
【AI with ML】第 3 章 :超越基础知识:检测图像中的特征
🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
在第 2 章中你学到了如何通过创建一个简单的神经网络开始使用计算机视觉,该神经网络将 Fashion MNIST 数据集的输入像素与 10 个标签相匹配,每个标签代表一种类型(或类别)的服装。虽然您创建了一个非常擅长检测服装类型的网络,但存在一个明显的缺点。你的神经网络是在单色小图片上训练的,每张图片只包含一件衣服,而且那件衣服位于图片。
要使模型更上一层楼,您需要能够检测图像中的特征。因此,举例来说,如果我们有办法将图像过滤成组成元素,而不是仅仅查看图像中的原始像素,会怎样?匹配这些元素而不是原始像素,将有助于我们更有效地检测图像的内容。考虑一下我们在上一章中使用的 Fashion MNIST 数据集——当检测鞋子时,神经网络可能被聚集在图像底部的许多暗像素激活,它会把这些像素视为鞋底。但是当鞋子不再居中并填充框架时,这个逻辑就不成立了。
一种检测特征的方法来自您可能熟悉的摄影和图像处理方法。如果您曾经使用过像 Photoshop 或 GIMP 这样的工具来锐化图像,那么您就是在使用对图像像素起作用的数学过滤器。这些过滤器的另一个词是卷积,通过在神经网络中使用它们,您将创建一个卷积神经网络(CNN)。
在本章中,您将了解如何使用卷积来检测图像中的特征。然后,您将更深入地研究根据内部特征对图像进行分类。我们将探索图像增强以获得更多特征,并探索迁移学习以获取其他人学习过的已有特征,然后简要介绍如何使用 dropout 优化您的模型。
卷积
一个卷积只是一个过滤器用于将像素与其相邻像素相乘以获得该像素的新值的权重。例如,考虑来自 Fashion MNIST 的踝靴图像及其像素值,如图3-1所示。
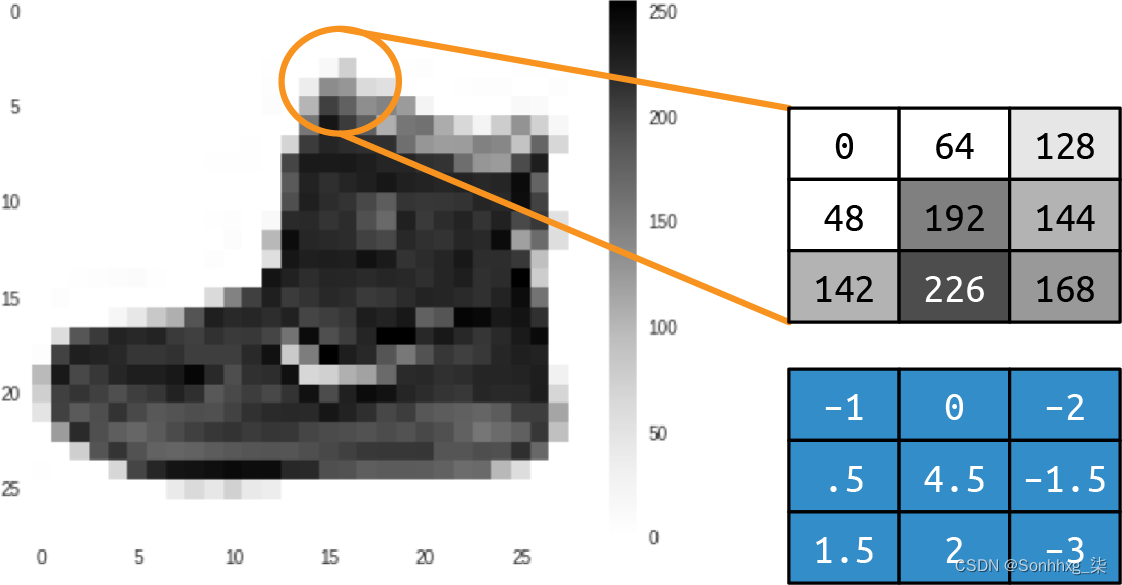
图 3-1。卷边踝靴
如果我们查看选区中间的像素,我们可以看到它的值为 192(回想一下 Fashion MNIST 使用像素值从 0 到 255 的单色图像)。上方和左侧的像素值为 0,紧靠上方的像素值为 64,依此类推。
如果我们然后在相同的 3 × 3 网格中定义一个过滤器,如下所示的原始值,我们可以通过为它计算一个新值来转换该像素。我们通过将网格中每个像素的当前值乘以过滤器网格中相同位置的值,然后求和来实现这一点。此总数将是当前像素的新值。然后我们对图像中的所有像素重复此操作。
所以在这种情况下,虽然选区中心像素的当前值为 192,但应用滤镜后的新值将为:
new_val = (-1 * 0) + (0 * 64) + (-2 * 128) +
(.5 * 48) + (4.5 * 192) + (-1.5 * 144) +
(1.5 * 142) + (2 * 226) + (-3 * 168)这等于 577,这将是该像素的新值。对图像中的每个像素重复此过程将为我们提供经过过滤的图像。
让我们考虑一下对更复杂的图像应用过滤器的影响:为了便于测试而内置到 SciPy 中的上升图像。这是一张 512 × 512 的灰度图像,显示了两个人在爬楼梯。
使用左侧为负值、右侧为正值、中间为零的过滤器最终会从图像中删除除垂直线之外的大部分信息,如图3-2所示。
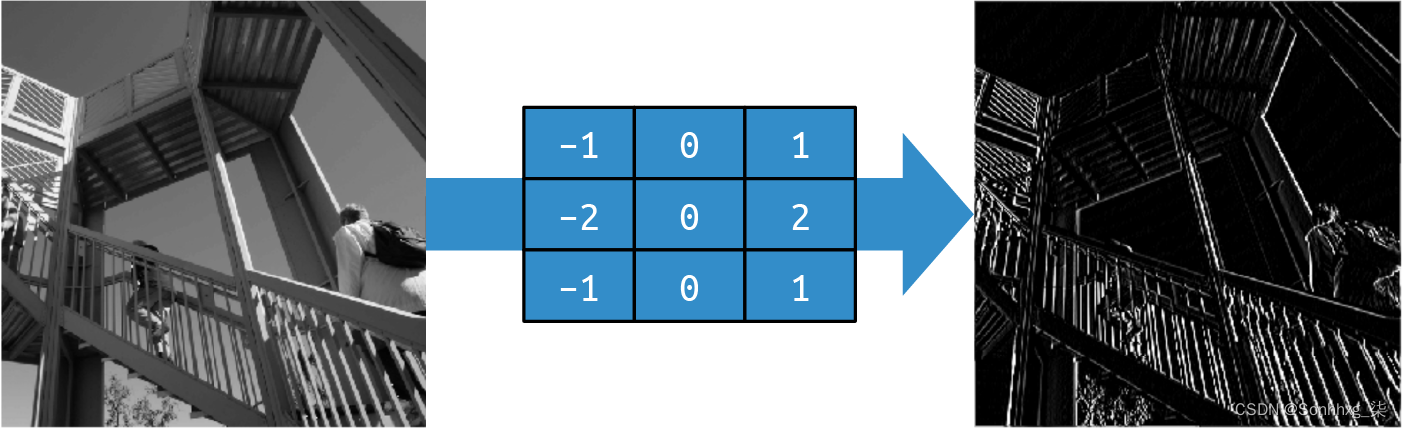
图 3-2。使用过滤器获取垂直线
同样,对过滤器进行微小的更改可以强调水平线,如图3-3所示。
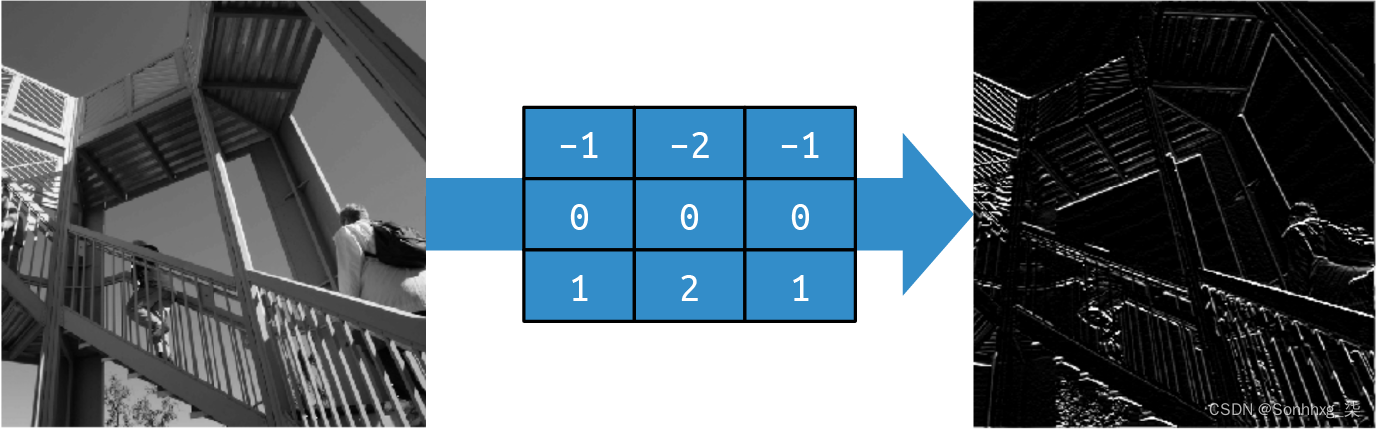
图 3-3。使用过滤器获取水平线
这些示例还表明图像中的信息量减少了,因此我们可以潜在地学习一组将图像减少为特征的过滤器,并且可以像以前一样将这些特征与标签匹配。以前,我们学习了神经元中用于匹配输入与输出的参数。同样,可以随着时间的推移学习将输入与输出相匹配的最佳过滤器。
当与池化相结合时,我们可以在保持特征的同时减少图像中的信息量。接下来我们将探讨这一点。
池化
池化是在保持图像内容语义的同时消除图像中像素的过程。最好用视觉来解释。图 3-4显示了最大池化的概念。
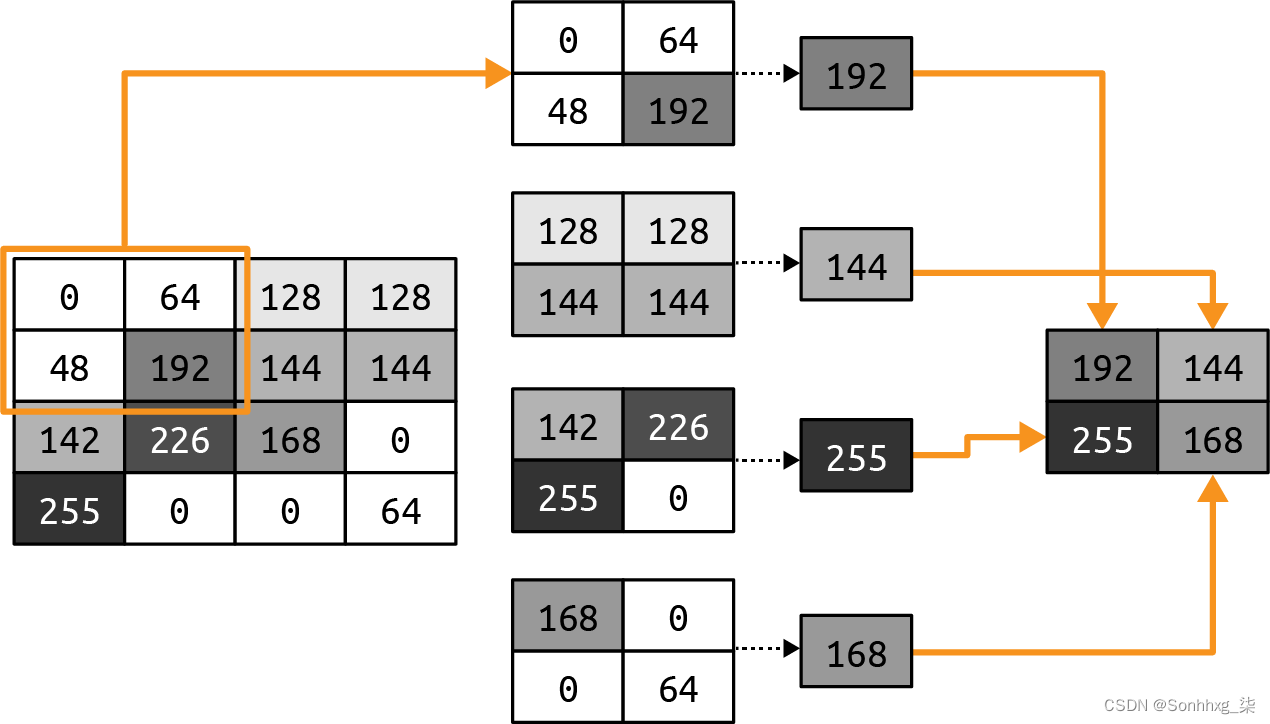
图 3-4。演示最大池化
在这种情况下,将左侧的框视为单色图像中的像素。然后我们将它们分组为 2 × 2 阵列,因此在本例中,16 个像素被分组为四个2 × 2阵列。这些称为池。
然后我们选择每个组中的最大值,并将它们重新组合成一个新图像。因此,左侧的像素减少了 75%(从 16 个减少到 4 个),每个池中的最大值构成了新图像。
图 3-5显示了图 3-2中的上升版本,在应用最大池化之后垂直线得到了增强。

图 3-5。垂直过滤和最大池化后的上升
请注意过滤后的功能不仅得到了维护,而且得到了进一步增强。此外,图像尺寸已从 512 × 512 变为 256 × 256——原始尺寸的四分之一。
笔记
还有其他池化方法,例如最小池化,它从池中取最小的像素值,以及平均池化,它取整体平均值。
实施卷积神经网络
在 第 2 章你创建了一个识别时尚图像的神经网络。为了方便起见,这里是完整的代码:
