
【ML on Kubernetes】第 6 章:机器学习工程
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在本章中,我们将讨论机器学习( ML ) 工程生命周期的模型构建和模型管理活动。您将了解 ML 平台在为数据科学家提供自助解决方案方面的作用,以便他们能够更有效地工作并与数据团队和数据科学家同行协作。
本章的重点不是建立模型;而是建立模型。相反,它展示了该平台如何在不同环境和团队的不同成员之间带来一致性和安全性。您将了解该平台如何在准备和维护数据科学工作空间方面简化数据科学家的工作。
在本章中,您将了解以下主题:
- 了解机器学习工程?
- 使用自定义笔记本图像
- 介绍 MLflow
- 使用 MLflow 作为实验跟踪系统
- 使用 MLflow 作为模型注册系统
技术要求
本章包括一些动手设置和练习。您将需要一个使用Operator Lifecycle Manager ( OLM )配置的正在运行的 Kubernetes 集群。第 3 章“探索 Kubernetes”中介绍了构建这样的 Kubernetes 环境。在尝试本章中的技术练习之前,请确保您有一个正常工作的 Kubernetes 集群,并且在您的 Kubernetes 集群上安装了开放数据中心( ODH )。第 4 章“机器学习平台剖析”中介绍了 ODH 的安装。您可以在以下位置找到与本书相关的所有代码https://github.com/PacktPublishing/Machine-Learning-on-Kubernetes.
了解机器学习工程
机器学习工程是过程将软件工程原理和实践应用于 ML 项目。在本书的上下文中,ML 工程也是一门有助于将应用程序开发实践应用于数据科学生命周期的学科。当您编写网站或银行系统等传统应用程序时,有一些流程和工具可以帮助您从一开始就编写高质量的代码。智能 IDE、标准环境、持续集成、自动化测试和静态代码分析只是其中的几个例子。自动化和持续部署实践使组织能够在一天内多次部署应用程序而无需停机。
ML 工程是一个松散的术语,它将传统软件工程实践的好处带入模型开发领域。然而,大多数数据科学家不是开发人员。他们可能不熟悉软件工程实践。此外,数据科学家使用的工具可能不是执行 ML 工程任务的正确工具。话虽如此,该模型只是另一个软件。因此,我们也可以将现有的软件工程方法应用于 ML 模型。使用容器来打包和部署 ML 模型就是这样一个例子。
一些团队可能会聘请 ML 工程师来补充数据科学家的工作。虽然数据科学家的主要职责是构建解决业务问题的 ML 或深度学习模型,但 ML 工程师更关注软件工程方面。某些数据工程师的职责包括:
- 模型优化(也关于确保构建的模型针对将托管模型的目标环境进行优化)。
- 模型打包(使 ML 模型可移植、可交付、可执行和受版本控制)。模型打包还可能包括模型服务和容器化。
- 监控(建立用于收集性能指标、日志记录、警报和异常检测(如漂移和异常值检测)的基础设施)。
- 模型测试(包括 A/B 测试的便利化和自动化)。
- 模型部署。
- 构建和维护 MLOps 基础设施。
- 为 ML 模型实施持续集成和持续部署管道。
- 机器学习生命周期流程的自动化。
前面的列表中没有列出 ML 工程师的其他职责,但是这个列表应该已经让您了解如何区分数据科学和 ML 工程。
ML 平台您正在构建的项目将减少手动完成的 ML 工程任务的数量,即使是数据科学家也可以自己完成大部分 ML 工程任务。
在接下来的部分中,您将看到数据科学家如何跟踪模型开发迭代以提高模型质量并与团队分享学习成果。您将看到团队如何将版本控制应用到 ML 模型和其他软件工程实践到 ML 世界。
我们将在下一章继续我们的 ML 工程之旅,在那里您将看到如何以标准方式打包和部署模型,并了解如何自动化部署过程。
让我们从为我们的数据科学团队构建标准开发环境开始。
使用自定义笔记本图像
