbarked],axis = 1)
return(dfresult)
x_train = preprocessing(dftrain_raw).values
y_train = dftrain_raw[['Survived']].values
x_test = preprocessing(dftest_raw).values
y_test = dftest_raw[['Survived']].values
print("x_train.shape =", x_train.shape )
print("x_test.shape =", x_test.shape )
print("y_train.shape =", y_train.shape )
print("y_test.shape =", y_test.shape )
'''
输出:
x_train.shape = (712, 15)
x_test.shape = (179, 15)
y_train.shape = (712, 1)
y_test.shape = (179, 1)
'''
tips:
pandas 中的 get_dummies 方法主要用于对类别型特征做 One-Hot 编码(独热编码)。
pd.isna(dfdata[‘Age’]).astype(‘int32’) 查找NaN值并变为1,其余非NaN值变为0
进一步使用DataLoader和TensorDataset封装成可以迭代的数据管道。
dl_train = DataLoader(TensorDataset(torch.tensor(x_train).float(),torch.tensor(y_train).float()),
shuffle = True, batch_size = 8)
dl_valid = DataLoader(TensorDataset(torch.tensor(x_test).float(),torch.tensor(y_test).float()),
shuffle = False, batch_size = 8)
tips

# 测试数据管道
for features,labels in dl_train:
print(features,labels)
break
tensor([[ 0.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000,
0.0000, 7.2292, 1.0000, 1.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 1.0000, 0.0000, 1.0000, 26.0000, 0.0000, 1.0000,
0.0000, 7.8542, 1.0000, 0.0000, 0.0000, 1.0000, 0.0000],
[ 1.0000, 0.0000, 0.0000, 0.0000, 1.0000, 28.0000, 0.0000, 1.0000,
0.0000, 82.1708, 1.0000, 1.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 1.0000, 0.0000, 1.0000, 26.0000, 0.0000, 2.0000,
0.0000, 8.6625, 1.0000, 0.0000, 0.0000, 1.0000, 0.0000],
[ 0.0000, 0.0000, 1.0000, 1.0000, 0.0000, 9.0000, 0.0000, 4.0000,
2.0000, 31.2750, 1.0000, 0.0000, 0.0000, 1.0000, 0.0000],
[ 0.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000,
0.0000, 14.5000, 1.0000, 0.0000, 0.0000, 1.0000, 0.0000],
[ 0.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000, 1.0000, 0.0000,
0.0000, 7.2292, 1.0000, 1.0000, 0.0000, 0.0000, 0.0000],
[ 0.0000, 1.0000, 0.0000, 0.0000, 1.0000, 19.0000, 0.0000, 0.0000,
0.0000, 10.5000, 1.0000, 0.0000, 0.0000, 1.0000, 0.0000]]) tensor([[1.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.],
[0.]])
小总结:

数据处理:第一步要弄明白各个字段是什么意思,分清什么是标签,什么是特征,考虑哪些特征需要保留
- 对于数值型数据保留即可
- 对于类别数据要进行独热编码 pd.get_dummies()
- 对于缺失数据,除了填充意外,还需要增加一列是否是缺失值pd.isna()并转为0/1
补充:pd.get_dummies(dfdata[‘Embarked’],dummy_na=True)
- dummy_na : bool, default False
Add a column to indicate NaNs, if False NaNs are ignored.
x_train = preprocessing(dftrain_raw)
x_train.head()

二、定义模型
使用Pytorch通常有三种方式构建模型:
- 使用nn.Sequential按层顺序构建模型
- 继承nn.Module基类构建自定义模型
- 继承nn.Module基类构建模型并辅助应用模型容器进行封装。
此处选择使用最简单的nn.Sequential,按层顺序模型。
def create_net():
net = nn.Sequential()
net.add_module("linear1",nn.Linear(15,20))
net.add_module("relu1",nn.ReLU())
net.add_module("linear2",nn.Linear(20,15))
net.add_module("relu2",nn.ReLU())
net.add_module("linear3",nn.Linear(15,1))
net.add_module("sigmoid",nn.Sigmoid())
return net
net = create_net()
print(net)
'''
输出:
Sequential(
(linear1): Linear(in_features=15, out_features=20, bias=True)
(relu1): ReLU()
(linear2): Linear(in_features=20, out_features=15, bias=True)
(relu2): ReLU()
(linear3): Linear(in_features=15, out_features=1, bias=True)
(sigmoid): Sigmoid()
)
'''
!pip install torchkeras
!pip install prettytable
!pip install datetime
'''
Torchkeras长见识了
'''
from torchkeras import summary
summary(net,input_shape=(15,))