import tensorflow as tf
data = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = data.load_data()
training_images = training_images / 255.0
test_images = test_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=5)要将其转换为卷积神经网络,我们只需使用我们模型定义中的卷积层。我们还将添加池化层。
要实现卷积层,您将使用 tf.keras.layers.Conv2D类型。这接受在层中使用的卷积数、卷积的大小、激活函数等作为参数。
例如,这是一个用作神经网络输入层的卷积层:
tf.keras.layers.Conv2D(64, (3, 3), activation='relu',
input_shape=(28, 28, 1)),在这种情况下,我们希望该层学习 64 个卷积。它将随机初始化这些,并且随着时间的推移将学习最适合将输入值与其标签匹配的过滤器值。指示(3, 3)过滤器的大小。早些时候我展示了 3 × 3 滤波器,这就是我们在这里指定的。这是最常见的过滤器尺寸;您可以根据需要更改它,但您通常会看到奇数个轴,例如5 × 5或 7 × 7,这是因为滤镜如何从图像的边界移除像素,稍后您将看到。
和activation参数input_shape与之前相同。由于我们在这个例子中使用 Fashion MNIST,形状仍然是 28 × 28。但是请注意,因为Conv2D层是为多色图像设计的,所以我们将第三维指定为 1,所以我们的输入形状是 28 × 28 × 1。彩色图像通常将 3 作为第三个参数,因为它们存储为 R、G 和 B 的值。
以下是如何使用神经网络中的池化层。您通常会在卷积层之后立即执行此操作:
tf.keras.layers.MaxPooling2D(2, 2),在图 3-4的示例中,我们将图像分成 2 × 2 个池,并在每个池中选取最大值。此操作可以参数化以定义池大小。这些是您在这里可以看到的参数——(2, 2)表示我们的池是 2 × 2。
现在让我们使用 CNN 探索 Fashion MNIST 的完整代码:
import tensorflow as tf
data = tf.keras.datasets.fashion_mnist
(training_images, training_labels), (test_images, test_labels) = data.load_data()
training_images = training_images.reshape(60000, 28, 28, 1)
training_images = training_images / 255.0
test_images = test_images.reshape(10000, 28, 28, 1)
test_images = test_images / 255.0
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(64, (3, 3), activation='relu',
input_shape=(28, 28, 1)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(64, (3, 3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
model.fit(training_images, training_labels, epochs=50)
model.evaluate(test_images, test_labels)
classifications = model.predict(test_images)
print(classifications[0])
print(test_labels[0])这里有几点需要注意。还记得之前我说过图像的输入形状必须与层的Conv2D期望相匹配,并且我们将其更新为 28 × 28 × 1 图像吗?数据也必须相应地重塑。28×28是图像的像素数,1是颜色通道数。您通常会发现灰度图像为 1,彩色图像为 3,其中有三个通道(红色、绿色和蓝色),数字表示该颜色的强度。
因此,在对图像进行归一化之前,我们还对每个数组进行整形以使其具有额外的维度。以下代码将我们的训练数据集从 60,000 张图像,每张 28 × 28(因此是一个 60,000 × 28 × 28 数组)更改为 60,000 张图像,每张 28 × 28 × 1:
training_images = training_images.reshape(60000, 28, 28, 1)然后我们对测试数据集做同样的事情。
另请注意,在原始在深度神经网络 (DNN) 中,我们先通过一层运行输入,Flatten然后再将其送入第一Dense层。我们在这里的输入层中丢失了它——相反,我们只指定输入形状。请注意,在层之前Dense,在卷积和池化之后,数据将被展平。