正如您在第 5 章,数据工程中所见,JupyterHub 允许您启动基于 Jupyter Notebook 的开发以自助服务的方式提供环境。您已启动Base Elyra Notebook Image容器映像并使用它来使用 Apache Spark 编写数据处理代码。这种方法使您的团队能够使用一致或标准化的开发环境(例如,相同的 Python 版本和相同的库来构建代码)并将安全策略应用于您的团队正在使用的已知软件集。但是,您可能还想使用一组不同的库或不同的 ML 框架创建自己的自定义图像。该平台允许您这样做。
在以下小节中,您将构建和部署要在您的团队中使用的自定义容器映像。
构建自定义笔记本容器映像
假设您的团队想要使用特定版本的 Scikit 库以及其他一些支持库,例如joblib。然后,您希望您的团队在开发他们的数据科学代码时使用这个库:
1.打开本书代码库中提供的Dockerfile ,位于chapter6/CustomNotebookDockerfile。此文件使用 ODH 提供和使用的基本映像,然后添加所需的库。文件如图 6.1所示:
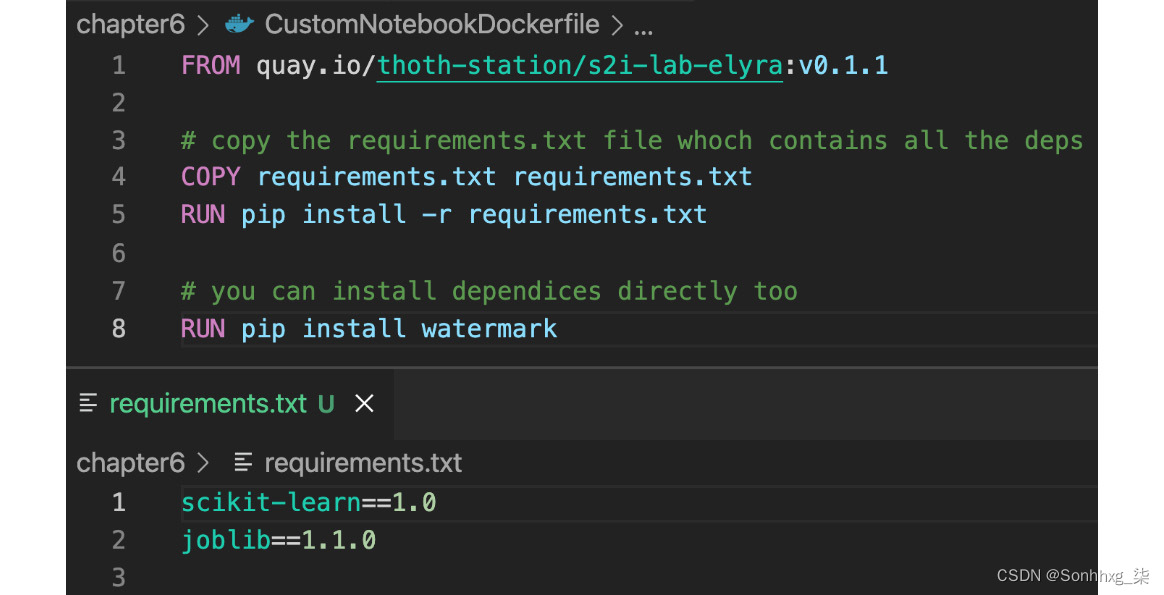
图 6.1 – 自定义笔记本镜像的 Dockerfile
请注意第一行,它指的是撰写本文时的最新图像。此图像由 ODH 使用。第 4 行和第 5 行安装在requirements.txt文件中定义的 Python 包。第 8 行安装不在requirements.txt文件中的依赖项。如果您希望向图像添加其他包,只需在requirements.txt中插入一行即可。
2.使用上一步中提供的文件构建映像。运行以下命令:
docker build -t scikit-notebook:v1.1.0 -f chapter6/CustomNotebookDockerfile ./chapter6/。您应该看到以下响应:

图 6.2 – 容器构建命令的输出
3.根据您的喜好标记构建的图像。您需要将此映像推送到 Kubernetes 集群可以访问它的注册表。我们使用quay.io作为首选的公共 Docker 存储库,您可以在此处使用您的首选存储库。注意在执行命令之前,您需要调整以下命令并更改quay.io/ml-on-k8s/部分:
docker tag scikit-notebook:v1.1.0 quay.io/ml-on-k8s/scikit-notebook:v1.1.0没有上述命令的输出。
4.将映像推送到您选择的 Docker 存储库。使用以下命令并确保按照步骤 3更改存储库位置。根据您的连接速度,此图像可能需要一些时间才能推送到 Internet 存储库。要有耐心:
docker push quay.io/ml-on-k8s/scikit-notebook:v1.1.0您应该会看到该命令的输出,如图 6.3所示。等待推送完成。
图 6.3 – 将自定义笔记本镜像推送到 Docker 存储库
现在,图像可用要使用的。您将在接下来的步骤中配置 ODH 清单以使用此映像。
5.打开manifests/jupyterhub-images/base/customnotebook-imagestream.yaml文件。该文件如下所示:

图 6.4 – ImageStream 对象
ODH 的 JupyterHub 使用一个名为Imagestream的 CRD 。这是 Red Hat OpenShift 上的本机对象,但在标准 Kubernetes 中不可用。我们创建了这个对象作为ODH 清单中的自定义资源,以便它可以与上游 Kubernetes 集成。您可以在manifests/odh-common/base/imagestream-crd.yaml找到这些资源。
注意第 7 行和第 8 行,我们定义了一些注释。JupyterHub读取所有图像流对象并使用这些注释显示在 JupyterHub 登录页面上。JupyterHub 还会查看名为dockerImageReference的字段,以根据请求加载这些容器图像。
我们鼓励您将本书的代码库 fork 到您自己的 Git 帐户并添加更多图像。请记住在manifests/kfdef/ml-platform.yaml文件中更改 Git 存储库的位置。