题外话:这不就是tensorflow的summary函数么
三、训练模型
Pytorch通常需要用户编写自定义训练循环,训练循环的代码风格因人而异。
有3类典型的训练循环代码风格:
- 脚本形式训练循环
- 函数形式训练循环
- 类形式训练循环。
此处介绍一种较通用的脚本形式。
from sklearn.metrics import accuracy_score
loss_func = nn.BCELoss()
optimizer = torch.optim.Adam(params=net.parameters(),lr = 0.01)
metric_func = lambda y_pred,y_true: accuracy_score(y_true.data.numpy(),y_pred.data.numpy()>0.5)
metric_name = "accuracy"
tips:
accuracy_score 分类正确率
>>>import numpy as np
>>>from sklearn.metrics import accuracy_score
>>>y_pred = [0, 2, 1, 3]
>>>y_true = [0, 1, 2, 3]
>>>accuracy_score(y_true, y_pred)
0.5
>>>accuracy_score(y_true, y_pred, normalize=False)
2
epochs = 10
log_step_freq = 30
dfhistory = pd.DataFrame(columns = ["epoch","loss",metric_name,"val_loss","val_"+metric_name])
print("Start Training...")
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("=========="*8 + "%s"%nowtime)
for epoch in range(1,epochs+1):
# 1,训练循环-------------------------------------------------
net.train()
loss_sum = 0.0
metric_sum = 0.0
step = 1
for step, (features,labels) in enumerate(dl_train, 1):
# 梯度清零
optimizer.zero_grad()
# 正向传播求损失
predictions = net(features)
loss = loss_func(predictions,labels)
metric = metric_func(predictions,labels)
# 反向传播求梯度
loss.backward()
optimizer.step()
# 打印batch级别日志
loss_sum += loss.item()
metric_sum += metric.item()
if step%log_step_freq == 0:
print(("[step = %d] loss: %.3f, "+metric_name+": %.3f") %
(step, loss_sum/step, metric_sum/step))
# 2,验证循环-------------------------------------------------
net.eval()
val_loss_sum = 0.0
val_metric_sum = 0.0
val_step = 1
for val_step, (features,labels) in enumerate(dl_valid, 1):
# 关闭梯度计算
with torch.no_grad():
predictions = net(features)
val_loss = loss_func(predictions,labels)
val_metric = metric_func(predictions,labels)
val_loss_sum += val_loss.item()
val_metric_sum += val_metric.item()
# 3,记录日志-------------------------------------------------
info = (epoch, loss_sum/step, metric_sum/step,
val_loss_sum/val_step, val_metric_sum/val_step)
dfhistory.loc[epoch-1] = info
# 打印epoch级别日志
print(("\nEPOCH = %d, loss = %.3f,"+ metric_name + \
" = %.3f, val_loss = %.3f, "+"val_"+ metric_name+" = %.3f")
%info)
nowtime = datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S')
print("\n"+"=========="*8 + "%s"%nowtime)
print('Finished Training...')
'''
输出:
Start Training...
================================================================================2022-02-12 14:58:12
[step = 30] loss: 0.639, accuracy: 0.613
[step = 60] loss: 0.622, accuracy: 0.654
EPOCH = 1, loss = 0.629,accuracy = 0.653, val_loss = 0.551, val_accuracy = 0.714
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.559, accuracy: 0.717
[step = 60] loss: 0.557, accuracy: 0.733
EPOCH = 2, loss = 0.555,accuracy = 0.721, val_loss = 0.531, val_accuracy = 0.734
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.560, accuracy: 0.746
[step = 60] loss: 0.539, accuracy: 0.756
EPOCH = 3, loss = 0.518,accuracy = 0.768, val_loss = 0.429, val_accuracy = 0.783
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.490, accuracy: 0.787
[step = 60] loss: 0.484, accuracy: 0.794
EPOCH = 4, loss = 0.493,accuracy = 0.785, val_loss = 0.513, val_accuracy = 0.741
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.518, accuracy: 0.779
[step = 60] loss: 0.470, accuracy: 0.806
EPOCH = 5, loss = 0.476,accuracy = 0.799, val_loss = 0.460, val_accuracy = 0.799
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.526, accuracy: 0.758
[step = 60] loss: 0.477, accuracy: 0.800
EPOCH = 6, loss = 0.465,accuracy = 0.803, val_loss = 0.482, val_accuracy = 0.793
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.520, accuracy: 0.775
[step = 60] loss: 0.470, accuracy: 0.798
EPOCH = 7, loss = 0.468,accuracy = 0.795, val_loss = 0.469, val_accuracy = 0.772
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.459, accuracy: 0.825
[step = 60] loss: 0.474, accuracy: 0.810
EPOCH = 8, loss = 0.481,accuracy = 0.794, val_loss = 0.452, val_accuracy = 0.783
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.496, accuracy: 0.767
[step = 60] loss: 0.474, accuracy: 0.779
EPOCH = 9, loss = 0.474,accuracy = 0.787, val_loss = 0.443, val_accuracy = 0.793
================================================================================2022-02-12 14:58:13
[step = 30] loss: 0.424, accuracy: 0.838
[step = 60] loss: 0.481, accuracy: 0.804
EPOCH = 10, loss = 0.478,accuracy = 0.787, val_loss = 0.423, val_accuracy = 0.799
================================================================================2022-02-12 14:58:13
Finished Training...
'''
tips:

四、评估模型
我们首先评估一下模型在训练集和验证集上的效果。
dfhistory

%matplotlib inline
%config InlineBackend.figure_format = 'svg'
import matplotlib.pyplot as plt
def plot_metric(dfhistory, metric):
train_metrics = dfhistory[metric]
val_metrics = dfhistory['val_'+metric]
epochs = range(1, len(train_metrics) + 1)
plt.plot(epochs, train_metrics, 'bo--')
plt.plot(epochs, val_metrics, 'ro-')
plt.title('Training and validation '+ metric)
plt.xlabel("Epochs")
plt.ylabel(metric)
plt.legend(["train_"+metric, 'val_'+metric])
plt.show()
plot_metric(dfhistory,"loss")

plot_metric(dfhistory,"accuracy")

五、使用模型
#预测概率
y_pred_probs = net(torch.tensor(x_test[0:10]).float()).data
y_pred_probs
'''
tensor([[0.1430],
[0.6967],
[0.3841],
[0.6717],
[0.6588],
[0.9006],
[0.2218],
[0.8791],
[0.5890],
[0.1544]])
'''
```python
#预测类别
y_pred = torch.where(y_pred_probs>0.5,
torch.ones_like(y_pred_probs),torch.zeros_like(y_pred_probs))
y_pred
'''
tensor([[0.],
[1.],
[0.],
[1.],
[1.],
[1.],
[0.],
[1.],
[1.],
[0.]])
'''

**tips:**
```python
torch.tensor(1).numpy() # array(1)
torch.tensor(1).data # tensor(1)
torch.tensor(1).item() # 1 仅仅对标量使用
torch.tensor(1).float() # 转成浮点型 tensor(1.)
torch.tensor(1).int() # 转成int32 tensor(1, dtype=torch.int32)
六、保存模型
Pytorch 有两种保存模型的方式,都是通过调用pickle序列化方法实现的。
-
第一种方法只保存模型参数。
-
第二种方法保存完整模型。
推荐使用第一种,第二种方法可能在切换设备和目录的时候出现各种问题。
1,保存模型参数(推荐)
print(net.state_dict().keys())
'''
odict_keys(['linear1.weight', 'linear1.bias', 'linear2.weight', 'linear2.bias', 'linear3.weight', 'linear3.bias'])
'''
# 保存模型参数
torch.save(net.state_dict(), "./data/net_parameter.pkl")
net_clone = create_net()
net_clone.load_state_dict(torch.load("./data/net_parameter.pkl"))
net_clone.forward(torch.tensor(x_test[0:10]).float()).data
'''
tensor([[0.1327],
[0.8162],
[0.4354],
[0.5858],
[0.6404],
[0.9614],
[0.1819],
[0.8931],
[0.5858],
[0.2205]])
'''
2,保存完整模型(不推荐)
torch.save(net, './data/net_model.pkl')
net_loaded = torch.load('./data/net_model.pkl')
net_loaded(torch.tensor(x_test[0:10]).float()).data
'''
tensor([[0.0119],
[0.6029],
[0.2970],
[0.5717],
[0.5034],
[0.8655],
[0.0572],
[0.9182],
[0.5038],
[0.1739]])
'''
相关文章
- 通过ViewController的关键流程来理解流程建模
- activiti自定义流程之Spring整合activiti-modeler5.16实例(四):部署流程定义
- html内联元素,伪类选择器,字体设置 表单,做网页流程
- anydesk安装流程
- mybatis架构流程
- Atitit 定时器timer 总结 目录 1. 定时器 循环定时器 和timeout超时定时器1 2. Spring定时器1 2.1. 大概流程1 2.2. 核心源码springboot1
- atitit.抽奖活动插件组件设计--结构设计and 抽奖流程建模
- Algorithm:数学建模大赛(国赛和美赛)的简介/内容、数学建模做题流程、历年题目类型及思想、常用算法、常用工具之详细攻略
- 【经验分享】数学建模团队准备解决方案流程策略分享
- 【高并发】通过源码深度分析线程池中Worker线程的执行流程
- 一篇文章讲清楚芯片设计全流程及相关岗位划分
- 京东通天塔是什么?优势功能流程介绍
- 阿里云证书资源包申请免费SSL流程(图文教程)
- servlet处理用户请求的完整流程
- 电力系统| IEEE论文投稿流程
- 【偷偷卷死小伙伴Pytorch20天】-【day3】-【文本数据建模流程范例】
- 基于深度学习的三维重建网络PatchMatchNet(三):PatchMatchNet配置及代码主要运行流程
- Android高性能音频之OpenSL ES录音流程(一)