使用与第 2 章所示网络相同的 50 个时期的相同数据训练此网络,我们可以看到准确率有了很好的提高。虽然前面的例子在 50 个时期内在测试集上达到了 89% 的准确率,但这个例子将在大约一半的时间——24 或 25 个时期内达到 99%。所以我们可以看到,在神经网络中加入卷积肯定是在增加它对图像的分类能力。接下来让我们看一下图像通过网络的旅程,以便我们可以更多地了解其工作原理。
探索卷积网络
你可以使用检查你的模型 model.summary命令。当您在我们一直在研究的 Fashion MNIST 卷积网络上运行它时,您会看到如下内容:
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d (Conv2D) (None, 26, 26, 64) 640
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 13, 13, 64) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 11, 11, 64) 36928
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 1600) 0
_________________________________________________________________
dense (Dense) (None, 128) 204928
_________________________________________________________________
dense_1 (Dense) (None, 10) 1290
=================================================================
Total params: 243,786
Trainable params: 243,786
Non-trainable params: 0让我们首先看一下 Output Shape 列,以了解这里发生了什么。我们的第一层将有 28 × 28 的图像,并对其应用 64 个过滤器。但是因为我们的过滤器是 3 × 3,图像周围的 1 像素边界将丢失,将我们的整体信息减少到 26 × 26 像素。考虑图 3-6。如果我们将每个框作为图像中的一个像素,我们可以做的第一个可能的过滤器从第二行和第二列开始。同样的情况也会发生在图表的右侧和底部。
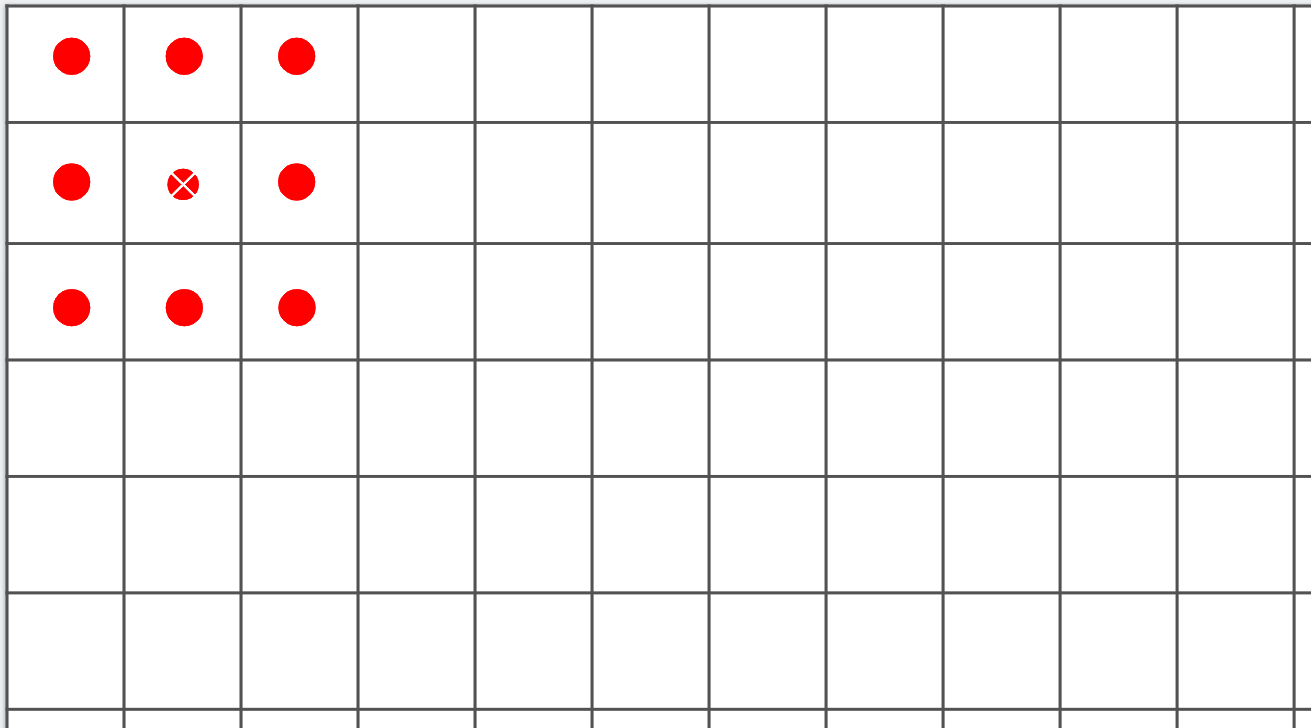
图 3-6。运行过滤器时丢失像素
因此,当通过 3 × 3 过滤器时,形状为 A × B 像素的图像将变为形状为 (A–2) × (B–2) 像素。类似地,一个 5 × 5 的滤波器会变成 (A–4) × (B–4),依此类推。由于我们使用 28 × 28 的图像和 3 × 3 的过滤器,我们的输出现在将是 26 × 26。
之后pooling层是2×2,所以图像的尺寸在每个轴上都会减半,变成(13×13)。下一个卷积层会将其进一步减少到 11 × 11,下一个池化,向下舍入,将使图像为 5 × 5。
因此,当图像经过两个卷积层时,结果将是许多 5×5 图像。多少?我们可以在 Param #(参数)列中看到。
每个卷积都是一个 3×3 的过滤器,加上一个偏差。还记得之前我们的密集层吗,每一层都是 Y = mX + c,其中 m 是我们的参数(又名权重),c 是我们的偏差?这非常相似,只是因为过滤器是 3 × 3,所以有 9 个参数要学习。鉴于我们定义了 64 个卷积,我们将有 640 个整体参数(每个卷积有 9 个参数加上一个偏差,总共 10 个,共有 64 个)。
这些MaxPooling层不学习任何东西,它们只是缩小图像,所以那里没有学到的参数——因此报告为 0。
下一个卷积层有 64 个过滤器,但每个过滤器都与前面的64 个过滤器相乘,每个过滤器有 9 个参数。我们对新的 64 个过滤器中的每一个都有偏差,所以我们的参数数量应该是 (64 × (64 × 9)) + 64,这给了我们网络需要学习的 36,928 个参数。
如果这令人困惑,请尝试将第一层中的卷积数更改为某个值,例如 10。您会看到第二层中的参数数变为 5,824,即 (64 × (10 × 9)) + 64).
当我们完成第二个卷积时,我们的图像是 5 × 5,我们有 64 张。如果我们将它相乘,我们现在有 1,600 个值,我们将把它们输入到一个由 128 个神经元组成的密集层中。每个神经元都有一个权重和一个偏差,我们有 128 个,因此网络将学习的参数数量为 ((5 × 5 × 64) × 128) + 128,给我们 204,928 个参数。
我们最终的 10 个神经元密集层接收了前面 128 个神经元的输出,因此学习的参数数量将为 (128 × 10) + 10,即 1,290。
那么参数的总数就是所有这些的总和:243,786。
训练这个网络需要我们学习这 243,786 个参数中最好的一组,以将输入图像与其标签相匹配。这是一个较慢的过程,因为有更多的参数,但正如我们从结果中看到的那样,它也建立了一个更准确的模型!