6.要让 JupyterHub 服务器看到新创建的映像,您需要重新启动 JupyterHub pod。您可以通过以下命令找到该 pod 并删除该 pod。几秒钟后,Kubernetes 将重新启动此 pod,您的新图像将出现在 JupyterHub 登录页面上:
kubectl get pods -n ml-workshop | grep jupyterhub您应该看到以下响应。请注意,您的设置的 pod 名称会有所不同:

图 6.5 – 名称包含 jupyterhub 的 Pod
7.通过运行以下命令删除 JupyterHub pod。请注意,您不需要在本练习中删除此 pod,因为自定义图像已经存在在我们的清单文件中。使用本节中提到的步骤添加新的客户笔记本图像后,将需要此步骤:
kubectl delete pod jupyterhub-7848ccd4b7-thnmm -n ml-workshop您应该看到以下响应。请注意,您的设置的 pod 名称会有所不同:
6.6 – delete pod 命令的输出
8.登录 JupyterHub,您将看到新的笔记本图像在此处列出:
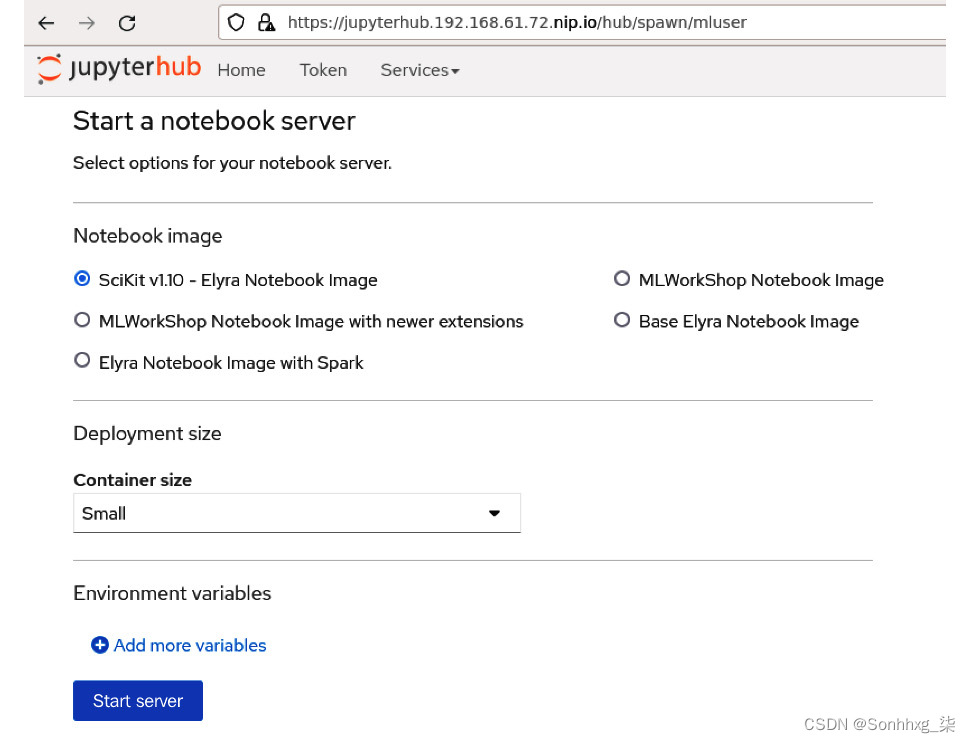
图 6.7 – 显示新笔记本图像的 JupyterHub 登录页面
在下一节中,您将了解 MLflow,该软件可帮助团队记录和共享模型训练和调优实验的结果。
介绍 MLflow
简单地说,MLflow 就在那里简化模型开发生命周期。数据科学家的大量时间都花在为给定的数据集寻找具有正确超参数的正确算法上。作为一名数据科学家,您会尝试不同的参数和算法组合,然后查看和比较结果以做出正确的选择。MLflow 允许您记录、跟踪和比较这些参数、它们的结果以及相关的指标。捕获每个实验细节的 MLflow 组件称为跟踪服务器。跟踪服务器捕获笔记本的环境详细信息,例如 Python 库及其版本,以及您的实验生成的工件。
跟踪服务器允许您比较在不同实验运行之间捕获的数据,例如性能指标(例如准确性)以及使用的超参数。您还可以与您的团队共享此数据以进行协作。
MLflow 跟踪服务器的第二个关键功能是模型注册表。考虑到你已经运行了十个不同的给定数据集的实验,而每个实验都会产生一个模型。只有一个模型将用于给定的问题。模型注册表允许您使用三个阶段(Staging、Production和Archived)之一标记所选模型。模型注册表具有允许您从自动化作业访问这些模型的 API。如果需要,注册表中的模型版本控制将使您能够使用生产中的自动化工具回滚到模型的先前版本。
图 6.8展示了 MLflow 软件的两大功能:

图 6.8 – MLflow 主要功能
既然您知道了 MLFlow 的用途,那么让我们来看看构成 MLFlow 的组件。
了解 MLflow 组件
让我们看看主要是什么MLflow 系统的组件是什么,以及它如何融入我们的 ML 平台的生态系统。
MLflow 服务器
MLflow 被部署为一个容器,它包含一个后端服务器、一个 GUI 和一个与之交互的 API。在后面的部分在本章中,您将使用MLflow API 将实验数据存储到其中。您将使用 GUI 组件来可视化实验跟踪和模型注册部分。您可以在manifests/mlflow/base/mlflow-dc.yaml找到此配置。
MLflow 后端存储
MLflow 服务器需要一个后端store 存储有关实验的元数据。ODH 组件自动将 PostgreSQL 数据库配置为用作 MLflow 的后端存储。您可以在manifests/mlflow/base/mlflow-postgres-statefulset.yaml找到此配置。
MLflow 存储
MLflow 服务器支持几种类型的存储,例如 S3 和数据库。此存储将用作工件(例如文件)的持久存储和模型文件。在我们的平台中,您将配置一个开源 S3 兼容存储称为Minio的服务。Minio 将为平台提供 S3 API 功能;但是,您的组织可能已经有一个企业范围的 S3 解决方案,如果有的话,我们建议使用现有的解决方案。您可以在manifests/minio/base/minio-dc.yaml找到此配置。
