
Python爬虫爬取某电影排行榜图片实例
2023-09-14 09:15:14 时间
今天继续给大家介绍Python 爬虫相关知识,本文主要内容是Python爬虫爬取某电影排行榜图片实例。
一、要求分析
在上文Python爬虫爬取某电影排行实例中,我们已经能够使用Python程序爬取某电影排行榜中的电影名称。今天,我们来尝试以下下载电影排行榜中的图片。
要想实现这一需求,就必须在上文代码的基础上,即先获得排行榜电影信息,然后提取出电影封面图片的URL,最后将图片下载到本地。
首先,我们可以将Ajax请求中的Json返回结果进行简单的解析,结果如下所示:
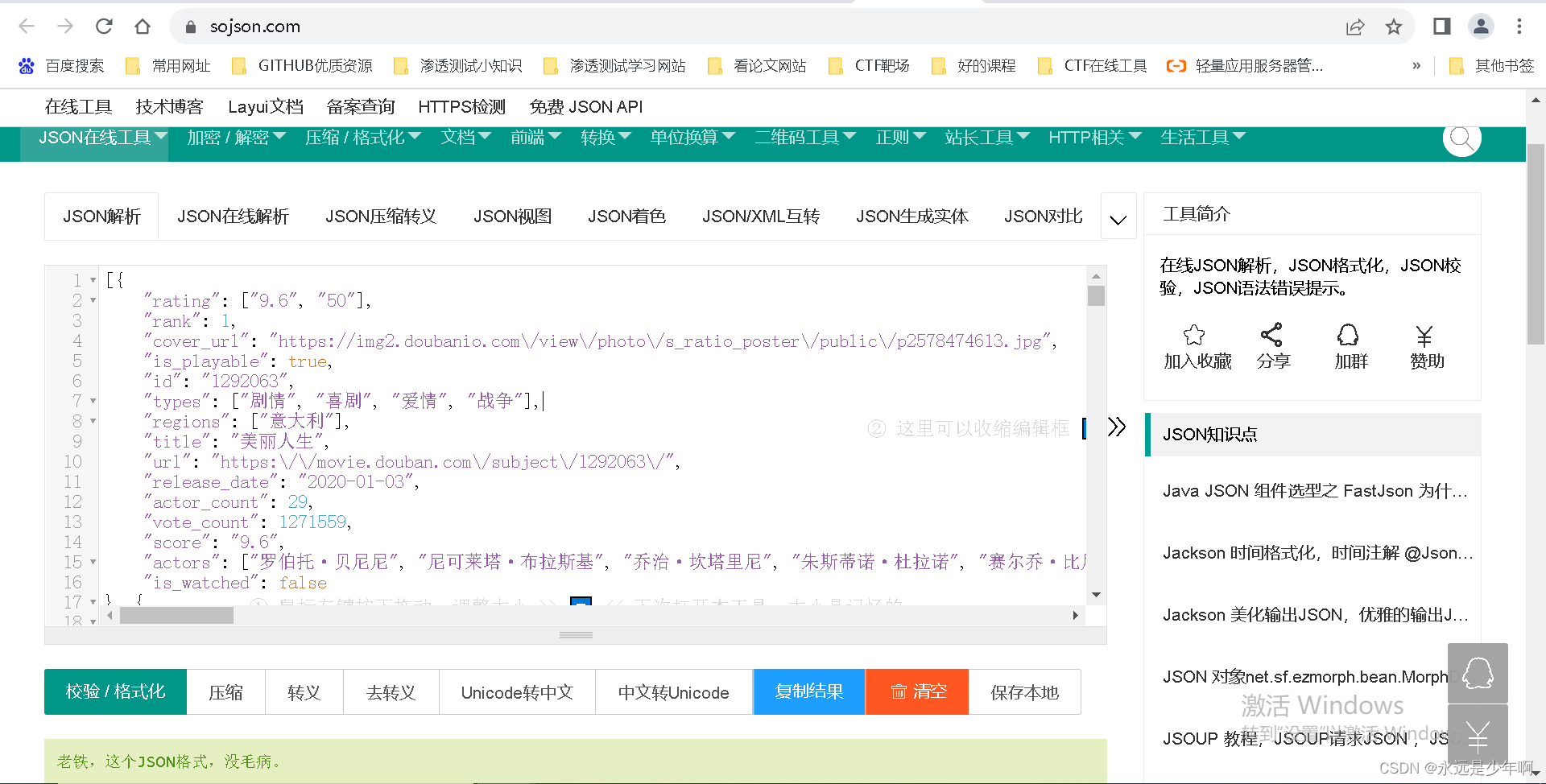
注意在返回字典中存在一个cover_id的变量,这个变量经过检查可以发现就是电影封面图片,如下所示:
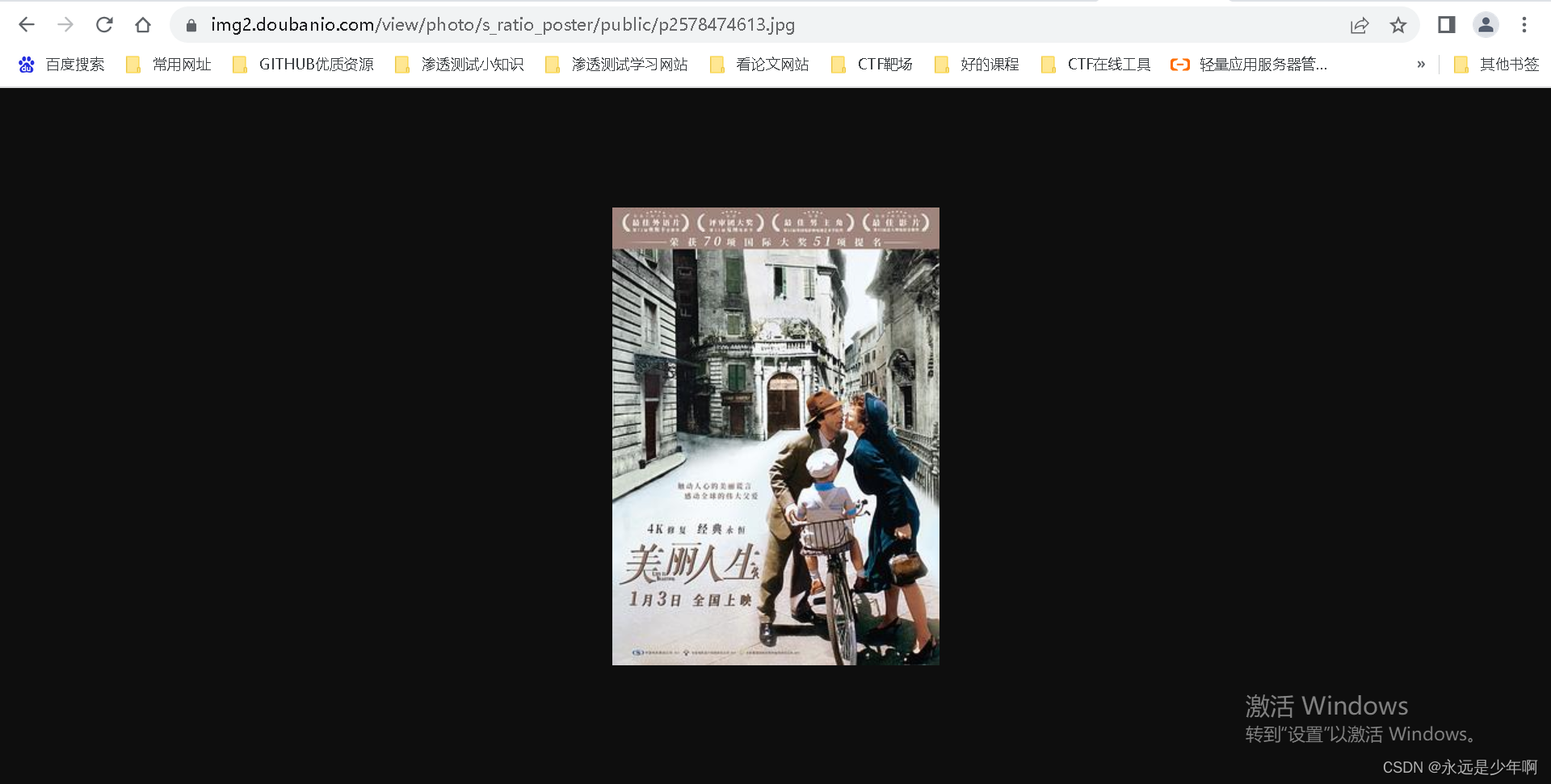
因此,我们只需要提取上述代码中字典的cover_id值,然后再发起URL请求下载该图片即可。
二、代码实现
接下来,我们就编写代码实现这一需求。编写好的代码如下所示:
import requests
import os
if not os.path.exists("./img"):
os.mkdir('./img')
url="https://movie.douban.com/j/chart/top_list"
get_param={
"type":"22","interval_id":"100:90","action":"","start":"0","limit":"10"
}
UA={"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"}
response=requests.get(url=url,params=get_param,headers=UA)
out_put=response.json()
for out in out_put:
img_url=out["cover_url"]
img_name="./img/"+out["title"]+".jpg"
img_data=requests.get(url=img_url,headers=UA).content
with open(img_name,"wb") as fp:
fp.write(img_data)
print("The picture has been downloaded!")