当然,对于这个数据集,我们仍然有图像为 28 × 28、单色且居中的限制。接下来我们将看看使用卷积来探索包含马和人的彩色图片的更复杂的数据集,我们将尝试确定图像是否包含其中之一。在这种情况下,主体不会像 Fashion MNIST 那样总是位于图像的中心,因此我们将不得不依靠卷积来发现区别特征。
建立一个 CNN 来区分马和人
在本节我们将探索比 Fashion MNIST分类器更复杂的场景。我们将扩展我们对卷积和卷积神经网络的了解,以尝试对特征位置并不总是在同一位置的图像内容进行分类。为此,我创建了 Horses 或 Humans 数据集。
马或人数据集
的数据集 这部分包含一千多个 300 × 300 像素的图像,马和人各占一半左右,以不同的姿势呈现。您可以在图 3-7中看到一些示例。

图 3-7。马和人
如您所见,对象具有不同的方向和姿势,并且图像构图也各不相同。例如,考虑两匹马——它们的头部方向不同,一匹缩小显示完整的动物,而另一匹放大,仅显示头部和身体的一部分。同样,人类的光线不同,肤色不同,姿势也不同。男人的手放在臀部,女人的手伸直。这些图像还包含树木和海滩等背景,因此分类器必须在不受背景影响的情况下确定图像的哪些部分是决定马是马、人是人的重要特征。
虽然之前的预测 Y = 2X – 1 或对小型单色服装图像进行分类的示例使用传统编码可能是可行的,但很明显这要困难得多,而且您正在越过界限,进入机器学习对于解决问题至关重要的地方问题。
一个有趣的旁注是这些图像都是计算机生成的。该理论认为,在马的 CGI 图像中发现的特征应该适用于真实图像。您将在本章后面看到它的工作原理。
Keras 图像数据生成器
这到目前为止,您一直在使用的时尚 MNIST 数据集带有标签。每个图像文件都有一个带有标签详细信息的关联文件。许多基于图像的数据集没有这个,马或人类也不例外。图像被分类到每种类型的子目录中,而不是标签。使用 TensorFlow 中的 Keras,一个名为 的工具ImageDataGenerator可以使用此结构自动为图像分配标签。
要使用ImageDataGenerator,您只需确保您的目录结构具有一组命名的子目录,每个子目录都是一个标签。例如,Horses 或 Humans 数据集以一组 ZIP 文件的形式提供,一个包含训练数据(1,000 多张图像),另一个包含验证数据(256 张图像)。当您将它们下载并解压到本地目录以进行训练和验证时,请确保它们的文件结构如图3-8 所示。
下面是获取训练数据并将其提取到适当命名的子目录中的代码,如图3-8所示:
import urllib.request
import zipfile
url = "https://storage.googleapis.com/laurencemoroney-blog.appspot.com/
horse-or-human.zip"
file_name = "horse-or-human.zip"
training_dir = 'horse-or-human/training/'
urllib.request.urlretrieve(url, file_name)
zip_ref = zipfile.ZipFile(file_name, 'r')
zip_ref.extractall(training_dir)
zip_ref.close()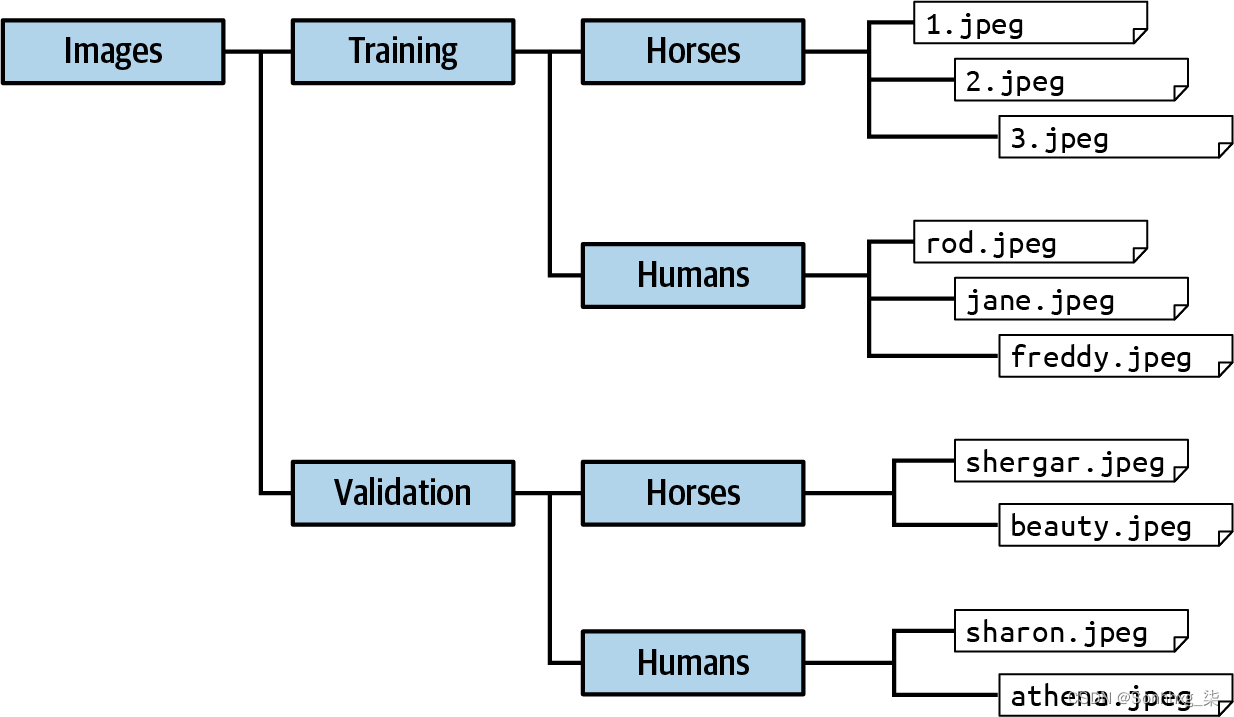
图 3-8。确保图像位于命名的子目录中
这只是下载训练数据的 ZIP 并将其解压缩到horse-or-human/training的目录中(我们将很快处理下载验证数据)。这是包含图像类型子目录的父目录。
要使用ImageDataGenerator我们现在只需使用以下代码:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
# All images will be rescaled by 1./255
train_datagen = ImageDataGenerator(rescale=1/255)
train_generator = train_datagen.flow_from_directory(
training_dir,
target_size=(300, 300),
class_mode='binary'
)我们首先创建一个ImageDataGeneratorcalled的实例train_datagen。然后我们指定这将通过从目录中流动图像来为训练过程生成图像。如前所述,该目录是training_dir 。我们还指出了一些关于数据的超参数,例如目标大小——在这种情况下,图像为 300 × 300,类别模式为binary. 模式通常binary是只有两种类型的图像(如本例)或categorical多于两种。
面向马或人类的 CNN 架构
那里此数据集与 Fashion MNIST 数据集之间的几个主要差异是您在设计用于对图像进行分类的架构时必须考虑的。首先,图像要大得多——300 × 300 像素——因此可能需要更多层。其次,图像是全彩色的,而不是灰度图像,因此每幅图像将具有三个通道而不是一个。第三,只有两种图像类型,所以我们有一个二元分类器,它可以只使用一个输出神经元来实现,其中一个类接近 0,另一个类接近 1。探索此架构时,请牢记以下注意事项:
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(16, (3,3), activation='relu' ,
input_shape=(300, 300, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
tf.keras.layers.Conv2D(32, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(1, activation='sigmoid')
])这里有很多事情需要注意。首先,这是第一层。我们定义了 16 个过滤器,每个 3 × 3,但是图像的输入形状是 (300, 300, 3)。请记住,这是因为我们的输入图像是 300 × 300 并且是彩色的,所以有三个通道,而不是我们之前使用的单色 Fashion MNIST 数据集只有一个通道。
在另一端,请注意输出层中只有一个神经元。这是因为我们使用的是二元分类器,我们可以得到如果我们用一个 sigmoid 函数。sigmoid 函数的目的是将一组值驱动到 0,将另一组值驱动到 1,这非常适合二元分类。
接下来,请注意我们如何堆叠更多的卷积层。我们这样做是因为我们的图像源非常大,并且随着时间的推移,我们希望有许多较小的图像,每个图像都突出显示了特征。如果我们看一下model.summary我们将看到的结果:
=================================================================
conv2d (Conv2D) (None, 298, 298, 16) 448
_________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 149, 149, 16) 0
_________________________________________________________________
conv2d_1 (Conv2D) (None, 147, 147, 32) 4640
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 73, 73, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 71, 71, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 35, 35, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 33, 33, 64) 36928
_________________________________________________________________
max_pooling2d_3 (MaxPooling2 (None, 16, 16, 64) 0
_________________________________________________________________
conv2d_4 (Conv2D) (None, 14, 14, 64) 36928
_________________________________________________________________
max_pooling2d_4 (MaxPooling2 (None, 7, 7, 64) 0
_________________________________________________________________
flatten (Flatten) (None, 3136) 0
_________________________________________________________________
dense (Dense) (None, 512) 1606144