MLflow 身份验证
MLflow 没有在撰写本文时,开箱即用的身份验证系统。在我们的平台,我们在 MLflow GUI 前面配置了一个代理服务器,它将在将请求转发到 MLflow 服务器之前对请求进行身份验证。为此,我们正在使用GitHub - oauth2-proxy/oauth2-proxy: A reverse proxy that provides authentication with Google, Azure, OpenID Connect and many more identity providers.上的开源组件。代理已经配置为使用平台的Keycloak服务执行单点登录( SSO ) 。
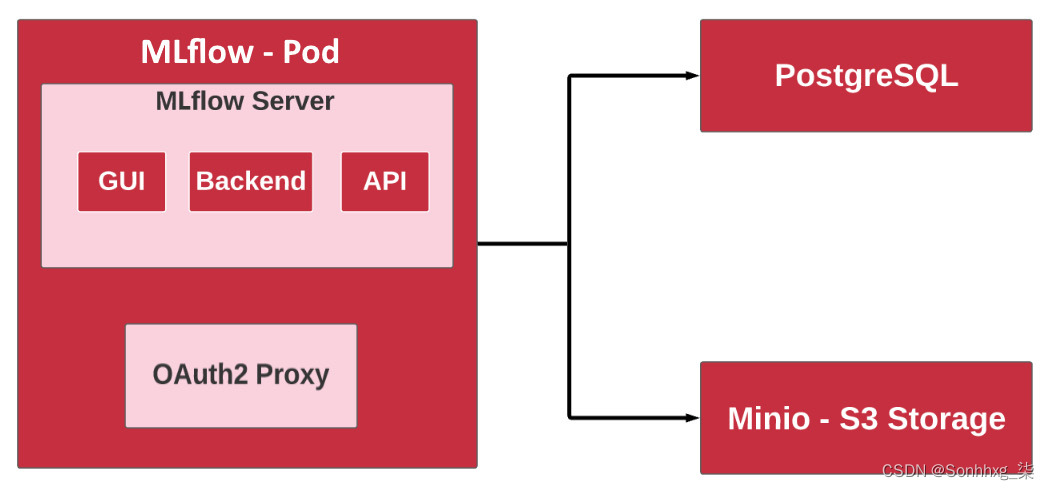
图 6.9 – MLflow 和平台中的相关组件
如图6.9 所示,MLflow pod 中有两个容器:MLflow 服务器和 OAuth2 代理。Oauth2 代理已配置为使用您的 Keycloak 实例安装。
当你创建了一个第 5 章数据工程中的 ODH 的新实例,它安装了许多平台组件,包括 MLflow 和 Minio。现在,让我们验证 MLflow 安装。
验证 MLflow 安装
ODH 已经安装了MLflow 和相关组件为您服务。现在,您将使用 MLflow GUI 来熟悉该工具。您可以想象所有团队成员都可以访问实验和模型,这将改善您团队的协作:
1.使用以下命令获取在 Kubernetes 环境中创建的入口对象。这是为了获取部署我们服务的端点的 URL:
kubectl get ingress -n ml-workshop您应该看到以下响应:

图 6.10 – 集群命名空间中的所有入口对象
2.打开 Minio GUI,我们的 S3 组件,并验证是否有一个存储桶可供 MLflow 用作它的存储。Minio 组件的 URL 将类似于https://minio.192.168.61.72.nip.io,您将在其中根据您的环境调整 IP 地址。密码在 manifests 文件中配置,它是minio123。我们在清单中添加了 Minio,以表明可以使用开源技术进行选择,但使其适用于生产环境超出了本书的范围。单击屏幕左侧的存储桶菜单项,您将看到可用的存储桶:

图 6.11 – Minio 存储桶列表
所有这些存储桶是如何创建的?在清单中,我们有一个创建存储桶的 Kubernetes 作业。你可以在manifests/minio/base/minio-job.yaml找到这份工作。该作业使用 Minio 命令行客户端mc来创建桶。您可以在此文件的命令字段名称下找到这些命令。
MLflow 使用的 S3 配置在manifests/mlflow/base/mlflow-dc.yaml 文件中配置。
您可以看到如下设置:
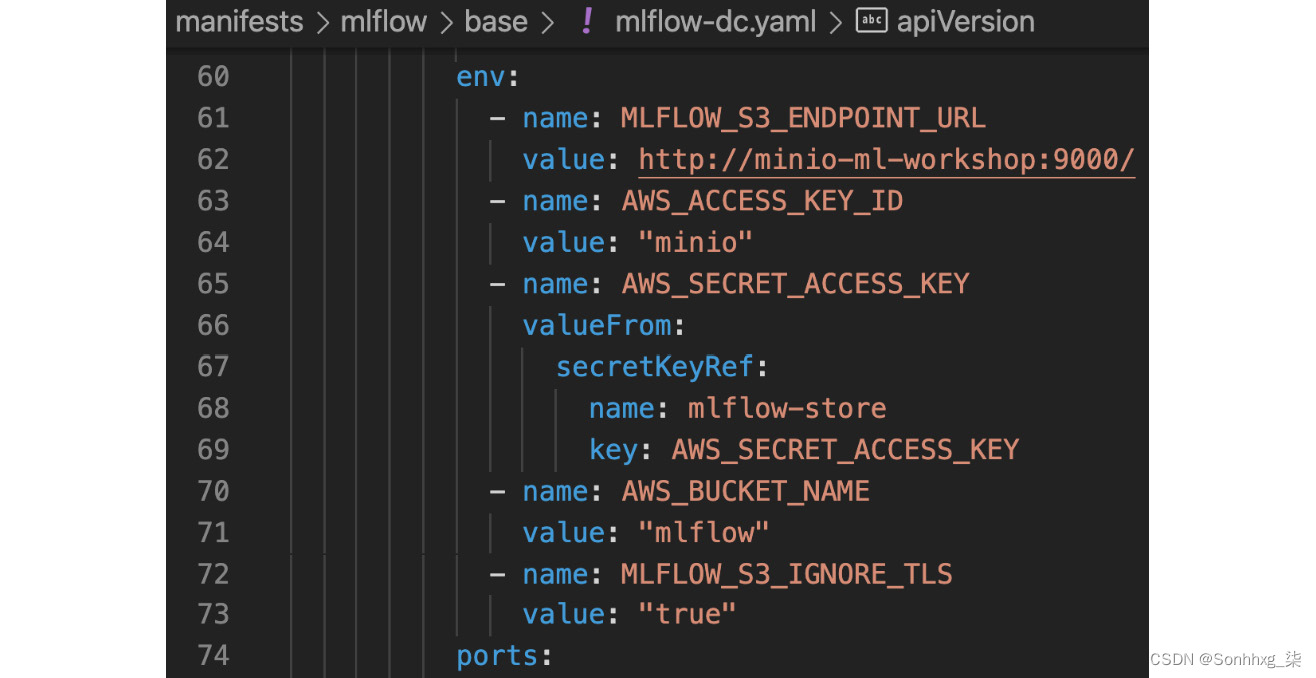
图 6.12 – 使用 Minio 的 MLflow 配置
3.打开浏览器并将jupyterhub入口的HOSTS值粘贴到浏览器中。对我来说,它是https://mlflow.192.168.61.72.nip.io。该 URL 将带您进入 Keycloak 登录页面,即 SSO 服务器,如下图所示。确保在此 URL 中将 IP 地址替换为您的 IP 地址。回想一下,MLflow 的身份验证部分由您在manifests/mlflow/base/mlflow-dc.yaml中配置的代理管理。
4.您可以看到 MLflow 的 OAuth 代理的配置如下。因为oauth-proxy和 MLflow 属于同一个 pod,我们所做的只是将流量从oauth-proxy 路由到 MLflow 容器。这是使用–upstream属性设置的。还可以看到oauth-proxy需要身份提供者服务器的名称,也就是 Keycloak,它是在--oidc-issuer属性下配置的:
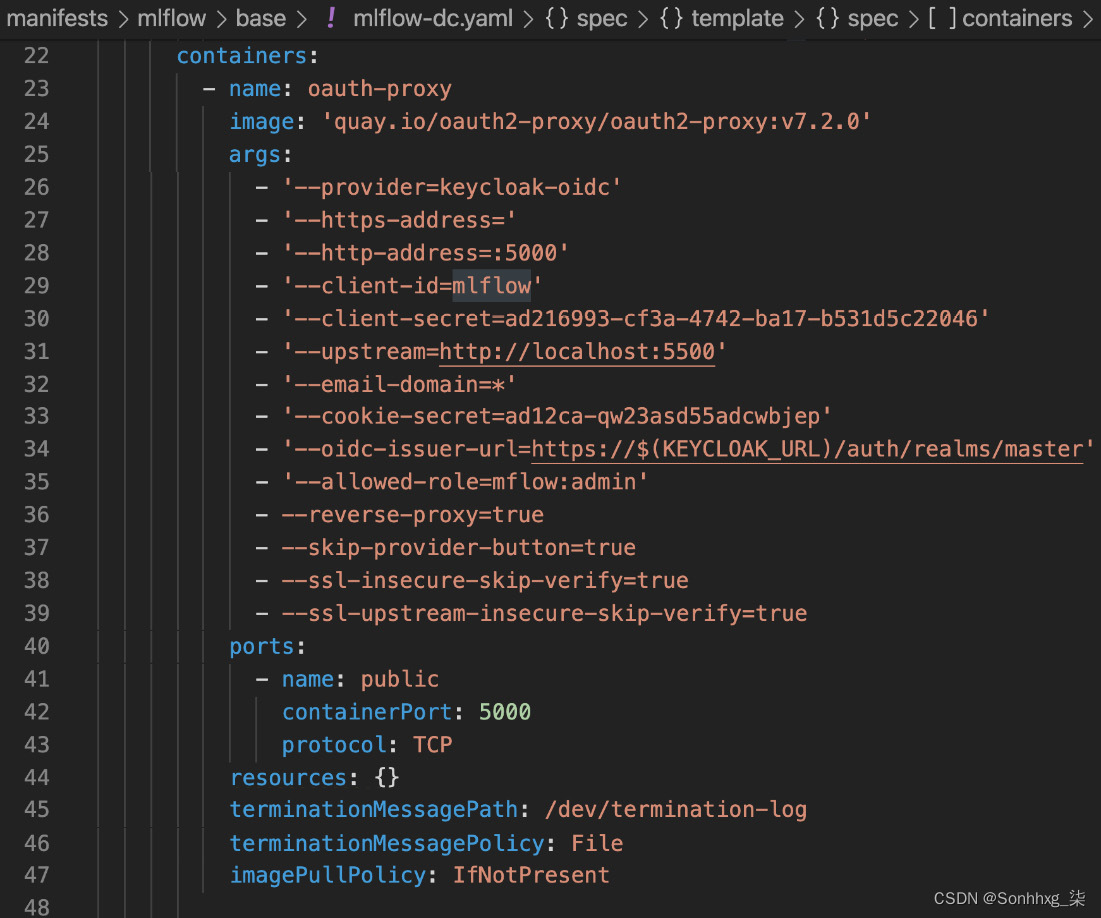