在上述代码中,我们涉及到了图片的下载操作。如果我们在使用requests方法下载的内容是一张图片,那么我们可以用它的content属性来表示这张图片,然后将其写入文件中即可。
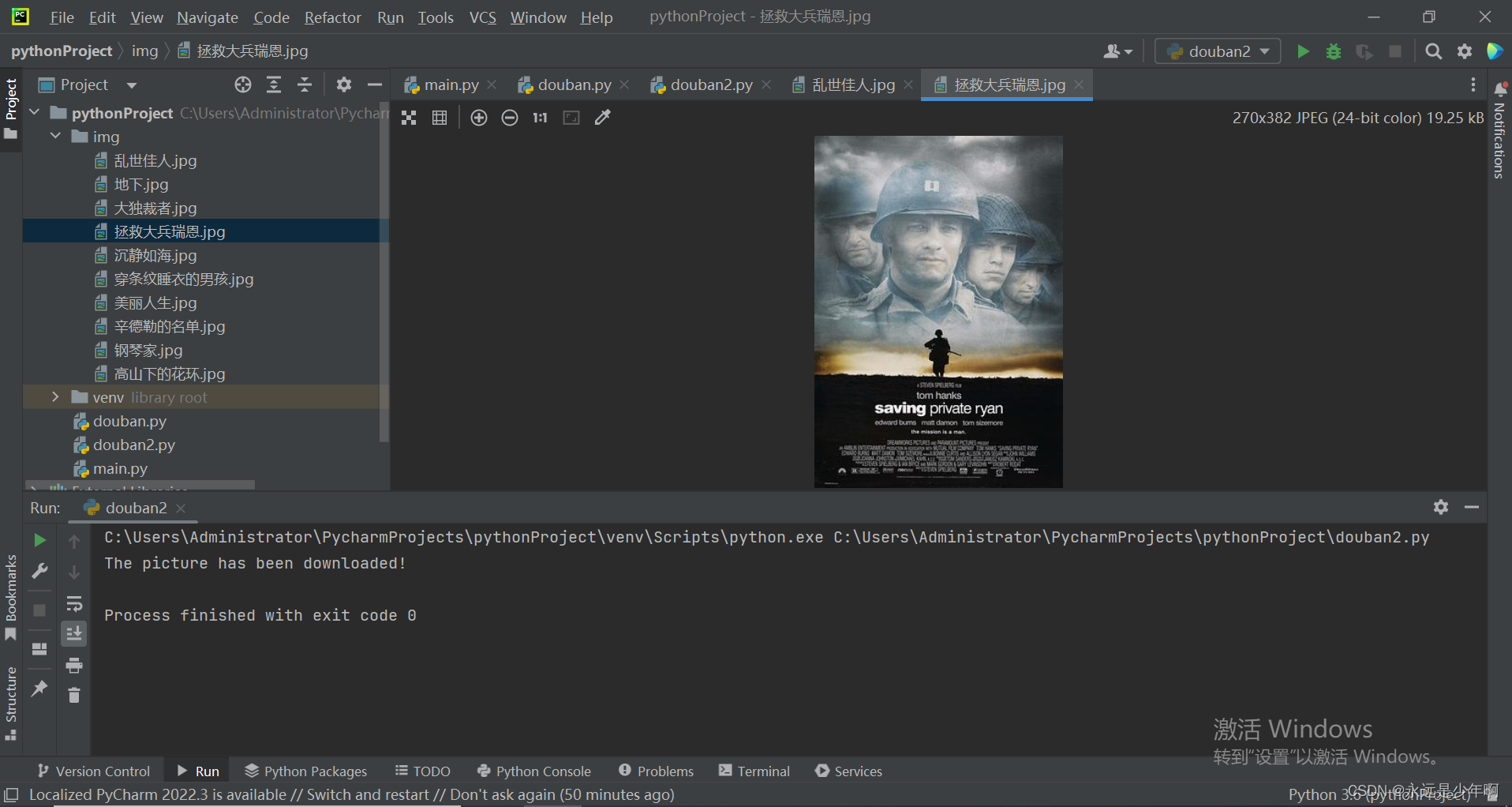
上述代码执行后结果如下所示:
原创不易,转载请说明出处:https://blog.csdn.net/weixin_40228200
相关文章
- 用Python的好处
- Python爬虫—-网页下载器和urllib2模块及对应的实例
- python 网络爬虫入门(一)———第一个python爬虫实例
- Python入门系列(十一)一篇搞定python操作MySQL数据库
- python中dtype的使用规范_Python numpy.dtype() 使用实例
- python截图识别文字_Python文字截图识别OCR工具实例解析
- python爬虫实例大全
- python中关于命名的例子_Python 命名规范入门实例「建议收藏」
- Python抓取数据_python抓取游戏数据
- Python: BeautifulSoup库入门
- Python: “中国大学排名定向爬虫”实例
- python表情代码_Python实现表情包的代码实例[通俗易懂]
- 【说站】python中使用logging的好处
- 遗传算法的应用实例python实现_遗传算法Python解决一个问题
- python chmod_Python os.chmod用法及代码示例
- python的学生信息管理系统_学员信息管理系统设计
- python 图像处理库_Python图像处理库
- 在 Python 中将一个 Legendre 系列添加到另一个 Legendre 系列
- 【源码】10 个 Python 爬虫入门实例!
- python数据分析实例:利用爬虫获取数据
- python-Python与SQLite数据库-使用Python执行SQLite查询(二)
- Python使用Opencv进行图像人脸、眼睛识别实例演示
- Python生成验证码实例详解编程语言
- Python编程学习,高效求解素数程序实例详解编程语言
- 从 Python 连接到 MySQL:实现更多强大的数据库应用(python和mysql)
- python实现socket客户端和服务端简单示例
- 使用Python判断IP地址合法性的方法实例
- python的绘图工具matplotlib使用实例
- python调用短信猫控件实现发短信功能实例