_________________________________________________________________
dense_1 (Dense) (None, 1) 513
=================================================================
Total params: 1,704,097
Trainable params: 1,704,097
Non-trainable params: 0
_________________________________________________________________请注意,当数据通过所有卷积层和池化层时,它最终变成了 7 × 7 个项目。从理论上讲,这些将是相对简单的激活特征图,仅包含 49 个像素。然后可以将这些特征图传递给密集神经网络,以将它们与适当的标签相匹配。
当然,这导致我们的参数比之前的网络多很多,所以训练起来会更慢。使用此架构,我们将学习 170 万个参数。
小费
本节以及本书许多地方的代码可能需要您导入 Python 库。要找到正确的导入,您可以在https://github.com/lmoroney/tfbook查看存储库。
为了训练网络,我们必须使用损失函数和优化器对其进行编译。在这种情况下,损失函数可以是 binary cross entropy loss function binary cross entropy,因为只有两个类,顾名思义这是一个专门针对那个场景设计的损失函数。和我们可以尝试一个新的优化器,均方根传播( RMSprop),它需要一个学习率 ( lr) 参数,允许我们调整学习。这是代码:
model.compile(loss='binary_crossentropy',
optimizer=RMSprop(lr=0.001),
metrics=['accuracy'])我们通过使用fit_generator和传递training_generator我们之前创建的它来训练:
history = model.fit_generator(
train_generator,
epochs=15
)此示例将在 Colab 中运行,但如果您想在自己的计算机上运行它,请确保使用pillowPillow安装库。pip install
笔记使用 TensorFlow Keras,您可以使用它model.fit来使您的训练数据适合您的训练标签。使用生成器时,旧版本要求您改为使用model.fit_generator。更高版本的 TensorFlow 将允许您使用其中任何一个。
仅在 15 个时期内,该架构就为我们提供了令人印象深刻的 95% 以上的训练集准确率。当然,这只是训练数据,并不表示网络以前未见过的数据的性能。
接下来,我们将使用生成器添加验证集并测量其性能,以便我们很好地了解该模型在现实生活中的表现。
向马或人类数据集添加验证
至添加验证,您将需要一个与训练数据集分开的验证数据集。在某些情况下,您会得到一个必须自己拆分的主数据集,但对于马或人类,您可以下载一个单独的验证集。
笔记
你可能想知道为什么我们在这里谈论验证数据集而不是测试数据集,以及它们是否是同一回事。对于像前几章中开发的模型这样的简单模型,将数据集分成两部分通常就足够了,一部分用于训练,一部分用于测试。但是对于像我们在这里构建的模型这样更复杂的模型,您需要创建单独的验证集和测试集。有什么不同?训练数据是用于教导网络数据和标签如何组合在一起的数据。验证数据用于在您训练时查看网络如何处理以前未见过的数据——即,它不用于将数据拟合到标签,而是用于检查拟合进行得如何。测试训练后使用数据来查看网络如何处理它以前从未见过的数据。一些数据集带有三向拆分,在其他情况下,您需要将测试集分成两部分进行验证和测试。在这里,您将下载一些额外的图像来测试模型。
您可以使用与用于训练图像的代码非常相似的代码来下载验证集并将其解压缩到不同的目录中:
validation_url = "https://storage.googleapis.com/laurencemoroney-blog.appspot.com
/validation-horse-or-human.zip"
validation_file_name = "validation-horse-or-human.zip"
validation_dir = 'horse-or-human/validation/'
urllib.request.urlretrieve(validation_url, validation_file_name)
zip_ref = zipfile.ZipFile(validation_file_name, 'r')
zip_ref.extractall(validation_dir)
zip_ref.close()获得验证数据后,您可以设置另一个ImageDataGenerator来管理这些图像:
validation_datagen = ImageDataGenerator(rescale=1/255)
validation_generator = train_datagen.flow_from_directory(
validation_dir,
target_size=(300, 300),
class_mode='binary'
)要让 TensorFlow 为您执行验证,您只需更新您的model.fit_generator方法以表明您想要使用验证数据逐个时期地测试模型。您可以通过使用validation_data参数并将其传递给您刚刚构建的验证生成器来执行此操作:
history = model.fit_generator(
train_generator,
epochs=15,
validation_data=validation_generator
)训练 15 个 epoch 后,您应该会看到您的模型在训练集上的准确率为 99% 以上,但在验证集上的准确率仅为 88% 左右。正如我们在上一章中看到的,这表明模型过度拟合。
尽管如此,考虑到训练的图像数量以及这些图像的多样性,性能还不错。您开始因缺少数据而碰壁,但是您可以使用一些技术来提高模型的性能。我们将在本章后面探讨它们,但在此之前让我们先看看如何使用这个模型。
测试马或人的图像
它是一切都很好,能够建立一个模型,但你当然想尝试一下。当我开始我的 AI 之旅时,我的一个主要挫折是我可以找到很多代码来展示我如何构建模型,以及这些模型如何执行的图表,但很少有代码可以帮助我解决这个问题模型自己尝试一下。我会在本书中尽量避免这种情况!
测试该模型使用 Colab 可能是最简单的。我在 GitHub 上提供了一个 Horses 或 Humans 笔记本,您可以直接在Colab中打开它。
训练完模型后,您会看到一个名为“运行模型”的部分。在运行它之前,先在网上找几张马或人的照片,然后下载到你的电脑上。Pixabay.com是一个非常好的网站,可以查看免版税图片。最好先将测试图像放在一起,因为节点可能会在您搜索时超时。
图 3-9显示了我从 Pixabay 下载的几张马和人的图片,用于测试模型。

图 3-9。测试图像
上传时,如图3-10所示,模型正确地将第一张图片分类为人,将第三张图片正确分类为马,但是中间的图片,尽管明显是人,却被错误地分类为马!
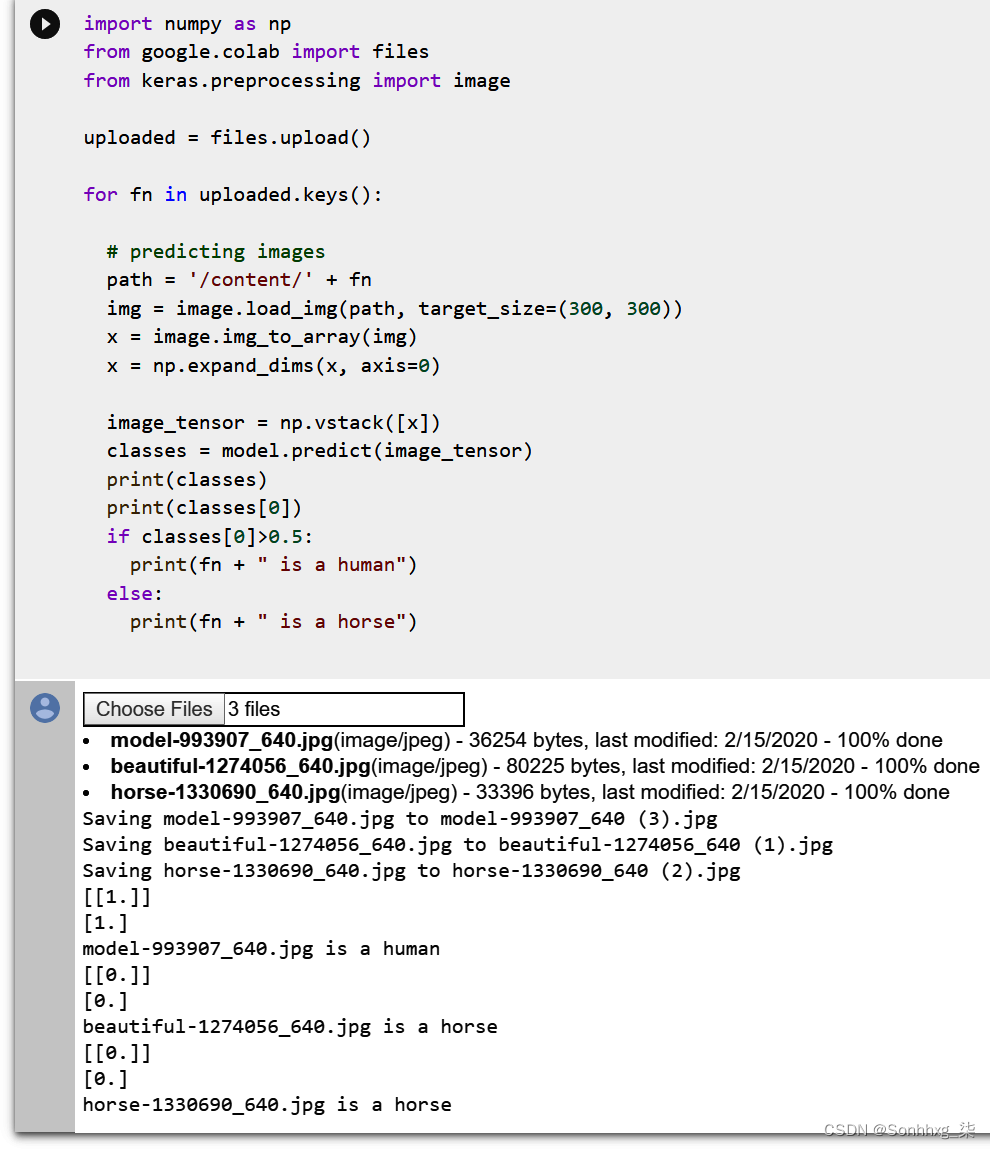
图 3-10。执行模型
您还可以同时上传多张图片,让模型对所有图片进行预测。您可能会注意到它倾向于过度拟合马。如果人没有完全摆好姿势——也就是说,你看不到他们的整个身体——它可能会偏向马。这就是本案中发生的事情。第一个人体模型是完全摆好姿势的,图像与数据集中的许多姿势相似,因此能够正确地对她进行分类。第二个模特正对着镜头,但只有她的上半身出现在画面中。没有像那样的训练数据,所以模型无法正确识别她。
现在让我们探索代码,看看它在做什么。也许最重要的部分是这个块:
img = image.load_img(path, target_size=(300, 300))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)在这里,我们从 Colab 写入图像的路径加载图像。请注意,我们将目标尺寸指定为 300 × 300。上传的图像可以是任何形状,但如果我们要将它们输入模型,则它们必须为300 × 300,因为这是训练模型识别的尺寸. 因此,第一行代码加载图像并将其调整为 300 × 300。
下一行代码将图像转换为二维数组。然而,该模型需要一个 3D 数组,如input_shape模型架构中所示。幸运的是,Numpy提供一种expand_dims处理此问题并允许我们轻松向数组添加新维度的方法。
既然我们的图像是 3D 数组,我们只想确保它是垂直堆叠的,以便它与训练数据的形状相同:
image_tensor = np.vstack([x])使用正确格式的图像,很容易进行分类:
classes = model.predict(image_tensor)该模型返回一个包含分类的数组。因为在这种情况下只有一个分类,所以它实际上是一个包含数组的数组。您可以在图 3-10中看到这一点,其中第一个(人体)模型看起来像[[1.]]。
所以现在只需检查该数组中第一个元素的值即可。如果它大于 0.5,我们正在看一个人:
if classes[0]>0.5:
print(fn + " is a human")
else:
print(fn + " is a horse")这里有几个要点需要考虑。首先,尽管该网络是根据合成的、计算机生成的图像进行训练的,但它在识别真实照片中的马或人方面表现相当出色。这是一个潜在的好处,因为您可能不需要数千张照片来训练模型,并且可以使用 CGI 以相对便宜的方式完成。
但是这个数据集也展示了你将面临的一个基本问题。你的训练集不可能代表你的模型在野外可能面临的每一种可能场景,因此模型总是对训练集有某种程度的过度专业化。此处显示了一个清晰而简单的示例,其中图 3-9中心的人被错误分类。训练集不包括那个姿势的人,因此模型没有“学习”到一个人可能看起来像那样。因此,它很有可能将这个人影视为一匹马,而在这种情况下,它确实做到了。
解决办法是什么?显而易见的一个是添加更多的训练数据,包括处于特定姿势的人类和其他最初没有表现出来的人。不过,这并不总是可能的。幸运的是,TensorFlow 中有一个巧妙的技巧,您可以使用它来虚拟地扩展您的数据集——它被称为图像增强,我们接下来将探讨它。
图像增强
在在上一节中,您构建了一个在相对较小的数据集上训练的马或人分类器模型。结果,您很快就开始遇到对一些以前未见过的图像进行分类的问题,例如,由于训练集不包含任何处于该姿势的人的图像,所以错误分类了一个女人和一匹马。
处理此类问题的一种方法是图像增强。该技术背后的想法是,当 TensorFlow 正在加载您的数据时,它可以通过使用大量转换修改它所拥有的数据来创建额外的新数据。例如,请看图 3-11。虽然数据集中没有任何东西看起来像右边的女人,但左边的图像有些相似。

图 3-11。数据集相似性
因此,例如,如果您可以在训练时放大左侧图像,如图3-12所示,您将增加模型将右侧图像正确分类为人物的机会。

图 3-12。放大训练集数据
-
回转
-
水平移动
-
垂直移动
-
剪毛
-
缩放
-
翻转
因为您一直在使用ImageDataGenerator来加载图像,所以您已经看到它已经进行了转换 — 当它像这样规范化图像时:
train_datagen = ImageDataGenerator(rescale=1/255)这其他转换也很容易在 中使用ImageDataGenerator,因此,例如,您可以执行以下操作:
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)在这里,除了重新缩放图像以对其进行标准化外,您还执行以下操作:
-
将每个图像随机旋转最多向左或向右 40 度
-
将图像垂直或水平平移最多 20%
-
将图像剪切高达 20%
-
将图像放大 20%
-
随机水平或垂直翻转图像
-
在最近的邻居移动或剪切后填充任何丢失的像素
当您使用这些参数重新训练时,您会注意到的第一件事是,由于所有图像处理,训练需要更长的时间。此外,您的模型的准确性可能不如以前那么高,因为以前它过度拟合了一组基本一致的数据。
在我的例子中,当使用这些增强进行训练时,我的准确率在 15 个 epoch 后从 99% 下降到 85%,而验证率略高于 89%。(这表明模型略微欠拟合,因此可以稍微调整参数。)
它之前错误分类的图 3-9中的图像呢?这一次,它做对了。多亏了图像扩充,训练集现在有足够的覆盖面让模型理解这个特定的图像也是一个人(见图3-13)。这只是一个数据点,可能不能代表真实数据的结果,但这是朝着正确方向迈出的一小步。

图 3-13。放大的女人现在被正确分类
如您所见,即使使用相对较小的数据集(如马或人类),您也可以开始构建相当不错的分类器。使用更大的数据集,您可以更进一步。改进模型的另一种技术是使用已经在其他地方学到的特征。许多拥有海量资源(数百万张图像)和经过数千个类别训练的庞大模型的研究人员分享了他们的模型,并且使用称为迁移学习的概念,您可以使用这些模型学习的特征并将它们应用到您的数据中。接下来我们将探讨它!
迁移学习
作为我们已经在本章中看到,使用卷积来提取特征可以成为识别图像内容的强大工具。然后可以将生成的特征图输入神经网络的密集层,以将它们与标签相匹配,并为我们提供一种更准确的方法来确定图像的内容。使用这种方法,通过一个简单的、快速训练的神经网络和一些图像增强技术,我们建立了一个模型,当在非常小的数据集上训练时,它在区分马和人方面的准确率为 80-90%。
但是我们可以使用一种称为迁移学习的方法进一步改进我们的模型。这迁移学习背后的想法很简单:与其从头开始为我们的数据集学习一组过滤器,为什么不使用一组在更大的数据集上学习的过滤器,这些过滤器具有比我们“负担得起”从头开始构建更多的功能?我们可以将它们放在我们的网络中,然后使用预学习的过滤器用我们的数据训练模型。例如,我们的 Horses 或 Humans 数据集只有两个类别。我们可以使用针对一千个类进行预训练的现有模型,但在某些时候,我们将不得不丢弃一些预先存在的网络,并添加可以让我们拥有两个类的分类器的层。
图 3-14显示了用于像我们这样的分类任务的 CNN 架构可能是什么样子。我们有一系列的卷积层导致密集层,而密集层又导致输出层。

图 3-14。卷积神经网络架构
我们已经看到我们能够使用这种架构构建一个非常好的分类器。但通过迁移学习,如果我们可以从另一个模型中获取预学习层,冻结或锁定它们,使它们不可训练,然后将它们放在我们的模型之上,如图 3-15 所示,会怎样?
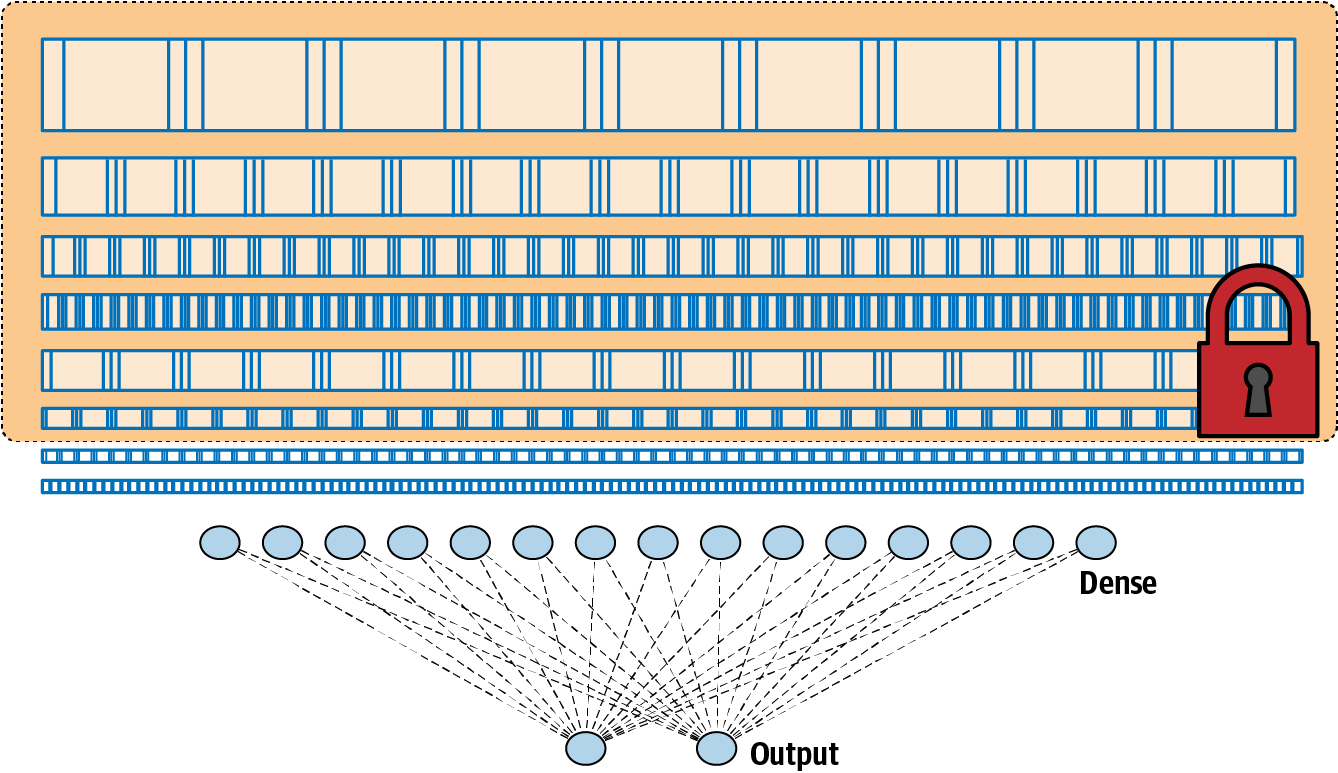
图 3-15。通过迁移学习从另一个架构中获取层
当我们考虑到这一点时,一旦它们被训练,所有这些层都只是一组数字,指示过滤器值、权重和偏差以及已知的架构(每层过滤器的数量、过滤器的大小等),重用它们的想法非常简单。
让我们看看这将如何出现在代码中。已经有多种可从各种来源获得的预训练模型。我们将使用来自 Google 的流行 Inception 模型的第 3 版,该模型在来自名为 ImageNet 的数据库中的超过一百万张图像上进行训练。它有几十层,可以将图像分为一千个类别。包含预训练权重的保存模型可用。要使用它,我们只需下载权重,创建 Inception V3 架构的实例,然后将权重加载到该架构中,如下所示:
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras import layers
from tensorflow.keras import Model
from tensorflow.keras.applications.inception_v3 import InceptionV3
from tensorflow.keras.optimizers import RMSprop
weights_url = "https://storage.googleapis.com/mledu-
datasets/inception_v3_weights_tf_dim_ordering_tf_kernels_notop.h5"
weights_file = "inception_v3.h5"
urllib.request.urlretrieve(weights_url, weights_file)
pre_trained_model = InceptionV3(input_shape=(150, 150, 3),
include_top=False,
weights=None)
pre_trained_model.load_weights(weights_file)现在我们有一个完整的预训练初始模型。如果你想检查它的架构,你可以这样做:
pre_trained_model.summary()请注意——它很大!尽管如此,还是要仔细查看它以查看图层及其名称。我喜欢使用名为 的那个,mixed7因为它的输出又好又小——7 × 7 图像——但你可以随意尝试其他的。
接下来,我们将冻结整个网络的重新训练,然后设置一个变量以指向mixed7的输出,作为我们想要将网络裁剪到的位置。我们可以用这段代码做到这一点:
for layer in pre_trained_model.layers:
layer.trainable = False
last_layer = pre_trained_model.get_layer('mixed7')
print('last layer output shape: ', last_layer.output_shape)
last_output = last_layer.output请注意,我们打印了最后一层的输出形状,此时您会看到我们得到了7 × 7 的图像。这表明当图像被馈送到 时mixed7,过滤器的输出图像大小为 7 × 7,因此它们非常易于管理。同样,您不必选择那个特定的层;欢迎您与其他人进行实验。
现在让我们看看如何在下面添加我们的致密层:
# Flatten the output layer to 1 dimension
x = layers.Flatten()(last_output)
# Add a fully connected layer with 1,024 hidden units and ReLU activation
x = layers.Dense(1024, activation='relu')(x)