图 6.13 – MLflow 的 OAuth 代理配置
MLflow 的登录页面类似于图 6.14中的页面。您会注意到顶部栏菜单上有两个部分。一个标签为Experiments,另一个标签为Models。
5.在您看到此页面之前,SSO配置将显示登录页面。输入用户 ID 为mluser,密码输入为mluser登录。用户名和密码在第 4 章,机器学习平台剖析,在创建 Keycloak 用户部分中配置。
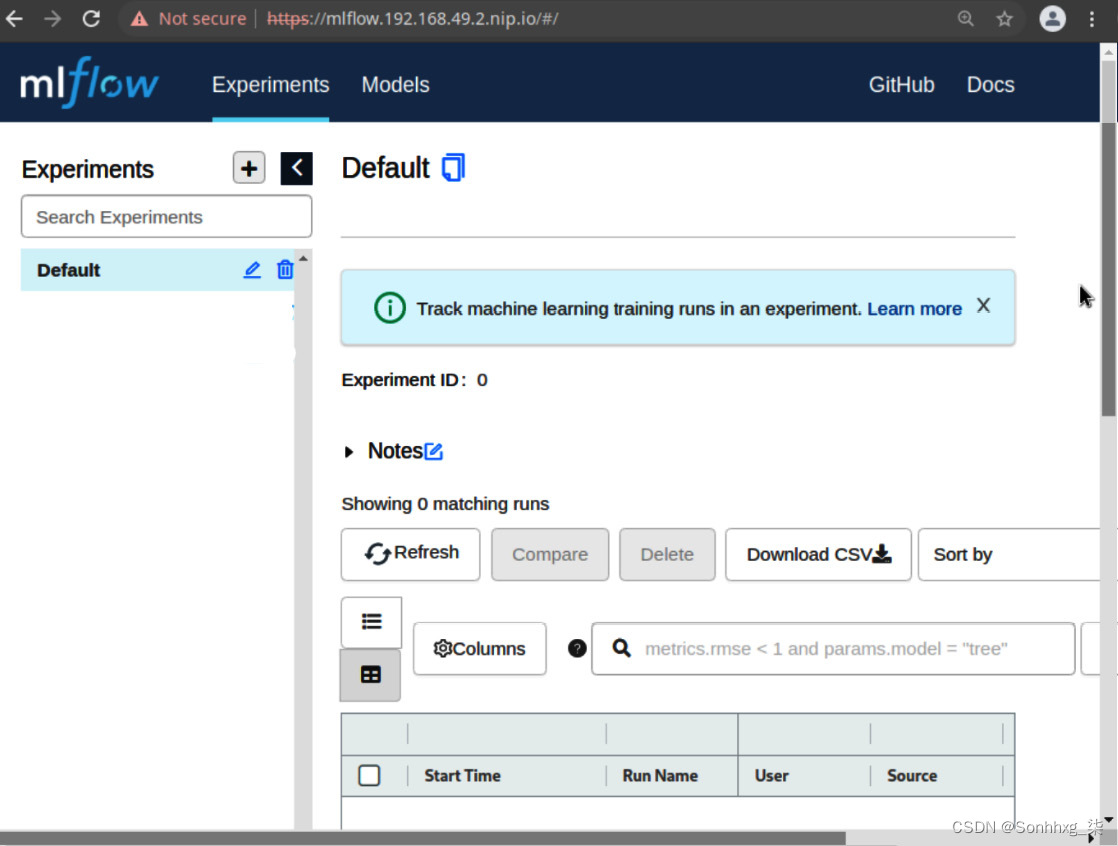
图 6.14 – MLflow 实验跟踪页面
实验屏幕的左侧包含实验列表,右侧显示实验运行的详细信息。将实验视为您正在从事的数据科学项目,例如消费者交易中的欺诈检测,“注释”部分捕获用于运行实验的参数、算法和其他信息的组合。
Models选项卡包含注册表中的模型列表、它们的版本和相应的阶段,其中提到了模型部署在什么环境中。

图 6.15 – MLflow 模型注册页面
如果您可以打开 MLflow URL 并查看上述步骤中描述的页面,那么您刚刚验证了 MLflow 已在您的平台中配置。下一步是编写一个笔记本,用于训练基本模型,同时在您的 MLflow 服务器中记录详细信息。
使用 MLFlow 作为实验跟踪系统
在本节中,您将了解 MLflow 库如何让您使用 MLflow 服务器记录您的实验。您在本章第一部分中看到的自定义笔记本映像已经将 MLflow 库打包到容器中。有关 MLflow 库的确切版本,请参阅第 6 章/requirements.txt文件。
在我们开始这个活动之前,了解两个主要概念很重要:实验和运行。
一个实验是一个MLflow 记录和分组元数据的逻辑名称,例如,一个实验可以是您的项目的名称。假设您正在为为您的零售客户预测信用卡欺诈。这可能成为实验名称。
一次跑步是一次执行在 MLflow 中跟踪的实验。运行属于实验。每次运行可能有稍微不同的配置、不同的超参数,有时还有不同的数据集。您将在 Jupyter 笔记本中调整这些实验参数。模型训练的每次执行通常被视为一次运行。
MLflow 有两种记录实验细节的主要方法。第一个是我们首选的方法,它是启用 MLflow 的自动日志记录功能以与您的 ML 库一起使用。它与 Scikit、TensorFlow、PyTorch、XGBoost 等集成。第二种方法是手动记录所有内容。您将在以下步骤中看到这两个选项。
这些步骤将向您展示如何在 Jupyter 笔记本中执行时在 MLflow 中记录实验运行或模型训练:
1.登录 JupyterHub 并确保选择自定义容器,例如Scikit v1.10 - Elyra Notebook Image。
在点击Start Server按钮之前,通过单击Add more variables链接添加一个环境变量。此变量可能包含敏感信息,例如密码。MLflow 需要此信息将工件上传到 Minio S3 服务器。
登录页面将类似于图 6.16中的屏幕截图:
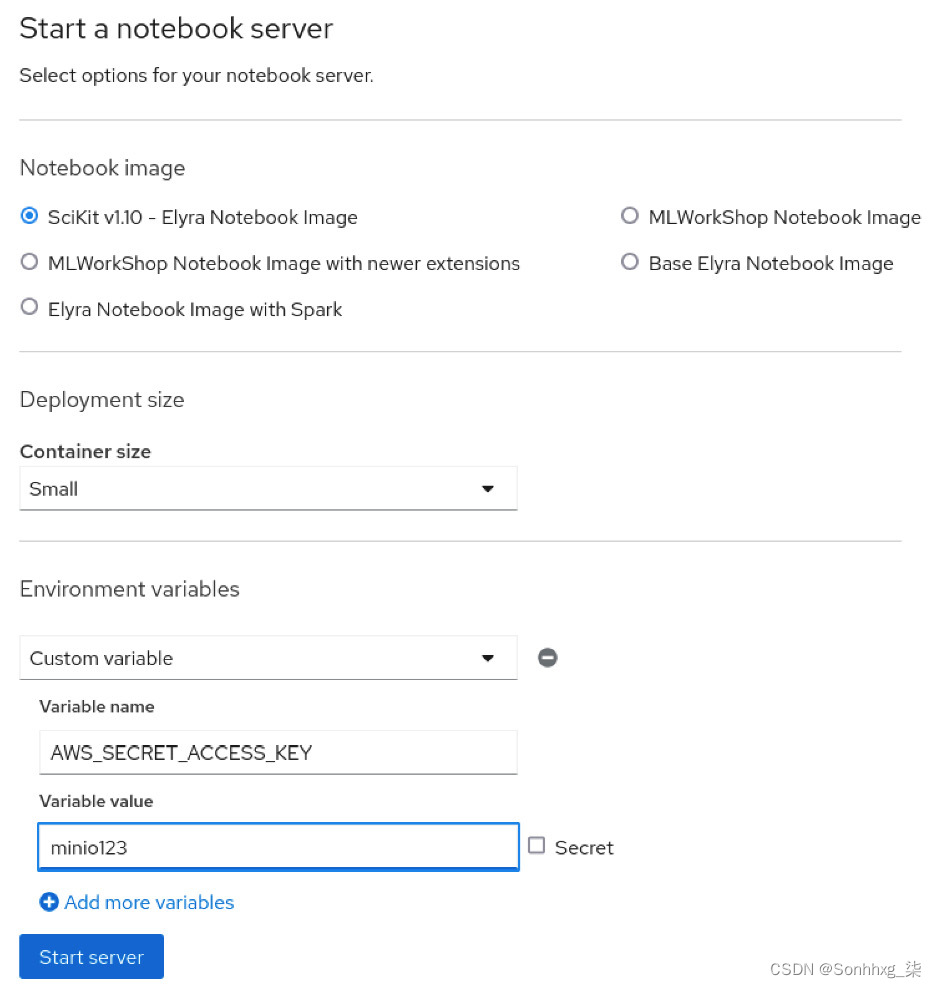
图 6.16 – 带有环境变量的 JupyterHub
2.打开位于第 6 章/hellomlflow.ipynb的笔记本。此笔记本向您展示了如何将实验数据记录到 MLflow 服务器上。
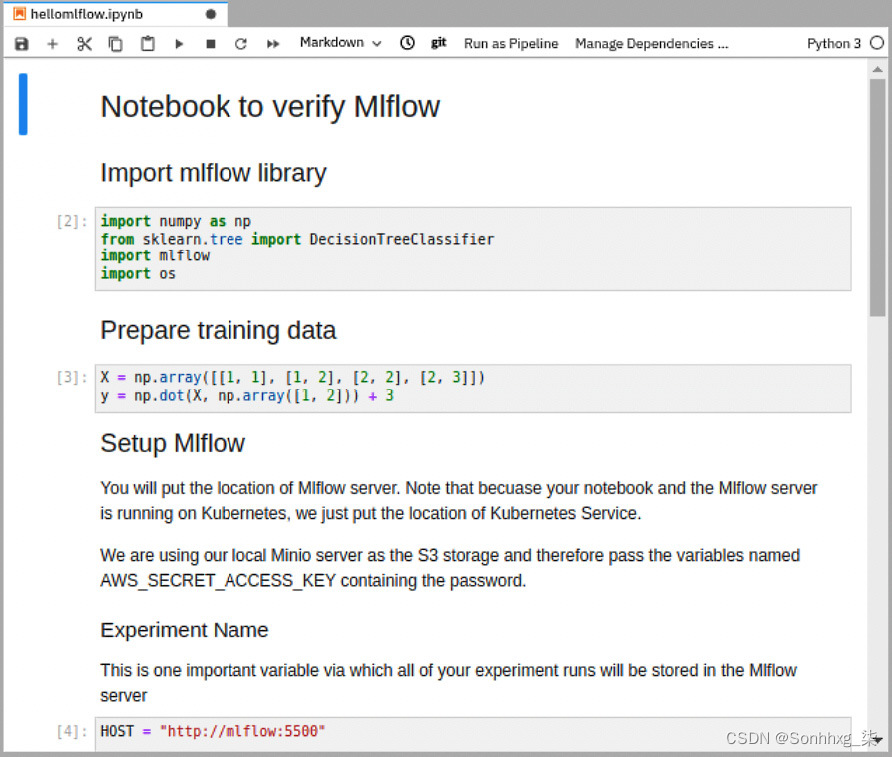
图 6.17 – 带有 Mlflow 集成的笔记本
请注意,在第一个代码单元中,您已导入 MLflow 库。在第二个代码单元中,您已经通过set_tracking_uri方法设置了 MLflow 服务器的位置。请注意,因为您的笔记本和 MLflow 服务器是在 Kubernetes 上运行,我们只是把存储在HOST变量名中并在这个方法中使用的 Kubernetes 服务的位置。
然后使用set_experiment方法设置实验的名称。这是一个重要的变量,您的所有实验运行都将通过它存储在 MLflow 服务器中。
这个单元格中的最后一个方法是sklearn.autolog,这是一种告诉 MLflow 我们正在使用 Scikit 库进行训练的方法,MLflow 将通过 Scikit API 记录数据。