# Add a final sigmoid layer for classification
x = layers.Dense(1, activation='sigmoid')(x)它就像从最后一个输出创建一组扁平层一样简单,因为我们会将结果提供给密集层。然后我们添加一个包含 1,024 个神经元的密集层,以及一个包含 1 个神经元的密集层作为我们的输出。
现在我们可以简单地定义我们的模型,只需说它是我们的预训练模型的输入,然后是x我们刚刚定义的输入。然后我们以通常的方式编译它:
model = Model(pre_trained_model.input, x)
model.compile(optimizer=RMSprop(lr=0.0001),
loss='binary_crossentropy',
metrics=['acc'])训练该架构上的模型超过 40 个时期的准确率达到 99%+,验证准确率达到 96%+(见图3-16)。

图 3-16。使用迁移学习训练马或人分类器
这里的结果比我们以前的模型要好得多,但您可以继续调整和改进它。您还可以探索该模型如何处理更大的数据集,例如著名的 来自 Kaggle 的Dogs vs. Cats。这是一个极其多样化的数据集,由 25,000 张猫和狗的图像组成,通常主题有些模糊——例如,如果它们被人拿着。
使用与之前相同的算法和模型设计,您可以在 Colab 上训练狗与猫分类器,使用 GPU 大约每个时期 3 分钟。对于 20 个 epoch,这相当于大约 1 小时的训练。
当使用如图 3-17中的非常复杂的图片进行测试时,该分类器将它们全部正确。我选择了一张长着猫耳朵的狗的照片,还有一张是背对着的。两张猫的照片都不典型。

图 3-17。被正确分类的不寻常的狗和猫
右下角的猫在洗爪子时闭着眼睛、垂着耳朵、伸出舌头,在加载到模型中时给出了图 3-18中的结果。你可以看到它给出了一个非常低的值 (4.98 × 10 –24 ),这表明网络几乎可以肯定它是一只猫!
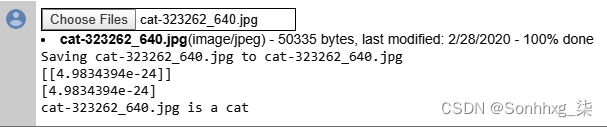
图 3-18。分类猫洗它的爪子
您可以在本书的GitHub 存储库中找到 Horses or Humans and Dogs vs. Cats 分类器的完整代码。
多类分类
在到目前为止,所有示例都是在构建二元分类器——在两个选项(马或人、猫或狗)之间进行选择的分类器。在构建多类分类器时,模型几乎相同,但存在一些重要差异。您的输出层现在需要n个神经元,而不是一个 sigmoid 激活的神经元或两个二元激活的神经元,其中n是您要分类的类数。您还必须将损失函数更改为适合多个类别的损失函数。例如,对于你在本章到目前为止构建的二元分类器,你的损失函数是二元交叉熵,如果你想为多个类扩展模型,你应该使用分类交叉熵。如果您使用 来ImageDataGenerator提供图像,则标签会自动完成,因此多个类别的工作方式与二进制类别相同——将ImageDataGenerator简单地根据子目录的数量进行标签。
例如,考虑一下石头剪刀布游戏。如果你想训练一个数据集来识别不同的手势,你需要处理三个类别。幸运的是,有一个简单的数据集可用于此目的。
有两个下载:一个训练集,包含许多不同的手,具有不同的大小、形状、颜色和指甲油等细节;和一组同样不同的手,但都不在训练集中。
您可以在图 3-19中看到一些示例。

图 3-19。剪刀石头布手势示例
使用数据集很简单。下载并解压它——排序的子目录已经存在于 ZIP 文件中——然后用它来初始化一个ImageDataGenerator:
!wget --no-check-certificate \
https://storage.googleapis.com/laurencemoroney-blog.appspot.com/rps.zip \
-O /tmp/rps.zip
local_zip = '/tmp/rps.zip'
zip_ref = zipfile.ZipFile(local_zip, 'r')
zip_ref.extractall('/tmp/')
zip_ref.close()
TRAINING_DIR = "/tmp/rps/"
training_datagen = ImageDataGenerator(
rescale = 1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest'
)但是请注意,当您从这里设置数据生成器时,您必须指定类模式是分类的,以便ImageDataGenerator使用两个以上的子目录:
train_generator = training_datagen.flow_from_directory(
TRAINING_DIR,
target_size=(150,150),
class_mode='categorical'
)在定义模型时,在关注输入层和输出层的同时,您要确保输入与数据的形状(在本例中为 150 × 150)相匹配,并且输出与类的数量(现在为三个)相匹配:
model = tf.keras.models.Sequential([
# Note the input shape is the desired size of the image:
# 150x150 with 3 bytes color
# This is the first convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu',
input_shape=(150, 150, 3)),
tf.keras.layers.MaxPooling2D(2, 2),
# The second convolution
tf.keras.layers.Conv2D(64, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The third convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# The fourth convolution
tf.keras.layers.Conv2D(128, (3,3), activation='relu'),
tf.keras.layers.MaxPooling2D(2,2),
# Flatten the results to feed into a DNN
tf.keras.layers.Flatten(),
# 512 neuron hidden layer
tf.keras.layers.Dense(512, activation='relu'),
tf.keras.layers.Dense(3, activation='softmax')
])最后,在编译模型时,您要确保它使用分类损失函数,例如分类交叉熵。二元交叉熵不适用于两个以上的类:
model.compile(loss = 'categorical_crossentropy', optimizer='rmsprop',
metrics=['accuracy'])然后训练和以前一样:
history = model.fit(train_generator, epochs=25,
validation_data = validation_generator, verbose = 1)您用于测试预测的代码也需要进行一些更改。现在有三个输出神经元,它们将为预测类输出接近 1 的值,为其他类输出接近 0 的值。请注意,使用的激活函数是softmax,这将确保所有三个预测加起来为 1。例如,如果模型看到它确实不确定的东西,它可能会输出 .4、.4、.2,但如果它看到了它非常确定的东西关于您可能会得到 .98、.01、.01。
另请注意,在使用 时ImageDataGenerator,类是按字母顺序加载的——因此虽然您可能希望输出神经元按游戏名称的顺序排列,但实际上顺序是布、石头、剪刀。
在 Colab 笔记本中尝试预测的代码如下所示。它与您之前看到的非常相似:
import numpy as np
from google.colab import files
from keras.preprocessing import image
uploaded = files.upload()
for fn in uploaded.keys():
# predicting images
path = fn
img = image.load_img(path, target_size=(150, 150))
x = image.img_to_array(img)
x = np.expand_dims(x, axis=0)
images = np.vstack([x])
classes = model.predict(images, batch_size=10)
print(fn)
print(classes)请注意,它不解析输出,只打印类。图 3-20显示了它在使用中的样子。
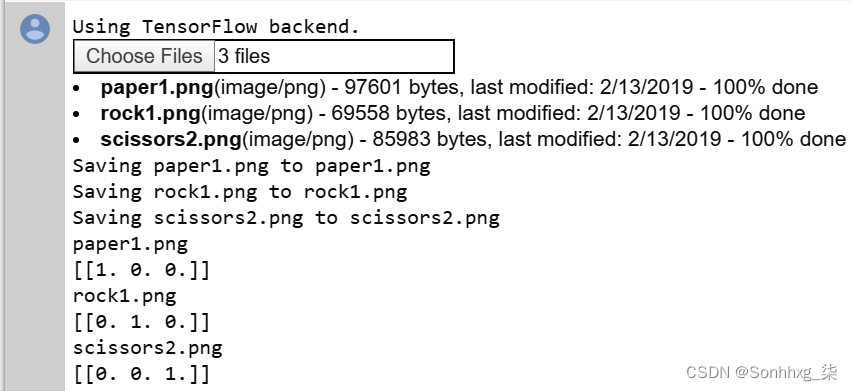
图 3-20。测试剪刀石头布分类器
您可以从文件名中看出图像是什么。Paper1.png以 结尾[1, 0, 0],这意味着第一个神经元被激活而其他神经元未被激活。同样,Rock1.png最终为[0, 1, 0],激活了第二个神经元,而Scissors2.png为[0, 0, 1]。请记住,神经元是按标签的字母顺序排列的!