图 6.18 – 带有 MLflow 配置的笔记本单元
在此笔记本的最后一个单元格中,您正在使用一个简单的DecisionTreeClassifier来训练您的模型。请注意,这是一个非常简单的模型,用于突出 MLflow 服务器的功能。
3.通过选择运行 > 运行所有单元菜单选项来运行笔记本。
4.登录MLflow 服务器并单击实验名称HelloMlFlow。MLflow 的 URL 将类似于https://mlflow.192.168.61.72.nip.io,并根据您的环境替换 IP 地址。如本章前面所述,您可以通过列出Kubernetes 集群的入口对象来获取此 URL。
您将看到如图 6.19所示的屏幕:

图 6.19 - 显示实验运行的 MLflow 实验跟踪屏幕
您会注意到右侧的表格包含一条记录。这是实验运行您在步骤 6中执行。如果您使用不同的参数多次执行笔记本,则每次运行将在此表中记录为一行。
5.单击表格的第一行。
您将获得在上一步中选择的运行的详细信息。屏幕将类似于图 6.20中的屏幕截图:
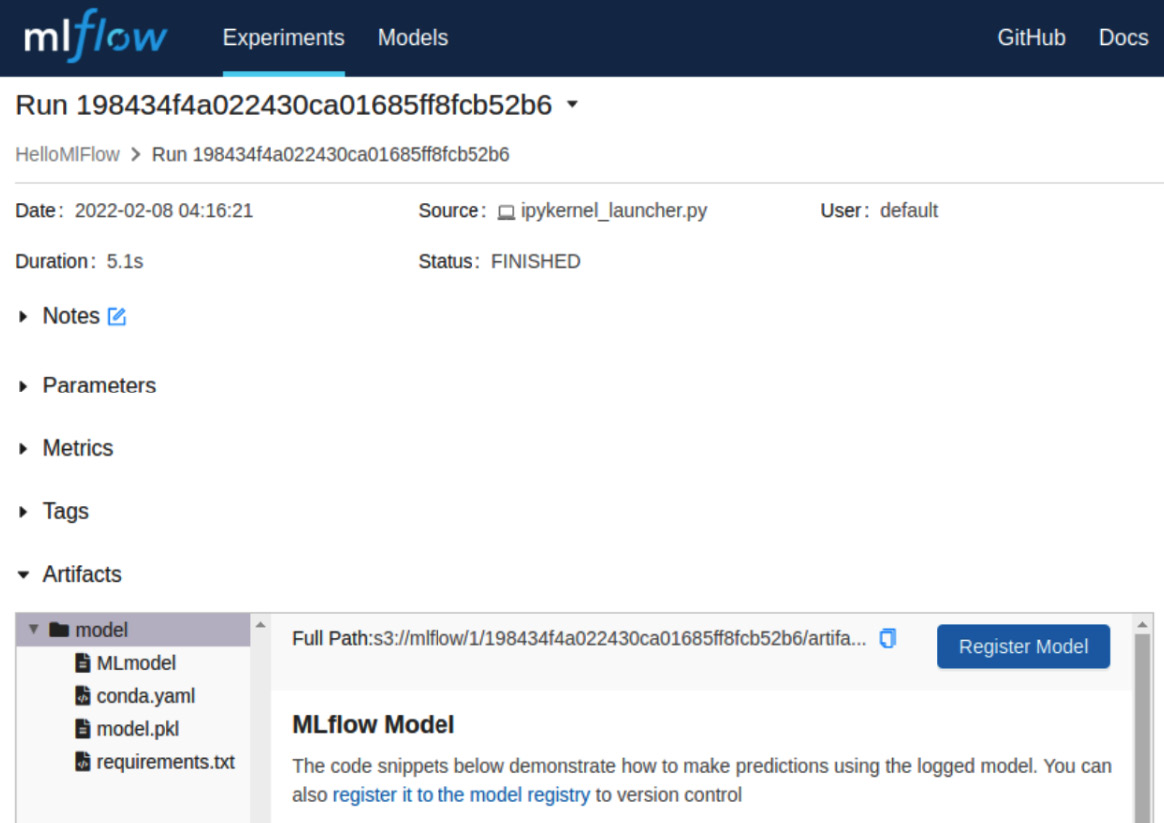
图 6.20 – MLflow 运行细节
让我们了解此屏幕上可用的信息:
- 参数:如果你点击参数旁边的小箭头,你会看到它已经记录了你的模型训练运行的超参数。如果您参考笔记本代码单元格编号4,您将看到我们用于DecisionTreeClassifier的参数也记录在这里。一个这样的例子是max_depth参数,如图 6.21所示:
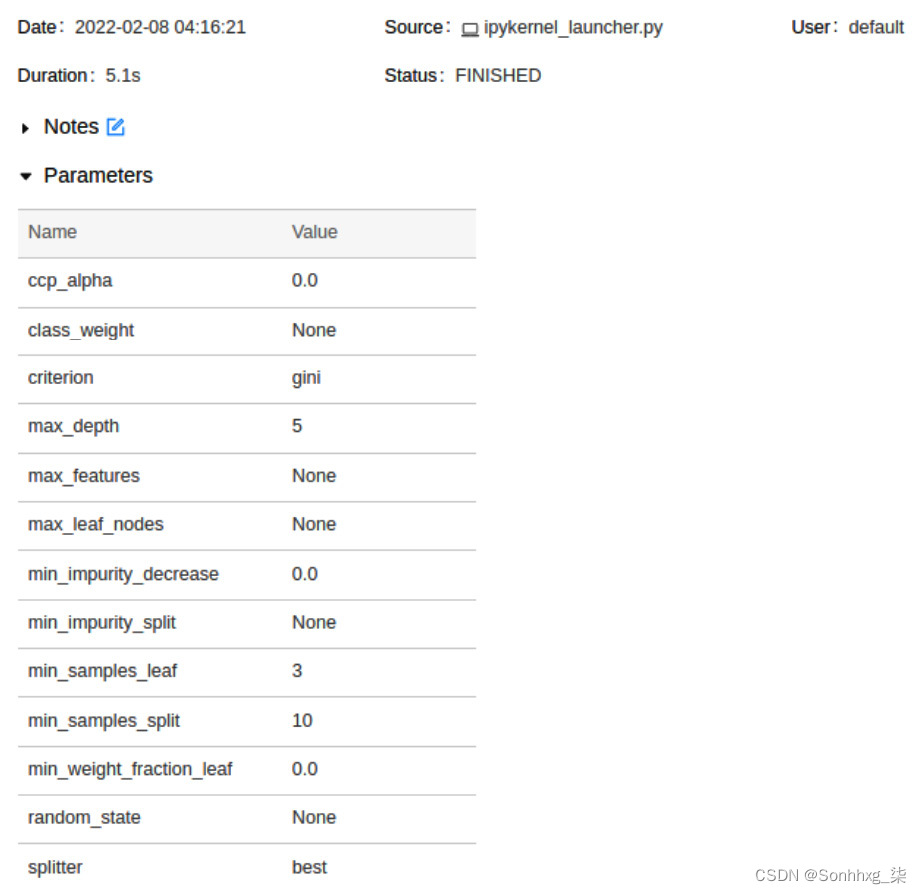
图 6.21 – MLflow 运行参数
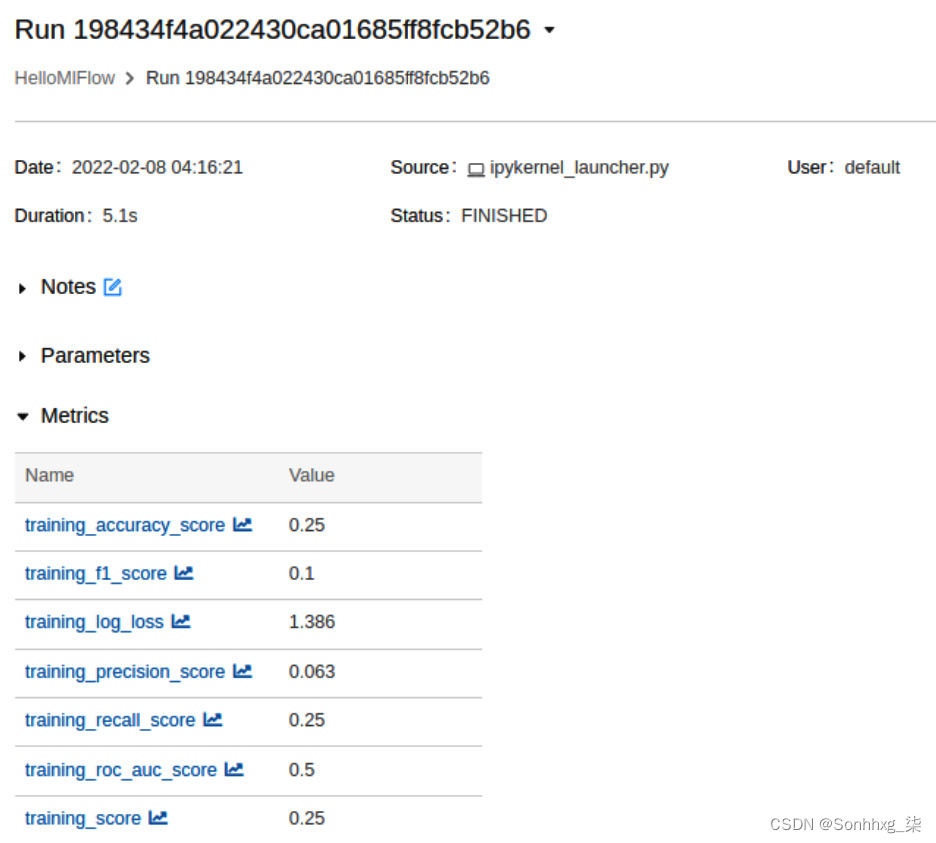
图 6.22 – MLflow 运行指标
- Tags :如果您单击Tags旁边的小箭头,您将看到自动关联的标签(例如,estimator_class),它定义了类型您使用过的 ML 算法。请注意,如果需要,您可以添加自己的标签。在下一节中,我们将展示如何为您的跑步关联自定义标签。图 6.23显示了一个标签示例:
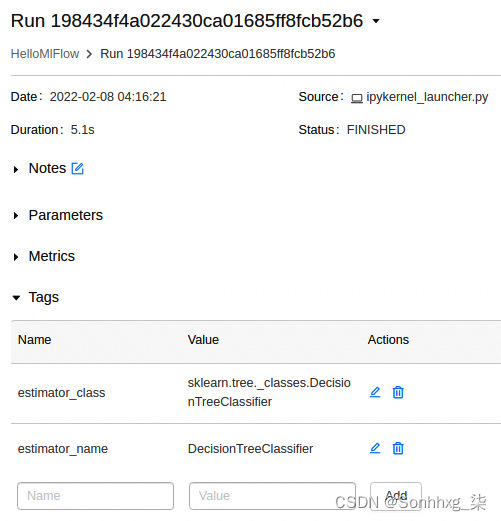
图 6.23 – MLflow 运行标签
- Artifacts:此部分包含与运行相关的工件,例如二进制模型文件。注意如果需要,您可以在此处添加自己的工件。在下一节中,我们将向您展示如何将工件与您的运行相关联。请记住,工件存储在您的 MLflow 服务器的关联 S3 存储桶中。请注意,模型二进制文件保存为model.pkl文件。
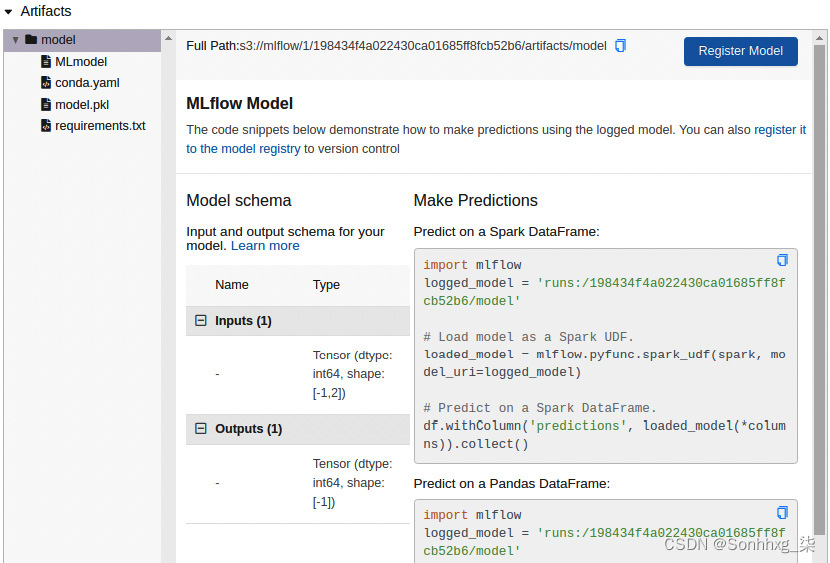
图 6.24 – MLflow 运行工件
- 要验证这些文件是否确实存储在 S3 服务器中,请登录 Minio 服务器,选择Buckets,然后单击MLflow 存储桶的浏览按钮。您将找到一个以您的运行名称创建的文件夹。此名称显示在左上角你的实验屏幕;查看前一个屏幕的左上角,您将看到一个由 32 个字母数字字符组合而成的标签。这个长数字就是您的运行 ID,您可以在 S3 存储桶中看到一个由 32 个字母数字字符组合而成的文件夹标签,如以下屏幕截图所示。您可以单击此链接查找存储在 S3 存储桶中的工件:
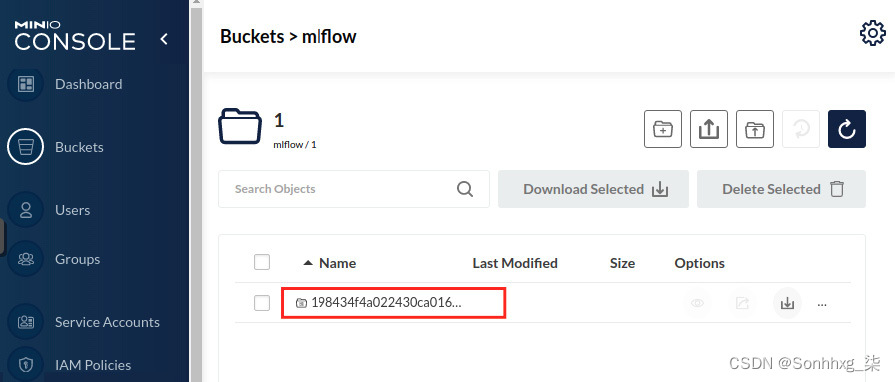
图 6.25 – Minio 存储桶位置
您刚刚在 JupyterHub 中成功训练了一个模型,并在 MLflow 中跟踪了训练运行。
你已经看到了 MLflow 如何将数据与您的每次运行相关联。您甚至可以通过从步骤 6中显示的表格中选择多个运行并单击“比较”按钮来比较多个运行之间的数据。
将自定义数据添加到实验运行
现在,让我们看看如何我们可以为每次运行添加更多数据。您将学习如何使用 MLflow API 将自定义数据与您的实验相关联:
1.首先启动 Jupyter 笔记本,就像您在上一节中所做的那样。