一些可用于测试数据集的图像可供下载。或者,当然,您可以自己尝试。请注意,训练图像都是在纯白色背景下完成的,因此如果您拍摄的照片背景中有很多细节,可能会造成一些混淆。
丢弃正则化
早些时候在本章中,我们讨论了过度拟合,在这种情况下,网络可能会变得过于专注于特定类型的输入数据,而对其他类型的输入数据表现不佳。帮助克服这个问题的一种技术是使用dropout 正则化。
当训练神经网络时,每个单独的神经元都会对后续层中的神经元产生影响。随着时间的推移,特别是在较大的网络中,一些神经元可能变得过度专业化——这会向下游提供信息,可能导致整个网络变得过度专业化并导致过度拟合。此外,相邻的神经元最终可能会具有相似的权重和偏差,如果不加以监控,这可能会导致整个模型过度专门化为那些神经元激活的特征。
例如,考虑图 3-21中的神经网络,其中有 2、6、6 和 2 个神经元层。中间层的神经元最终可能具有非常相似的权重和偏差。
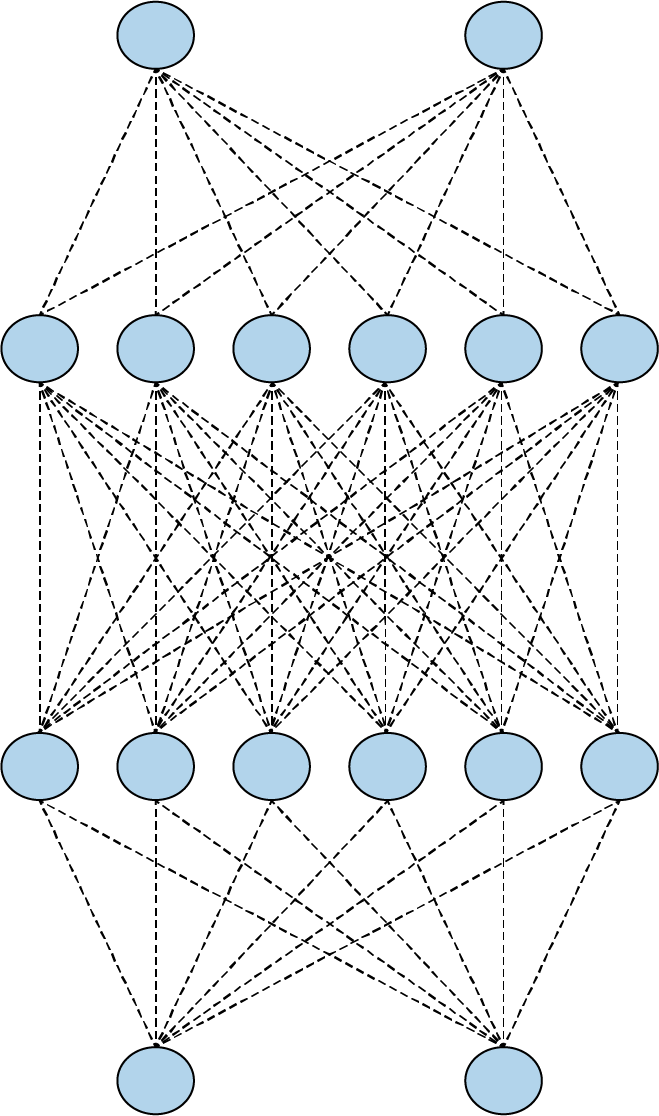
图 3-21。一个简单的神经网络
在训练时,如果你删除随机数量的神经元并忽略它们,它们对下一层神经元的贡献会暂时被阻止(图 3-22)。

图 3-22。一个有 dropouts 的神经网络
这减少了神经元变得过度专业化的机会。网络仍将学习相同数量的参数,但它应该更擅长泛化——也就是说,它应该对不同的输入更有弹性。
笔记
dropouts 的概念是由 Nitish Srivastava 等人提出的。在他们 2014 年的论文“Dropout:一种防止神经网络过度拟合的简单方法”中。
至在 TensorFlow 中实现 dropouts,你可以像这样使用一个简单的 Keras 层:
tf.keras.layers.Dropout(0.2),这将随机丢弃指定层中指定百分比的神经元(此处为 20%)。请注意,可能需要进行一些实验才能为您的网络找到正确的百分比。
有关演示这一点的简单示例,请考虑第 2 章中的 Fashion MNIST 分类器。我将更改网络定义以包含更多层,如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])对其进行 20 个 epoch 的训练,在训练集上的准确率约为 94%,在验证集上的准确率约为 88.5%。这是潜在过度拟合的迹象。
在每个密集层之后引入 dropout 如下所示:
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28,28)),
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10, activation=tf.nn.softmax)
])当这个网络在同一时期用相同的数据进行训练时,训练集上的准确率下降到大约 89.5%。验证集的准确率基本保持不变,为 88.3%。这些值彼此更接近;因此,dropouts 的引入不仅证明了过度拟合的发生,而且使用 dropouts 可以通过确保网络不会过度专注于训练数据来帮助消除这种歧义。
在设计神经网络时请记住,在训练集上取得好的结果并不总是一件好事。这可能是过度拟合的迹象。引入dropouts可以帮助你解决这个问题,这样你就可以在其他方面优化你的网络,而不会产生那种错误的安全感。
概括
本章向您介绍了使用卷积神经网络实现计算机视觉的更高级方法。您了解了如何使用卷积来应用可以从图像中提取特征的过滤器,并设计了您的第一个神经网络来处理比您在 MNIST 和 Fashion MNIST 数据集中遇到的更复杂的视觉场景。您还探索了提高网络准确性和避免过度拟合的技术,例如使用图像增强和丢弃。
在我们探索更多场景之前,您将在第 4 章中了解 TensorFlow 数据集,这项技术可以让您更轻松地访问用于训练和测试网络的数据。在本章中,您下载了 ZIP 文件并提取图像,但这并不总是可行的。借助 TensorFlow Datasets,您将能够使用标准 API 访问大量数据集。
相关文章
- Apache 服务器 基础知识小结
- java基础知识回顾之javaIO类---InputStreamReader和OutputStreamWriter转化流
- Python基础知识笔记-作用域
- 【STM32H7教程】第65章 STM32H7的低功耗串口LPUART基础知识和HAL库API
- 【STM32H7教程】第39章 STM32H7的DMAMUX基础知识(重要)
- 【微搭低代码】JavaScript基础知识-循环和条件控制
- 【项目实战】Springboot基础知识入门介绍、查漏补缺
- 声学工程师应知道的150个声学基础知识
- 【读一本书】《昇腾AI处理器架构与编程》--神经网络基础知识(2)
- 【大数据&人工智能AI】每个现代数据科学家都必须阅读的 6 篇论文:该领域的每个人都熟悉深度学习的一些最重要的现代基础知识的列表
- 一次性补全网络基础知识!
- 硬件工程师入门基础知识(一)基础元器件认识(二)
- C++基础知识要点--表达式 (Primer C++ 第五版 · 阅读笔记)
- TCL基础知识