2.在chapter6/hellomlflow-custom.ipynb打开笔记本。此笔记本向您展示了如何自定义将实验数据记录到 MLflow 服务器上。该笔记本与之前的笔记本类似,只是单元格6中的代码如图 6.26所示。此代码单元包含显示如何将数据与实验相关联的函数:

图 6.26 – MLflow 自定义数据收集笔记本
让我们了解这些在接下来的几个步骤中发挥作用。代码单元6中的代码片段如下:
with mlflow.start_run(tags={"mlflow.source.git.commit":
mlflow_util.get_git_revision_hash() ,
"mlflow.source.git.branch": mlflow_util.get_git_branch(),
"code.repoURL": mlflow_util.get_git_remote()}) as run:
model.fit(X, y)
mlflow_util.record_libraries(mlflow)
mlflow_util.log_metric(mlflow, "custom_mteric", 1.0)
mlflow_util.log_param(mlflow, "docker_image_name", os.environ["JUPYTER_IMAGE"])前面的代码将包含一个标记为code.repoURL的自定义标记。这使得追溯在给定实验运行中生成模型的原始源代码变得更加容易。
3.您可以在调用start_run函数时关联任何标签。以mlflow开头的标签键保留供内部使用。您可以看到我们已将 GIT 提交哈希与第一个属性相关联。这将帮助我们了解哪些实验属于您的代码存储库中的哪些代码版本。
您会发现code.repoURL标记包含 Git 存储库位置。您可以根据需要添加任意数量的标签。您可以通过转到 MLflow UI 并打开实验来查看标签。请注意,笔记本有不同的实验名称,它被引用为HelloMlFlowCustom。
注意顶部的Git Commit标签页面的部分,以及标签部分中的自定义标签名称code.repoURL:
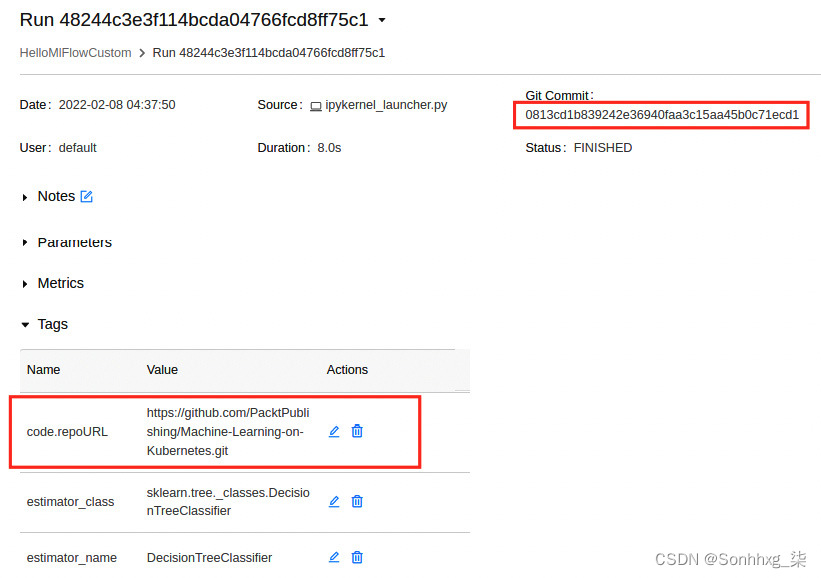
图 6.27 – MLflow 自定义标签
4.我们使用的第二个函数是record_libraries。这是一个包装函数,它在内部使用mlflow.log_artifact函数将文件与运行相关联。此实用程序功能正在捕获pip freeze输出,它提供了当前环境中的库。然后,实用程序函数将其写入文件并将文件上传到 MLflow 实验。您可以在chapter6/mlflow_util.py文件中查看此功能以及所有其他功能。
您可以在Artifacts部分看到一个新文件pip_freeze.txt可用,它记录了管道冻结命令的输出:
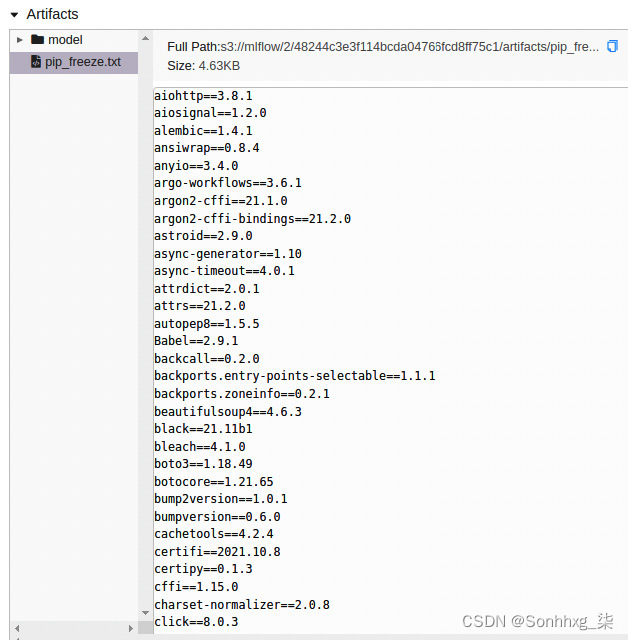
图 6.28 – MLflow 定制工件
5.log_metric函数记录度量名称及其关联值。请注意,指标的值应为数字。对于示例代码,您可以看到我们刚刚放置一个硬编码值 ( 1 ),但是,在现实世界中,这将是一个动态值,它指的是与您的每次实验运行相关的某些东西。您可以在页面的Metrics部分找到您的自定义指标:

图 6.29 – MLflow 自定义指标
6.log_param函数类似于log_metric函数,但它可以针对给定的参数名称采用任何类型的值。比如我们记录了使用的Docker镜像Jupyter 笔记本。回想一下,这是您构建的供数据科学家团队使用的自定义映像。您可以看到以下包含所需值的docker_image_name参数:
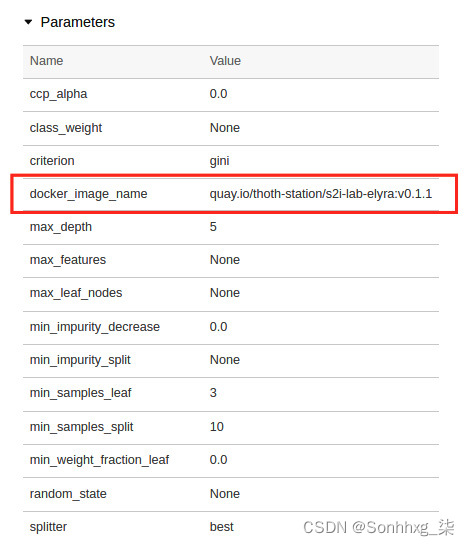
图 6.30 – MLflow 自定义参数
您已经使用 MLflow 跟踪、添加自定义标签和自定义工件到实验运行。在下一节中,您将看到 MLflow 作为模型注册表组件的功能。让我们深入挖掘。
使用 MLFlow 作为模型注册系统
回想一下,MLflow 有一个模型注册功能。注册表为您的模型提供版本控制功能。自动化工具可以从注册表中获取模型,以便在不同环境中部署甚至回滚您的模型。您将在后面的章节中看到,我们平台中的自动化工具通过 API 从这个注册表中获取模型。现在,让我们看看如何使用注册表:
1.通过访问 UI 并单击模型链接登录到 MLflow 服务器。您应该看到以下屏幕。单击创建模型按钮:
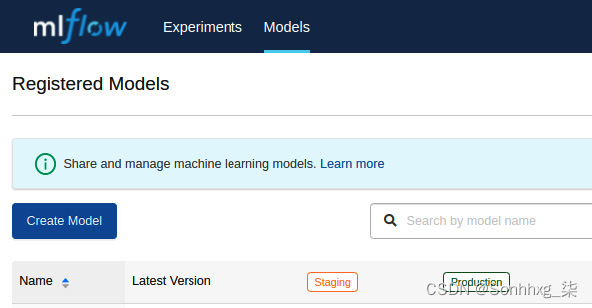
图 6.31 – MLflow 注册一个新模型
2.键入您的名称模型在弹出窗口中,如下图所示,然后单击“创建”按钮。此名称可以提及此模型所服务的项目的名称:

图 6.32 – MLflow 模型名称提示
3.现在,您需要将模型文件附加到此注册名称。回想上一节,您的实验中有多次运行。每次运行都定义了一组配置参数和与之关联的模型。选择要为其注册模型的实验并运行。
4.你会看到一个屏幕像下面这样。在Artifacts部分中选择模型标签,您会注意到右侧的Register Model按钮。单击此按钮:
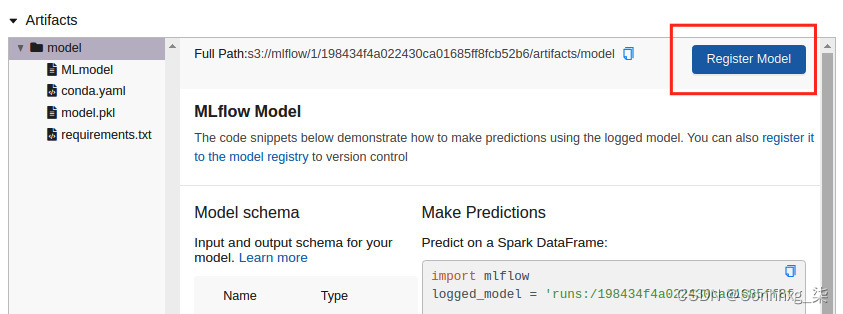
图 6.33 – 显示注册模型按钮的 MLflow
5.从弹出窗口中,选择您在步骤 1中创建的模型名称,然后单击注册。

图 6.34 – 在 MLflow 中注册模型时的模型名称对话框
6.转到步骤 1中提到的模型选项卡,您将看到您的模型已在 MLflow 中注册注册表。您将看到如以下屏幕截图所示的列表。单击模型名称,例如mlflowdemo:
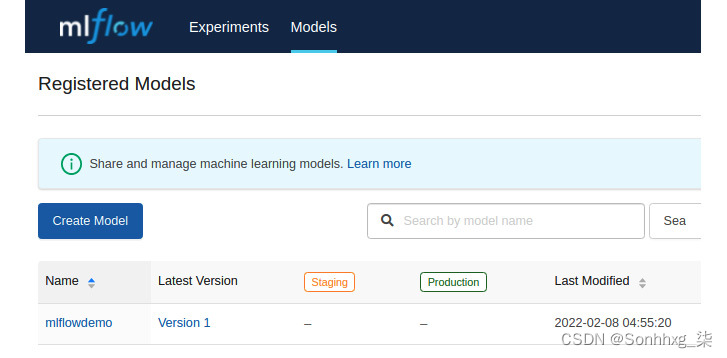
图 6.35 – MLflow 显示已注册模型及其版本的列表
7.您将看到详细信息屏幕,您可以在其中附加阶段标签所指的模型阶段。你还可以编辑其他属性,我们将留给您探索可以与此模型关联的数据:
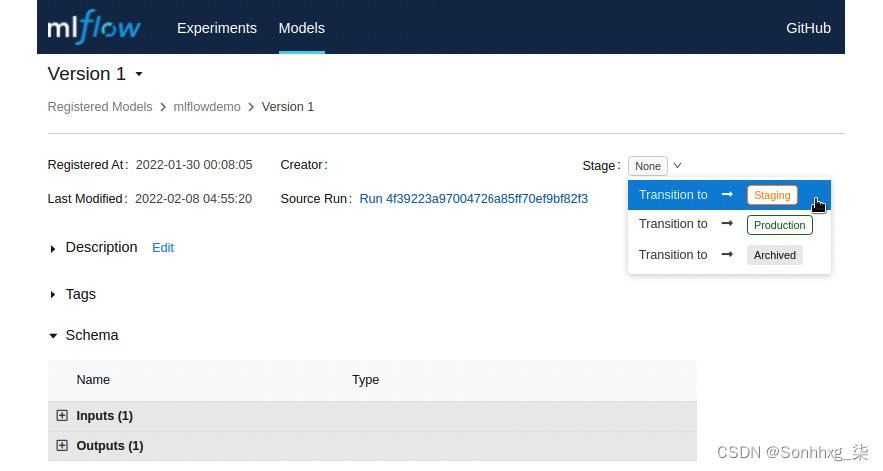
图 6.36 - MLflow 显示将注册模型提升到更高环境的按钮
恭喜!你刚刚使用 MLflow 作为模型注册表的经验!您还看到了如何将模型版本提升到生命周期的不同阶段。
概括
在本章中,您对机器学习工程以及它与数据科学的区别有了更好的理解。您还了解了 ML 工程师的一些职责。您必须注意,随着越来越多的技术浮出水面,ML 工程的定义和 ML 工程师的角色仍在不断发展。我们不会在本书中讨论的一种技术是在线机器学习。
您还学习了如何创建自定义笔记本图像并使用它来标准化笔记本环境。您已经在 Jupyter 笔记本中训练了一个模型,同时使用 MLflow 来跟踪和比较您的模型开发参数、训练结果和指标。您还了解了如何将 MLflow 用作模型注册表,以及如何将模型版本提升到生命周期的不同阶段。
下一章将继续 ML 工程领域,您将打包和部署 ML 模型以作为 API 使用。然后,您将使用 ML 平台中可用的工具自动化包并部署该过程。
相关文章
- Kubernetes 系列(六):kubectl 命令
- Kubernetes详解(四十)——Secret和ConfigMap
- kubernetes 服务发现 Node_Exporter 监控 Kubernetes 集群节点
- 适合 Kubernetes 初学者的一些实战练习(一)
- Kubernetes基础自学系列 | 使用Helm部署dashboard
- Kubernetes基础自学系列 | PV讲解
- kubernetes要实现的目标——随机关掉一台机器,看你的服务能否正常;减少的应用实例能否自动迁移并恢复到其他节点;服务能否随着流量进行自动伸缩
- Kubernetes web界面kubernetes-dashboard安装【h】
- Kubernetes 将应用迁移至kubernetes
- a37.ansible 生产实战案例 -- 基于二进制包安装kubernetes v1.23 -- 集群部署(一)
- Kubernetes部署_使用kubernetes部署prometheus+grafana监控系统(Kubernetes工作实践类)